See More, Match Better: Multi-Source Feature Fusion for Two-View Correspondence Learning
Pith reviewed 2026-06-27 17:08 UTC · model grok-4.3
The pith
TriMatch fuses geometric features with texture and structural semantics to suppress pseudo-consistent outliers in two-view matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
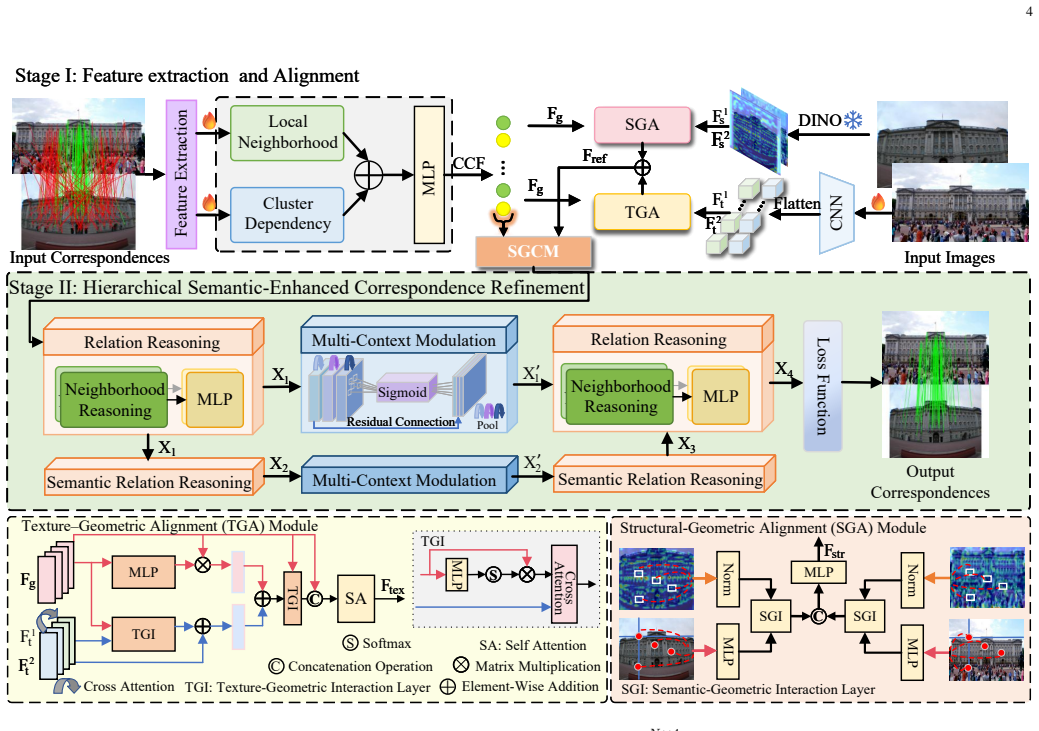
TriMatch is a two-part multi-source fusion pipeline: feature extraction jointly pulls geometric, texture semantic, and structural semantic descriptors; Texture-Geometric Alignment and Structural-Geometric Alignment modules close the representation gap; a Semantic-Guided Correspondence Modulation module then uses the aligned semantics to suppress geometrically plausible yet semantically inconsistent matches; Hierarchical Semantic-Enhanced Correspondence Refinement progressively models dependencies and recalibrates multi-context responses for final discrimination.
What carries the argument
TriMatch framework whose Texture-Geometric Alignment, Structural-Geometric Alignment, and Semantic-Guided Correspondence Modulation modules integrate the three feature sources to modulate geometric responses with semantic consistency checks.
If this is right
- Correspondence classifiers become more robust to scenes with locally similar geometric patterns.
- Downstream structure-from-motion pipelines receive cleaner initial matches without extra RANSAC iterations.
- The same alignment-plus-modulation pattern can be inserted into existing correspondence networks.
- Hierarchical refinement allows progressive incorporation of context at multiple scales.
Where Pith is reading between the lines
- The method may generalize to multi-view settings if the same semantic modulation is applied across more than two images.
- If semantic alignment proves stable, similar fusion could help other geometric tasks such as optical flow in low-texture areas.
- Performance gains would likely shrink on datasets where semantic labels themselves are noisy or ambiguous.
- Replacing the alignment modules with learned cross-attention could be a direct next experiment.
Load-bearing premise
Semantic features extracted from the images can be aligned to geometric features reliably enough that the modulation step consistently removes geometrically plausible but semantically wrong matches even in repetitive or textureless scenes.
