OpenBibleTTS: Large-Scale Speech Resources and TTS Models for Low-Resource Languages
Pith reviewed 2026-06-27 16:14 UTC · model grok-4.3
The pith
OpenBibleTTS benchmark shows no single TTS system leads on all 37 low-resource languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
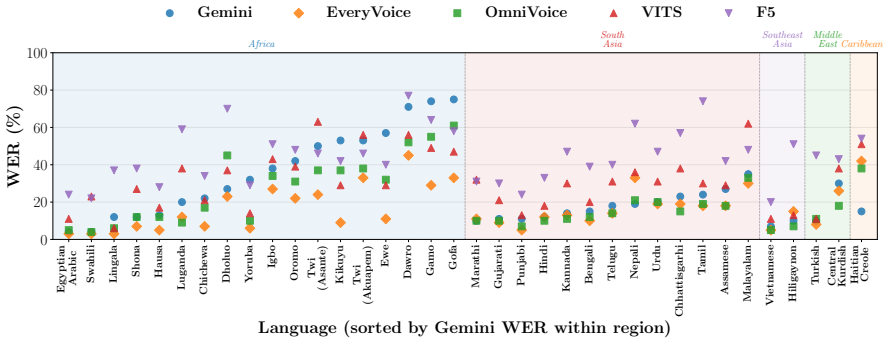
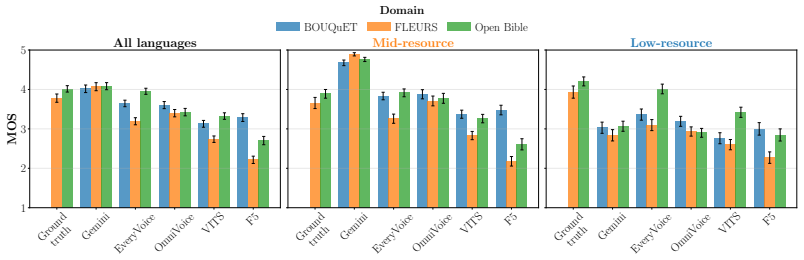
OpenBibleTTS supplies aligned audio-text resources for 37 low-resource languages and shows through direct comparison that Gemini-TTS receives the highest human listener ratings on most languages while monolingual EveryVoice models trained on the new data produce the strongest intelligibility and are preferred for several African languages, whereas open from-scratch systems lose quality sharply when given text outside the Biblical domain.
What carries the argument
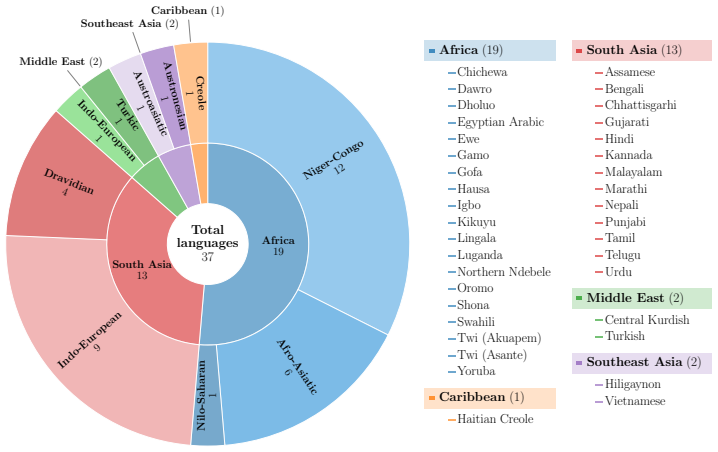
OpenBibleTTS dataset of aligned speech and text from Bible translations across 37 languages, used both to train monolingual models and to evaluate multiple TTS systems on in-domain and out-of-domain material.
If this is right
- Choice of TTS architecture must be made per language and per metric rather than assuming one multilingual model will suffice.
- Language-specific training data improves intelligibility scores in several African languages compared with broad multilingual systems.
- Open from-scratch TTS systems remain unreliable when the input text departs from the narrow domain of the training corpus.
- Human listener judgments remain necessary because automatic metrics alone do not predict which system listeners will prefer.
Where Pith is reading between the lines
- Extending the benchmark beyond religious text would test whether the observed gaps persist in everyday domains such as news or health information.
- Hybrid approaches that start from a multilingual base and then adapt with the new monolingual data could combine coverage with local quality.
