RunAgent SuperBrowser: A Theory of Autonomous Web Navigation Grounded in Human Browsing Behaviour
Pith reviewed 2026-06-27 16:35 UTC · model grok-4.3
The pith
Web agents reach high success when they limit memory and separate perception from planning like humans do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
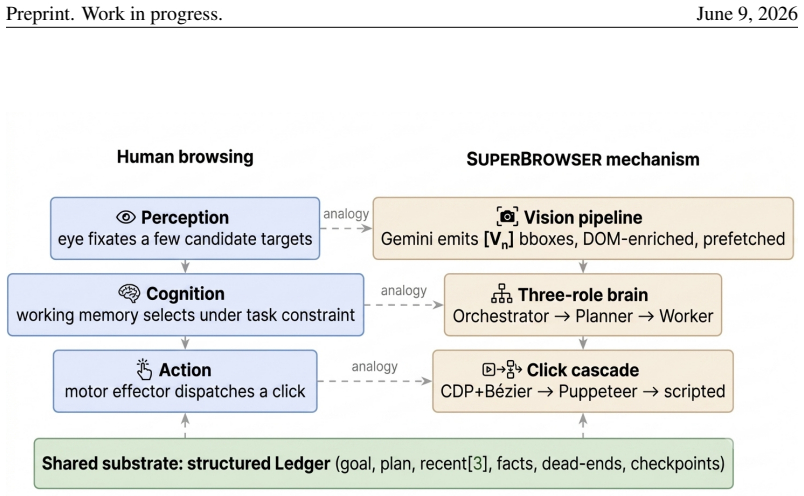
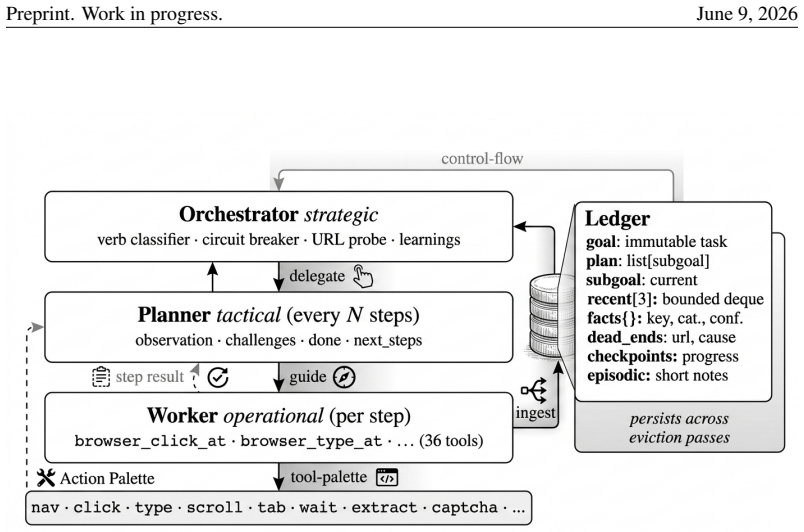
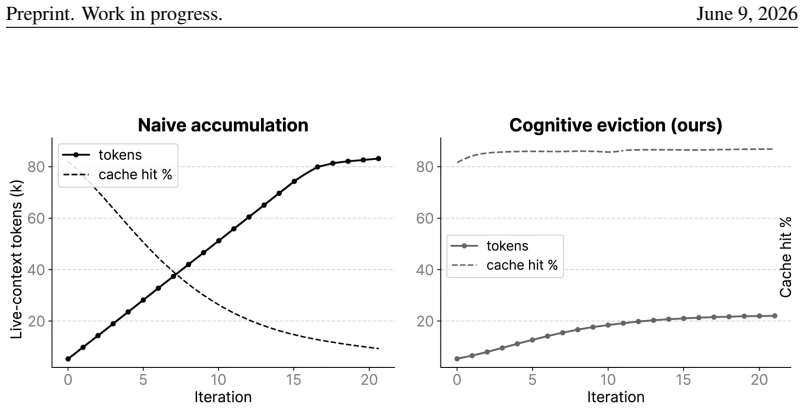
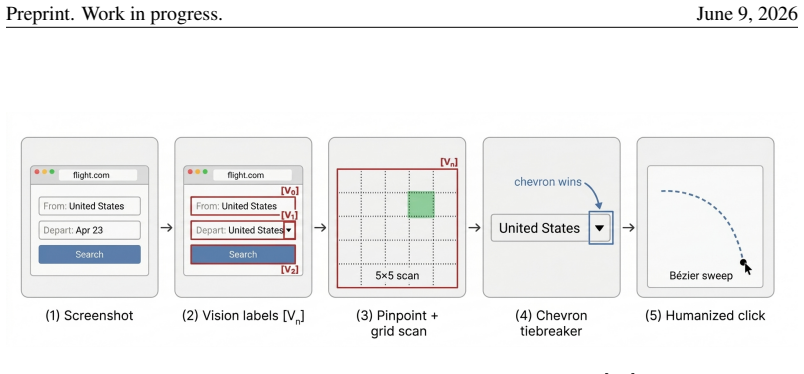
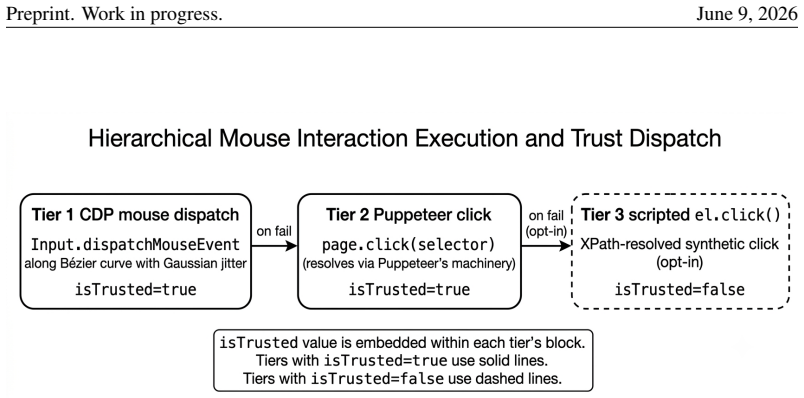
SUPERBROWSER operationalizes human browsing as three coupled mechanisms. A vision-first bounding-box pipeline labels candidate interactive regions on every screenshot and supplies them asynchronously to the language model. A three-role brain—an Orchestrator for classification and routing, a Planner that evaluates progress every few steps, and a Worker that emits actions—separates strategic from operational reasoning. A structured Ledger stores only the goal, the last three actions, a small set of facts and dead-ends, and checkpoints; a six-phase eviction loop discards stale screenshots, state blobs, and traces. Action execution uses a three-tier click cascade with humanized Bezier motion and
What carries the argument
The perception-cognition-action triad: vision-first bounding-box pipeline, three-role brain, and eviction-managed Ledger that retains only goal-relevant state.
If this is right
- Agents achieve high task completion without retaining every pixel or full reasoning trace in context.
- Separating progress evaluation from action emission reduces drift over long navigation sequences.
- Humanized execution mechanics resolve common UI ambiguities such as small arrows next to labels.
- Consistent application of limited memory across components yields larger gains than isolated optimizations.
- The same cognitive-contract pattern can be applied to other sequential interaction benchmarks.
Where Pith is reading between the lines
- If memory limits are the main driver, the same eviction discipline could improve performance in other long-horizon agent domains such as robotic manipulation.
- Removing the vision-first step while keeping the rest would test whether perception ordering matters more than the ledger itself.
- The design implies that simply enlarging context windows is not the only or best route to better web agents.
- Future work could collect additional human browsing traces to refine the exact eviction rules or role boundaries.
Load-bearing premise
The performance gain is produced by the human-like perception-cognition-action design rather than by unstated implementation choices or the underlying model.
