One Model, Multiple Goals: Adaptive Multi-Objective Learning for E-commerce Dialogue Systems
Pith reviewed 2026-06-27 16:40 UTC · model grok-4.3
The pith
MORE treats reasoning accuracy as optimization constraints to jointly improve decision-making and natural responses in e-commerce dialogues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
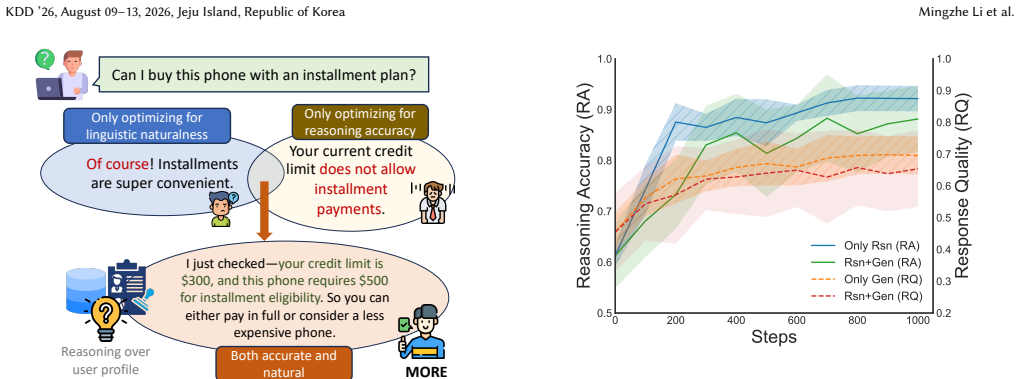
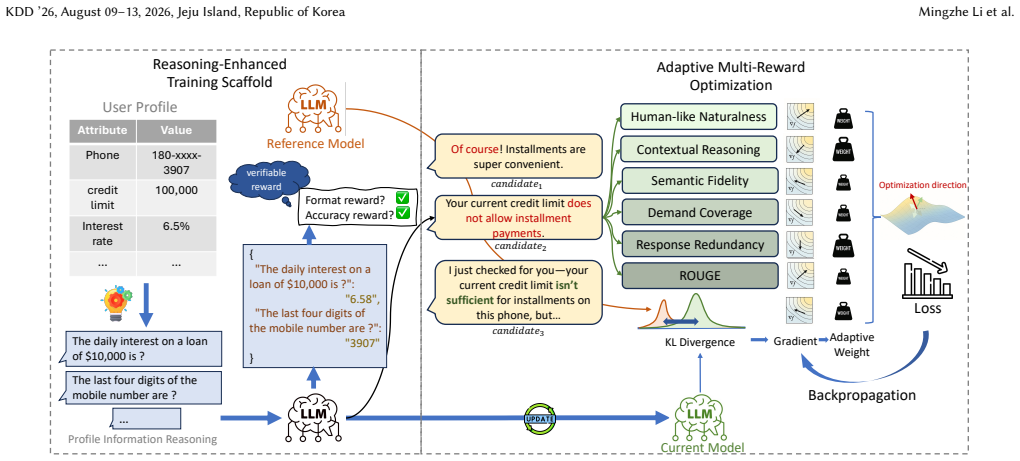
MORE jointly optimizes reasoning accuracy and linguistic naturalness by treating reasoning functions as constraints that guide policy optimization rather than mixing them into a single reward, combined with an adaptive multi-reward mechanism that dynamically reweights signals such as fluency and naturalness via gradient feedback. The resulting system generates natural responses directly at inference time while retaining benefits from the reasoning-enhanced training scaffold.
What carries the argument
Reasoning functions enforced as constraints on policy optimization, together with an adaptive multi-reward aggregator that reweights linguistic signals based on gradient feedback.
If this is right
- Improves overall conversion by 16.53 percent and reached conversion by 30.09 percent in 14-day online experiments on production traffic.
- Increases user satisfaction and reduces handoff rates to human agents.
- Recovers about 60 percent of the incremental conversion lift that human agents achieve over baselines.
- Outperforms strong baselines on two real-world ByteDance dialogue systems and on the MultiWOZ 2.2 benchmark.
