TUDSR: Twice Upsampling-Diffusion for Higher Super-Resolution
Pith reviewed 2026-06-27 16:48 UTC · model grok-4.3
The pith
A twice-upsampling diffusion method with chunked higher-resolution training produces usable 2048x2048 images from base diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
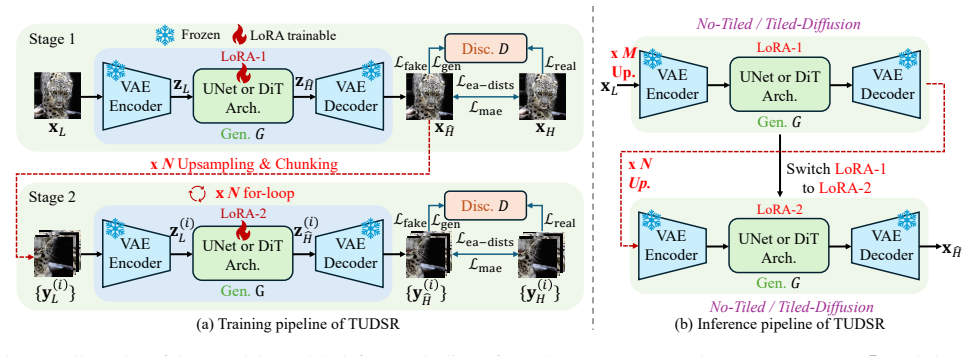
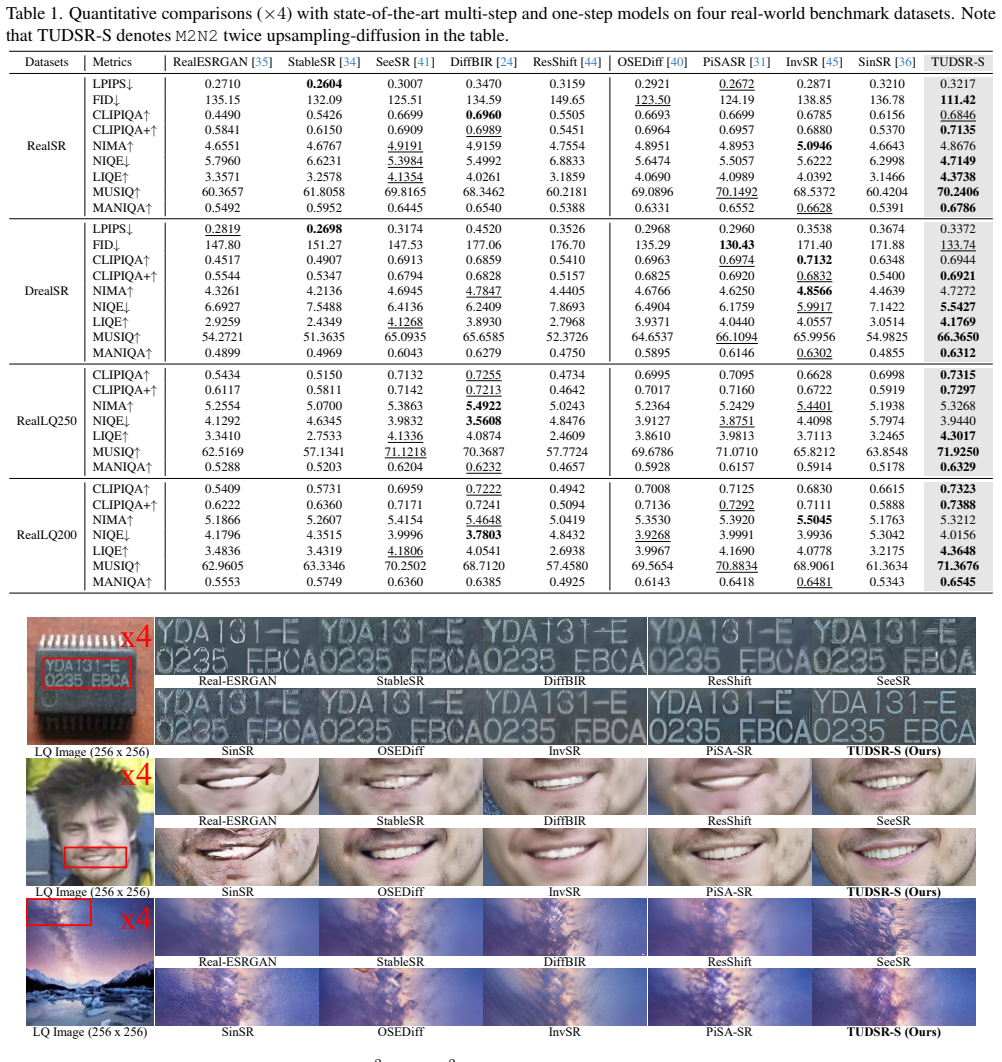
TUDSR consists of two stages: first training at R-resolution, then applying a looped chunk-based training strategy at NR-resolution; each stage uses a one-step GAN architecture of generator plus discriminator. Based on SD2.1-base, the resulting TUDSR-S model reaches state-of-the-art performance on multiple benchmarks and produces high-quality images at 1024 squared and 2048 squared resolutions that significantly outperform prior methods.
