ω-EVA: Envision, Verify, and Act with Latent Interactive World Models
Pith reviewed 2026-06-27 16:08 UTC · model grok-4.3
The pith
A policy can improve its actions by checking their imagined latent consequences through a world model before committing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
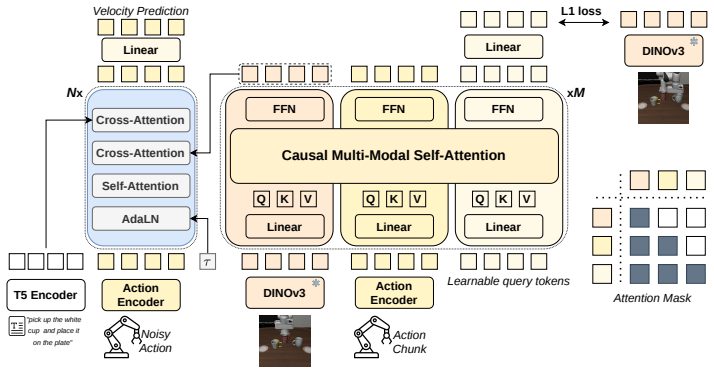
ω-EVA realizes an Envision–Verify–Act loop by first learning action-conditioned latent dynamics, then training a language-conditioned flow policy on the resulting representations, and finally feeding each proposal back through the world model so that a tri-branch refiner can jointly reason over the current state, the proposal-conditioned future, and the proposed action itself, producing improved action chunks without any video generation at inference time.
What carries the argument
The tri-branch refiner that jointly reasons over current state, proposal-conditioned future, and proposed action inside the latent world model.
If this is right
- The full pipeline consistently raises the performance of the base proposal policy across single-arm, bimanual, long-horizon, and perturbed simulation settings.
- Latent-space diagnostics reveal structured, action-conditioned future representations.
- The system reaches competitive results with roughly 1.2 billion parameters and no extra robot-data pretraining.
- World models shift from passive predictors to active modules that supply action feedback.
Where Pith is reading between the lines
- If the latent verification step generalizes, similar loops could let agents in non-robot domains self-check plans without full external simulation.
- The absence of video generation at test time suggests the method could scale to higher-resolution or longer-horizon tasks more easily than pixel-level predictors.
- A natural next test would be to measure whether the same architecture improves success rates when transferred from simulation to physical robots with real sensor noise.
Load-bearing premise
Joint reasoning over current state, proposal-conditioned future, and proposed action in the tri-branch refiner reliably produces better final actions than the proposal policy alone.
What would settle it
An ablation that removes the world-model feedback loop or the tri-branch refiner and measures no consistent performance drop on the same single-arm, bimanual, long-horizon, and perturbed simulation benchmarks.
Figures



read the original abstract
Embodied policies typically map current observations directly to actions, leaving candidate-action consequences implicit. World models provide predictive supervision, representations, or external simulation, but rarely let a policy inspect the imagined consequence of its own proposal before acting. We introduce $\omega$-EVA, a latent interactive world model that realizes an Envision--Verify--Act loop for embodied action generation. Its three-stage framework learns action-conditioned latent dynamics, trains a language-conditioned flow policy on dynamics-aware visual representations, and feeds the policy's proposal back through the world model. A tri-branch refiner jointly reasons over the current state, proposal-conditioned future, and proposed action to produce the final action chunk. Because consequence reasoning remains in latent feature space, $\omega$-EVA avoids generating future videos at inference. Evaluations across diverse single-arm, bimanual, long-horizon, and perturbed simulation settings show that the complete interaction pipeline consistently improves the proposal policy, while latent diagnostics indicate meaningful action-conditioned future structure. With approximately 1.2B parameters and no additional robot-data pretraining, $\omega$-EVA demonstrates a compact and competitive performance--scale--data trade-off, making the world model an active action-feedback module rather than a passive predictor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ω-EVA, a latent interactive world model realizing an Envision-Verify-Act loop for embodied action generation. It learns action-conditioned latent dynamics, trains a language-conditioned flow policy on dynamics-aware visual representations, and routes the policy's proposal through the world model. A tri-branch refiner jointly reasons over the current state, proposal-conditioned future latents, and proposed action to output the final action chunk, remaining entirely in latent space to avoid video generation at inference. The paper claims that evaluations across single-arm, bimanual, long-horizon, and perturbed simulation settings show the complete pipeline consistently improves the proposal policy, with latent diagnostics confirming meaningful action-conditioned future structure. The model uses ~1.2B parameters with no additional robot-data pretraining.
