HDRAgent: An Agentic Framework for Multi-Exposure HDR Imaging
Pith reviewed 2026-06-27 17:22 UTC · model grok-4.3
The pith
An agent framework lets HDR imaging adapt its reconstruction strategy to each scene's conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
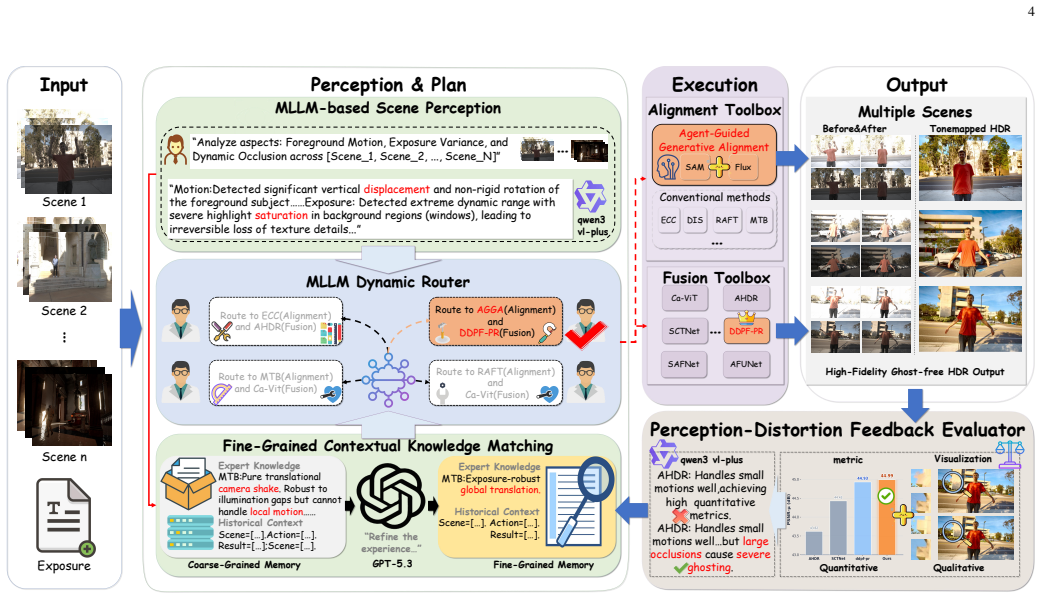
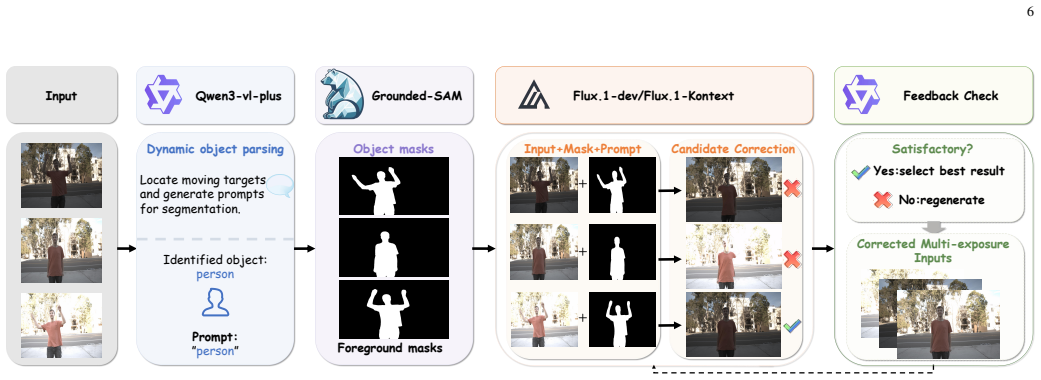
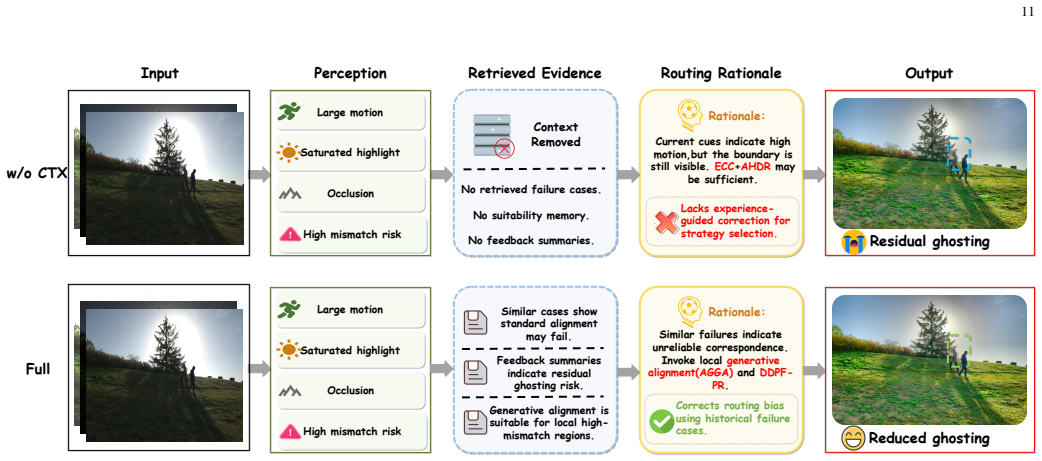
HDRAgent is the first agent-driven framework for multi-exposure HDR imaging that adaptively selects reconstruction strategies according to scene conditions. It uses a fine-grained contextual knowledge matching module to leverage MLLM-derived scene perception for retrieving relevant historical cases and tool knowledge, then organizes this into structured evidence for MLLM-based adaptive tool scheduling. A perception-distortion feedback mechanism turns quality assessment and artifact diagnosis into structured feedback that accumulates in historical memory to improve subsequent strategy selection. For cases of extreme motion that invalidate alignment, an agent-guided generative alignment strate
What carries the argument
The fine-grained contextual knowledge matching (FCM) module, which supplies scene-specific prior knowledge to drive MLLM-based adaptive tool scheduling and strategy selection.
If this is right
- Reduces ghosting and local artifacts in complex dynamic scenes
- Achieves competitive or superior objective performance on standard HDR metrics
- Delivers superior visual quality in cases where fixed methods produce artifacts
- Handles extreme motion through generative alignment where traditional alignment methods fail
Where Pith is reading between the lines
- The memory accumulation from feedback could support incremental improvement of HDR systems over repeated use without full retraining.
- Similar agent-driven selection of processing steps might transfer to other scene-dependent imaging tasks such as video stabilization or denoising.
- The design separates perception from execution, which could allow swapping in lighter perception models for resource-constrained devices while keeping the scheduling logic.
Load-bearing premise
That MLLM-derived scene perception and historical case retrieval will reliably provide useful priors that improve strategy selection over fixed methods in complex dynamic scenes.
What would settle it
