ReGIL: Retrieval-Guided Imitation Learning from a Single Demonstration
Pith reviewed 2026-06-27 16:21 UTC · model grok-4.3
The pith
Treating one demonstration as reusable memory via retrieval supplies step-wise rewards that let robot policies reach over 75 percent success after less than an hour of training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
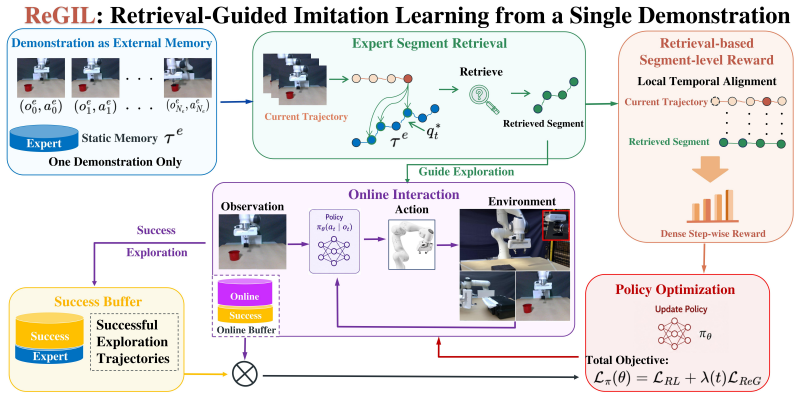
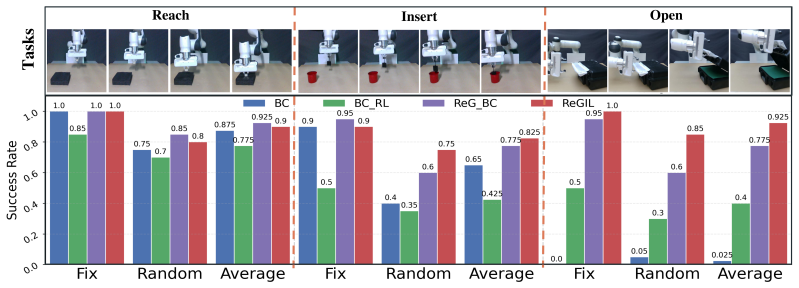
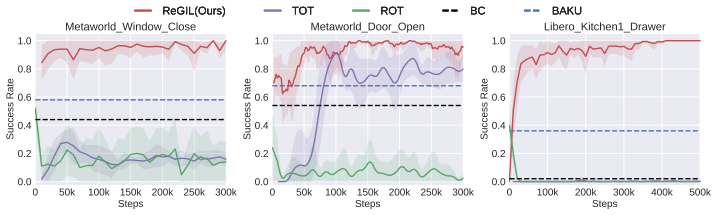
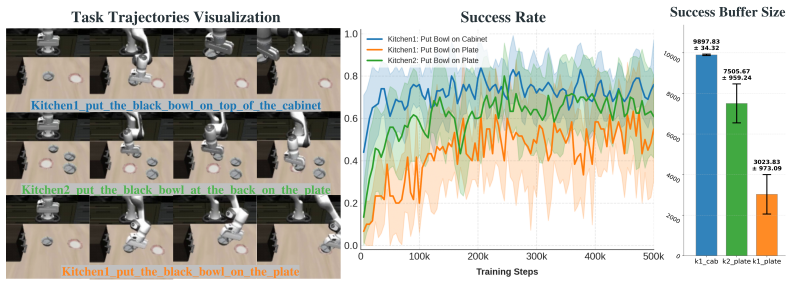
ReGIL stores the single demonstration as external memory and queries it throughout training to guide exploration, form a regularization buffer, and generate rewards through local temporal alignment between the current trajectory and the retrieved segment, yielding over 75 percent success on three manipulation tasks with randomness in initial pose and target position after less than one hour of online training.