What would settle it
A controlled test on image pairs containing repetitive patterns or large textureless regions where TriMatch shows no gain in inlier precision or recall over a geometric-only baseline.
Figures

read the original abstract
Two-view correspondence learning aims to distinguish true correspondences (inliers) from false ones (outliers) in image pairs by leveraging their underlying differences. Existing methods mainly rely on coordinate-based geometric consistency. However, they often struggle with pseudo-consistent outliers in scenes containing repetitive structures, textureless regions, or locally similar geometric patterns. To address this limitation, we propose TriMatch, a multi-source feature fusion framework for two-view correspondence learning, which consists of two parts: feature extraction and feature refinement. In feature extraction, TriMatch jointly extracts geometric, texture semantic, and structural semantic features to provide complementary evidence for correspondence discrimination. To bridge the gap between semantic and geometric features, texture and structural semantic features are aligned with geometric features through dedicated Texture-Geometric Alignment and Structural-Geometric Alignment modules, respectively. We further introduce a Semantic-Guided Correspondence Modulation module, which modulates geometric features using semantic information to suppress geometrically plausible but semantically inconsistent correspondences. In feature refinement, a Hierarchical Semantic-Enhanced Correspondence Refinement strategy progressively models correspondence dependencies and recalibrates multi-context feature responses, enabling more reliable inlier-outlier discrimination. Extensive experiments demonstrate the effectiveness, robustness, and generalization capability of TriMatch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TriMatch, a multi-source feature fusion framework for two-view correspondence learning consisting of feature extraction and refinement stages. In extraction, it jointly extracts geometric, texture semantic, and structural semantic features; aligns the semantic features to geometric ones via Texture-Geometric Alignment and Structural-Geometric Alignment modules; and applies Semantic-Guided Correspondence Modulation to suppress geometrically plausible but semantically inconsistent matches. Refinement uses a Hierarchical Semantic-Enhanced Correspondence Refinement strategy. The central claim is that these components supply complementary semantic evidence that geometric consistency alone cannot provide, improving robustness in scenes with repetitive structures, textureless regions, or locally similar patterns.
Significance. If the experimental validation holds, the work offers a practical engineering response to documented failure modes of coordinate-based geometric methods. By explicitly fusing and aligning multiple feature sources, it could improve inlier-outlier discrimination for downstream tasks such as structure-from-motion and stereo matching. The modular design and progressive refinement strategy are clearly motivated by the target failure cases.
major comments (2)
- [§3] §3 (Framework description): the claim that Texture-Geometric Alignment and Structural-Geometric Alignment modules reliably bridge semantic and geometric features rests on the unexamined assumption that these features can be aligned without introducing new inconsistencies; no formulation of the alignment objective, loss terms, or architectural details is supplied to show how complementarity is enforced.
- [§3] §3 (Semantic-Guided Correspondence Modulation): the assertion that semantic modulation suppresses pseudo-consistent outliers in repetitive or textureless scenes is load-bearing for the central contribution, yet the description provides no mechanism (e.g., attention weights, gating function, or modulation equation) or targeted failure-case analysis to substantiate consistent suppression.
minor comments (2)
- [Abstract] The abstract states that 'extensive experiments demonstrate' effectiveness but the provided text contains no quantitative results, ablation tables, or dataset-specific metrics; these must be added with explicit comparisons to prior geometric-only baselines.
- Notation for the three feature types (geometric, texture semantic, structural semantic) is introduced without a consistent symbol table or diagram showing their dimensionalities and fusion points.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that Section 3 requires additional technical detail on the alignment and modulation modules to substantiate the claims. We will revise the paper accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Framework description): the claim that Texture-Geometric Alignment and Structural-Geometric Alignment modules reliably bridge semantic and geometric features rests on the unexamined assumption that these features can be aligned without introducing new inconsistencies; no formulation of the alignment objective, loss terms, or architectural details is supplied to show how complementarity is enforced.
Authors: We agree that the current manuscript description in §3 is insufficient. In the revised version we will supply the explicit alignment objectives, the loss terms used to enforce complementarity between semantic and geometric features, and the full architectural specifications of both the Texture-Geometric Alignment and Structural-Geometric Alignment modules, including how potential inconsistencies are avoided during alignment. revision: yes
-
Referee: [§3] §3 (Semantic-Guided Correspondence Modulation): the assertion that semantic modulation suppresses pseudo-consistent outliers in repetitive or textureless scenes is load-bearing for the central contribution, yet the description provides no mechanism (e.g., attention weights, gating function, or modulation equation) or targeted failure-case analysis to substantiate consistent suppression.
