Asymptotic Optimality of Thompson Sampling for Risk-Averse Bandits with Sub-Gaussian Rewards
Pith reviewed 2026-06-27 17:16 UTC · model grok-4.3
The pith
A nonparametric Thompson Sampling algorithm matches the instance-dependent regret lower bound for risk-averse bandits under any continuous risk functional on sub-Gaussian distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
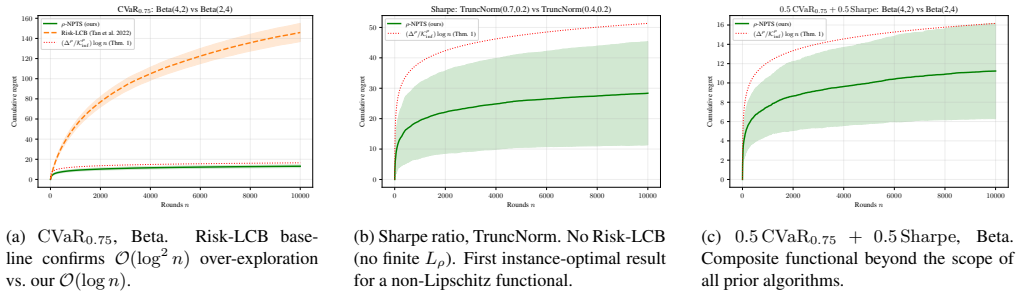
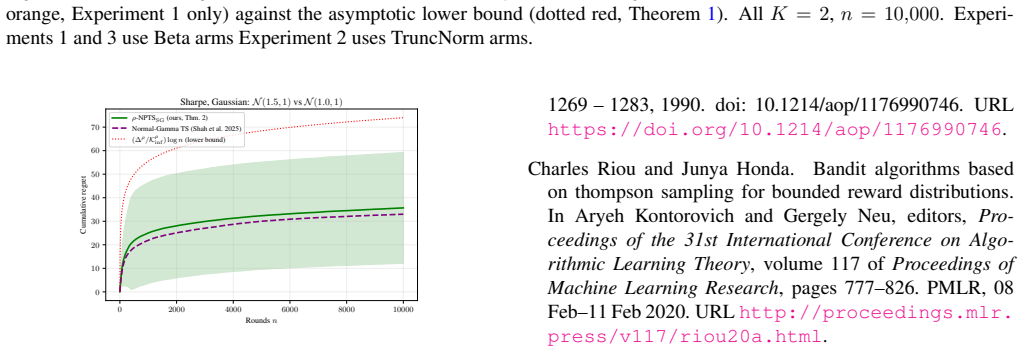
We prove that ρ-NPTS_SG achieves regret matching the instance-dependent lower bound to leading order in log n, establishing it as asymptotically optimal for any continuous risk functional ρ on the class of distributions with bounded density and sub-Gaussian tails, including Gaussian arms. Both this result and its bounded-support counterpart require only continuity of ρ: strictly weaker than the dominance condition of prior parametric Thompson Sampling results, and strictly weaker than the Lipschitz condition of UCB-type algorithms, yielding the first instance-optimal guarantees for non-Lipschitz functionals such as the Sharpe ratio without parametric reward assumptions. The key technical con
What carries the argument
The truncated discretisation lemma, which projects the growing-alphabet Dirichlet posterior onto a fixed grid via the Dirichlet aggregation property while keeping all polynomial prefactors of fixed degree independent of sample size.
If this is right
- The algorithm attains asymptotic optimality for CVaR, mean-variance, Sharpe ratio, and distortion risk measures on sub-Gaussian arms.
- Instance-optimal guarantees now hold for non-Lipschitz risk functionals without requiring parametric reward distributions.
- The same proof structure covers both the bounded-support case and the sub-Gaussian case.
- Only continuity of ρ is needed, removing the need for dominance or Lipschitz conditions used in earlier analyses.
Where Pith is reading between the lines
- The continuity-only condition may allow the same optimality result to apply to additional risk measures not previously analyzed.
- The discretisation technique could be adapted to other nonparametric bandit settings where the support grows with the number of observations.
- Practical risk-averse systems could adopt the algorithm directly without first verifying Lipschitz properties of their chosen risk measure.
Load-bearing premise
The risk functional must be continuous.
What would settle it
An explicit construction of a continuous risk functional and a family of sub-Gaussian distributions where the regret of ρ-NPTS_SG grows faster than the instance-dependent lower bound by more than lower-order terms in log n would falsify the asymptotic optimality claim.