What carries the argument
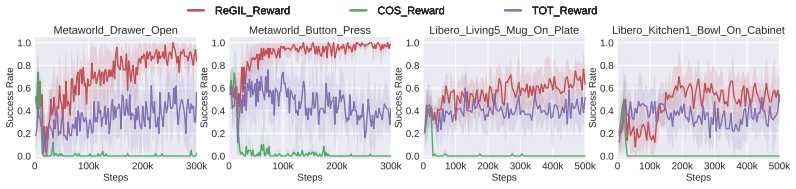
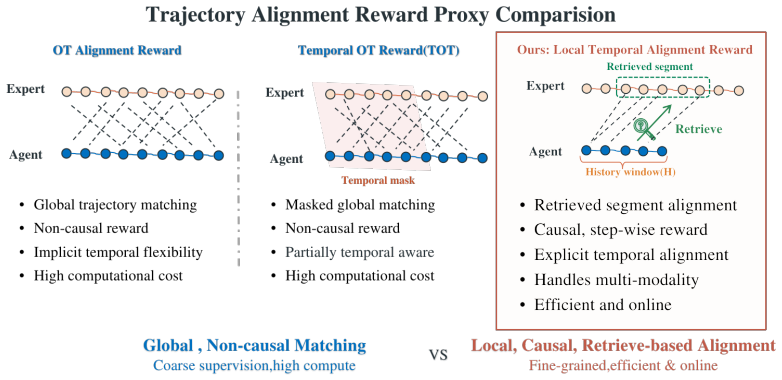
Local temporal alignment between the live trajectory and the retrieved demonstration segment that produces step-wise rewards.
If this is right
- Policies can tolerate initial pose variation and still recover because rewards stay available at every step.
- Training time drops below one hour because the demonstration supplies dense feedback rather than requiring random exploration.
- The same stored demonstration can be reused across multiple tasks that share similar motion segments.
- Real-robot deployment becomes feasible when only one human demonstration is available.
Where Pith is reading between the lines
- The same retrieval-plus-alignment pattern could be tested on tasks where the demonstration is a video rather than robot states.
- If alignment works, one might replace the single demonstration with a small set of segments and measure whether retrieval accuracy improves.
- The method suggests that long-horizon tasks can be learned without explicit subgoal decomposition when memory lookup replaces sparse terminal rewards.
Load-bearing premise
Local temporal alignment between the current trajectory and a retrieved segment produces a reliable reward signal that remains informative even after early deviations in a long task.
What would settle it
A controlled trial in which the policy is forced to deviate in the first few steps and success rate falls to near zero while the alignment-based reward stays high.
Figures

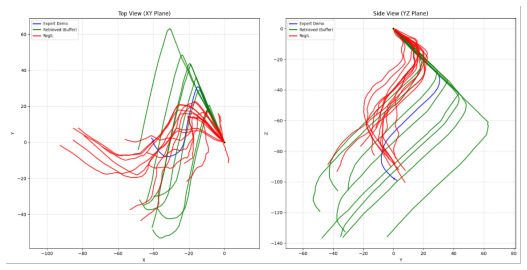
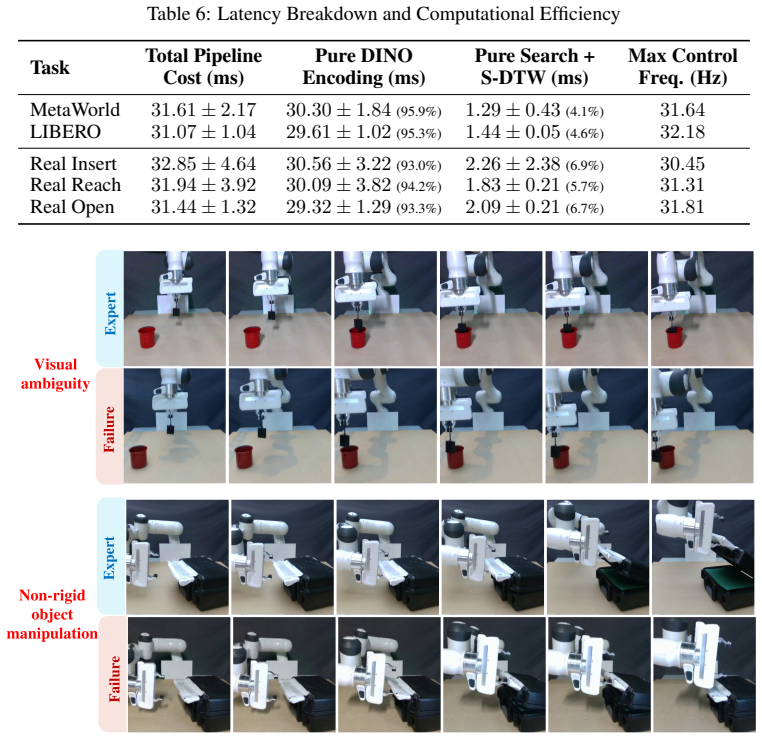
read the original abstract
Learning robot manipulation policies with deep neural networks from a single demonstration remains highly challenging, as even small deviations from the demonstrated trajectory can quickly compound into failure, while collecting substantial online interaction data is costly. We propose ReGIL, a retrieval-guided imitation learning framework that treats a single demonstration as an external memory. ReGIL repeatedly queries this static memory throughout training to simultaneously guide exploration, generate the regularization buffer, and construct rewards. Specifically, it computes rewards through local temporal alignment between the current trajectory and the retrieved segment, providing step-wise and informative feedback for policy improvement. We evaluate ReGIL on robotic manipulation tasks from the LIBERO and Meta-World benchmarks under the single demonstration setting. ReGIL outperforms prior baselines in both success rate and training efficiency. In real-robot experiments, using only one demonstration and less than one hour of online training, ReGIL achieves over 75% success rate across three manipulation tasks with randomness in both initial robot pose and target position. These results demonstrate that leveraging the single demonstration as reusable memory can provide more than static supervision for efficient robot learning. More details can be found on our website: https://regil2026.