What carries the argument
Twice Upsampling-Diffusion (TUDSR) framework that combines R-resolution training with looped chunk-based NR-resolution training inside one-step GAN stages.
If this is right
- The method yields state-of-the-art results on existing super-resolution benchmarks.
- It produces usable images at 1024 squared and 2048 squared without building larger base architectures.
- Training remains feasible on limited-resource hardware because full native high-resolution models are avoided.
- The two-stage process with chunked loops directly addresses quality drop when upsampling ratios exceed native model support.
Where Pith is reading between the lines
- The chunking strategy could be tested on other diffusion backbones beyond SD2.1 to check if the quality gain generalizes.
- If the one-step GAN stages prove stable, the same loop pattern might apply to video or 3D generation tasks that also hit resolution ceilings.
- Hardware-constrained labs could adopt this staged approach to explore higher resolutions without immediate need for larger clusters.
Load-bearing premise
The looped chunk training at higher resolution keeps image quality intact and avoids new artifacts once the upsampling ratio passes the model's original native limit.
What would settle it
Generate 2048x2048 images with TUDSR-S on standard benchmarks and compare perceptual quality and artifact levels against a native high-resolution diffusion model trained directly at that scale; clear, consistent degradation in the TUDSR outputs would falsify the central claim.
Figures






read the original abstract
Diffusion-based generative models have achieved remarkable success in real-world image super-resolution (SR). With tiled diffusion techniques, these models can produce high-resolution images that exceed their native-supported resolution. However, the quality of such high-resolution (e.g $2048^2$) outputs often remains extremely poor, primarily due to two factors we consider: the image upsampling ratio (e.g $\times8$) exceeding the model's native-supported upsampling ratio (e.g $\times4$), and the model's native-supported resolution. In practice, training a native high-resolution model requires larger architectures, which incur significant computational overhead and GPU memory costs, making it hard on limited-resource equipment. Thus, we present TUDSR, a Twice Upsampling-Diffusion framework for higher SR. The TUDSR framework mainly consists of two stages: the first involves training at $R$-resolution, and the second introduces a looped chunk-based training strategy at $NR$-resolution. Each stage adapts a one-step GAN architecture comprising a generator and a discriminator. Based on SD2.1-base, we develop TUDSR-S, which achieves state-of-the-art performance across multiple benchmarks. Extensive experiments further demonstrate that TUDSR-S generates high-quality images at the resolutions of $1024^2$ and even $2048^2$, significantly outperforming existing approaches. Code is available at https://github.com/wuer5/TUDSR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TUDSR, a Twice Upsampling-Diffusion framework consisting of two stages—training at R-resolution followed by looped chunk-based training at NR-resolution—each employing a one-step GAN (generator + discriminator). Built on SD2.1-base as TUDSR-S, it claims state-of-the-art performance on multiple SR benchmarks and the ability to generate high-quality outputs at 1024² and 2048² resolutions, addressing limitations of tiled diffusion when upsampling ratios exceed the model's native ×4 limit.
Significance. If the central claims hold with rigorous validation, the approach would offer a practical route to high-resolution SR on limited hardware by avoiding the need for larger native high-res models, while leveraging existing diffusion backbones. The public code release supports reproducibility and potential follow-up work.
major comments (2)
- [Method (looped chunk-based training)] The looped chunk-based training strategy at NR-resolution (described in the method) provides no explicit mechanism—such as chunk overlap, blending functions, or global consistency loss—for enforcing boundary consistency. This directly undermines the claim of artifact-free outputs at ×8 upsampling to 2048², as local chunk optimization can produce visible seams or texture inconsistencies.