What would settle it
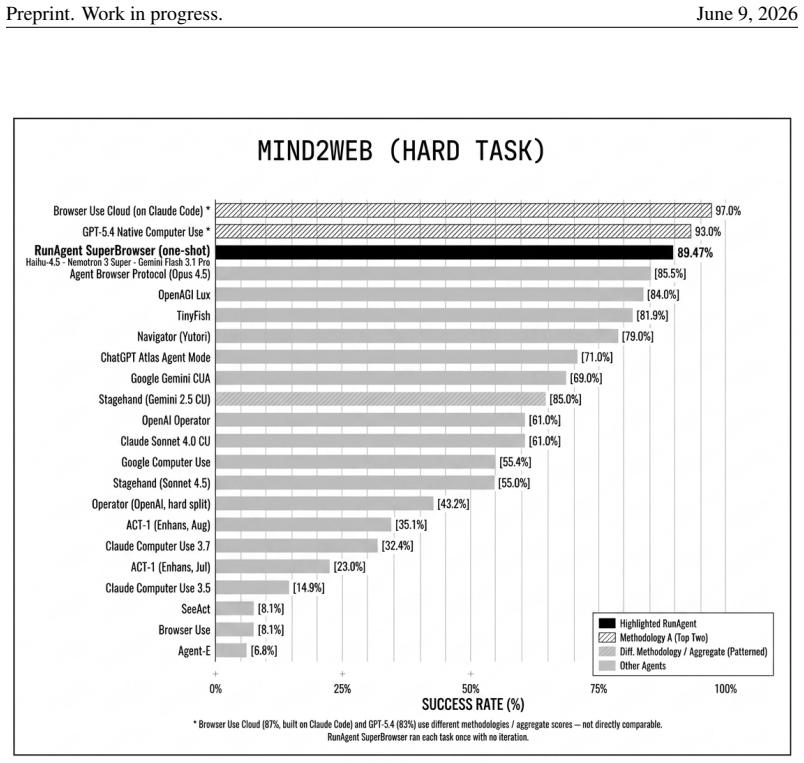
An ablation that keeps the same model and infrastructure but removes the Ledger eviction loop or the three-role separation and measures whether success on the same 66 tasks falls below the reported 89.47 percent.
Figures
read the original abstract
We present SUPERBROWSER, an autonomous web-navigation agent designed against a single guiding hypothesis: a web agent should browse the way a person browses. A human reading a page does not retain every pixel they have seen; they look at a few candidate targets, decide on one, and remember only what is needed to keep the goal alive. We operationalize this perception-cognition-action triad as three coupled mechanisms. First, a vision-first bounding-box pipeline labels candidate interactive regions on every screenshot and feeds them, asynchronously prefetched, to the language model so that the "eye" precedes the "hand". Second, a three-role brain -- an Orchestrator that classifies and routes, a Planner that evaluates progress every few steps, and a Worker that emits per-step actions -- separates strategic from operational reasoning. Third, a structured Ledger stores only what a person would: the goal, the last three actions, a small set of facts and dead-ends, and a handful of checkpoints; a six-phase eviction loop systematically discards stale screenshots, state blobs, and reasoning traces from the live context. Action execution is a three-tier click cascade (Chrome DevTools Protocol to Puppeteer to scripted) with humanized Bezier motion, plus a chevron-aware bounding-box snapper that resolves the "small arrow beside a large label" ambiguity. On the Mind2Web Hard benchmark (66 tasks), SUPERBROWSER attains 89.47% success, placing third overall and ahead of every published open/research browser-agent baseline by a large margin. We argue that the gain comes not from any single trick but from the consistent application of a cognitive contract throughout the system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SUPERBROWSER, an autonomous web-navigation agent designed to emulate human browsing via a perception-cognition-action triad. This is implemented through a vision-first bounding-box pipeline for candidate regions, a three-role brain (Orchestrator for routing, Planner for progress evaluation, Worker for actions), and a structured Ledger with six-phase eviction to retain only goal-relevant information. On the Mind2Web Hard benchmark (66 tasks), it reports 89.47% success, ranking third overall and ahead of published open/research baselines, with gains attributed to consistent application of the cognitive contract rather than isolated tricks.