Authors: We acknowledge that the mechanism and supporting analysis are not adequately detailed. The revision will include the precise modulation equation, the formulation of any attention weights or gating functions inside the Semantic-Guided Correspondence Modulation module, and a targeted evaluation on the specific failure cases (repetitive structures, textureless regions) to demonstrate consistent suppression of pseudo-consistent outliers. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes an empirical neural architecture (TriMatch) consisting of feature extraction modules (Texture-Geometric Alignment, Structural-Geometric Alignment, Semantic-Guided Correspondence Modulation) and a refinement strategy. No equations, fitted parameters, predictions, or derivations are described in the provided text. The central claim is an engineering response to known failure modes of geometric-only methods, with value to be assessed via experiments rather than formal reduction to inputs. No self-citation chains, self-definitional steps, or ansatzes appear. The method is self-contained as an architectural design without load-bearing circular elements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic features provide complementary evidence to geometric features for distinguishing inliers from outliers.
invented entities (3)
-
Texture-Geometric Alignment module
no independent evidence
-
Structural-Geometric Alignment module
no independent evidence
-
Semantic-Guided Correspondence Modulation module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Modeling the world from internet photo collections,
N. Snavely, S. M. Seitz, and R. Szeliski, “Modeling the world from internet photo collections,”International Journal of Computer Vision, vol. 80, no. 2, pp. 189–210, 2008
2008
-
[2]
Structure-from-motion revisited,
J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4104–4113
2016
-
[3]
Benchmarking 6dof outdoor visual localization in changing conditions,
T. Sattler, W. Maddern, C. Toft, A. Torii, L. Hammarstrand, E. Stenborg, D. Safari, M. Okutomi, M. Pollefeys, J. Sivicet al., “Benchmarking 6dof outdoor visual localization in changing conditions,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8601–8610
2018
-
[4]
Epm-net: Efficient feature extraction, point-pair feature matching for robust 6-d pose estimation,
J. Zhang, J. Shi, D. Zou, X. Shu, S. Bai, J. Lu, H. Zhu, J. Ni, and Y . Sun, “Epm-net: Efficient feature extraction, point-pair feature matching for robust 6-d pose estimation,”IEEE Transactions on Multimedia, vol. 26, pp. 5120–5130, 2023
2023
-
[5]
Computational intelligence in remote sensing image registration: A survey,
Y . Wu, J.-W. Liu, C.-Z. Zhu, Z.-F. Bai, Q.-G. Miao, W.-P. Ma, and M.-G. Gong, “Computational intelligence in remote sensing image registration: A survey,”International Journal of Automation and Computing, vol. 18, no. 1, pp. 1–17, 2021
2021
-
[6]
Robust feature matching via graph neighborhood motion consensus,
J. Huang, H. Li, Y . Gong, F. Fan, Y . Ma, Q. Du, and J. Ma, “Robust feature matching via graph neighborhood motion consensus,”IEEE Transactions on Multimedia, vol. 26, pp. 9790–9803, 2024
2024
-
[7]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110, 2004
2004
-
[8]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 224–236
2018
-
[9]
Learn- ing to find good correspondences,
K. M. Yi, E. Trulls, Y . Ono, V . Lepetit, M. Salzmann, and P. Fua, “Learn- ing to find good correspondences,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 2666–2674
2018
-
[10]
Learning two-view correspondences and geometry using order-aware network,
J. Zhang, D. Sun, Z. Luo, A. Yao, L. Zhou, T. Shen, Y . Chen, L. Quan, and H. Liao, “Learning two-view correspondences and geometry using order-aware network,”arXiv, 2019
2019
-
[11]
Superglue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superglue: Learning feature matching with graph neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2020, pp. 4938–4947
2020
-
[12]
Progressive correspondence pruning by consensus learning,
C. Zhao, Y . Ge, F. Zhu, R. Zhao, H. Li, and M. Salzmann, “Progressive correspondence pruning by consensus learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6464–6473
2021
-
[13]
Ms2dg-net: Progressive correspondence learning via multiple sparse semantics dynamic graph,
L. Dai, Y . Liu, J. Ma, L. Wei, T. Lai, C. Yang, and R. Chen, “Ms2dg-net: Progressive correspondence learning via multiple sparse semantics dynamic graph,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8973–8982
2022
-
[14]
Ncmnet: Neighbor consistency mining network for two-view correspondence pruning,
X. Liu, R. Qin, J. Yan, and J. Yang, “Ncmnet: Neighbor consistency mining network for two-view correspondence pruning,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[15]
