Multi-Hop Knowledge Composition is Bound by Pretraining Exposure
Pith reviewed 2026-06-27 16:29 UTC · model grok-4.3
The pith
Large language models perform implicit multi-hop reasoning only on individuals that appeared in compositional contexts during pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Compositional failure on multi-hop questions persists at 97 percent one-hop accuracy and transfers to unseen questions only for individuals that appeared in compositional contexts during pretraining; no such transfer occurs for individuals absent from all compositional contexts, establishing exposure as a necessary condition.
What carries the argument
A strict experimental partition of individuals into those exposed versus never exposed to compositional contexts in pretraining data, followed by testing nine data-centric augmentation formats for transfer to unseen multi-hop questions.
If this is right
- Compositional pretraining data produces multi-hop capability that generalizes to new questions about the same individuals.
- The same data produces no multi-hop capability for individuals absent from compositional contexts.
- The gap is therefore a pretraining exposure issue rather than missing knowledge of the underlying facts.
- Multiple augmentation formats can be used to supply the missing compositional exposure.
Where Pith is reading between the lines
- Pretraining corpora could be filtered or augmented to increase the density of multi-entity sentences for better coverage of potential reasoning chains.
- Performance differences across models on real-world multi-hop tasks may partly reflect differences in how often their training data contained the relevant entity combinations.
- The same exposure requirement may apply to other forms of implicit composition such as temporal or causal chaining.
Load-bearing premise
The separation between exposed and unexposed individuals is complete, with no compositional patterns leaking into the unexposed group through any other part of the pretraining data.
What would settle it
Demonstrating reliable multi-hop performance on individuals verified to have zero appearances in any compositional pretraining contexts would falsify the necessity of such exposure.
Figures
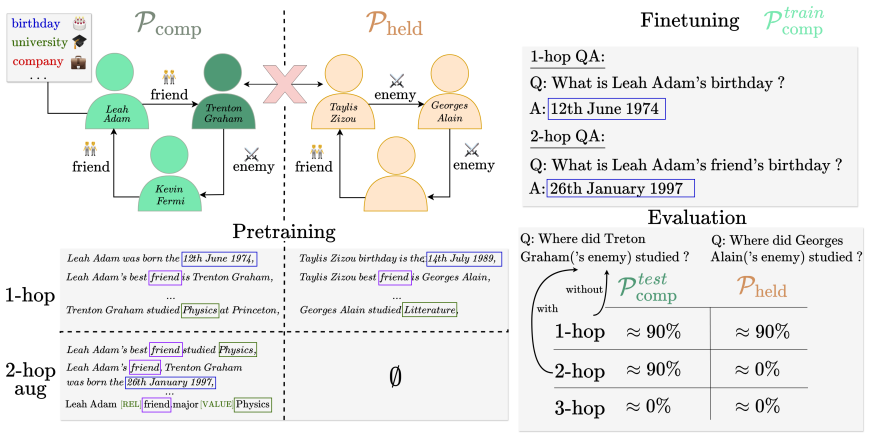
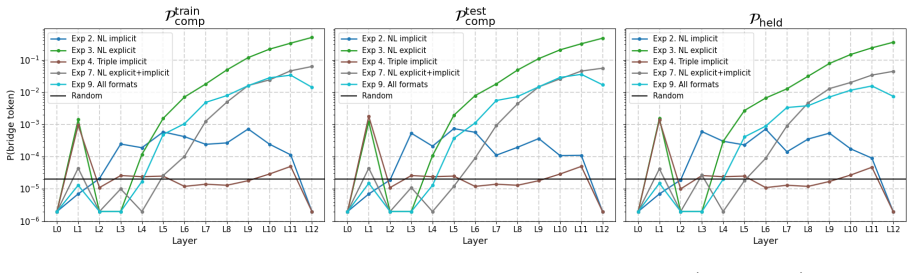
read the original abstract
Large Language Models fail at implicit multi-hop reasoning: a model answers "When was $X$ born?" and "Who is $Y$'s closest friend?" correctly but fails on "When was $Y$'s closest friend born?" in a single forward pass, even when both facts are perfectly memorized and individually retrievable. We study this failure in a controlled natural language setting with a strict separation between individuals exposed to compositional contexts during pretraining and those that never appear in any such context. We confirm that compositional failure persists even at 97% 1-hop accuracy, establishing the gap as a pretraining failure rather than a knowledge absence. We propose and test nine data-centric augmentation formats and find that compositional pretraining transfers to unseen questions for exposed individuals, but never to individuals absent from compositional pretraining, suggesting that exposure to compositional contexts during pretraining is a necessary condition for implicit multi-hop reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs fail at implicit multi-hop reasoning (e.g., combining two memorized facts in one forward pass) even at high 1-hop accuracy, and that this stems from lack of exposure to compositional contexts during pretraining rather than missing knowledge. In a controlled natural-language setting with strict separation between 'exposed' and 'unexposed' individuals, they report 97% 1-hop accuracy yet persistent multi-hop failure for the unexposed set; nine data-centric augmentation formats transfer to unseen questions only for exposed individuals, supporting the conclusion that pretraining exposure to compositional contexts is a necessary condition for implicit multi-hop reasoning.