- The release of alignments and models makes it possible to measure how much additional data is needed to close the out-of-domain gap for each language.
Load-bearing premise
The Biblical texts and recordings capture the full range of spelling variation and phonetic coverage found in everyday use of genuinely low-resource languages.
What would settle it
A direct comparison in which models trained on OpenBibleTTS show no intelligibility or preference advantage over models trained on downsampled high-resource data when both are tested on non-Biblical speech from the same low-resource languages.
Figures
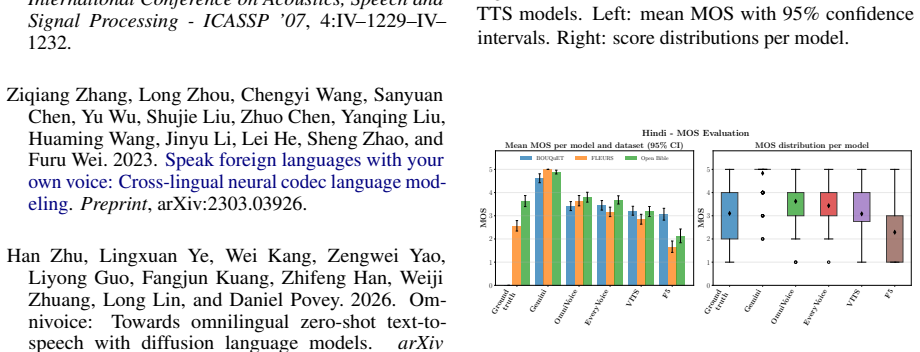
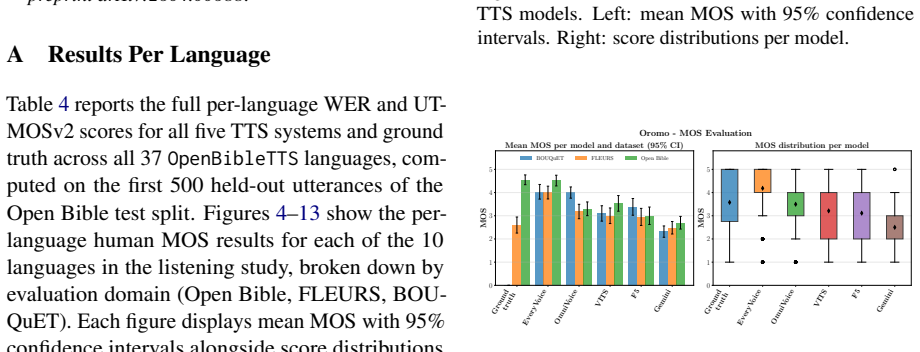
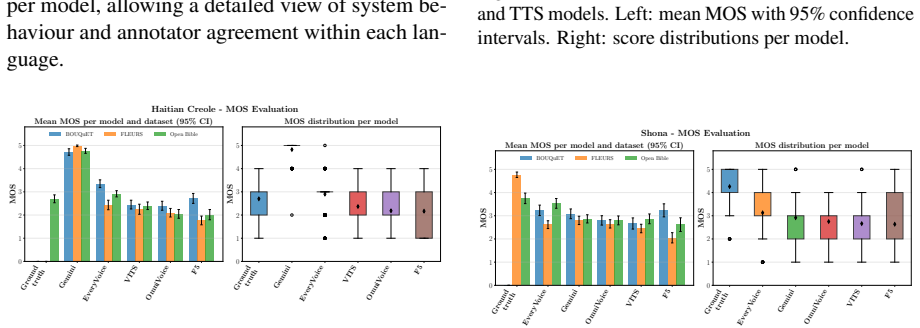
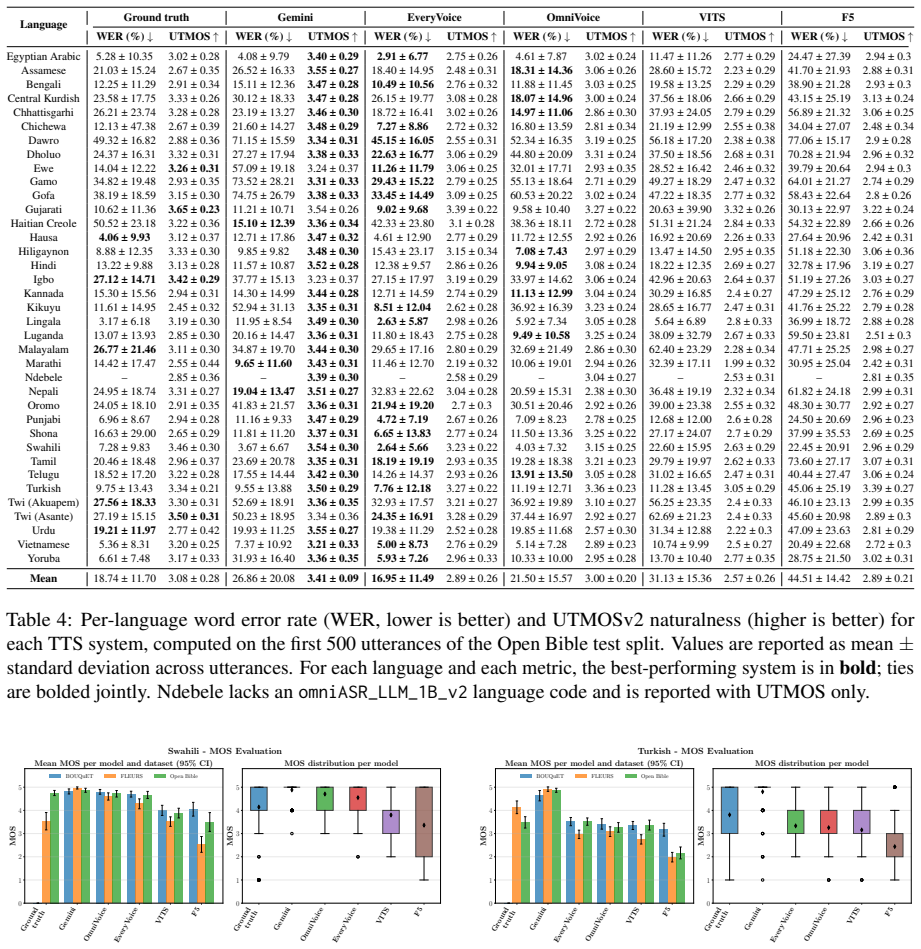
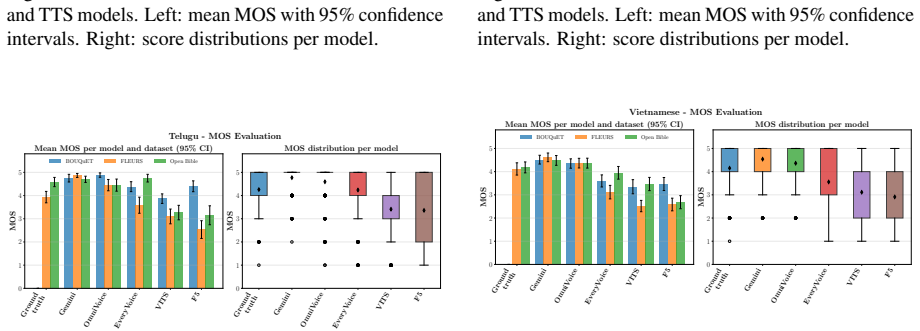
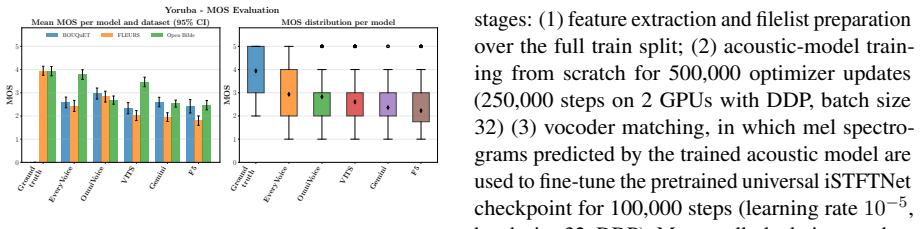

read the original abstract
Recent advances in neural text-to-speech (TTS) and multilingual speech generation have substantially improved synthetic speech quality, yet these gains remain unevenly distributed across the world's languages. Existing models are still dominated by a small set of high-resource languages, while many studies of low-resource TTS are simulated on artificially downsampled high-resource corpora that do not reflect the orthographic variation and limited phonetic coverage encountered in genuinely underrepresented settings. As such, we introduce OpenBibleTTS, which is a large-scale benchmark for low-resource speech synthesis spanning 37 underrepresented languages. Moreover, a systematic comparison of various TTS architectures and large-scale speech generation models is conducted across in-domain Biblical text and out-of-domain material. Results show that no single system dominates across languages and metrics: Gemini-TTS achieves the highest listener ratings on most evaluated languages, but monolingual EveryVoice models trained on OpenBibleTTS remain strongest for intelligibility and are preferred in several African languages, while open from-scratch systems degrade sharply on out-of-domain text, revealing a persistent gap between broad multilingual coverage and reliable synthesis quality