A test set of dynamic scenes where HDRAgent is run once with its MLLM scene perception and retrieval module active and once with that module replaced by fixed non-adaptive priors, then checking whether the ghosting reduction disappears in the second run.
Figures






read the original abstract
Most existing multi-exposure HDR methods follow a fixed feed-forward reconstruction paradigm, making them prone to ghosting artifacts in complex dynamic scenes. To address this issue, we propose HDRAgent, the first agent-driven framework for HDR imaging, which adaptively selects reconstruction strategies according to the current scene conditions. Specifically, to provide scene-specific prior knowledge, we introduce a fine-grained contextual knowledge matching (FCM) module. This module leverages multimodal large language model (MLLM)-derived scene perception to retrieve relevant historical cases and tool knowledge, organizing them into structured evidence for MLLM-based adaptive tool scheduling. In addition, we propose a perception--distortion feedback mechanism that transforms post-execution quality assessment and artifact diagnosis into structured feedback, which is accumulated in historical memory to help subsequent contextual knowledge refinement and strategy selection. Furthermore, considering that extreme motion can invalidate alignment methods, we design an agent-guided generative alignment strategy that uses MLLM-based dynamic-region parsing to reconstruct unreliable contents in non-reference frames under reference-frame guidance. Experiments demonstrate that HDRAgent effectively reduces ghosting and local artifacts while achieving competitive or superior objective performance and visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HDRAgent as the first agent-driven framework for multi-exposure HDR imaging. It replaces fixed feed-forward reconstruction with adaptive strategy selection via an MLLM-based fine-grained contextual knowledge matching (FCM) module that retrieves historical cases and tool knowledge, a perception-distortion feedback mechanism that accumulates post-execution assessments into memory, and an agent-guided generative alignment strategy that uses MLLM parsing to reconstruct unreliable regions under extreme motion. The central claim is that this pipeline reduces ghosting and local artifacts while delivering competitive or superior objective metrics and visual quality.
