CT-VAM: A Cerebello-Thalamic-Inspired Vision-Action Model for Efficient Visuomotor Control
Pith reviewed 2026-06-27 15:58 UTC · model grok-4.3
The pith
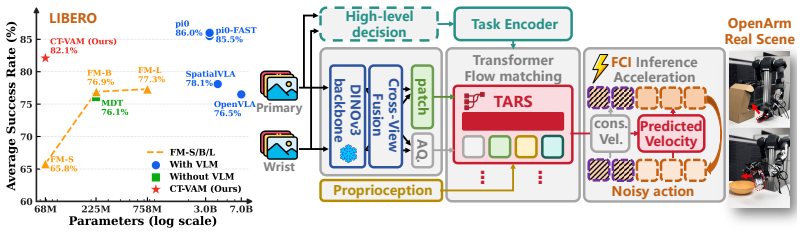
A 68M-parameter model matches larger VLA models on robot manipulation tasks while cutting inference latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CT-VAM is a cerebello-thalamic-inspired vision-action model that predicts action chunks from dual-view visual observations, proprioception, and a lightweight task condition; its TARS stream-separated conditional attention decoder independently routes action, visual, and task streams to prevent dense sensory tokens from overwhelming compact task-relevant conditions, yielding LIBERO success rates competitive with substantially larger VLA models at 68M parameters together with reduced inference latency and support for asynchronous chunk execution via flow-consistent inpainting.
What carries the argument
TARS (Thalamic Action Routing Stream), a stream-separated conditional attention decoder that independently routes action, visual, and task streams.
If this is right
- High-level semantic planning can be offloaded to large models while low-level control runs locally at high frequency.
- The same architecture supports robust deployment on resource-constrained robotic hardware.
- Action chunk prediction with flow-consistent inpainting enables continuous closed-loop execution without waiting for full language re-processing.
- Inference latency drops relative to monolithic VLA models of similar capability.
Where Pith is reading between the lines
- The same stream-separation principle could be tested on non-manipulation sensorimotor loops such as navigation or locomotion.
- If the lightweight task condition proves sufficient, future work could measure how small the condition can become before performance collapses.
- The cloud-edge split suggested by the design invites direct measurement of end-to-end latency and communication cost in a distributed setup.
Load-bearing premise
The TARS decoder can route the three input streams independently so that dense visual tokens do not overwhelm the compact task condition.
What would settle it
A controlled ablation in which removing the stream separation from TARS causes LIBERO success rates to fall below those of the full 68M model would falsify the routing claim.
Figures





read the original abstract
Vision-language-action models have shown strong promise for robot manipulation, yet raw language is primarily needed to specify task intent rather than to be repeatedly processed during high-frequency low-level execution. Motivated by this separation, we propose a cerebello-thalamic-inspired vision-action model (CT-VAM) for efficient task-conditioned visuomotor control. CT-VAM acts as a compact local execution policy that predicts action chunks from dualview visual observations, proprioception, and a lightweight task condition, potentially enabling a practical cloud-edge paradigm in which high-level semantic reasoning can be handled by large models while fast closed-loop control runs on local hardware. To fuse heterogeneous inputs effectively, CT-VAM introduces TARS (Thalamic Action Routing Stream), a stream-separated conditional attention decoder that independently routes action, visual and task streams, preventing dense sensory tokens from overwhelming compact task-relevant conditions. With only 68M parameters, CT-VAM achieves LIBERO success rates competitive with substantially larger VLA models, while reducing inference latency. Together with flow-consistent inpainting for asynchronous chunk execution, CT-VAM supports high-frequency control and demonstrates robust realworld deployment on resource-constrained robotic platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CT-VAM, a 68M-parameter cerebello-thalamic-inspired vision-action model for efficient task-conditioned visuomotor control. It introduces TARS, a stream-separated conditional attention decoder to fuse dual-view visual observations, proprioception, and a lightweight task condition without dense sensory tokens overwhelming task-relevant information. The model is framed as a compact local execution policy that can complement large VLMs in a cloud-edge setup, with additional support from flow-consistent inpainting for asynchronous chunk execution. The central claims are competitive LIBERO success rates versus larger VLA models, reduced inference latency, high-frequency control capability, and robust real-world deployment on resource-constrained platforms.
Significance. If the performance and efficiency claims are substantiated, the work could meaningfully advance practical deployment of visuomotor policies by enabling separation of high-level semantic reasoning (cloud) from low-level closed-loop control (edge), with bio-inspired mechanisms potentially improving input fusion efficiency in robotics.
major comments (2)
- [Abstract] Abstract: the claim that CT-VAM 'achieves LIBERO success rates competitive with substantially larger VLA models' is presented without any numerical success rates, named baseline models, ablation results, or error bars, rendering the central efficiency-performance tradeoff impossible to evaluate.
- [Abstract] Abstract: the description of TARS as independently routing action, visual, and task streams to prevent dense tokens from overwhelming compact conditions is stated at a high level with no architectural equations, attention formulations, or empirical verification of the separation mechanism, which is load-bearing for the claimed fusion advantage.
minor comments (2)
- [Abstract] Abstract: 'dualview' should be hyphenated as 'dual-view' for clarity.
- [Abstract] Abstract: 'realworld' should be 'real-world'.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each major comment below and have revised the manuscript to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CT-VAM 'achieves LIBERO success rates competitive with substantially larger VLA models' is presented without any numerical success rates, named baseline models, ablation results, or error bars, rendering the central efficiency-performance tradeoff impossible to evaluate.