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReGIL, a retrieval-guided imitation learning framework that treats a single demonstration as static external memory. It repeatedly queries this memory to guide exploration, populate a regularization buffer, and construct rewards via local temporal alignment between the current trajectory and the retrieved segment from the demo. The method is evaluated on LIBERO and Meta-World benchmarks under the single-demonstration setting and on three real-robot manipulation tasks, where it reports outperforming baselines and achieving over 75% success rate with randomness in initial robot pose and target position using only one demonstration and less than one hour of online training.
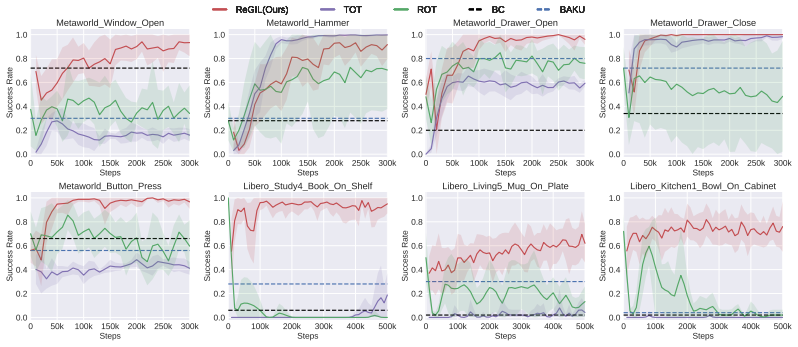
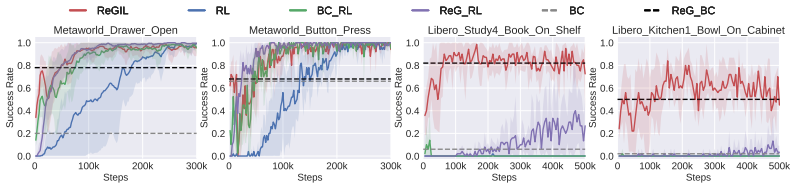
Significance. If the reported performance holds and the local-alignment reward remains informative under distribution shift, the work would demonstrate a practical way to extract more than static supervision from a single demonstration, potentially lowering data requirements for robot manipulation policies. The real-robot results with limited training time are a positive indicator of efficiency if they are statistically robust.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central claim that local temporal alignment between the current trajectory and the retrieved segment produces reliable step-wise feedback rests on the untested assumption that the similarity signal remains dense and non-misleading after an early deviation places the agent outside the demonstration support. In long-horizon tasks with initial-pose and target randomness, this could collapse the reward to near-zero or produce spurious alignments; the manuscript provides no reward-density histograms, deviation-ablation curves, or analysis of nearest-neighbor behavior under state shift.
- [Abstract and §5] Real-robot experiments (abstract and §5): success rates above 75% are reported without the number of evaluation trials, standard deviations, or statistical tests, and without ablations isolating the contribution of the retrieval-based reward versus the regularization buffer. These omissions make it impossible to verify that the performance gain is attributable to the proposed mechanism rather than implementation details or task-specific tuning.
minor comments (2)
- The website link is provided but the manuscript does not indicate whether code, hyperparameters, or demonstration data will be released, which would aid reproducibility.