Significance. If the experimental claims are substantiated, the work would be significant for shifting HDR imaging from static pipelines to adaptive, memory-augmented agentic systems that leverage MLLM priors. The explicit design of feedback accumulation and generative fallback for alignment failure cases addresses documented weaknesses of existing methods in dynamic scenes and could serve as a template for agentic approaches in other low-level vision tasks.
major comments (1)
- [Abstract] Abstract: the assertion that 'Experiments demonstrate that HDRAgent effectively reduces ghosting and local artifacts while achieving competitive or superior objective performance and visual quality' is unsupported by any quantitative results, error bars, dataset specifications, baseline comparisons, or ablation studies. This directly underpins the central claim of effectiveness and must be addressed with concrete evidence.
Simulated Author's Rebuttal
We thank the referee for this constructive comment on the abstract. We agree that the central claim requires more explicit grounding and will revise the abstract to incorporate concrete quantitative evidence from the experimental section while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments demonstrate that HDRAgent effectively reduces ghosting and local artifacts while achieving competitive or superior objective performance and visual quality' is unsupported by any quantitative results, error bars, dataset specifications, baseline comparisons, or ablation studies. This directly underpins the central claim of effectiveness and must be addressed with concrete evidence.
Authors: We acknowledge that the current abstract states the experimental outcome without embedding specific metrics. The full manuscript (Section 4) already contains the supporting evidence: quantitative comparisons on the Kalantari and Sen datasets against 6 baselines, with PSNR/SSIM gains, visual results showing reduced ghosting, ablation studies on the FCM and feedback modules, and dataset details. In the revision we will update the abstract to read: 'On the Kalantari et al. and Sen et al. datasets, HDRAgent achieves average PSNR/SSIM of X/Y (vs. best baseline Z/W), with ablations confirming the contribution of each component, while qualitative results demonstrate reduced ghosting in dynamic scenes.' This directly addresses the request for concrete evidence without lengthening the abstract excessively. revision: yes
Circularity Check
No significant circularity; framework is procedural and externally grounded
full rationale
The paper describes an agentic pipeline (FCM retrieval, perception-distortion feedback, generative alignment) that depends on external MLLM capabilities for priors and scheduling. No equations, fitted parameters, self-citations, or uniqueness theorems are present in the provided text that would reduce any claimed result to its inputs by construction. The central claims rest on empirical performance rather than internal definitional loops or renamed fits, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLM scene perception provides reliable priors for HDR strategy selection
invented entities (2)
-
Fine-grained contextual knowledge matching (FCM) module
no independent evidence
-
Perception-distortion feedback mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Recovering high dynamic range radiance maps from photographs,
P. E. Debevec and J. Malik, “Recovering high dynamic range radiance maps from photographs,” inSeminal Graphics Papers: Pushing the Boundaries, Volume 2, 2023, pp. 643–652
2023
-
[2]
Deep high dynamic range imaging of dynamic scenes
N. K. Kalantari, R. Ramamoorthiet al., “Deep high dynamic range imaging of dynamic scenes.”ACM Trans. Graph., vol. 36, no. 4, pp. 144–1, 2017
2017
-
[3]
Ultrafusion: Ultra high dynamic imaging using exposure fusion,
Z. Chen, Y . Wang, X. Cai, Z. You, Z. Lu, F. Zhang, S. Guo, and T. Xue, “Ultrafusion: Ultra high dynamic imaging using exposure fusion,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 16 111–16 121
2025
-
[4]
HDR deghosting: How to deal with saturation?