in underserved linguistic communities. We complement automatic evaluation with subjective human judgments, and open-source all processed datasets, alignments, and trained models to support future low-resource TTS research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OpenBibleTTS, a large-scale benchmark dataset spanning 37 underrepresented languages derived from Bible translations and recordings. It performs a systematic comparison of TTS architectures and large-scale models (including Gemini-TTS, monolingual EveryVoice models trained on the new data, and open from-scratch systems) on both in-domain Biblical text and out-of-domain material. The central empirical claim is that no single system dominates across languages and metrics: Gemini-TTS receives the highest listener ratings on most languages, EveryVoice models are strongest for intelligibility and preferred in several African languages, and open from-scratch systems degrade sharply on out-of-domain text. Automatic and human evaluations are reported, with all processed datasets, alignments, and trained models to be released.
Significance. If the results hold, this provides a valuable public benchmark and resource for low-resource TTS research that moves beyond artificially downsampled high-resource corpora. The explicit release of data and models is a clear strength that directly supports reproducibility and follow-on work. The finding of persistent out-of-domain degradation even in multilingual systems underscores a practical gap in current approaches for underserved languages.
major comments (2)
- [Abstract and Introduction] Abstract and Introduction: The positioning of OpenBibleTTS as capturing 'orthographic variation and limited phonetic coverage encountered in genuinely underrepresented settings' (contrasted with prior artificially downsampled data) is load-bearing for interpreting the performance gaps, yet no analysis, phonetic inventory statistics, or comparison to colloquial speech is provided to establish that the Bible-derived corpora exhibit these properties distinctly. This weakens attribution of results to the 'genuinely low-resource' setting.