- [Abstract and Experiments] The SOTA assertion and high-resolution quality claims rest on performance comparisons, yet the manuscript supplies no quantitative metrics, baseline tables, or ablation results in the abstract or early sections to substantiate that TUDSR-S outperforms existing tiled-diffusion and one-step GAN methods.
minor comments (2)
- [Introduction] Notation for R-resolution and NR-resolution is introduced without a clear definition or diagram showing how the twice-upsampling stages compose.
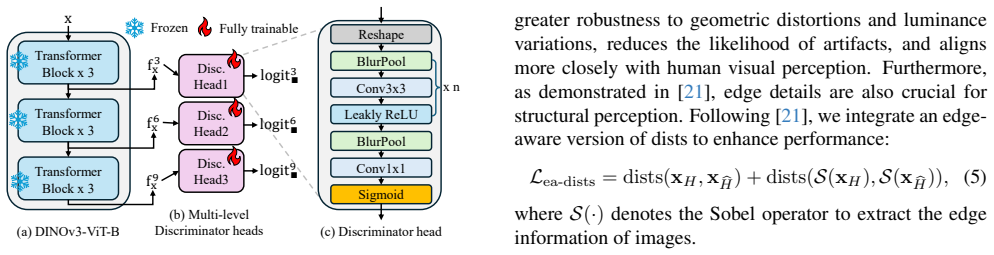
- [Method] The one-step GAN architecture is referenced but lacks a precise description of how the discriminator is trained or how it interacts with the diffusion component across stages.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our method and results. We respond to each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: The looped chunk-based training strategy at NR-resolution (described in the method) provides no explicit mechanism—such as chunk overlap, blending functions, or global consistency loss—for enforcing boundary consistency. This directly undermines the claim of artifact-free outputs at ×8 upsampling to 2048², as local chunk optimization can produce visible seams or texture inconsistencies.
Authors: We agree that the manuscript's description of the looped chunk-based training does not explicitly specify boundary-handling mechanisms such as overlap or blending. In the revised version we will expand the method section to detail the chunking procedure, including any implicit consistency arising from the looping schedule and one-step GAN training, and we will add overlap/blending where needed along with corresponding ablation visuals to substantiate the artifact-free claim at 2048². revision: yes
-
Referee: The SOTA assertion and high-resolution quality claims rest on performance comparisons, yet the manuscript supplies no quantitative metrics, baseline tables, or ablation results in the abstract or early sections to substantiate that TUDSR-S outperforms existing tiled-diffusion and one-step GAN methods.
Authors: The abstract is intentionally concise and defers quantitative details to the Experiments section, where tables and ablations appear. To strengthen early substantiation we will insert a short summary paragraph with key metric improvements (e.g., PSNR/SSIM/LPIPS deltas versus tiled baselines) into the Introduction and will ensure the abstract's SOTA statement is directly tied to those reported numbers. revision: partial
Circularity Check
No circularity: engineering framework with empirical claims only
full rationale
The paper describes a two-stage training procedure (R-resolution then NR-resolution looped chunks) plus one-step GAN adaptation of SD2.1-base. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted inputs or self-citations. Performance claims rest on benchmark comparisons rather than any closed theoretical loop. This is a standard engineering contribution with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption One-step GAN architectures can be adapted for diffusion-based super-resolution training
invented entities (1)
-
TUDSR two-stage framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dream- clear: High-capacity real-world image restoration with privacy-safe dataset curation.Advances in Neural Informa- tion Processing Systems, 37:55443–55469, 2024
Yuang Ai, Xiaoqiang Zhou, Huaibo Huang, Xiaotian Han, Zhengyu Chen, Quanzeng You, and Hongxia Yang. Dream- clear: High-capacity real-world image restoration with privacy-safe dataset curation.Advances in Neural Informa- tion Processing Systems, 37:55443–55469, 2024. 5
2024
-
[2]
arXiv preprint arXiv:2112.058142(3), 4 (2021)
Shir Amir, Yossi Gandelsman, Shai Bagon, and Tali Dekel. Deep vit features as dense visual descriptors.arXiv preprint arXiv:2112.05814, 2(3):4, 2021. 4
-
[3]
Toward real-world single image super-resolution: A new benchmark and a new model
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. InProceedings of the IEEE/CVF international conference on computer vision, pages 3086–3095, 2019. 5
2019
-
[4]
Toward real-world single image super-resolution: A new benchmark and a new model
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. InProceedings of the IEEE/CVF international conference on computer vision, pages 3086–3095, 2019. 1
2019
-
[5]
Real-world single image super-resolution: A brief review.Information Fusion, 79:124–145, 2022