Significance. If the performance gains can be causally linked to the proposed mechanisms through controlled experiments, the work would contribute a human-grounded design principle for web agents that could improve reliability and reduce context bloat in long-horizon tasks. The high success rate on a challenging benchmark is notable and, if substantiated, offers a falsifiable template for agent architecture that other systems could adopt or test against.
major comments (2)
- [Abstract] Abstract: The central claim that 'the gain comes not from any single trick but from the consistent application of a cognitive contract throughout the system' is load-bearing for the paper's thesis. No ablation results, component-removal experiments, or VLM-controlled baselines (e.g., ReAct-style agent on the identical model) are referenced to isolate the contribution of the bounding-box pipeline, three-role separation, or Ledger eviction; the attribution therefore remains an assertion rather than a demonstrated result.
- [Experimental evaluation] Experimental evaluation (implied by benchmark reporting): The manuscript does not disclose the exact VLM employed or its zero-shot performance on the same Mind2Web Hard tasks. Without this, it is impossible to determine whether the 89.47% success rate exceeds what the underlying model would achieve under a simpler prompting regime, undermining the claim that the cognitive contract is the source of the margin over baselines.
Simulated Author's Rebuttal
We thank the referee for these focused comments on evidence and attribution. We address each point directly and commit to revisions that add the requested controls and disclosures without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the gain comes not from any single trick but from the consistent application of a cognitive contract throughout the system' is load-bearing for the paper's thesis. No ablation results, component-removal experiments, or VLM-controlled baselines (e.g., ReAct-style agent on the identical model) are referenced to isolate the contribution of the bounding-box pipeline, three-role separation, or Ledger eviction; the attribution therefore remains an assertion rather than a demonstrated result.
Authors: We agree the claim requires stronger isolation. The revised manuscript will add (i) component-removal ablations for the vision-first bounding-box pipeline, three-role brain, and six-phase Ledger eviction, and (ii) a ReAct-style baseline run on the identical VLM and task set. These experiments will quantify the incremental contribution of the integrated cognitive contract versus isolated mechanisms. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation (implied by benchmark reporting): The manuscript does not disclose the exact VLM employed or its zero-shot performance on the same Mind2Web Hard tasks. Without this, it is impossible to determine whether the 89.47% success rate exceeds what the underlying model would achieve under a simpler prompting regime, undermining the claim that the cognitive contract is the source of the margin over baselines.
Authors: We will name the exact VLM and its version in the revised experimental section. We will also report zero-shot and ReAct-style prompting results on the identical model and Mind2Web Hard split so readers can directly compare the margin attributable to the proposed architecture. revision: yes
Circularity Check
No circularity; empirical design and benchmark result are self-contained
full rationale
The manuscript advances a design hypothesis (human-like perception-cognition-action triad) and reports an empirical success rate (89.47% on Mind2Web Hard) without any equations, fitted parameters renamed as predictions, or load-bearing self-citations. The three mechanisms are presented as direct operationalizations of the initial hypothesis rather than derived quantities; the benchmark outcome is measured, not computed from the design by construction. No uniqueness theorems, ansatzes, or renamings of known results appear. The attribution of gains to the cognitive contract is interpretive but does not reduce any claimed result to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human browsing can be operationalized as a perception-cognition-action triad implemented via vision-first bounding boxes, three-role reasoning, and an evicting ledger.