- Notation for the alignment similarity metric and the retrieval query procedure should be defined more explicitly in the method section to allow independent re-implementation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central claim that local temporal alignment between the current trajectory and the retrieved segment produces reliable step-wise feedback rests on the untested assumption that the similarity signal remains dense and non-misleading after an early deviation places the agent outside the demonstration support. In long-horizon tasks with initial-pose and target randomness, this could collapse the reward to near-zero or produce spurious alignments; the manuscript provides no reward-density histograms, deviation-ablation curves, or analysis of nearest-neighbor behavior under state shift.
Authors: We acknowledge that direct analysis of reward behavior under distribution shift would strengthen the central claim. While the reported >75% success rates on long-horizon real-robot tasks with pose and target randomness provide empirical support that the alignment signal remains informative, we agree this is indirect. In the revision we will add reward-density histograms, deviation-ablation curves, and nearest-neighbor analysis under state shift to explicitly verify density and reliability of the similarity signal. revision: yes
-
Referee: [Abstract and §5] Real-robot experiments (abstract and §5): success rates above 75% are reported without the number of evaluation trials, standard deviations, or statistical tests, and without ablations isolating the contribution of the retrieval-based reward versus the regularization buffer. These omissions make it impossible to verify that the performance gain is attributable to the proposed mechanism rather than implementation details or task-specific tuning.
Authors: We agree that rigorous statistical reporting and component ablations are necessary. In the revised manuscript we will report the exact number of evaluation trials, standard deviations across independent runs, and include appropriate statistical tests. We will also add ablations that isolate the retrieval-based local-alignment reward from the regularization buffer to demonstrate the contribution of each element. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes ReGIL as using a single fixed demonstration as external memory for retrieval, regularization, and reward via local temporal alignment. No load-bearing step reduces a claimed prediction, success rate, or result to a fitted parameter or self-citation by construction. Reported outcomes on LIBERO, Meta-World, and real-robot tasks are presented as empirical evaluations independent of the method's internal definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Behavioral Cloning from Observation
F. Torabi, G. Warnell, and P. Stone. Behavioral cloning from observation.arXiv preprint arXiv:1805.01954, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Di Palo and E
N. Di Palo and E. Johns. Dinobot: Robot manipulation via retrieval and alignment with vi- sion foundation models. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 2798–2805. IEEE, 2024
2024
-
[3]
Malato, F
F. Malato, F. Leopold, A. Melnik, and V . Hautam ¨aki. Zero-shot imitation policy via search in demonstration dataset. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7590–7594. IEEE, 2024
2024
-
[4]
Di Palo and E
N. Di Palo and E. Johns. On the effectiveness of retrieval, alignment, and replay in manipula- tion.IEEE Robotics and Automation Letters, 9(3):2032–2039, 2024
2032
-
[5]
R. S. Sutton, A. G. Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[6]
Kroemer, S
O. Kroemer, S. Niekum, and G. Konidaris. A review of robot learning for manipulation: Challenges, representations, and algorithms.Journal of Machine Learning Research, 22(30): 1–82, 2021. URLhttp://jmlr.org/papers/v22/19-804.html
2021
-
[7]
Memmel, J
M. Memmel, J. Berg, B. Chen, A. Gupta, and J. Francis. STRAP: Robot sub-trajectory re- trieval for augmented policy learning. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=4VHiptx7xe
2025
- [8]
- [9]
- [10]
-
[11]
P. Yang, X. Wang, R. Zhang, C. Wang, F. A. Oliehoek, and J. Kober. Task-unaware life- long robot learning with retrieval-based weighted local adaptation, 2025. URLhttps: //openreview.net/forum?id=YR79EyejsG
2025
-
[12]
J. Pari, N. M. M. Shafiullah, S. P. Arunachalam, and L. Pinto. The surprising effectiveness of representation learning for visual imitation. In18th Robotics: Science and Systems, RSS 2022. MIT Press Journals, 2022
2022
-
[13]
T. Oba, M. Walter, and N. Ukita. Read: Retrieval-enhanced asymmetric diffusion for mo- tion planning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17974–17984, June 2024
2024
- [14]
-
[15]
Fujimoto and S
