RT-SDGOD: Real-Time Single-Domain Generalized Object Detection
Pith reviewed 2026-06-27 16:46 UTC · model grok-4.3
The pith
Real-time detectors generalize across domains by training multiple queries to cover stable object evidence without any added inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
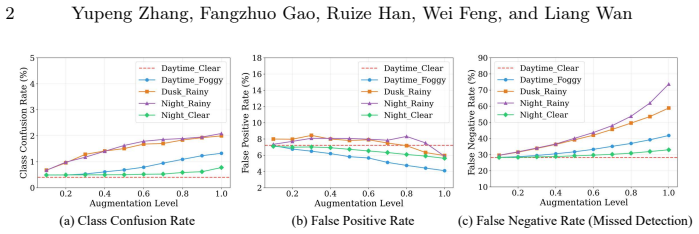
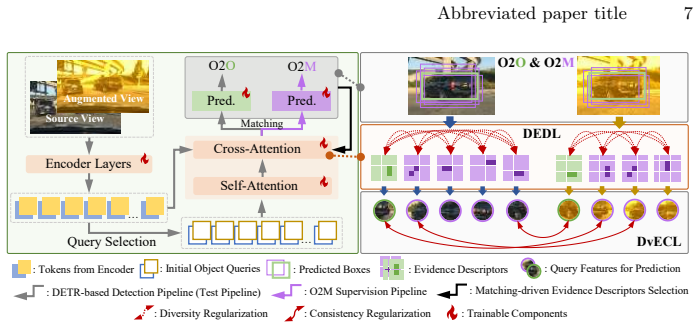
The paper establishes that DETR-based real-time detectors degrade under domain shift primarily via increased missed detections caused by limited and unstable object-level discriminative evidence. RT-SDGDet addresses this with a multi-evidence collaborative modeling framework: one-to-many supervision builds stable object-specific query groups, Discriminative Evidence Diversity Learning expands coverage of object evidence, and Dual-view Evidence Consistency Learning improves stability across views. All additions occur only at training time, so inference overhead remains zero while generalization improves on multiple unseen target domains.
What carries the argument
Multi-evidence collaborative modeling framework that uses one-to-many supervision to form stable object-specific query groups, plus DEDL for evidence diversity and DvECL for evidence consistency under perturbations.
If this is right
- Real-time detectors achieve higher accuracy on unseen domains while preserving original inference speed.
- Missed detections fall because object evidence coverage widens and remains consistent across appearance changes.
- The method applies to existing DETR-based real-time architectures without architecture changes at deployment.
- Generalization gains hold across multiple distinct target domains without any target data used in training.
Where Pith is reading between the lines
- The same training-only evidence stabilization might transfer to other real-time vision tasks that suffer domain shift, such as segmentation or tracking.
- If the query-grouping idea scales, it could reduce reliance on expensive domain adaptation pipelines that require target-domain samples.
- Designers of new real-time detectors could adopt these training losses as a default robustness layer when target conditions are unknown.
Load-bearing premise
Domain shift mainly increases missed detections because object evidence is limited and unstable, and training-time multi-query collaboration can expand and stabilize that evidence without harming real-time speed.
What would settle it
Run the detector on shifted domains and count missed detections with and without the training components; if missed detections do not drop or if measured inference latency rises, the claim is false.
Figures



read the original abstract
In real-world deployment under strict real-time constraints, weather and imaging variations induce significant distribution shifts, severely degrading detectors. Single-Domain Generalized Object Detection aims to mitigate this issue, yet existing methods rarely investigate-at the level of problem formulation-the generalization capability of real-time detectors under such constrained inference budgets. To this end, we introduce Real-Time Single-Domain Generalized Object Detection (RT-SDGOD), which focuses on how real-time detectors can achieve cross-domain generalization under zero extra inference overhead by relying solely on training-time representation learning. We observe that, under domain shift, DETR-based real-time detectors mainly degrade through increased missed detections, rooted in limited and unstable object-level discriminative evidence. Based on this, we propose RT-SDGDet, a multi-evidence collaborative modeling framework for RT-SDGOD. The core idea is to enable multiple queries of the same object to collaboratively cover more sufficient discriminative evidence while maintaining the stability of such evidence modeling across views. Specifically, we use one-to-many (O2M) supervision to construct stable object-specific query groups, and further design Discriminative Evidence Diversity Learning (DEDL) and Dual-view Evidence Consistency Learning (DvECL) to expand object-level evidence coverage and improve evidence stability under appearance perturbations, respectively. Since all components are introduced only during training, our method incurs no extra inference overhead. Extensive experiments show that the proposed method achieves better generalization performance than existing approaches across multiple unseen target domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the RT-SDGOD setting for real-time object detectors under domain shift and proposes RT-SDGDet, a training-only framework that uses one-to-many (O2M) supervision to form stable query groups, plus Discriminative Evidence Diversity Learning (DEDL) and Dual-view Evidence Consistency Learning (DvECL) to expand and stabilize object-level evidence. It claims that DETR-based real-time detectors degrade primarily via increased missed detections under shift, that the proposed components directly mitigate this without side effects, and that the resulting model outperforms prior approaches on multiple unseen target domains while incurring zero extra inference cost.