Authors: We agree with this observation. To better substantiate the central claim, we will revise the abstract to include specific numerical success rates from our LIBERO experiments, the names of the baseline VLA models, and reference to error bars. The detailed results and ablations are presented in Section 4, but incorporating key figures into the abstract will allow readers to evaluate the efficiency-performance tradeoff immediately. revision: yes
-
Referee: [Abstract] Abstract: the description of TARS as independently routing action, visual, and task streams to prevent dense tokens from overwhelming compact conditions is stated at a high level with no architectural equations, attention formulations, or empirical verification of the separation mechanism, which is load-bearing for the claimed fusion advantage.
Authors: The abstract is intended to be high-level, with full architectural details, equations for the stream-separated conditional attention, and empirical ablations verifying the separation mechanism provided in Sections 3.2 and 4.3 of the manuscript. However, to address the concern directly, we will revise the abstract description to be more precise regarding the mechanism. We cannot include full equations due to abstract length constraints, but the revision will better highlight the separation benefit with reference to the empirical verification in the paper. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present CT-VAM as an empirically validated architecture whose performance claims rest on LIBERO benchmark success rates and latency measurements rather than any closed-form derivation. No equations, fitted parameters presented as predictions, self-citations invoked as uniqueness theorems, or ansatzes smuggled via prior work are visible. The TARS decoder is introduced as a design choice motivated by biological analogy and input-fusion needs; its effectiveness is asserted via experimental outcomes, not by construction from the inputs themselves. This is the expected non-finding for a systems paper whose central results are benchmark-driven.
Axiom & Free-Parameter Ledger
invented entities (1)
-
TARS (Thalamic Action Routing Stream)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Huang, P
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR, 2022
2022
-
[2]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do As I Can, Not As I Say: Grounding language in robotic affor- dances.arXiv preprint arXiv:2204.01691, 2022
Pith/arXiv arXiv 2022
-
[3]
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. PaLM-E: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
Pith/arXiv arXiv 2023
-
[4]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[5]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[6]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open X-Embodiment: Robotic learning datasets and RT-X mod- els: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[7]
URL https://www.roboticsproceedings.org/ rss21/p010.html
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky. π0: A vision-language-action flow model for general robot control. InProceeding...
-
[8]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. OpenVLA: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[9]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023. 9
2023
-
[10]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[11]
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters, 2025
2025
-
[12]
H. Wang, C. Xiong, R. Wang, and X. Chen. Bitvla: 1-bit vision-language-action models for robotics manipulation.arXiv preprint arXiv:2506.07530, 2025
arXiv 2025
-
[13]
S. Ye, J. Jang, B. Jeon, S. J. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos. InInternational Conference on Learning Representations, volume 2025, pages 28213–28239, 2025
2025
-
[14]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spa- tialVLA: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[15]
Pertsch, K
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models. InRobotics: Science and Systems, 2025
2025
-
[16]
Reuss, ¨O
M. Reuss, ¨O. E. Ya˘gmurlu, F. Wenzel, and R. Lioutikov. Multimodal diffusion transformer: Learning versatile behavior from multimodal goals. InRobotics: Science and Systems, 2024
2024
-
[17]
Y . Guo, J. Li, Q. Liu, W. Fu, J. Qin, and Y . Kang. DG-ACMP: Deformation-guided motion planning with acceptable contacts for manipulators in cluttered environments.IEEE Robotics and Automation Letters, 2026
2026
-
[18]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[19]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023
2023
-
[20]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, et al. DINOv3.arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[21]
Y . Wang, P. Ding, L. Li, C. Cui, Z. Ge, X. Tong, W. Song, H. Zhao, W. Zhao, P. Hou, et al. VLA-Adapter: An effective paradigm for tiny-scale vision-language-action model. InPro- ceedings of the AAAI conference on artificial intelligence, volume 40, pages 18638–18646, 2026
2026
-
[22]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Cliport: What and where pathways for robotic manipu- lation. InConference on robot learning, pages 894–906. PMLR, 2022
2022
-
[23]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
2023
-
[24]
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023
Pith/arXiv arXiv 2023
-
[25]
R. A. Fisher. On the mathematical foundations of theoretical statistics.Philosophical Trans- actions of the Royal Society of London. Series A, 222:309–368, 1922
1922
-
[26]
T. M. Cover and J. A. Thomas.Elements of Information Theory. Wiley-Interscience, 2 edition, 2006. 10
2006
-
[27]
N. Tishby, F. C. Pereira, and W. Bialek. The information bottleneck method.arXiv preprint physics/0004057, 2000
Pith/arXiv arXiv 2000
-
[28]
Darcet, M
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision transformers need registers. In International conference on learning representations, volume 2024, pages 2632–2652, 2024
2024
-
[29]
NVIDIA Jetson Orin Series.https://www.nvidia.com/en-us/ autonomous-machines/embedded-systems/jetson-orin/, 2025
NVIDIA. NVIDIA Jetson Orin Series.https://www.nvidia.com/en-us/ autonomous-machines/embedded-systems/jetson-orin/, 2025. Accessed: 2026-06- 07
2025
-
[30]
NVIDIA TensorRT Documentation.https://docs.nvidia.com/ deeplearning/tensorrt/latest/, 2025
NVIDIA. NVIDIA TensorRT Documentation.https://docs.nvidia.com/ deeplearning/tensorrt/latest/, 2025. Accessed: 2026-06-07
2025
-
[31]
Open Neural Network Exchange.https://onnx.ai/, 2025
ONNX Community. Open Neural Network Exchange.https://onnx.ai/, 2025. Accessed: 2026-06-07. 11 A Theoretical Details A.1 Interpretation of Grounded Intent The grounded intentGis not assumed to be a language string. It may be an explicit task identifier, a latent instruction feature, a goal-like representation, or a structured state that encodes the task- r...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.