Where Pith is reading between the lines
- The constraint formulation could extend to other dialogue domains that require hidden reasoning during training but direct generation at test time.
- Removing inference overhead positions the method for high-volume customer service where latency matters.
- Gradient-based reweighting of multiple rewards may stabilize training when objectives conflict in non-e-commerce settings.
Load-bearing premise
Treating reasoning functions strictly as constraints prevents oscillations and unstable learning when objectives have diverging dynamics.
What would settle it
An ablation that mixes reasoning and linguistic rewards directly into one objective, then measures whether learning remains stable and gains remain comparable in the same 14-day production traffic, would test the constraint approach.
Figures





read the original abstract
Dialogue systems in e-commerce scenarios often need to satisfy multiple objectives: accurately reasoning over user profiles (e.g., eligibility, credit limit) to ensure correct decision-making and user state interpretation, while also generating natural and faithful responses. These goals are complementary but not identical. In this work, we propose MORE, an adaptive Multi-Objective REinforcement learning framework that jointly optimizes reasoning accuracy and linguistic naturalness. Our preliminary experiments show that directly mixing rewards with diverging optimization dynamics can cause oscillations and unstable learning. Thus, instead of optimizing a single mixed reward, we treat reasoning functions as constraints that guide policy optimization. At inference time, the system directly generates responses without explicit reasoning steps, while still benefiting from reasoning-enhanced scaffold and avoiding additional inference overhead. To better balance linguistic objectives during response generation, we introduce an adaptive multi-reward mechanism that aggregates signals such as fluency and naturalness and dynamically reweighs them via gradient feedback. We evaluate MORE on two real-world dialogue systems at ByteDance and the MultiWOZ 2.2 benchmark, where it consistently outperforms strong baselines. In 14-day online experiments on ByteDance production traffic, MORE improves overall and reached conversion by 16.53% and 30.09%, while increasing user satisfaction and reducing handoff rates. Notably, in a human-machine comparison, MORE recovers about 60% of the incremental conversion lift achieved by human agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MORE, an adaptive multi-objective reinforcement learning framework for e-commerce dialogue systems. It jointly optimizes reasoning accuracy (treated as hard constraints) and linguistic naturalness (via an adaptive multi-reward aggregator that dynamically reweights signals such as fluency), avoiding direct reward mixing to prevent oscillations. At inference the model generates responses directly without explicit reasoning steps. Evaluations on ByteDance production systems and MultiWOZ 2.2 report consistent outperformance of baselines; 14-day online A/B tests show 16.53% and 30.09% lifts in overall and reached conversion, plus gains in satisfaction and reduced handoffs, recovering ~60% of the incremental lift from human agents.
Significance. If the production results and the constraint-based stability claim hold after proper validation, the work would offer a practical, deployable solution for multi-objective dialogue optimization in high-stakes e-commerce settings. The separation of reasoning constraints from linguistic rewards and the gradient-based adaptive aggregator address a real tension in production systems and could generalize beyond the reported domains.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): The central design decision to treat reasoning functions strictly as constraints (rather than mixing rewards) rests on the assertion that preliminary experiments showed oscillations and unstable learning, yet the manuscript supplies neither those experiments, an oscillation metric, nor any ablation comparing the two formulations across domains or reward scales. This is load-bearing for the claimed stability advantage.
- [§5] §5 (Online Experiments): The 14-day production A/B test results (16.53% overall conversion lift, 30.09% reached-conversion lift) are presented without statistical significance tests, confidence intervals, traffic volume, randomization details, or pre-registered metric definitions. These omissions prevent verification that the reported gains are attributable to the proposed constraint mechanism versus other unstated factors.
- [§4] §4 (Adaptive Multi-Reward): The adaptive reweighting mechanism is described at a high level via gradient feedback, but the manuscript lacks the explicit update rule or loss formulation (e.g., how weights are computed from per-objective gradients) and provides no sensitivity analysis or ablation on the reweighting hyperparameters.
minor comments (2)
- [§3] The inference-time claim that the model benefits from the reasoning scaffold without additional overhead would be clearer with a short diagram or pseudocode showing the training vs. inference pipelines.