Significance. If the reported improvements hold under controlled ablations and are accompanied by quantitative metrics, the work would demonstrate a practical way to embed consequence reasoning from a latent world model directly into policy refinement. This could shift world models from passive predictors to active feedback modules in robotics while preserving a favorable performance-scale-data trade-off.
major comments (2)
- [Abstract] Abstract: the claim that 'the complete interaction pipeline consistently improves the proposal policy' is presented without any quantitative metrics, baseline comparisons, error bars, or exclusion criteria for the simulation suites, which are required to substantiate the central empirical result.
- [Tri-branch refiner (architecture description)] Tri-branch refiner (architecture description): the load-bearing claim is that feeding proposal-conditioned future latents into the refiner yields better final actions than the proposal policy alone via explicit consequence reasoning. The description states the refiner is trained end-to-end on three inputs, yet no ablation is reported that removes only the future branch while holding total parameter count and training procedure fixed. Without this control, gains cannot be attributed to the Envision-Verify-Act loop rather than added capacity.
minor comments (1)
- [Abstract] Abstract: the symbol ω in the title and model name is not defined or motivated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the complete interaction pipeline consistently improves the proposal policy' is presented without any quantitative metrics, baseline comparisons, error bars, or exclusion criteria for the simulation suites, which are required to substantiate the central empirical result.
Authors: The abstract is a high-level summary; the full manuscript reports quantitative results with metrics, baselines, error bars, and task details in the Experiments section. To directly address the concern, we will revise the abstract to include key quantitative highlights (e.g., average success-rate gains and number of runs) while preserving its length. revision: yes
-
Referee: [Tri-branch refiner (architecture description)] Tri-branch refiner (architecture description): the load-bearing claim is that feeding proposal-conditioned future latents into the refiner yields better final actions than the proposal policy alone via explicit consequence reasoning. The description states the refiner is trained end-to-end on three inputs, yet no ablation is reported that removes only the future branch while holding total parameter count and training procedure fixed. Without this control, gains cannot be attributed to the Envision-Verify-Act loop rather than added capacity.
Authors: We agree that an ablation removing only the future branch while exactly matching parameter count and training procedure is required to isolate the contribution of consequence reasoning. The current manuscript shows full-pipeline gains over the proposal policy but does not contain this control. We will add the requested ablation (training a matched-capacity variant without the future branch) and report the results. revision: yes
Circularity Check
No circularity: claims rest on empirical simulation evaluations
full rationale
The paper describes an architectural pipeline (latent dynamics, flow policy, tri-branch refiner) trained end-to-end and evaluated on external simulation benchmarks (single-arm, bimanual, long-horizon, perturbed settings). No equations, derivations, or first-principles results are presented that reduce any claimed improvement to a quantity defined by the same fitted data or self-citation chain. The Envision-Verify-Act loop is realized through model components whose performance is measured against held-out simulation rollouts rather than internal consistency; this is the standard non-circular pattern for empirical robotics papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Feedback world model enables precise guidance of diffusion policy.arXiv preprint arXiv:2605.15705,
Tuo An, Jindou Jia, Gen Li, Jingliang Li, Chuhao Zhou, Pengfei Liu, Bofan Lyu, Jiaqi Bai, Xinying Guo, Geng Li, et al. Feedback world model enables precise guidance of diffusion policy.arXiv preprint arXiv:2605.15705,
-
[2]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Am- mar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
-
[3]
Randall Balestriero and Yann LeCun. Lejepa: Provable and scalable self-supervised learning with- out the heuristics.arXiv preprint arXiv:2511.08544,
-
[4]
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doersch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283,
-
[5]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
-
[6]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xi- anliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and bench- mark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088,
-
[7]
ISSN 0360-0300. doi: 10.1145/3746449. URLhttps://doi.org/10.1145/3746449. Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172,