Significance. If the separation and transfer results hold, the work would establish a data-centric bound on emergent reasoning capabilities, showing that multi-hop composition does not arise from general pretraining or individual fact memorization alone. The controlled natural-language design and differential transfer findings (exposed vs. unexposed) provide a clear empirical contrast that could guide future data-augmentation and pretraining studies.
major comments (1)
- [Abstract] Abstract and experimental setup: the necessity claim requires that the unexposed set had literally zero exposure to any multi-fact compositional patterns. The abstract asserts a 'strict separation' was enforced, but without a concrete description of the auditing procedure (e.g., how indirect linkages via lists, tables, or paraphrases were ruled out across the full pretraining corpus), it is impossible to confirm the separation is complete; any undetected leakage would reduce the result to a correlation rather than a necessity demonstration.
minor comments (1)
- [Abstract] The abstract states 'nine data-centric augmentation formats' without naming or categorizing them; a brief enumeration or pointer to a table/appendix would improve readability.
Simulated Author's Rebuttal
We thank the referee for identifying the need for explicit documentation of the separation procedure. We address the concern below and will revise the manuscript to strengthen the presentation of our controlled experimental design.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental setup: the necessity claim requires that the unexposed set had literally zero exposure to any multi-fact compositional patterns. The abstract asserts a 'strict separation' was enforced, but without a concrete description of the auditing procedure (e.g., how indirect linkages via lists, tables, or paraphrases were ruled out across the full pretraining corpus), it is impossible to confirm the separation is complete; any undetected leakage would reduce the result to a correlation rather than a necessity demonstration.
Authors: We agree that the manuscript would benefit from a more explicit description of how the strict separation was enforced. Our experiments are conducted in a fully controlled synthetic natural-language setting in which the pretraining corpus is generated from scratch; unexposed individuals are constructed by design to never appear in any multi-fact compositional contexts (including paraphrases, lists, tables, or other indirect linkages). We will revise the experimental setup section to provide the precise data-generation rules and verification steps used to guarantee this separation. Because the corpus is synthetic and fully specified by the authors, the separation is enforced at the point of data creation rather than through post-hoc auditing of an external pretraining corpus. revision: yes
Circularity Check
Empirical study with independent experimental validation
full rationale
The paper is an empirical investigation that measures multi-hop reasoning performance on held-out individuals after enforcing a separation in pretraining exposure. The necessity claim follows directly from the observed difference in outcomes between the two groups rather than from any definitional reduction, fitted parameter renamed as prediction, or self-citation chain. No equations appear in the provided text, and the experimental design (strict separation) is presented as a controllable variable whose enforcement is asserted rather than derived from prior self-citations. The result therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Individual facts are perfectly memorized and individually retrievable at 97 percent accuracy
- domain assumption The pretraining corpus allows a strict partition of individuals into those appearing in compositional contexts and those that never do
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Are emergent abilities of large language models a mirage? , author=. Advances in neural information processing systems , volume=
-
[2]
Jianlin Su and Murtadha H. M. Ahmed and Yu Lu and Shengfeng Pan and Wen Bo and Yunfeng Liu , bibsource =. doi:10.1016/J.NEUCOM.2023.127063 , journal =
-
[3]
Measuring and Narrowing the Compositionality Gap in Language Models
Ofir Press and Muru Zhang and Sewon Min and Ludwig Schmidt and Noah A. Smith and Mike Lewis , bibsource =. Measuring and Narrowing the Compositionality Gap in Language Models , url =. Findings of the Association for Computational Linguistics:. doi:10.18653/V1/2023.FINDINGS-EMNLP.378 , editor =
-
[4]
Wang, Xinyi and Tan, Shawn and Xu, Shenbo and Jin, Mingyu and Wang, William Yang and Panda, Rameswar and Shen, Yikang , journal =. Do
-
[5]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , bibsource =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS...