Significance. If the mechanistic claims and quantitative gains are substantiated, the work would be significant for practical deployment of real-time detectors in variable conditions, as it targets the inference-budget constraint explicitly and avoids test-time adaptation overhead. The training-only design and focus on evidence coverage are potentially useful contributions if supported by targeted ablations and error breakdowns.
major comments (3)
- [Abstract, §1] Abstract and §1: The central observation that degradation occurs 'mainly' through increased missed detections (rather than precision loss or localization error) is stated without any supporting quantitative breakdown of error types (FN vs. FP vs. box regression) on target domains; this is load-bearing for the subsequent design of O2M+DEDL+DvECL.
- [§3, §4] §3 and §4: No ablation isolates the contribution of DEDL and DvECL from the O2M supervision itself, nor measures 'evidence coverage' or 'stability' directly (e.g., via query-feature variance or positive-match cardinality); without these, it is unclear whether the reported gains stem from the proposed mechanisms or from generic regularization or training schedule changes.
- [§5] §5 (experiments): The abstract asserts 'better generalization performance than existing approaches' but supplies no numerical results, baselines, mAP deltas, or error bars; the full experimental section must provide these with statistical detail to substantiate the claim that the method secures the stated generalization benefit.
minor comments (2)
- [Abstract] Abstract contains a typographical issue: 'investigate-at the level' should be 'investigate at the level'.
- [§3] Notation for the proposed losses (DEDL, DvECL) and their weighting hyperparameters should be introduced with explicit equations in §3 before being referenced in the experimental protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the supporting evidence, ablations, and experimental reporting.
read point-by-point responses
-
Referee: [Abstract, §1] Abstract and §1: The central observation that degradation occurs 'mainly' through increased missed detections (rather than precision loss or localization error) is stated without any supporting quantitative breakdown of error types (FN vs. FP vs. box regression) on target domains; this is load-bearing for the subsequent design of O2M+DEDL+DvECL.
Authors: We agree that a quantitative breakdown of error types is necessary to support the central claim. In the revised manuscript we will add tables and analysis breaking down false negatives, false positives, and localization errors on the unseen target domains, confirming that missed detections are the dominant source of degradation. revision: yes
-
Referee: [§3, §4] §3 and §4: No ablation isolates the contribution of DEDL and DvECL from the O2M supervision itself, nor measures 'evidence coverage' or 'stability' directly (e.g., via query-feature variance or positive-match cardinality); without these, it is unclear whether the reported gains stem from the proposed mechanisms or from generic regularization or training schedule changes.
Authors: We acknowledge the need for component-wise isolation and direct mechanism measurements. The revised version will include new ablations that evaluate O2M alone, then add DEDL, then add DvECL, plus quantitative metrics for evidence coverage (e.g., positive-match cardinality) and stability (e.g., query-feature variance across views) to demonstrate that gains arise from the proposed mechanisms rather than generic effects. revision: yes
-
Referee: [§5] §5 (experiments): The abstract asserts 'better generalization performance than existing approaches' but supplies no numerical results, baselines, mAP deltas, or error bars; the full experimental section must provide these with statistical detail to substantiate the claim that the method secures the stated generalization benefit.