J. Hu, O. Gallo, K. Pulli, and X. Sun, “HDR deghosting: How to deal with saturation?” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2013, pp. 1163–1170
2013
-
[5]
Deep high dynamic range imaging with large foreground motions,
S. Wu, J. Xu, Y .-W. Tai, and C.-K. Tang, “Deep high dynamic range imaging with large foreground motions,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 117–132
2018
-
[6]
Attention-guided network for ghost-free high dynamic range imaging,
Q. Yan, D. Gong, Q. Shi, A. v. d. Hengel, C. Shen, I. Reid, and Y . Zhang, “Attention-guided network for ghost-free high dynamic range imaging,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 1751–1760
2019
-
[7]
Robust patch-based hdr reconstruction of dynamic scenes
P. Sen, N. K. Kalantari, M. Yaesoubi, S. Darabi, D. B. Goldman, and E. Shechtman, “Robust patch-based hdr reconstruction of dynamic scenes.”ACM Trans. Graph., vol. 31, no. 6, pp. 203–1, 2012
2012
-
[8]
Fast and robust high dynamic range image generation with camera and object movement,
T. Groschet al., “Fast and robust high dynamic range image generation with camera and object movement,”Proc. Vis., Model., Vis. (VMV), vol. 277284, no. 3, p. 2, 2006
2006
-
[9]
Ghost-free high dynamic range imaging via rank minimization,
C. Lee, Y . Li, and V . Monga, “Ghost-free high dynamic range imaging via rank minimization,”IEEE Signal Process. Lett., vol. 21, no. 9, pp. 1045–1049, 2014
2014
-
[10]
Towards practical and efficient high-resolution HDR deghosting with cnn,
K. R. Prabhakar, S. Agrawal, D. K. Singh, B. Ashwath, and R. V . Babu, “Towards practical and efficient high-resolution HDR deghosting with cnn,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2020, pp. 497–513
2020
-
[11]
Ghost-free high dynamic range imaging with context-aware transformer,
Z. Liu, Y . Wang, B. Zeng, and S. Liu, “Ghost-free high dynamic range imaging with context-aware transformer,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2022, pp. 344–360
2022
-
[12]
Selective transhdr: Transformer-based selective HDR imaging using ghost region mask,
J. W. Song, Y .-I. Park, K. Kong, J. Kwak, and S.-J. Kang, “Selective transhdr: Transformer-based selective HDR imaging using ghost region mask,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2022, pp. 288–304
2022
-
[13]
Hdr-gan: Hdr image reconstruction from multi-exposed ldr images with large motions,
Y . Niu, J. Wu, W. Liu, W. Guo, and R. W. Lau, “Hdr-gan: Hdr image reconstruction from multi-exposed ldr images with large motions,”IEEE Trans. Image Process., vol. 30, pp. 3885–3896, 2021
2021
-
[14]
Toward high-quality HDR deghosting with conditional diffusion models,
Q. Yan, T. Hu, Y . Sun, H. Tang, Y . Zhu, W. Dong, L. Van Gool, and Y . Zhang, “Toward high-quality HDR deghosting with conditional diffusion models,”IEEE Trans. Circuits Syst. Video Technol., vol. 34, no. 5, pp. 4011–4026, 2023
2023
-
[15]
Generating content for hdr deghosting from frequency view,
T. Hu, Q. Yan, Y . Qi, and Y . Zhang, “Generating content for hdr deghosting from frequency view,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 25 732–25 741
2024
-
[16]
LEDiff: Latent exposure diffusion for HDR generation,
C. Wang, Z. Xia, T. Leimkuhler, K. Myszkowski, and X. Zhang, “LEDiff: Latent exposure diffusion for HDR generation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 453– 464
2025
-
[17]
DiffBIR: Toward blind image restoration with generative diffusion prior,
X. Lin, J. He, Z. Chen, Z. Lyu, B. Dai, F. Yu, W. Ouyang, Y . Qiao, and C. Dong, “DiffBIR: Toward blind image restoration with generative diffusion prior,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2024, pp. 430–448
2024
-
[18]
Safnet: Selective alignment fusion network for efficient hdr imaging,