Reference graph
Works this paper leans on
-
[1]
Psychological Review , volume =
The magical number seven, plus or minus two: Some limits on our capacity for processing information , author =. Psychological Review , volume =
-
[2]
Behavioral and Brain Sciences , volume =
The magical number 4 in short-term memory: A reconsideration of mental storage capacity , author =. Behavioral and Brain Sciences , volume =
-
[3]
The Psychology of Learning and Motivation , editor =
Working memory , author =. The Psychology of Learning and Motivation , editor =
-
[4]
Trends in Cognitive Sciences , volume =
The episodic buffer: A new component of working memory? , author =. Trends in Cognitive Sciences , volume =
-
[5]
Cognitive Science , volume =
Cognitive load during problem solving: Effects on learning , author =. Cognitive Science , volume =
-
[6]
Organization of Memory , editor =
Episodic and semantic memory , author =. Organization of Memory , editor =. 1972 , pages =
1972
-
[7]
Thinking, Fast and Slow , author =
-
[8]
Journal of Cognitive Neuroscience , volume =
Declarative and Nondeclarative Memory: Multiple Brain Systems Supporting Learning and Memory , author =. Journal of Cognitive Neuroscience , volume =
-
[9]
Psychological Review , volume =
Acquisition of cognitive skill , author =. Psychological Review , volume =
-
[10]
2004 , note =
An Integrated Theory of the Mind , author =. 2004 , note =
2004
-
[11]
Psychological Review , volume =
Toward an instance theory of automatization , author =. Psychological Review , volume =
-
[12]
Psychological Review , volume =
A schema theory of discrete motor skill learning , author =. Psychological Review , volume =
-
[13]
1967 , note =
Human Performance , author =. 1967 , note =
1967
-
[14]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , volume =
A model of saliency-based visual attention for rapid scene analysis , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , volume =
-
[15]
Nature Reviews Neuroscience , volume =
Computational modelling of visual attention , author =. Nature Reviews Neuroscience , volume =
-
[16]
Science , volume =
Scanpaths in eye movements during pattern perception , author =. Science , volume =
-
[17]
Proceedings of the 2002 Symposium on Eye Tracking Research & Applications (ETRA) , pages =
Visual attention to repeated internet images: testing the scanpath theory on the world wide web , author =. Proceedings of the 2002 Symposium on Eye Tracking Research & Applications (ETRA) , pages =
2002
-
[18]
Nielsen Norman Group Article , year =
F-shaped pattern for reading web content , author =. Nielsen Norman Group Article , year =
-
[19]
2010 , note =
Eyetracking Web Usability , author =. 2010 , note =
2010
-
[20]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI) , pages =
What Do You See When You're Surfing? Using Eye Tracking to Predict Salient Regions of Web Pages , author =. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI) , pages =
-
[21]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI) , pages =
Information foraging in information access environments , author =. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI) , pages =
-
[22]
Information Foraging Theory: Adaptive Interaction with Information , author =
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Mind2Web: Towards a Generalist Agent for the Web , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[24]
arXiv preprint arXiv:2504.01382 , year=
An Illusion of Progress? Assessing the Current State of Web Agents , author =. arXiv preprint arXiv:2504.01382 , year =
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
International Conference on Learning Representations (ICLR) , year =
WebArena: A Realistic Web Environment for Building Autonomous Agents , author =. International Conference on Learning Representations (ICLR) , year =
-
[27]
Annual Meeting of the Association for Computational Linguistics (ACL) , year =
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , author =. Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[28]
International Conference on Machine Learning (ICML) , year =
World of Bits: An Open-Domain Platform for Web-Based Agents , author =. International Conference on Machine Learning (ICML) , year =
-
[29]
International Conference on Learning Representations (ICLR) , year =
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration , author =. International Conference on Learning Representations (ICLR) , year =
-
[30]
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and others , journal =