- [Results (human evaluation)] Human evaluation (results section): No quantitative details on data volume per language, inter-rater agreement, or statistical testing of the claimed listener preferences are reported, which is necessary to substantiate the human judgments and the claim that 'no single system dominates'.
minor comments (1)
- [Figures/Tables] Figure and table captions could more explicitly state the number of listeners and languages evaluated to improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Introduction] Abstract and Introduction: The positioning of OpenBibleTTS as capturing 'orthographic variation and limited phonetic coverage encountered in genuinely underrepresented settings' (contrasted with prior artificially downsampled data) is load-bearing for interpreting the performance gaps, yet no analysis, phonetic inventory statistics, or comparison to colloquial speech is provided to establish that the Bible-derived corpora exhibit these properties distinctly. This weakens attribution of results to the 'genuinely low-resource' setting.
Authors: We acknowledge that additional characterization of the Bible-derived corpora would strengthen the positioning. These corpora exhibit orthographic variation across the 37 languages due to differing scripts and conventions in the translations, and phonetic coverage is limited to the vocabulary and sounds present in the formal Biblical text. However, the manuscript does not provide explicit phonetic inventory statistics or comparisons to colloquial speech. We will revise the Abstract and Introduction to include basic quantitative descriptors such as average text length, unique word counts, and character inventories per language. A direct comparison to colloquial speech is not feasible within the current study without new data collection and is noted as a limitation. revision: partial
-
Referee: [Results (human evaluation)] Human evaluation (results section): No quantitative details on data volume per language, inter-rater agreement, or statistical testing of the claimed listener preferences are reported, which is necessary to substantiate the human judgments and the claim that 'no single system dominates'.