Authors: The full experimental section already reports mAP comparisons against baselines across multiple unseen domains. To fully address the request we will augment the section with explicit mAP deltas, error bars from multiple random seeds, and statistical significance tests in the revised manuscript. revision: yes
Circularity Check
No circularity: derivation chain is self-contained
full rationale
The paper states an empirical observation about degradation modes under domain shift and introduces new training-only components (O2M supervision, DEDL, DvECL) to address it. No equations, fitted parameters, or predictions are described that reduce by construction to the inputs or target metrics. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim rests on the proposed training additions and experimental results rather than any definitional or statistical equivalence to prior fitted quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Vidit, V., Engilberge, M., Salzmann, M.: Clip the gap: A single domain generaliza- tion approach for object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3219–3229 (2023) 2, 4
2023
-
[2]
arXiv preprint arXiv:2504.19574 (2025) 2, 4
Hwang, S., Han, D., Jeon, M.: Dg-detr: Toward domain generalized detection trans- former. arXiv preprint arXiv:2504.19574 (2025) 2, 4
-
[3]
In: Proceed- ingsoftheAAAIConferenceonArtificialIntelligence.vol.38,pp.5958–5966(2024) 2, 4
Wu, F., Gao, J., Hong, L., Wang, X., Zhou, C., Ye, N.: G-nas: Generalizable neural architecture search for single domain generalization object detection. In: Proceed- ingsoftheAAAIConferenceonArtificialIntelligence.vol.38,pp.5958–5966(2024) 2, 4
2024
-
[4]
arXiv preprint arXiv:2504.20498 (2025) 2, 4
Han, J., Wang, Y., Chen, L.: Style-adaptive detection transformer for single-source domain generalized object detection. arXiv preprint arXiv:2504.20498 (2025) 2, 4
-
[5]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 779–788 (2016) 4
2016
-
[6]
YOLOv12: Attention-Centric Real-Time Object Detectors
Tian, Y., Ye, Q., Doermann, D.: Yolov12: Attention-centric real-time object detec- tors. arXiv preprint arXiv:2502.12524 (2025) 4, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2506.17733 (2025) 4, 10
Lei, M., Li, S., Wu, Y., Hu, H., Zhou, Y., Zheng, X., Ding, G., Du, S., Wu, Z., Gao, Y.: Yolov13: Real-time object detection with hypergraph-enhanced adaptive visual perception. arXiv preprint arXiv:2506.17733 (2025) 4, 10
-
[8]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020) 4, 6
2020
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: Detrs beat yolos on real-time object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16965–16974 (2024) 4
2024
-
[10]
arXiv:2407.17140 [cs.CV] https://arxiv.org/abs/2407.17140 Paul C
Lv, W., Zhao, Y., Chang, Q., Huang, K., Wang, G., Liu, Y.: Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer. arXiv preprint arXiv:2407.17140 (2024) 4
-
[11]
In: 2025 IEEE/CVF Winter Confer- ence on Applications of Computer Vision (WACV)
Wang, S., Xia, C., Lv, F., Shi, Y.: Rt-detrv3: Real-time end-to-end object detection with hierarchical dense positive supervision. In: 2025 IEEE/CVF Winter Confer- ence on Applications of Computer Vision (WACV). pp. 1628–1636. IEEE (2025) 4, 10
2025
-
[12]
Liao, Z., Zhao, Y., Shan, X., Yan, Y., Liu, C., Lu, L., Ji, X., Chen, J.: Rt-detrv4: Painlessly furthering real-time object detection with vision foundation models. arXiv preprint arXiv:2510.25257 (2025) 4, 10 16 Yupeng Zhang, Fangzhuo Gao, Ruize Han, Wei Feng, and Liang Wan
-
[13]
arXiv preprint arXiv:2406.03459 (2024) 4, 10
Chen, Q., Su, X., Zhang, X., Wang, J., Chen, J., Shen, Y., Han, C., Chen, Z., Xu, W., Li, F., et al.: Lw-detr: A transformer replacement to yolo for real-time detection. arXiv preprint arXiv:2406.03459 (2024) 4, 10
-
[14]
arXiv preprint arXiv:2410.13842 (2024) 4, 10
Peng, Y., Li, H., Wu, P., Zhang, Y., Sun, X., Wu, F.: D-fine: Redefine re- gression task in detrs as fine-grained distribution refinement. arXiv preprint arXiv:2410.13842 (2024) 4, 10
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Huang, S., Lu, Z., Cun, X., Yu, Y., Zhou, X., Shen, X.: Deim: Detr with improved matching for fast convergence. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15162–15171 (2025) 4, 10
2025