- [§5] Table or figure captions for the MultiWOZ results should explicitly state the evaluation metrics (e.g., success rate, BLEU) and whether human or automatic judgments were used.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important areas for strengthening the manuscript's claims on stability, experimental rigor, and methodological transparency. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The central design decision to treat reasoning functions strictly as constraints (rather than mixing rewards) rests on the assertion that preliminary experiments showed oscillations and unstable learning, yet the manuscript supplies neither those experiments, an oscillation metric, nor any ablation comparing the two formulations across domains or reward scales. This is load-bearing for the claimed stability advantage.
Authors: We agree that the preliminary experiments and supporting metrics are essential to substantiate the stability claim and should have been included. In the revision we will add a dedicated subsection (or appendix) presenting the oscillation metrics (e.g., reward variance and policy gradient norm over training steps), the exact experimental setup, and a direct ablation comparing reward mixing versus the constraint formulation on both the ByteDance production data and MultiWOZ 2.2. This will make the design decision fully verifiable. revision: yes
-
Referee: [§5] §5 (Online Experiments): The 14-day production A/B test results (16.53% overall conversion lift, 30.09% reached-conversion lift) are presented without statistical significance tests, confidence intervals, traffic volume, randomization details, or pre-registered metric definitions. These omissions prevent verification that the reported gains are attributable to the proposed constraint mechanism versus other unstated factors.
Authors: We acknowledge the need for greater statistical transparency. The revised §5 will report p-values from appropriate significance tests, 95% confidence intervals, approximate daily traffic volume (aggregated to respect privacy constraints), randomization procedure, and the pre-registered metric definitions. While exact per-day traffic counts cannot be disclosed for proprietary reasons, the added information will allow readers to assess the reliability and attribution of the reported lifts. revision: partial
-
Referee: [§4] §4 (Adaptive Multi-Reward): The adaptive reweighting mechanism is described at a high level via gradient feedback, but the manuscript lacks the explicit update rule or loss formulation (e.g., how weights are computed from per-objective gradients) and provides no sensitivity analysis or ablation on the reweighting hyperparameters.
Authors: We will expand §4 with the precise mathematical formulation, including the gradient-based weight update rule and the composite loss expression. The revision will also add a sensitivity analysis table and ablation experiments varying the key reweighting hyperparameters, demonstrating robustness across the reported domains. revision: yes
Circularity Check
No circularity in claimed derivation or results
full rationale
The paper presents an empirical RL framework (MORE) motivated by preliminary experiments on reward mixing, with performance evaluated via production A/B tests and MultiWOZ. No mathematical derivations, equations, first-principles predictions, or load-bearing self-citations appear in the abstract or described content. The design choice to use constraints is justified by external (unshown) experiments rather than reducing to a self-referential definition or fitted input renamed as prediction. Central claims rest on external traffic data rather than any internal chain that collapses to inputs by construction. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thomas Back. 1994. Selective pressure in evolutionary algorithms: A charac- terization of selection mechanisms. InProceedings of the first IEEE conference on evolutionary computation. IEEE World Congress on Computational Intelligence. IEEE, 57–62
1994
-
[2]
Namo Bang, Jeehyun Lee, and Myoung-Wan Koo. 2023. Task-Optimized Adapters for an End-to-End Task-Oriented Dialogue System. InFindings of the Association for Computational Linguistics: ACL 2023. 7355–7369
2023
-
[3]