-
[8]
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626,
-
[9]
Vidar: Embodied video diffusion model for generalist manipulation.arXiv preprint arXiv:2507.12898,
Yao Feng, Hengkai Tan, Xinyi Mao, Chendong Xiang, Guodong Liu, Shuhe Huang, Hang Su, and Jun Zhu. Vidar: Embodied video diffusion model for generalist manipulation.arXiv preprint arXiv:2507.12898,
-
[10]
Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125,
-
[11]
World models.arXiv preprint arXiv:1803.10122, 2(3):440,
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440,
-
[12]
Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603,
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603,
Pith/arXiv arXiv 1912
-
[13]
Mastering atari with dis- crete world models.arXiv preprint arXiv:2010.02193,
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with dis- crete world models.arXiv preprint arXiv:2010.02193,
Pith/arXiv arXiv 2010
-
[14]
Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104,
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104,
-
[15]
World model for robot learning: A comprehensive survey
Bohan Hou, Gen Li, Jindou Jia, Tuo An, Xinying Guo, Sicong Leng, Haoran Geng, Yanjie Ze, Tatsuya Harada, Philip Torr, et al. World model for robot learning: A comprehensive survey. arXiv preprint arXiv:2605.00080,
-
[16]
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803,
-
[17]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054,
-
[18]
19 Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimiz- ing speed and success.arXiv preprint arXiv:2502.19645,
-
[19]
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163,
-
[20]
Causal world modeling for robot control.arXiv preprint arXiv:2601.21998,
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998,
-
[21]
Unified video action model.arXiv preprint arXiv:2503.00200,
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200,
-
[22]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
-
[23]
RDT-1B: A Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1B: A Diffusion Foundation Model for Bimanual Manipulation. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025,
2025
-
[24]
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos.Preprint at arXiv:2507.15597,
-
[25]
Hao Luo, Ye Wang, Wanpeng Zhang, Sipeng Zheng, Ziheng Xi, Chaoyi Xu, Haiweng Xu, Haoqi Yuan, Chi Zhang, Yiqing Wang, Yicheng Feng, and Zongqing Lu. Being-H0.5: Scaling Human- Centric Robot Learning for Cross-Embodiment Generalization.Preprint at arXiv:2601.12993, 2026a. Hao Luo, Wanpeng Zhang, Yicheng Feng, Sipeng Zheng, Haiweng Xu, Chaoyi Xu, Ziheng Xi, ...
-
[26]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. Leworld- model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312,
-
[27]
Jepa- vla: Video predictive embedding is needed for vla models.arXiv preprint arXiv:2602.11832,
Shangchen Miao, Ningya Feng, Jialong Wu, Ye Lin, Xu He, Dong Li, and Mingsheng Long. Jepa- vla: Video predictive embedding is needed for vla models.arXiv preprint arXiv:2602.11832,
-
[28]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747,
-
[29]
Dinov3.arXiv preprint arXiv:2508.10104,
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
-
[30]
20 Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, and Zhibo Chen. Vla-jepa: Enhancing vision-language-action model with latent world model.arXiv preprint arXiv:2602.10098,
-
[31]
Gigaworld-0: World models as data engine to empower embodied ai.arXiv preprint arXiv:2511.19861,
GigaWorld Team, Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Haoyun Li, Jiagang Zhu, Kerui Li, Mengyuan Xu, et al. Gigaworld-0: World models as data engine to empower embodied ai.arXiv preprint arXiv:2511.19861,
-
[32]
Motubrain: An advanced world action model for robot control.arXiv preprint arXiv:2604.27792,
MotuBrain Team, Chendong Xiang, Fan Bao, Haitian Liu, Hengkai Tan, Hongzhe Bi, James Li, Jiabao Liu, Jingrui Pang, Kiro Jing, et al. Motubrain: An advanced world action model for robot control.arXiv preprint arXiv:2604.27792,
-
[33]
World action models: The next frontier in embodied ai.arXiv preprint arXiv:2605.12090,
Siyin Wang, Junhao Shi, Zhaoyang Fu, Xinzhe He, Feihong Liu, Chenchen Yang, Yikang Zhou, Zhaoye Fei, Jingjing Gong, Jinlan Fu, et al. World action models: The next frontier in embodied ai.arXiv preprint arXiv:2605.12090,
-
[34]
Gigaworld-policy: An efficient action-centered world–action model
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. Gigaworld-policy: An efficient action-centered world–action model. arXiv preprint arXiv:2603.17240, 2026a. Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiann...
-
[35]
Act2goal: From world model to general goal-conditioned policy.arXiv preprint arXiv:2512.23541,
Pengfei Zhou, Liliang Chen, Shengcong Chen, Di Chen, Wenzhi Zhao, Rongjun Jin, Guanghui Ren, and Jianlan Luo. Act2goal: From world model to general goal-conditioned policy.arXiv preprint arXiv:2512.23541,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.