S. Fujimoto and S. S. Gu. A minimalist approach to offline reinforcement learning.Advances in neural information processing systems, 34:20132–20145, 2021
2021
-
[16]
A. Ajay, A. Kumar, P. Agrawal, S. Levine, and O. Nachum. Opal: Offline primitive discov- ery for accelerating offline reinforcement learning. InInternational Conference on Learning Representations, 2021
2021
-
[17]
Uchendu, T
I. Uchendu, T. Xiao, Y . Lu, B. Zhu, M. Yan, J. Simon, M. Bennice, C. Fu, C. Ma, J. Jiao, S. Levine, and K. Hausman. Jump-start reinforcement learning. InProceedings of the 40th International Conference on Machine Learning, Proceedings of Machine Learning Re- search, pages 34556–34583. PMLR, 2023. URLhttps://proceedings.mlr.press/ v202/uchendu23a.html
2023
-
[18]
A. Nair, B. McGrew, M. Andrychowicz, W. Zaremba, and P. Abbeel. Overcoming exploration in reinforcement learning with demonstrations. In2018 IEEE international conference on robotics and automation (ICRA), pages 6292–6299. IEEE, 2018
2018
-
[19]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human- in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[20]
Haldar, V
S. Haldar, V . Mathur, D. Yarats, and L. Pinto. Watch and match: Supercharging imitation with regularized optimal transport.CoRL, 2022
2022
-
[21]
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine. Efficient online reinforcement learning with offline data. InProceedings of the 40th International Conference on Machine Learning, vol- ume 202 ofProceedings of Machine Learning Research, pages 1577–1594. PMLR, 23–29 Jul
-
[22]
URLhttps://proceedings.mlr.press/v202/ball23a.html
-
[23]
S. Tao, A. Shukla, T. kai Chan, and H. Su. Reverse forward curriculum learning for extreme sample and demo efficiency. InThe Twelfth International Conference on Learning Represen- tations, 2024. URLhttps://openreview.net/forum?id=w4rODxXsmM
2024
-
[24]
Y . Fu, H. Zhang, D. Wu, W. Xu, and B. Boulet. Robot policy learning with tempo- ral optimal transport reward. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Pa- quet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages 122078–122103. Curran Associates, Inc., 2024. doi:10.52202/ 079017-3879. URLhttp...
2024
-
[25]
R. Dadashi, L. Hussenot, M. Geist, and O. Pietquin. Primal wasserstein imitation learning. arXiv preprint arXiv:2006.04678, 2020
-
[26]
Papagiannis and Y
G. Papagiannis and Y . Li. Imitation learning with sinkhorn distances. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 116–131. Springer, 2022
2022
-
[27]
Y . Luo, S. Cohen, E. Grefenstette, M. P. Deisenroth, et al. Optimal transport for offline imita- tion learning. InThe Eleventh International Conference on Learning Representations
-
[28]
P. Senin. Dynamic time warping algorithm review.Information and Computer Science De- partment University of Hawaii at Manoa Honolulu, USA, 855(1-23):40, 2008
2008
-
[29]
Cohen, G
S. Cohen, G. Luise, A. Terenin, B. Amos, and M. Deisenroth. Aligning time series on in- comparable spaces. InInternational conference on artificial intelligence and statistics, pages 1036–1044. PMLR, 2021
2021
-
[30]
A. Fickinger, S. Cohen, S. Russell, and B. Amos. Cross-domain imitation learning via optimal transport.arXiv preprint arXiv:2110.03684, 2021. 10
-
[31]
M ¨uller.Fundamentals of music processing: Using Python and Jupyter notebooks, vol- ume 2
M. M ¨uller.Fundamentals of music processing: Using Python and Jupyter notebooks, vol- ume 2. Springer, 2021
2021
-
[32]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Cou- prie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski. DINOv3, 2025. URLhttps: //arxiv.org/...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Fujimoto, H
S. Fujimoto, H. Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. InInternational Conference on Machine Learning, pages 1582–1591, 2018
2018
-
[34]
McLean, E
R. McLean, E. Chatzaroulas, L. McCutcheon, F. R ¨oder, T. Yu, Z. He, K. Zentner, R. Julian, J. K. Terry, I. Woungang, N. Farsad, and P. S. Castro. Meta-world+: An improved, stan- dardized, RL benchmark. InThe Thirty-ninth Annual Conference on Neural Information Pro- cessing Systems Datasets and Benchmarks Track, 2025. URLhttps://openreview.net/ forum?id=1...
2025
-
[35]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Haldar, Z
S. Haldar, Z. Peng, and L. Pinto. Baku: An efficient transformer for multi-task policy learning. Advances in Neural Information Processing Systems, 37:141208–141239, 2024
2024
-
[37]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[38]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual represen- tation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022. Appendices A ReGIL Algorithm Detail A.1 Overall Algorithm Detail ReGIL is an online imitation learning method that leverages retrieval-guided exploration and op- timization from demonstrations. At...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.