Authors: We agree that these details are necessary to support the human evaluation results and the claim that no single system dominates. The manuscript currently reports listener ratings across languages but omits specifics on evaluation volume per language, inter-rater agreement, and statistical tests. In the revised manuscript, we will expand the Results section to include the number of utterances rated per language, inter-rater agreement metrics, and appropriate statistical testing (e.g., significance of preference differences) to substantiate the findings. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential reductions
full rationale
The paper introduces the OpenBibleTTS dataset across 37 languages and reports empirical comparisons of TTS systems (Gemini-TTS, EveryVoice, etc.) on in-domain and out-of-domain text using listener ratings and intelligibility metrics. No equations, first-principles derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the abstract or described content. The central claims rest on direct experimental results and human judgments rather than any chain that reduces outputs to inputs by construction. Self-citations, if present, are not load-bearing for any mathematical result. This is a standard empirical resource paper whose findings are externally falsifiable via the released data and models.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human listener ratings provide a valid and reproducible measure of speech intelligibility and naturalness
- domain assumption The Biblical corpus captures orthographic and phonetic properties of genuinely low-resource languages without the artifacts of artificial downsampling
Reference graph
Works this paper leans on
-
[1]
Scripture in the Languages of the World , year =
-
[2]
F5- TTS : A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Chen, Yushen and Niu, Zhikang and Ma, Ziyang and Deng, Keqi and Wang, Chunhui and JianZhao, JianZhao and Yu, Kai and Chen, Xie. F5- TTS : A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.313
-
[3]
Proceedings of the 38th International Conference on Machine Learning , year =
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech , author =. Proceedings of the 38th International Conference on Machine Learning , year =
-
[4]
2021 , url =
Ren, Yi and Hu, Chenxu and Tan, Xu and Qin, Tao and Zhao, Sheng and Zhao, Zhou and Liu, Tie-Yan , booktitle =. 2021 , url =
2021
-
[5]
ArXiv , year=
A Survey on Neural Speech Synthesis , author=. ArXiv , year=
-
[6]
and Casanova, Edresson and Junior, Arnaldo Candido and Soares, Anderson S
Oliveira, Frederico S. and Casanova, Edresson and Junior, Arnaldo Candido and Soares, Anderson S. and Galv \ a o Filho, Arlindo R. Cml-tts: A multilingual dataset for speech synthesis in low-resource language. Text, Speech, and Dialogue. 2023
2023
-
[7]
Interspeech , year=
MLS: A Large-Scale Multilingual Dataset for Speech Research , author=. Interspeech , year=
-
[8]
2022 IEEE Spoken Language Technology Workshop (SLT) , year=
FLEURS: FEW-Shot Learning Evaluation of Universal Representations of Speech , author=. 2022 IEEE Spoken Language Technology Workshop (SLT) , year=
2022
-
[9]
doi:10.21437/Interspeech.2024-1356 , issn =
Min Ma and Yuma Koizumi and Shigeki Karita and Heiga Zen and Jason Riesa and Haruko Ishikawa and Michiel Bacchiani , year =. doi:10.21437/Interspeech.2024-1356 , issn =
-
[10]
Common Voice: A Massively-Multilingual Speech Corpus
Ardila, Rosana and Branson, Megan and Davis, Kelly and Kohler, Michael and Meyer, Josh and Henretty, Michael and Morais, Reuben and Saunders, Lindsay and Tyers, Francis and Weber, Gregor. Common Voice: A Massively-Multilingual Speech Corpus. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[11]
Perez Ogayo and Graham Neubig and Alan. 2022 , booktitle =. doi:10.21437/Interspeech.2022-152 , issn =
-
[12]
Josh Meyer and David Adelani and Edresson Casanova and Alp Öktem and Daniel Whitenack and Julian Weber and Salomon. 2022 , booktitle =. doi:10.21437/Interspeech.2022-10850 , issn =
-
[13]
Lau, Mingfei and Chen, Qian and Fang, Yeming and Xu, Tingting and Chen, Tongzhou and Golik, Pavel. Data Quality Issues in Multilingual Speech Datasets: The Need for Sociolinguistic Awareness and Proactive Language Planning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v...