2022
-
[6]
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models , url =
Pan Lu and Baolin Peng and Hao Cheng and Michel Galley and Kai. Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models , url =. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , editor =
2023
-
[7]
Skills-in-Context: Unlocking Compositionality in Large Language Models , url =
Chen, Jiaao and Pan, Xiaoman and Yu, Dian and Song, Kaiqiang and Wang, Xiaoyang and Yu, Dong and Chen, Jianshu , bibsource =. Skills-in-Context: Unlocking Compositionality in Large Language Models , url =. Findings of the Association for Computational Linguistics:. doi:10.18653/V1/2024.FINDINGS-EMNLP.812 , editor =
-
[8]
Understanding and Patching Compositional Reasoning in
Li, Zhaoyi and Jiang, Gangwei and Xie, Hong and Song, Linqi and Lian, Defu and Wei, Ying , bibsource =. Understanding and Patching Compositional Reasoning in. Findings of the Association for Computational Linguistics,. doi:10.18653/V1/2024.FINDINGS-ACL.576 , editor =
-
[9]
Hopping Too Late: Exploring the Limitations of Large Language Models on Multi-Hop Queries , url =
Biran, Eden and Gottesman, Daniela and Yang, Sohee and Geva, Mor and Globerson, Amir , bibsource =. Hopping Too Late: Exploring the Limitations of Large Language Models on Multi-Hop Queries , url =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,. doi:10.18653/V1/2024.EMNLP-MAIN.781 , editor =
-
[10]
Towards a Mechanistic Interpretation of Multi-Step Reasoning Capabilities of Language Models , url =
Hou, Yifan and Li, Jiaoda and Fei, Yu and Stolfo, Alessandro and Zhou, Wangchunshu and Zeng, Guangtao and Bosselut, Antoine and Sachan, Mrinmaya , bibsource =. Towards a Mechanistic Interpretation of Multi-Step Reasoning Capabilities of Language Models , url =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,. doi:10...
-
[11]
Advances in Neural Information Processing Systems , volume=
How do Transformers Learn Implicit Reasoning? , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Grokking of Implicit Reasoning in Transformers:
Boshi Wang and Xiang Yue and Yu Su and Huan Sun , bibsource =. Grokking of Implicit Reasoning in Transformers:. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , editor =
2024
-
[13]
Understanding Reasoning Ability of Language Models From the Perspective of Reasoning Paths Aggregation , url =
Xinyi Wang and Alfonso Amayuelas and Kexun Zhang and Liangming Pan and Wenhu Chen and William Yang Wang , bibsource =. Understanding Reasoning Ability of Language Models From the Perspective of Reasoning Paths Aggregation , url =. Forty-first International Conference on Machine Learning,
-
[14]
Mikita Balesni and Tomasz Korbak and Owain Evans , bibsource =. The Two-Hop Curse:. CoRR , timestamp =. doi:10.48550/ARXIV.2411.16353 , eprint =
-
[15]
Physics of Language Models: Part 3.1, Knowledge Storage and Extraction , url =
Zeyuan Allen. Physics of Language Models: Part 3.1, Knowledge Storage and Extraction , url =. Forty-first International Conference on Machine Learning,
-
[16]
Xu, Zhuoyan and Shi, Zhenmei and Liang, Yingyu , bibsource =. Do Large Language Models Have Compositional Ability? An Investigation into Limitations and Scalability , url =. CoRR , timestamp =. doi:10.48550/ARXIV.2407.15720 , eprint =
-
[17]
Physics of Language Models: Part 3.2, Knowledge Manipulation , url =
Allen-Zhu, Zeyuan and Li, Yuanzhi , bibsource =. Physics of Language Models: Part 3.2, Knowledge Manipulation , url =. The Thirteenth International Conference on Learning Representations,
-
[18]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. The Tenth International Conference on Learning Representations,
-
[19]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[20]
Qiu, Z., Ou, Z., Wu, B., Li, J., Liu, A., and King, I
Petroni, Fabio and Rockt. Language Models as Knowledge Bases?. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1250
-
[21]
and Sifre, Laurent , title =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
2022
-
[22]
2020 , url =
nostalgebraist , title =. 2020 , url =
2020
-
[23]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Zhu, Hanlin and Huang, Baihe and Zhang, Shaolun and Jordan, Michael and Jiao, Jiantao and Tian, Yuandong and Russell, Stuart , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[24]
IEEE Transactions on Knowledge and Data Engineering , volume=
Unifying large language models and knowledge graphs: A roadmap , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2024 , publisher=
2024
-
[25]
2026 , url=
Ali Hatamizadeh and Syeda Nahida Akter and Shrimai Prabhumoye and Jan Kautz and Mostofa Patwary and Mohammad Shoeybi and Bryan Catanzaro and Yejin Choi , booktitle=. 2026 , url=
2026
-
[26]
The First Workshop on System-2 Reasoning at Scale, NeurIPS'24 , year=
Distilling System 2 into System 1 , author=. The First Workshop on System-2 Reasoning at Scale, NeurIPS'24 , year=
-
[27]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Wang, Xinyi and Amayuelas, Alfonso and Zhang, Kexun and Pan, Liangming and Chen, Wenhu and Wang, William Yang , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.