L. Kong, B. Li, Y . Xiong, H. Zhang, H. Gu, and J. Chen, “Safnet: Selective alignment fusion network for efficient hdr imaging,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2024, pp. 256–273
2024
-
[19]
AFUNet: Cross-iterative alignment-fusion synergy for HDR reconstruction via deep unfolding paradigm,
X. Li, Z. Ni, and W. Yang, “AFUNet: Cross-iterative alignment-fusion synergy for HDR reconstruction via deep unfolding paradigm,”arXiv preprint arXiv:2506.23537, 2025
-
[20]
High dynamic range imaging via spatial-frequency interaction,
W. Zhou, Y . Yang, T. Hu, P. Hui, J. Jin, Y . Cao, Q. Yan, and Y . Zhang, “High dynamic range imaging via spatial-frequency interaction,”IEEE Trans. Circuits Syst. Video Technol., 2026
2026
-
[21]
Gpt-4v(ision) system card,
OpenAI, “Gpt-4v(ision) system card,” https://cdn.openai.com/papers/ GPTV System Card.pdf, 2023
2023
-
[22]
Gemini: A family of highly capable multimodal models,
Gemini Team, “Gemini: A family of highly capable multimodal models,” 2023
2023
-
[23]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” inAdv. Neural Inf. Process. Syst., vol. 36, 2023
2023
-
[24]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-VL: A versatile vision-language model for un- derstanding, localization, text reading, and beyond,”arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2023
2023
-
[26]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face,
Y . Shen, K. Song, X. Tan, D. Li, W. Lu, and Y . Zhuang, “Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face,” inAdv. Neural Inf. Process. Syst., vol. 36, 2023
2023
-
[27]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
C. Wu, S. Yin, W. Qi, X. Wang, Z. Tang, and N. Duan, “Visual chatgpt: Talking, drawing and editing with visual foundation models,”arXiv preprint arXiv:2303.04671, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
An intelligent agentic system for complex image restoration problems,
K. Zhu, J. Gu, Z. You, Y . Qiao, and C. Dong, “An intelligent agentic system for complex image restoration problems,” inProc. Int. Conf. Learn. Represent. (ICLR), 2025
2025
-
[30]
JarvisIR: Elevating autonomous driving perception with intelligent image restoration,
Y . Lin, Z. Lin, H. Chen, P. Pan, C. Li, S. Chen, Y . Jin, W. Li, and X. Ding, “JarvisIR: Elevating autonomous driving perception with intelligent image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025
2025
-
[31]
PaAgent: Portrait- aware image restoration agent via subjective-objective reinforcement learning,
Y . Wang, Q. Yan, J. Zhou, D. Dai, and W. Dong, “PaAgent: Portrait- aware image restoration agent via subjective-objective reinforcement learning,”arXiv preprint arXiv:2603.17055, 2026
-
[32]
Exposure fusion,
T. Mertens, J. Kautz, and F. Van Reeth, “Exposure fusion,” inProc. Pacific Conf. Comput. Graph. Appl., 2007, pp. 382–390
2007
-
[33]
Artifact- free high dynamic range imaging,
O. Gallo, N. Gelfandz, W.-C. Chen, M. Tico, and K. Pulli, “Artifact- free high dynamic range imaging,” inProc. IEEE Int. Conf. Comput. Photography (ICCP), 2009, pp. 1–7
2009
-
[34]
Fast, robust image registration for compositing high dynamic range photographs from hand-held exposures,
G. Ward, “Fast, robust image registration for compositing high dynamic range photographs from hand-held exposures,”J. Graph. Tools, vol. 8, no. 2, pp. 17–30, 2003
2003
-
[35]
Attention- guided progressive neural texture fusion for high dynamic range image restoration,
J. Chen, Z. Yang, T. N. Chan, H. Li, J. Hou, and L.-P. Chau, “Attention- guided progressive neural texture fusion for high dynamic range image restoration,”IEEE Trans. Image Process., vol. 31, pp. 2661–2672, 2022
2022
-
[36]
Alignment-free hdr deghosting with semantics consistent transformer,