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gasic. 2018. MultiWOZ-A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 5016–5026
2018
- [4]
-
[5]
Jan Deriu, Alvaro Rodrigo, Arantxa Otegi, Guillermo Echegoyen, Sophie Rosset, Eneko Agirre, and Mark Cieliebak. 2021. Survey on evaluation methods for dialogue systems.Artificial Intelligence Review54, 1 (2021), 755–810
2021
-
[6]
Wenjie Dong, Sirong Chen, and Yan Yang. 2025. Protod: Proactive task-oriented dialogue system based on large language model. InProceedings of the 31st Inter- national Conference on Computational Linguistics. 9147–9164
2025
-
[7]
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. 2024. Kto: Model alignment as prospect theoretic optimization.ICML (2024)
2024
-
[8]
Yihao Feng, Shentao Yang, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, and Huan Wang. 2023. Fantastic Rewards and How to Tame Them: A Case Study on Reward Learning for Task-Oriented Dialogue Systems. InICLR
2023
-
[9]
Nikolaus Hansen and Andreas Ostermeier. 2001. Completely derandomized self-adaptation in evolution strategies.Evolutionary computation9, 2 (2001), 159–195
2001
-
[10]
Wanwei He, Yinpei Dai, Yinhe Zheng, Yuchuan Wu, Zheng Cao, Dermot Liu, Peng Jiang, Min Yang, Fei Huang, Luo Si, et al. 2022. Galaxy: A generative pre- trained model for task-oriented dialog with semi-supervised learning and explicit policy injection. InProceedings of the AAAI conference on artificial intelligence, Vol. 36. 10749–10757
2022
-
[11]
2010.Robust nonparametric statistical methods
Thomas P Hettmansperger and Joseph W McKean. 2010.Robust nonparametric statistical methods. CRC press
2010
-
[12]
Ehsan Hosseini-Asl, Bryan McCann, Chien-Sheng Wu, Semih Yavuz, and Richard Socher. 2020. A simple language model for task-oriented dialogue.Advances in Neural Information Processing Systems33 (2020), 20179–20191
2020
-
[13]
Natasha Jaques, Asma Ghandeharioun, Judy Hanwen Shen, Craig Ferguson, Agata Lapedriza, Noah Jones, Shixiang Gu, and Rosalind Picard. 2019. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog.arXiv preprint arXiv:1907.00456(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [14]
-
[15]
Wai-Chung Kwan, Hong-Ru Wang, Hui-Min Wang, and Kam-Fai Wong. 2023. A survey on recent advances and challenges in reinforcement learning methods for task-oriented dialogue policy learning.Machine Intelligence Research20, 3 (2023), 318–334
2023
-
[16]
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al
-
[17]
RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. InInternational Conference on Machine Learning. PMLR, 26874– 26901
-
[18]
Jiwei Li, Michel Galley, Chris Brockett, Georgios Spithourakis, Jianfeng Gao, and William B Dolan. 2016. A Persona-Based Neural Conversation Model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 994–1003
2016
-
[19]
Jiwei Li, Will Monroe, Tianlin Shi, Sebastien Jean, Alan Ritter, and Dan Jurafsky
-
[20]
Deep reinforcement learning for dialogue generation. InEMNLP
-
[21]
Mingzhe Li, Xiuying Chen, Jing Xiang, Qishen Zhang, Changsheng Ma, Chenchen Dai, Jinxiong Chang, Zhongyi Liu, and Guannan Zhang. 2024. Multi-Intent Attribute-Aware Text Matching in Searching. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 360–368
2024
-
[22]
Mingzhe Li, Jing Xiang, Qishen Zhang, Kaiyang Wan, and Xiuying Chen. 2025. Flipping knowledge distillation: Leveraging small models’ expertise to enhance llms in text matching. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 22218–22229
2025
-
[23]
Ye Liu, Wolfgang Maier, Wolfgang Minker, and Stefan Ultes. 2021. Naturalness Evaluation of Natural Language Generation in Task-oriented Dialogues Using BERT. InProceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021). 839–845
2021
-
[24]
Do June Min, Veronica Perez-Rosas, Kenneth Resnicow, and Rada Mihalcea
-
[25]
Dynamic reward adjustment in multi-reward reinforcement learning for counselor reflection generation.COLING(2024)
2024
-
[26]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
2002
-
[27]
Dimple Patil. 2024. Artificial intelligence in retail and e-commerce: Enhancing customer experience through personalization, predictive analytics, and real-time engagement.Predictive Analytics, And Real-Time Engagement (November 26, 2024) (2024)
2024
-
[28]