-
[16]
arXiv preprint arXiv:2509.20787 (2025) 4, 10
Huang, S., Hou, Y., Liu, L., Yu, X., Shen, X.: Real-time object detection meets dinov3. arXiv preprint arXiv:2509.20787 (2025) 4, 10
-
[17]
arXiv preprint arXiv:2511.09554 (2025) 4, 6, 10
Robinson, I., Robicheaux, P., Popov, M., Ramanan, D., Peri, N.: Rf-detr: Neural architecture search for real-time detection transformers. arXiv preprint arXiv:2511.09554 (2025) 4, 6, 10
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Danish, M.S., Khan, M.H., Munir, M.A., Sarfraz, M.S., Ali, M.: Improving sin- gle domain-generalized object detection: A focus on diversification and alignment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17732–17742 (2024) 4
2024
-
[19]
IEEE Transactions on Neural Networks and Learning Systems (2024) 4
Rao, Z., Guo, J., Tang, L., Huang, Y., Ding, X., Guo, S.: Srcd: Semantic reason- ing with compound domains for single-domain generalized object detection. IEEE Transactions on Neural Networks and Learning Systems (2024) 4
2024
-
[20]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Wu, A., Deng, C.: Single-domain generalized object detection in urban scene via cyclic-disentangled self-distillation. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 847–856 (2022) 4, 9
2022
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Y., Zhou, S., Liu, X., Hao, C., Fan, B., Tian, J.: Unbiased faster r-cnn for single-source domain generalized object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 28838– 28847 (2024) 4
2024
-
[22]
xiao et al
Xiao, A., Yu, W., Yu, H.: Sample-aware randaugment: Search-free automatic data augmentation for effective image recognition: A. xiao et al. International Journal of Computer Vision133(11), 7710–7725 (2025) 5, 10
2025
-
[23]
Cheng, S., Gokhale, T., Yang, Y.: Adversarial bayesian augmentation for single- sourcedomaingeneralization.In:ProceedingsoftheIEEE/CVFInternationalCon- ference on Computer Vision. pp. 11400–11410 (2023) 5, 10
2023
-
[24]
Xu, M., Qin, L., Chen, W., Pu, S., Zhang, L.: Multi-view adversarial discriminator: Minethenon-causalfactorsforobjectdetectioninunseendomains.In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8103–8112 (2023) 5, 8, 10
2023
-
[25]
In: The Eleventh International Conference on Learning Representations (ICLR 2023)
Fan, Q., Segu, M., Tai, Y.W., Yu, F., Tang, C.K., Schiele, B., Dai, D.: Towards robust object detection invariant to real-world domain shifts. In: The Eleventh International Conference on Learning Representations (ICLR 2023). OpenReview (2023) 5, 10
2023
-
[26]
In: proceedings of the AAAI conference on artificial intelligence
Lee, W., Hong, D., Lim, H., Myung, H.: Object-aware domain generalization for object detection. In: proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 2947–2955 (2024) 5, 10
2024
-
[27]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Xu,X.,Yang,J.,Shi,W.,Ding,S.,Luo,L.,Liu,J.:Physaug:Aphysical-guidedand frequency-based data augmentation for single-domain generalized object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 21815–21823 (2025) 5, 10 Abbreviated paper title 17
2025
-
[28]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Li, F., Zhang, H., Liu, S., Guo, J., Ni, L.M., Zhang, L.: Dn-detr: Accelerate detr training by introducing query denoising. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 13619–13627 (2022) 6
2022
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Jia, D., Yuan, Y., He, H., Wu, X., Yu, H., Lin, W., Sun, L., Zhang, C., Hu, H.: Detrs with hybrid matching. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19702–19712 (2023) 6
2023
-
[30]
In: Proceedings of the IEEE/CVF international conference on com- puter vision
Chen, Q., Chen, X., Wang, J., Zhang, S., Yao, K., Feng, H., Han, J., Ding, E., Zeng, G., Wang, J.: Group detr: Fast detr training with group-wise one-to-many assignment. In: Proceedings of the IEEE/CVF international conference on com- puter vision. pp. 6633–6642 (2023) 6
2023
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, C., Sun, Y., Wang, W., Chen, Q., Ding, E., Yang, Y., Wang, J.: Ms-detr: Efficient detr training with mixed supervision. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17027–17036 (2024) 6
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.