-
[31]
and Del Verme, Manuel and Marty, Tom and Boige, L\'eo and Thakkar, Megh and Cappart, Quentin and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre , journal =
Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Del Verme, Manuel and Marty, Tom and Boige, L\'eo and Thakkar, Megh and Cappart, Quentin and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre , journal =. The
-
[32]
Pan, Yichen and Kong, Dehan and Zhou, Sida and Cui, Cheng and Leng, Yifei and Jiang, Bing and Liu, Xiangru and Fu, Yuyou and Shao, Shuyan and Yin, Kunlin and Wang, Yejie and Wu, Junda and Zheng, Stephen Marcus and Liu, Yifei and Liu, Yiyang and Bai, Yibo and Wang, Yiren and Xie, Tianbao , journal =
-
[33]
Lu, Jiaqi and others , journal =
-
[34]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and others , journal =
-
[35]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in
Yang, Jianwei and Zhang, Hao and Li, Feng and Zou, Xueyan and Li, Chunyuan and Gao, Jianfeng , journal =. Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in
-
[36]
Zheng, Boyuan and Gou, Boyu and Kil, Jihyung and Sun, Huan and Su, Yu , booktitle =
-
[37]
Hong, Wenyi and Wang, Weihan and Lv, Qingsong and Xu, Jiazheng and Yu, Wenmeng and Ji, Junhui and Wang, Yan and Wang, Zihan and Zhang, Yuxiao and Li, Juanzi and Xu, Bin and Dong, Yuxiao and Ding, Ming and Tang, Jie , booktitle =
-
[38]
Qin, Yujia and Ye, Yining and Fang, Junjie and Wang, Haoming and Liang, Shihao and Tian, Shizuo and Zhang, Junda and Li, Jiahao and Li, Yunxin and Huang, Shijue and Zhao, Wanjun and Li, Hongjin and Yang, Dingdang and Liu, Wei and Wei, Shimao and Xu, Mingjun and Chu, Jiangwei and Zhang, Tao and Jin, Hangliang and Sun, Mengyuan and others , journal =
-
[39]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =
-
[40]
Xu, Binfeng and Peng, Zhiyuan and Lei, Bowen and Mukherjee, Subhabrata and Liu, Yuchen and Xu, Dongkuan , booktitle =
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[42]
Nakano, Reiichiro and Hilton, Jacob and Balaji, Suchir and Wu, Jeff and Ouyang, Long and Kim, Christina and Hesse, Christopher and Jain, Shantanu and Kosaraju, Vineet and Saunders, William and others , journal =
-
[43]
A Real-World
Gur, Izzeddin and Furuta, Hiroki and Huang, Austin and Safdari, Mustafa and Matsuo, Yutaka and Eck, Douglas and Faust, Aleksandra , booktitle =. A Real-World
-
[44]
Lai, Hanyu and Liu, Xiao and Iong, Iat Long and Yao, Shuntian and Chen, Yuxuan and Shen, Pengbo and Yu, Hao and Zhang, Hanchen and Zhang, Xiaohan and Dong, Yuxiao and Tang, Jie , journal =
-
[45]
He, Hongliang and Yao, Wenlin and Ma, Kaixin and Yu, Wenhao and Dai, Yong and Zhang, Hongming and Lan, Zhenzhong and Yu, Dong , journal =
-
[46]
Browser Use: enable
M. Browser Use: enable. 2024 , note =
2024
-
[47]
arXiv preprint arXiv:2511.19477 , year =
Building Browser Agents: Architecture, Security, and Practical Solutions , author =. arXiv preprint arXiv:2511.19477 , year =
-
[48]
Wu, Xuezhi and Tang, Yaoxiang and Wang, Yong and Wu, Yi and Wu, Yuan and Xie, Yi and others , journal =
-
[49]
arXiv preprint arXiv:2506.07153 , year =
Mind the Web: The Security of Web Use Agents , author =. arXiv preprint arXiv:2506.07153 , year =
-
[50]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[51]
Transactions on Machine Learning Research (TMLR) , year =
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. Transactions on Machine Learning Research (TMLR) , year =
-
[52]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , year =
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , year =
-
[53]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , journal =
-
[54]
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , journal =
-
[55]
Augmenting Language Models with Long-Term Memory , author =. arXiv preprint arXiv:2306.07174 , year =
-
[56]
Memory for Autonomous
Zhang, Yifei and Liu, Shichun and others , journal =. Memory for Autonomous
-
[57]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[58]
Conference on Robot Learning (CoRL) , year =
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances , author =. Conference on Robot Learning (CoRL) , year =
-
[59]
2024 , howpublished =
Introducing Computer Use, a New. 2024 , howpublished =
2024
-
[60]
2025 , howpublished =
Introducing Operator , author =. 2025 , howpublished =
2025
-
[61]
2023 , howpublished =
2023
-
[62]
2024 , howpublished =
Prompt caching with. 2024 , howpublished =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.