Baolin Peng, Xiujun Li, Lihong Li, Jianfeng Gao, Asli Celikyilmaz, Sungjin Lee, and Kam-Fai Wong. 2017. Composite Task-Completion Dialogue Policy Learning via Hierarchical Deep Reinforcement Learning. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2231–2240
2017
-
[29]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[30]
Vijay Mallik Reddy and Lakshmi Nivas Nalla. 2024. Personalization in e- commerce marketing: leveraging big data for tailored consumer engagement. Revista de Inteligencia Artificial en Medicina15, 1 (2024), 691–725
2024
-
[31]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[32]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Abigail See, Stephen Roller, Douwe Kiela, and Jason Weston. 2019. What makes a good conversation? How controllable attributes affect human judgments. In NAACL
2019
-
[34]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
2024
-
[35]
Weiyan Shi, Yu Li, Saurav Sahay, and Zhou Yu. 2021. Refine and Imitate: Reducing Repetition and Inconsistency in Persuasion Dialogues via Reinforcement Learn- ing and Human Demonstration. InFindings of the Association for Computational Linguistics: EMNLP 2021. 3478–3492
2021
-
[36]
Haoyu Song, Wei-Nan Zhang, Jingwen Hu, and Ting Liu. 2020. Generating per- sona consistent dialogues by exploiting natural language inference. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 8878–8885
2020
-
[37]
Zirui Song, Bin Yan, Yuhan Liu, Miao Fang, Mingzhe Li, Rui Yan, and Xiuying Chen. 2025. Injecting Domain-Specific Knowledge into Large Language Mod- els: A Comprehensive Survey. InFindings of the Association for Computational Linguistics: EMNLP 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Com...
2025
-
[38]
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback.Advances in neural information processing KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Mingzhe Li et al. systems33 (2020), 3008–3021
2020
-
[39]
Pei-Hao Su, Milica Gasic, Nikola Mrksic, Lina M Rojas-Barahona, Stefan Ultes, David Vandyke, Tsung-Hsien Wen, and Steve Young. 2016. On-line active reward learning for policy optimisation in spoken dialogue systems. InACL
2016
-
[40]
Haipeng Sun, Junwei Bao, Youzheng Wu, and Xiaodong He. 2023. Mars: Modeling Context & State Representations with Contrastive Learning for End-to-End Task- Oriented Dialog. InFindings of the Association for Computational Linguistics: ACL
2023
-
[41]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[42]
Heng-Da Xu, Xian-Ling Mao, Puhai Yang, Fanshu Sun, and He-Yan Huang. 2024. Rethinking task-oriented dialogue systems: From complex modularity to zero- shot autonomous agent. InProceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers). 2748–2763
2024
-
[43]
Shiquan Yang, Rui Zhang, Sarah Erfani, and Jey Han Lau. 2022. An Interpretable Neuro-Symbolic Reasoning Framework for Task-Oriented Dialogue Generation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 4918–4935
2022
-
[44]
Yunyi Yang, Yunhao Li, and Xiaojun Quan. 2021. Ubar: Towards fully end-to-end task-oriented dialog system with gpt-2. InProceedings of the AAAI conference on artificial intelligence, Vol. 35. 14230–14238
2021
-
[45]
Hongyi Yuan, Zheng Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. 2023. Rrhf: Rank responses to align language models with human feedback.Advances in Neural Information Processing Systems36 (2023), 10935– 10950
2023
-
[46]
Changshuo Zhang, Sirui Chen, Xiao Zhang, Sunhao Dai, Weijie Yu, and Jun Xu
- [47]
-
[48]
Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Personalizing dialogue agents: I have a dog, do you have pets too?. InACL
2018
-
[49]
Xiaoying Zhang, Baolin Peng, Kun Li, Jingyan Zhou, and Helen Meng. 2023. SGP-TOD: Building Task Bots Effortlessly via Schema-Guided LLM Prompting. InFindings of the Association for Computational Linguistics: EMNLP 2023. 13348– 13369
2023
-
[50]
If you have any questions, feel free to contact me
Zheng Zhang, Ryuichi Takanobu, Qi Zhu, MinLie Huang, and XiaoYan Zhu. 2020. Recent advances and challenges in task-oriented dialog systems.Science China Technological Sciences63, 10 (2020), 2011–2027. A Limitations WhileMOREdemonstrates strong performance in balancing multi- ple dialogue objectives, several limitations remain. First, our eval- uation is l...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.