-
[14]
Alabi and Xuechen Liu and Dietrich Klakow and Junichi Yamagishi , year =
Jesujoba O. Alabi and Xuechen Liu and Dietrich Klakow and Junichi Yamagishi , year =. doi:10.21437/Interspeech.2025-1437 , issn =
-
[15]
ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , year=
CMU Wilderness Multilingual Speech Dataset , author=. ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , year=
2019
-
[16]
2007 IEEE International Conference on Acoustics, Speech and Signal Processing - ICASSP '07 , year=
Statistical Parametric Speech Synthesis , author=. 2007 IEEE International Conference on Acoustics, Speech and Signal Processing - ICASSP '07 , year=
2007
-
[17]
Skerry-Ryan and Daisy Stanton and Yonghui Wu and Ron J
Yuxuan Wang and R.J. Skerry-Ryan and Daisy Stanton and Yonghui Wu and Ron J. Weiss and Navdeep Jaitly and Zongheng Yang and Ying Xiao and Zhifeng Chen and Samy Bengio and Quoc Le and Yannis Agiomyrgiannakis and Rob Clark and Rif A. Saurous , year =. doi:10.21437/Interspeech.2017-1452 , issn =
-
[18]
2016 , booktitle =
Aäron. 2016 , booktitle =
2016
-
[19]
ArXiv , year=
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis , author=. ArXiv , year=
-
[20]
Ryan Prenger and Rafael Valle and Bryan Catanzaro , title =. CoRR , volume =. 2018 , url =. 1811.00002 , timestamp =
Pith/arXiv arXiv 2018
-
[21]
arXiv preprint arXiv:2604.00688 , year=
OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models , author=. arXiv preprint arXiv:2604.00688 , year=
-
[22]
V oice C raft- X : Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing
Zheng, Zhisheng and Peng, Puyuan and Diwan, Anuj and Huynh, Cong Phuoc and Sun, Xiaohang and Liu, Zhu and Bhat, Vimal and Harwath, David. V oice C raft- X : Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.137
-
[23]
Proceedings of the 39th International Conference on Machine Learning , pages =
Casanova, Edresson and Weber, Julian and Shulby, Christopher D and Junior, Arnaldo Candido and G. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[24]
2023 , eprint=
Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling , author=. 2023 , eprint=
2023
-
[25]
Ziyue Jiang and Jinglin Liu and Yi Ren and Jinzheng He and Zhenhui Ye and Shengpeng Ji and Qian Yang and Chen Zhang and Pengfei Wei and Chunfeng Wang and Xiang Yin and Zejun MA and Zhou Zhao , booktitle=. Mega-. 2024 , url=
2024
-
[26]
Yuma Koizumi and Heiga Zen and Shigeki Karita and Yifan Ding and Kohei Yatabe and Nobuyuki Morioka and Michiel Bacchiani and Yu Zhang and Wei Han and Ankur Bapna , year=. 2305.18802 , booktitle=
-
[27]
Kim, Youngjae and Jeon, Yejin and Lee, Gary. Audio-Based Linguistic Feature Extraction for Enhancing Multi-lingual and Low-Resource Text-to-Speech. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.817
-
[28]
Interspeech , primaryClass=
CSS10: A Collection of Single Speaker Speech Datasets for 10 Languages , author=. Interspeech , primaryClass=. 2019 , eprint=
2019
-
[29]
Text-to-Speech for Under-Resourced Languages: Phoneme Mapping and Source Language Selection in Transfer Learning
Do, Phat and Coler, Matt and Dijkstra, Jelske and Klabbers, Esther. Text-to-Speech for Under-Resourced Languages: Phoneme Mapping and Source Language Selection in Transfer Learning. Proceedings of the 1st Annual Meeting of the ELRA/ISCA Special Interest Group on Under-Resourced Languages. 2022
2022
-
[30]
Speech Synthesis Workshop , primaryClass=
Strategies in Transfer Learning for Low-Resource Speech Synthesis: Phone Mapping, Features Input, and Source Language Selection , author=. Speech Synthesis Workshop , primaryClass=. 2023 , eprint=
2023
-
[31]
Transfer Learning for Low-Resource, Multi-Lingual, and Zero-Shot Multi-Speaker Text-to-Speech , year=
Jeong, Myeonghun and Kim, Minchan and Choi, Byoung Jin and Yoon, Jaesam and Jang, Won and Kim, Nam Soo , journal=. Transfer Learning for Low-Resource, Multi-Lingual, and Zero-Shot Multi-Speaker Text-to-Speech , year=
-
[32]
2024 , volume=
Saeki, Takaaki and Maiti, Soumi and Li, Xinjian and Watanabe, Shinji and Takamichi, Shinnosuke and Saruwatari, Hiroshi , journal=. 2024 , volume=
2024
-
[33]
International Joint Conference ON Artificial Intelligence (IJCAI) , year=
Learning to Speak from Text: Zero-Shot Multilingual Text-to-Speech with Unsupervised Text Pretraining , author=. International Joint Conference ON Artificial Intelligence (IJCAI) , year=
-
[34]
Low-Resource Multilingual and Zero-Shot Multispeaker TTS
Lux, Florian and Koch, Julia and Vu, Ngoc Thang. Low-Resource Multilingual and Zero-Shot Multispeaker TTS. Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.aacl-main.56
-
[35]
Goyal, Naman and Gao, Cynthia and Chaudhary, Vishrav and Chen, Peng-Jen and Wenzek, Guillaume and Ju, Da and Krishnan, Sanjana and Ranzato, Marc ' Aurelio and Guzm \'a n, Francisco and Fan, Angela. The F lores-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation. Transactions of the Association for Computational Linguistics. 2022...