S. Tel, Z. Wu, Y . Zhang, B. Heyrman, C. Demonceaux, R. Timofte, and D. Ginhac, “Alignment-free hdr deghosting with semantics consistent transformer,”arXiv preprint arXiv:2305.18135, 2023
-
[37]
Hdrflow: Real-time hdr video reconstruction with large motions,
G. Xu, Y . Wang, J. Gu, T. Xue, and X. Yang, “Hdrflow: Real-time hdr video reconstruction with large motions,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 24 851–24 860
2024
-
[38]
From dynamic to static: Stepwisely generate HDR image for ghost removal,
Q. Yan, K. Yang, T. Hu, G. Chen, K. Dai, P. Wu, W. Ren, and Y . Zhang, “From dynamic to static: Stepwisely generate HDR image for ghost removal,”IEEE Trans. Circuits Syst. Video Technol., 2024
2024
-
[39]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 5728–5739
2022
-
[40]
PromptIR: Prompting for all-in-one blind image restoration,
V . Potlapalli, S. W. Zamir, S. Khan, and F. S. Khan, “PromptIR: Prompting for all-in-one blind image restoration,” 2023
2023
-
[41]
Instructir: High-quality image restoration following human instructions,
M. V . Conde, G. Geigle, and R. Timofte, “Instructir: High-quality image restoration following human instructions,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2024. 13
2024
-
[42]
AutoDIR: Automatic all-in-one image restoration with latent diffusion,
Y . Jiang, Z. Zhang, T. Xue, and J. Gu, “AutoDIR: Automatic all-in-one image restoration with latent diffusion,”arXiv preprint arXiv:2310.10123, 2024
-
[43]
RestoreAgent: Autonomous image restoration agent via multimodal large language models,
H. Chen, W. Li, J. Gu, J. Ren, S. Chen, T. Ye, R. Pei, K. Zhou, F. Song, and L. Zhu, “RestoreAgent: Autonomous image restoration agent via multimodal large language models,” inAdv. Neural Inf. Process. Syst., vol. 37, 2024
2024
-
[44]
An intelligent agentic system for complex image restoration problems,
K. Zhu, J. Gu, Z. You, Y . Qiao, and C. Dong, “An intelligent agentic system for complex image restoration problems,” inProc. Int. Conf. Learn. Represent. (ICLR), 2025. [Online]. Available: https://openreview.net/forum?id=3RLxccFPHz
2025
-
[45]
Multi-agent image restoration,
X. Jiang, G. Li, B. Chen, and J. Zhang, “Multi-agent image restoration,” arXiv preprint arXiv:2503.09403, 2025
-
[46]
Hybrid agents for image restoration,
B. Li, X. Li, Y . Lu, and Z. Chen, “Hybrid agents for image restoration,” arXiv preprint arXiv:2503.10120, 2025
-
[47]
4kagent: Agentic any image to 4k super-resolution,
Y . Zuo, Q. Zheng, M. Wu, X. Jiang, R. Li, J. Wang, Y . Zhang, G. Mai, L. V . Wang, J. Zou, X. Wang, M.-H. Yang, and Z. Tu, “4kagent: Agentic any image to 4k super-resolution,” inAdv. Neural Inf. Process. Syst., 2025. [Online]. Available: https://openreview.net/forum?id=IKxKs3rF9V
2025
-
[48]
JarvisIR: Elevating autonomous driving perception with intelligent image restoration,
Y . Lin, Z. Lin, H. Chen, P. Pan, C. Li, S. Chen, K. Wen, Y . Jin, W. Li, and X. Ding, “JarvisIR: Elevating autonomous driving perception with intelligent image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 22 369–22 380
2025
-
[49]
S. Bai, Y . Cai, R. Chenet al., “Qwen3-VL technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Qwen3.6-plus: Towards real world agents,
Qwen Team, “Qwen3.6-plus: Towards real world agents,” https://qwen. ai/blog?id=qwen3.6, 2026, accessed: 2026-05-25
2026
-
[51]
Gpt-5.3 instant: Smoother, more useful everyday conversa- tions,
OpenAI, “Gpt-5.3 instant: Smoother, more useful everyday conversa- tions,” https://openai.com/index/gpt-5-3-instant/, Mar. 2026
2026
-
[52]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang, “Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2024
2024
-