Honggang Chen, Xiaohai He, Linbo Qing, Yuanyuan Wu, Chao Ren, Ray E Sheriff, and Ce Zhu. Real-world single image super-resolution: A brief review.Information Fusion, 79:124–145, 2022. 1
2022
-
[6]
Frequency-dynamic attention modulation for dense prediction
Linwei Chen, Lin Gu, and Ying Fu. Frequency-dynamic attention modulation for dense prediction. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 22620–22632, 2025. 4
2025
-
[7]
Learning a deep convolutional network for image super-resolution
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. InEuropean conference on computer vi- sion, pages 184–199. Springer, 2014. 1
2014
-
[8]
Image super-resolution using deep convolutional net- works.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional net- works.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015
2015
-
[9]
Yitong Dong, Qi Zhang, Minchao Jiang, Zhiqiang Wu, Qingnan Fan, Ying Feng, Huaqi Zhang, Hujun Bao, and Guofeng Zhang. One-shot refiner: Boosting feed-forward novel view synthesis via one-step diffusion.arXiv preprint arXiv:2601.14161, 2026. 1
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions, 2021. 4
2021
-
[11]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[12]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020. 2, 3
2020
-
[13]
Pablo Hern ´andez-C´amara, Jose Manuel Ja ´en-Lorites, Jorge Vila-Tom´as, Valero Laparra, and Jesus Malo. Do vision transformers see like humans? evaluating their perceptual alignment.arXiv preprint arXiv:2508.09850, 2025. 4
-
[14]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 5
2017
-
[15]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2
2020
-
[16]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 1
2022
-
[17]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 5
2019
-
[18]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021. 5
2021
-
[19]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013. 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 1, 2
2024
-
[21]
Jianze Li, Jiezhang Cao, Zichen Zou, Xiongfei Su, Xin Yuan, Yulun Zhang, Yong Guo, and Xiaokang Yang. Un- leashing the power of one-step diffusion based image super- resolution via a large-scale diffusion discriminator.arXiv preprint arXiv:2410.04224, 2024. 4
-
[22]
One diffusion step to real- world super-resolution via flow trajectory distillation,
Jianze Li, Jiezhang Cao, Yong Guo, Wenbo Li, and Yulun Zhang. One diffusion step to real-world super-resolution via flow trajectory distillation.arXiv preprint arXiv:2502.01993,
-
[23]
Lsdir: A large scale dataset for image restoration
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Deman- dolx, et al. Lsdir: A large scale dataset for image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1775–1787, 2023. 5
2023
-
[24]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InEuropean conference on computer vision, pages 430–448. Springer, 2024. 2, 5, 6
2024
-
[25]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 5
2019
-
[26]
Tiled diffusion
Or Madar and Ohad Fried. Tiled diffusion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7795–7804, 2025. 1, 2
2025
-
[27]
completely blind
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Mak- ing a “completely blind” image quality analyzer.IEEE Sig- nal processing letters, 20(3):209–212, 2012. 5
2012
-
[28]
Diffusion models, image super-resolution, and everything: A survey.IEEE Transactions on Neural Networks and Learn- ing Systems, 2024
Brian B Moser, Arundhati S Shanbhag, Federico Raue, Stanislav Frolov, Sebastian Palacio, and Andreas Dengel. Diffusion models, image super-resolution, and everything: A survey.IEEE Transactions on Neural Networks and Learn- ing Systems, 2024. 1
2024
-
[29]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 2
2022
-
[30]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
2025
-
[31]
Pixel-level and semantic-level ad- justable super-resolution: A dual-lora approach
Lingchen Sun, Rongyuan Wu, Zhiyuan Ma, Shuaizheng Liu, Qiaosi Yi, and Lei Zhang. Pixel-level and semantic-level ad- justable super-resolution: A dual-lora approach. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 2333–2343, 2025. 1, 2, 5, 6
2025
-
[32]
Nima: Neural image assessment.IEEE transactions on image processing, 27(8): 3998–4011, 2018
Hossein Talebi and Peyman Milanfar. Nima: Neural image assessment.IEEE transactions on image processing, 27(8): 3998–4011, 2018. 5
2018
-
[33]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. InPro- ceedings of the AAAI conference on artificial intelligence, pages 2555–2563, 2023. 5