Figures
read the original abstract
We prove that $\rho\text{-}\mathrm{NPTS}_{\mathrm{SG}}$, an anchor-free nonparametric Thompson Sampling algorithm for risk-averse bandits, achieves regret matching the instance-dependent lower bound to leading order in $\log n$, establishing it as asymptotically optimal for any continuous risk functional $\rho$ (CVaR, mean-variance, Sharpe ratio, distortion risk measures, and more) on the class of distributions with bounded density and sub-Gaussian tails, including Gaussian arms. Both this result and its bounded-support counterpart require only continuity of $\rho$: strictly weaker than the dominance condition of prior parametric Thompson Sampling results, and strictly weaker than the Lipschitz condition of UCB-type algorithms, yielding the first instance-optimal guarantees for non-Lipschitz functionals such as the Sharpe ratio without parametric reward assumptions. The bounded-support case is developed first as a stepping stone sharing the same proof structure. The key technical contributions are a discretisation lemma (bounded support) and a truncated discretisation lemma (sub-Gaussian tails), each projecting the growing-alphabet Dirichlet posterior onto a fixed grid via the Dirichlet aggregation property, holding all polynomial prefactors at fixed degree independent of sample size and breaking the super-exponential barrier that blocked prior proofs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proves that ρ-NPTS_SG, an anchor-free nonparametric Thompson Sampling algorithm, achieves regret matching the instance-dependent lower bound to leading order in log n for any continuous risk functional ρ (including CVaR, mean-variance, Sharpe ratio, and distortion risk measures) on the class of distributions with bounded density and sub-Gaussian tails. The bounded-support case is developed first, followed by the sub-Gaussian case; both rely only on continuity of ρ. The key technical tools are a discretization lemma (bounded support) and a truncated discretization lemma (sub-Gaussian tails) that project the growing-alphabet Dirichlet posterior onto a fixed grid via the Dirichlet aggregation property while keeping all polynomial prefactors of bounded degree independent of n.
Significance. If the result holds, the work establishes the first instance-optimal guarantees for non-Lipschitz risk functionals such as the Sharpe ratio without parametric reward assumptions or dominance/Lipschitz conditions on ρ. The discretization lemmas that control prefactors independently of sample size and break the super-exponential barrier constitute a clear technical advance over prior parametric Thompson Sampling analyses.
minor comments (2)
- The abstract states that the bounded-support case is a 'stepping stone' sharing the same proof structure; a brief forward reference to the section containing the truncated discretization lemma would help readers track the shared steps.
- Notation for the algorithm (ρ-NPTS_SG) and the risk functional ρ is introduced in the abstract without an immediate pointer to the formal definition; adding a parenthetical reference to the relevant section would improve readability.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, for highlighting the significance of the discretization lemmas and the instance-optimal guarantees for non-Lipschitz functionals such as the Sharpe ratio, and for recommending acceptance.
Circularity Check
No significant circularity
full rationale
The paper's derivation establishes asymptotic optimality via new discretization and truncated discretization lemmas that project the Dirichlet posterior onto a fixed grid using the Dirichlet aggregation property, with all polynomial prefactors of bounded degree independent of n. These lemmas are presented as original technical contributions that break the super-exponential barrier, directly supporting the regret bound matching the instance-dependent lower bound to leading order in log n under the sole assumption of continuity of ρ. No step reduces by construction to a fitted parameter, self-citation chain, ansatz smuggled via prior work, or renamed empirical pattern; the central claim retains independent content from the stated assumptions and lower bound.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The risk functional ρ is continuous.
- domain assumption Reward distributions have bounded density and sub-Gaussian tails.
Reference graph
Works this paper leans on
-
[1]
Ang, Ming Liang and Lim, Eloise Y. Y. and Chang, Joel Q. L. , year =. Thompson Sampling for. 2105.06960 , archivePrefix=
-
[2]
Order Optimal Regret Bounds for
Shah, Mohammad Taha and Khurshid, Sabrina and Ghatak, Gourab , year =. Order Optimal Regret Bounds for. 2508.13749 , archivePrefix=
-
[3]
Advances in Applied Mathematics , volume =
Asymptotically efficient adaptive allocation rules , author =. Advances in Applied Mathematics , volume =
-
[4]
Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI-ECAI) , year =
A Survey of Risk-Aware Multi-Armed Bandits , author =. Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI-ECAI) , year =
-
[5]
Chang, Joel Q. L. and Tan, Vincent Y. F. , booktitle =. A Unifying Theory of. 2022 , volume =
2022
-
[6]
A Bayesian Learning Automaton for Solving Two-Armed Bernoulli Bandit Problems , year=
Granmo, Ole-Christoffer , booktitle=. A Bayesian Learning Automaton for Solving Two-Armed Bernoulli Bandit Problems , year=
-
[7]
2012 , eprint=
Thompson Sampling: An Asymptotically Optimal Finite Time Analysis , author=. 2012 , eprint=
2012
-
[8]
2021 , eprint=
From Optimality to Robustness: Dirichlet Sampling Strategies in Stochastic Bandits , author=. 2021 , eprint=