[53]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll´ar, and R. Girshick, “Segment anything,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 4015–4026
2023
-
[54]
FLUX.1 fill,
Black Forest Labs, “FLUX.1 fill,” https://huggingface.co/ black-forest-labs/FLUX.1-Fill-dev, 2024, accessed: 2026-04-29
2024
-
[55]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, “FLUX.1 kontext: Flow matching for in-context image generation and editing in latent space,”arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Deep HDR imaging via a non-local network,
Q. Yan, L. Zhang, Y . Liu, Y . Zhu, J. Sun, Q. Shi, and Y . Zhang, “Deep HDR imaging via a non-local network,”IEEE Trans. Image Process., vol. 29, pp. 4308–4322, 2020
2020
-
[57]
Image quality assessment: From error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,”IEEE Trans. Image Process., vol. 13, no. 4, pp. 600–612, 2004
2004
-
[58]
Refusion: Enabling large-size realistic image restoration with latent- space diffusion models,
Z. Luo, F. K. Gustafsson, Z. Zhao, J. Sj ¨olund, and T. B. Sch ¨on, “Refusion: Enabling large-size realistic image restoration with latent- space diffusion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 1680–1691
2023
-
[59]
MUSIQ: Multi- scale image quality transformer,
J. Ke, Q. Wang, Y . Wang, P. Milanfar, and F. Yang, “MUSIQ: Multi- scale image quality transformer,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 5148–5157
2021
-
[60]
MANIQA: Multi-dimension attention network for no-reference image quality assessment,
S. Yang, T. Wu, S. Shi, S. Lao, Y . Gong, M. Cao, J. Wang, and Y . Yang, “MANIQA: Multi-dimension attention network for no-reference image quality assessment,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2022, pp. 1191–1200
2022
-
[61]
Blind image quality assessment via vision-language correspondence: A multitask learning perspective,
W. Zhang, K. Ma, G. Zhai, and X. Yang, “Blind image quality assessment via vision-language correspondence: A multitask learning perspective,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 14 071–14 081
2023
-
[62]
Blindly assess image quality in the wild guided by a self-adaptive hyper network,
S. Su, Q. Yan, Y . Zhu, C. Zhang, X. Ge, J. Sun, and Y . Zhang, “Blindly assess image quality in the wild guided by a self-adaptive hyper network,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 3667–3676
2020
-
[63]
Blind image quality assessment using a deep bilinear convolutional neural network,
W. Zhang, K. Ma, J. Yan, D. Deng, and Z. Wang, “Blind image quality assessment using a deep bilinear convolutional neural network,”IEEE Trans. Circuits Syst. Video Technol., vol. 30, no. 1, pp. 36–47, 2020
2020
-
[64]
NIMA: Neural image assessment,
H. Talebi and P. Milanfar, “NIMA: Neural image assessment,”IEEE Trans. Image Process., vol. 27, no. 8, pp. 3998–4011, 2018
2018
-
[65]
A unified hdr imaging method with pixel and patch level,
Q. Yan, W. Chen, S. Zhang, Y . Zhu, J. Sun, and Y . Zhang, “A unified hdr imaging method with pixel and patch level,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 22 211–22 220
2023
-
[66]
Sensor-realistic synthetic data engine for multi-frame high dynamic range photography,
J. Hu, G. Choe, Z. Nadir, O. Nabil, S.-J. Lee, H. Sheikh, Y . Yoo, and M. Polley, “Sensor-realistic synthetic data engine for multi-frame high dynamic range photography,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2020, pp. 516–517
2020
-
[67]
Semantic masking with curriculum learning for robust HDR image reconstruction: Z. ni et al
Z. Ni, Y . Zhang, K. Ren, W. Yang, H. Wang, and S. Kwong, “Semantic masking with curriculum learning for robust HDR image reconstruction: Z. ni et al.”Int. J. Comput. Vis., vol. 133, no. 10, pp. 6896–6911, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.