Mgnet: Learning corre- spondences via multiple graphs,
D. Luanyuan, X. Du, H. Zhang, and J. Tang, “Mgnet: Learning corre- spondences via multiple graphs,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 4, 2024, pp. 3945–3953
2024
-
[16]
Bclnet: Bilateral consensus learning for two-view correspondence pruning,
X. Miao, G. Xiao, S. Wang, and J. Yu, “Bclnet: Bilateral consensus learning for two-view correspondence pruning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 5, 2024, pp. 4225–4232
2024
-
[17]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[18]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[20]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,
M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,”Commun. ACM, vol. 24, no. 6, pp. 381–395, 1981
1981
-
[21]
Matching with prosac-progressive sample consensus,
O. Chum and J. Matas, “Matching with prosac-progressive sample consensus,” in2005 IEEE computer society Conference on Computer Vision and Pattern Recognition, vol. 1. IEEE, 2005, pp. 220–226
2005
-
[22]
Usac: A universal framework for random sample consensus,
R. Raguram, O. Chum, M. Pollefeys, J. Matas, and J.-M. Frahm, “Usac: A universal framework for random sample consensus,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 2022–2038, 2012
2022
-
[23]
Magsac++, a fast, reliable and accurate robust estimator,
D. Barath, J. Noskova, M. Ivashechkin, and J. Matas, “Magsac++, a fast, reliable and accurate robust estimator,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 1304–1312
2020
-
[24]
Robust point matching via vector field consensus,
J. Ma, J. Zhao, J. Tian, A. L. Yuille, and Z. Tu, “Robust point matching via vector field consensus,”IEEE Transactions on Image Processing, vol. 23, no. 4, pp. 1706–1721, 2014
2014
-
[25]
Gms: Grid-based motion statistics for fast, ultra-robust feature correspondence,
J. Bian, W.-Y . Lin, Y . Matsushita, S.-K. Yeung, T.-D. Nguyen, and M.-M. Cheng, “Gms: Grid-based motion statistics for fast, ultra-robust feature correspondence,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4181–4190
2017
-
[26]
Locality preserving matching,
J. Ma, J. Zhao, J. Jiang, H. Zhou, and X. Guo, “Locality preserving matching,”International Journal of Computer Vision, vol. 127, no. 5, pp. 512–531, 2019
2019
-
[27]
Lmr: Learning a two- class classifier for mismatch removal,
J. Ma, X. Jiang, J. Jiang, J. Zhao, and X. Guo, “Lmr: Learning a two- class classifier for mismatch removal,”IEEE Transactions on Image Processing, vol. 28, no. 8, pp. 4045–4059, 2019
2019
-
[28]
Mining consistent correspon- dences using co-occurrence statistics,
G. Xiao, S. Wang, H. Wang, and J. Ma, “Mining consistent correspon- dences using co-occurrence statistics,”Pattern Recognition, vol. 119, p. 108062, 2021
2021
-
[29]
U-match: two-view correspondence learning with hierarchy-aware local context aggregation,
Z. Li, S. Zhang, and J. Ma, “U-match: two-view correspondence learning with hierarchy-aware local context aggregation,” inProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, 2023, pp. 1169–1176
2023
-
[30]
Progressive neighbor consistency mining for correspondence pruning,
X. Liu and J. Yang, “Progressive neighbor consistency mining for correspondence pruning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9527–9537
2023
-
[31]
Dhm-net: Deep hypergraph modeling for robust feature matching,
S. Chen, G. Xiao, J. Guo, Q. Wu, and J. Ma, “Dhm-net: Deep hypergraph modeling for robust feature matching,”IEEE Transactions on Image Processing, 2024
2024
-
[32]
Deep motion field consen- sus with learnable kernels for two-view correspondence learning,
Y . Lu, J. Le, Z. Li, Y . Yuan, and J. Ma, “Deep motion field consen- sus with learnable kernels for two-view correspondence learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 6, 2025, pp. 5829–5837. 8
2025
-
[33]
Dematch++: Two-view correspondence learning via deep motion field decomposition and respective local- context aggregation,
S. Zhang, Z. Li, and J. Ma, “Dematch++: Two-view correspondence learning via deep motion field decomposition and respective local- context aggregation,”IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2025
2025
-
[34]
Vsformer: Visual- spatial fusion transformer for correspondence pruning,
T. Liao, X. Zhang, L. Zhao, T. Wang, and G. Xiao, “Vsformer: Visual- spatial fusion transformer for correspondence pruning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 4, 2024, pp. 3369–3377
2024
-
[35]
A convnet for the 2020s,
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11 976–11 986
2022
-
[36]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9650–9660
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.