2021
-
[9]
and Wiley, J
Huber, P.J. and Wiley, J. and InterScience, W. , biburl =
-
[10]
Halmos , title =
Paul R. Halmos , title =. Bulletin of the American Mathematical Society , number =. 1959 , doi =
1959
-
[11]
Theory of Probability and Its Applications , year=
Convergence of Random Processes and Limit Theorems in Probability Theory , author=. Theory of Probability and Its Applications , year=
-
[12]
, journal=
Posner, E. , journal=. Random coding strategies for minimum entropy , year=
-
[13]
Proceedings of the 31st Conference On Learning Theory , pages =
A General Approach to Multi-Armed Bandits Under Risk Criteria , author =. Proceedings of the 31st Conference On Learning Theory , pages =. 2018 , editor =
2018
-
[14]
Asymptotically efficient adaptive allocation rules , journal =. 1985 , issn =. doi:https://doi.org/10.1016/0196-8858(85)90002-8 , url =
-
[15]
Proceedings of the 25th Annual Conference on Learning Theory , pages =
Analysis of Thompson Sampling for the Multi-armed Bandit Problem , author =. Proceedings of the 25th Annual Conference on Learning Theory , pages =. 2012 , editor =
2012
-
[16]
Learning Bounds for Risk-sensitive Learning , url =
Lee, Jaeho and Park, Sejun and Shin, Jinwoo , booktitle =. Learning Bounds for Risk-sensitive Learning , url =
-
[17]
Continuous Mean-Covariance Bandits , year =
Yihan Du and Siwei Wang and Zhixuan Fang and Longbo Huang , booktitle =. Continuous Mean-Covariance Bandits , year =
-
[18]
Mean-variance and value at risk in multi-armed bandit problems , year=
Vakili, Sattar and Zhao, Qing , booktitle=. Mean-variance and value at risk in multi-armed bandit problems , year=
-
[19]
Proceedings of the 5th Asian Conference on Machine Learning , pages =
Exploration vs Exploitation vs Safety: Risk-Aware Multi-Armed Bandits , author =. Proceedings of the 5th Asian Conference on Machine Learning , pages =. 2013 , editor =
2013
-
[20]
2009 , publisher=
Large Deviations Techniques and Applications , author=. 2009 , publisher=
2009
-
[21]
Bernoulli , pages=
A large-deviation principle for Dirichlet posteriors , author=. Bernoulli , pages=. 2000 , publisher=
2000
-
[22]
Koolen and Sandeep Juneja , title =
Shubhada Agrawal and Wouter M. Koolen and Sandeep Juneja , title =. CoRR , volume =. 2020 , url =
2020
-
[23]
2021 , eprint=
Off-Policy Risk Assessment in Contextual Bandits , author=. 2021 , eprint=
2021
-
[24]
International Conference on Machine Learning , pages=
Thompson Sampling Algorithms for Mean-Variance Bandits , author=. International Conference on Machine Learning , pages=
-
[25]
Advances in Neural Information Processing Systems , pages=
Risk-aversion in multi-armed bandits , author=. Advances in Neural Information Processing Systems , pages=
-
[26]
Distributionally-Aware Exploration for
Tamkin, Alex and Keramati, Ramtin and Dann, Christoph and Brunskill, Emma , booktitle=. Distributionally-Aware Exploration for
-
[27]
A revised approach for risk-averse multi-armed bandits under CVaR criterion , journal =
Najakorn Khajonchotpanya and Yilin Xue and Napat Rujeerapaiboon , keywords =. A revised approach for risk-averse multi-armed bandits under CVaR criterion , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.orl.2021.05.005 , url =
-
[28]
Proceedings of the 38th International Conference on Machine Learning , pages =
Optimal Thompson Sampling strategies for support-aware CVaR bandits , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[29]
2021 , eprint=
Risk-Constrained Thompson Sampling for CVaR Bandits , author=. 2021 , eprint=
2021
-
[30]
Mathematical Finance , volume=
Coherent measures of risk , author=. Mathematical Finance , volume=. 1999 , publisher=
1999
-
[31]
Proceedings of the 31st International Conference on Algorithmic Learning Theory , pages =
Bandit Algorithms Based on Thompson Sampling for Bounded Reward Distributions , author =. Proceedings of the 31st International Conference on Algorithmic Learning Theory , pages =. 2020 , editor =
2020
-
[32]
Premium Calculation by Transforming the Layer Premium Density , volume=
Wang, Shaun , year=. Premium Calculation by Transforming the Layer Premium Density , volume=. ASTIN Bulletin , publisher=. doi:10.2143/AST.26.1.563234 , number=
-
[33]
Mathematics of Operations Research , volume =
Garivier, Aur\'elien and M\'enard, Pierre and Stoltz, Gilles , title =. Mathematics of Operations Research , volume =. 2019 , doi =. https://doi.org/10.1287/moor.2017.0928 , abstract =
-
[34]
Biometrika , volume=
On the likelihood that one unknown probability exceeds another in view of the evidence of two samples , author=. Biometrika , volume=. 1933 , publisher=
1933
-
[35]
On the lookback distortion risk measure: theory and applications , volume =
Hürlimann, Werner , year =. On the lookback distortion risk measure: theory and applications , volume =
-
[36]
Massart , title =
P. Massart , title =. The Annals of Probability , number =. 1990 , doi =
1990
-
[37]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[38]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[39]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[40]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[41]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[42]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[43]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[44]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[45]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[46]
2008 , eprint=
Crime and punishment in scientific research , author=. 2008 , eprint=
2008
-
[47]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.