2023
-
[34]
Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12):5929–5949, 2024
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12):5929–5949, 2024. 2, 5, 6
2024
-
[35]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1905–1914,
1905
-
[36]
Sinsr: diffusion-based image super- resolution in a single step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C Kot, and Bihan Wen. Sinsr: diffusion-based image super- resolution in a single step. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25796–25805, 2024. 1, 2, 5, 6
2024
-
[37]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 5
2004
-
[38]
Deep learn- ing for image super-resolution: A survey.IEEE transactions on pattern analysis and machine intelligence, 43(10):3365– 3387, 2020
Zhihao Wang, Jian Chen, and Steven CH Hoi. Deep learn- ing for image super-resolution: A survey.IEEE transactions on pattern analysis and machine intelligence, 43(10):3365– 3387, 2020. 1
2020
-
[39]
Component divide-and-conquer for real-world image super-resolution
Pengxu Wei, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qix- iang Ye, Wangmeng Zuo, and Liang Lin. Component divide-and-conquer for real-world image super-resolution. In European conference on computer vision, pages 101–117. Springer, 2020. 5
2020
-
[40]
One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024. 1, 2, 5, 6
2024
-
[41]
Seesr: Towards semantics- aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics- aware real-world image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25456–25467, 2024. 2, 5, 6
2024
-
[42]
Vit-comer: Vision transformer with convolu- tional multi-scale feature interaction for dense predictions
Chunlong Xia, Xinliang Wang, Feng Lv, Xin Hao, and Yifeng Shi. Vit-comer: Vision transformer with convolu- tional multi-scale feature interaction for dense predictions. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 5493–5502, 2024. 4
2024
-
[43]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022. 5
2022
-
[44]
Resshift: Efficient diffusion model for image super- resolution by residual shifting.Advances in Neural Infor- mation Processing Systems, 36:13294–13307, 2023
Zongsheng Yue, Jianyi Wang, and Chen Change Loy. Resshift: Efficient diffusion model for image super- resolution by residual shifting.Advances in Neural Infor- mation Processing Systems, 36:13294–13307, 2023. 2, 5, 6
2023
-
[45]
Arbitrary-steps image super-resolution via diffusion inver- sion
Zongsheng Yue, Kang Liao, and Chen Change Loy. Arbitrary-steps image super-resolution via diffusion inver- sion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23153–23163, 2025. 2, 5, 6
2025
-
[46]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 1
2023
-
[47]
Making convolutional networks shift- invariant again
Richard Zhang. Making convolutional networks shift- invariant again. InInternational conference on machine learning, pages 7324–7334. PMLR, 2019. 4
2019
-
[48]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 4, 5
2018
-
[49]
Blind image quality assessment via vision- language correspondence: A multitask learning perspective
Weixia Zhang, Guangtao Zhai, Ying Wei, Xiaokang Yang, and Kede Ma. Blind image quality assessment via vision- language correspondence: A multitask learning perspective. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14071–14081, 2023. 5 TUDSR: Twice Upsampling-Diffusion for Higher Super-Resolution Supplementar...
2023
-
[50]
The quality of the image generated byM8is also significantly lower than that ofM4N2, whileN8achieves the worst results
More Visualizations on TUDSR-S (×8) Figure 7 shows more visualizations of twice upsampling- diffusion (×8) on TUDSR-S.M4N2achieves the best clarity and detail across all10cases from RealLQ250. The quality of the image generated byM8is also significantly lower than that ofM4N2, whileN8achieves the worst results. This result indicates that decomposing×8into...
-
[51]
TUDSR-S exhibits overwhelming perfor- mance across these one-step models, highlighting the effec- tiveness of our twice upsampling-diffusion method
More Qualitative Comparisons (×8) Figures 8 and 9 show more visual comparisons of×8SR (2562 →2048 2). TUDSR-S exhibits overwhelming perfor- mance across these one-step models, highlighting the effec- tiveness of our twice upsampling-diffusion method. LQ Images N8 M8 M4N2 (Our settings) Figure 7. Visualization of twice upsampling-diffusion (×8i.e.256 2 →20...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.