-
[36]
Andrews, Pierre and Artetxe, Mikel and Meglioli, Mariano Coria and Costa-juss \`a , Marta R. and Chuang, Joe and Dale, David and Duppenthaler, Mark and Ekberg, Nathanial Paul and Gao, Cynthia and Licht, Daniel Edward and Maillard, Jean and Mourachko, Alexandre and Ropers, Christophe and Saleem, Safiyyah and S \'a nchez, Eduardo and Tsiamas, Ioannis and Tu...
-
[37]
2024 IEEE Spoken Language Technology Workshop (SLT) , year=
E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS , author=. 2024 IEEE Spoken Language Technology Workshop (SLT) , year=
2024
-
[38]
doi:10.21437/Interspeech.2024-2016 , issn =
Edresson Casanova and Kelly Davis and Eren Gölge and Görkem Göknar and Iulian Gulea and Logan Hart and Aya Aljafari and Joshua Meyer and Reuben Morais and Samuel Olayemi and Julian Weber , year =. doi:10.21437/Interspeech.2024-2016 , issn =
-
[39]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , year=
ZMM-TTS: Zero-Shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-Supervised Discrete Speech Representations , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , year=
-
[40]
Florian Lux and Sarina Meyer and Lyonel Behringer and Frank Zalkow and Phat Do and Matt Coler and Emanuël A. P. Habets and Ngoc Thang Vu , year =. doi:10.21437/Interspeech.2024-1335 , issn =
-
[41]
ArXiv , year=
Qwen3-TTS Technical Report , author=. ArXiv , year=
-
[42]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[43]
2025 , eprint=
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages , author=. 2025 , eprint=
2025
-
[44]
The T05 System for The
Baba, Kaito and Nakata, Wataru and Saito, Yuki and Saruwatari, Hiroshi , booktitle =. The T05 System for The. 2024 , pages =
2024
-
[45]
Vocos: Closing the Gap between Time-Domain and
Siuzdak, Hubert , booktitle =. Vocos: Closing the Gap between Time-Domain and. 2024 , url =
2024
-
[46]
2023 , url =
Lee, Sang-gil and Ping, Wei and Ginsburg, Boris and Catanzaro, Bryan and Yoon, Sungroh , booktitle =. 2023 , url =
2023
-
[47]
2025 , howpublished =
2025
-
[48]
Speech Generation for
Pine, Aidan and Cooper, Erica and Guzm. Speech Generation for. Computer Speech & Language , volume =. 2024 , doi =
2024
-
[49]
R ead A long Studio: Practical Zero-Shot Text-Speech Alignment for Indigenous Language Audiobooks
Littell, Patrick and Joanis, Eric and Pine, Aidan and Tessier, Marc and Huggins Daines, David and Torkornoo, Delasie. R ead A long Studio: Practical Zero-Shot Text-Speech Alignment for Indigenous Language Audiobooks. Proceedings of the 1st Annual Meeting of the ELRA/ISCA Special Interest Group on Under-Resourced Languages. 2022
2022
-
[50]
doi:10.21437/Interspeech.2023-105 , issn =
Hervé Bredin , year =. doi:10.21437/Interspeech.2023-105 , issn =
-
[51]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[52]
2023 , eprint=
Scaling Speech Technology to 1,000+ Languages , author=. 2023 , eprint=
2023
-
[53]
2022 , eprint=
iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform , author=. 2022 , eprint=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.