IS-CoT: Breaking the Long-form Generation Collapse via Interleaved Structural Thinking
Pith reviewed 2026-06-27 16:24 UTC · model grok-4.3
The pith
Embedding a dynamic Plan-Write-Reflect cycle inside generation prevents length collapse in long-form LLM writing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
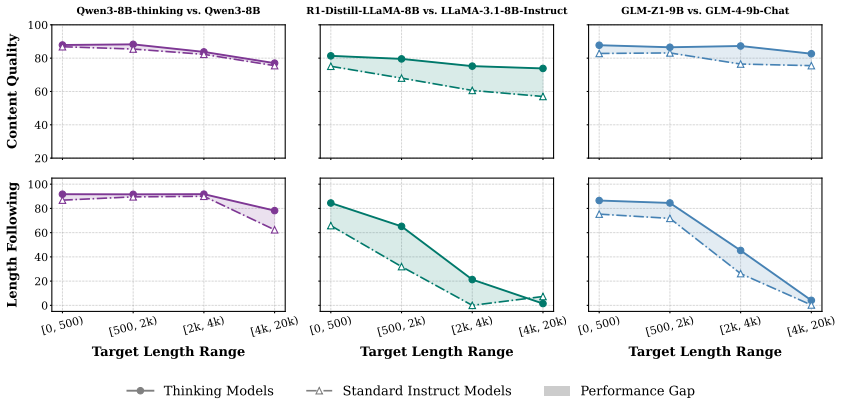
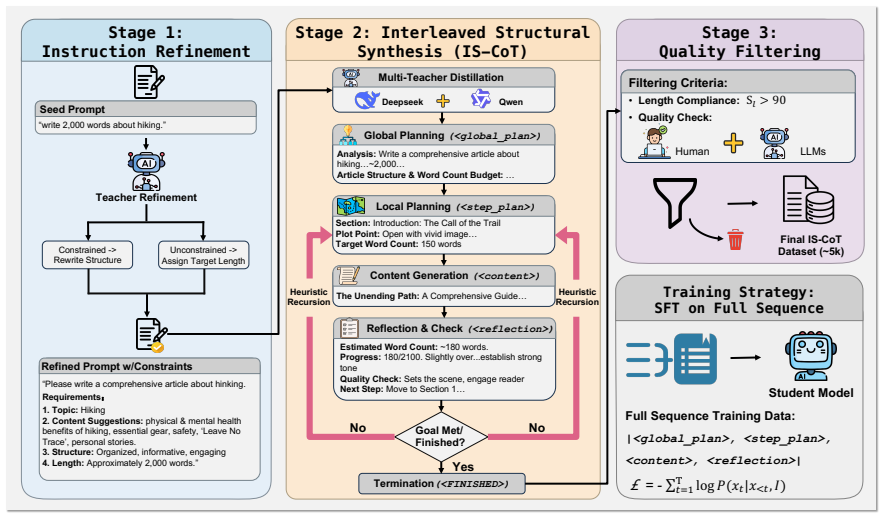
The Interleaved Structural Chain-of-Thought (IS-CoT) framework embeds a dynamic Plan-Write-Reflect cycle into the generation process, enabling continuous strategy adaptation and global alignment without additional assistance, which overcomes the limitation of static hierarchical planning that causes severe length collapse in reasoning-enhanced models on open-ended writing tasks beyond 2,000 words.
What carries the argument
The Interleaved Structural Chain-of-Thought (IS-CoT) framework that interleaves planning, writing, and reflection steps inside a single generation pass to supply ongoing dynamic guidance.
If this is right
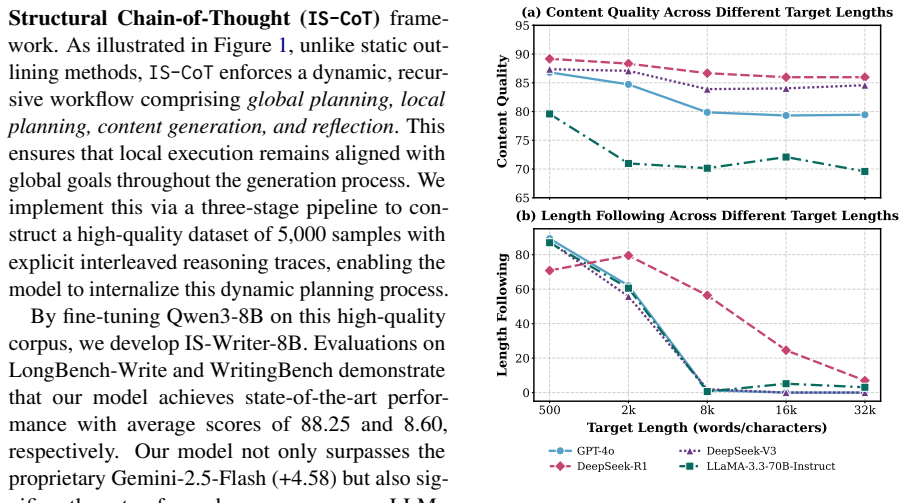
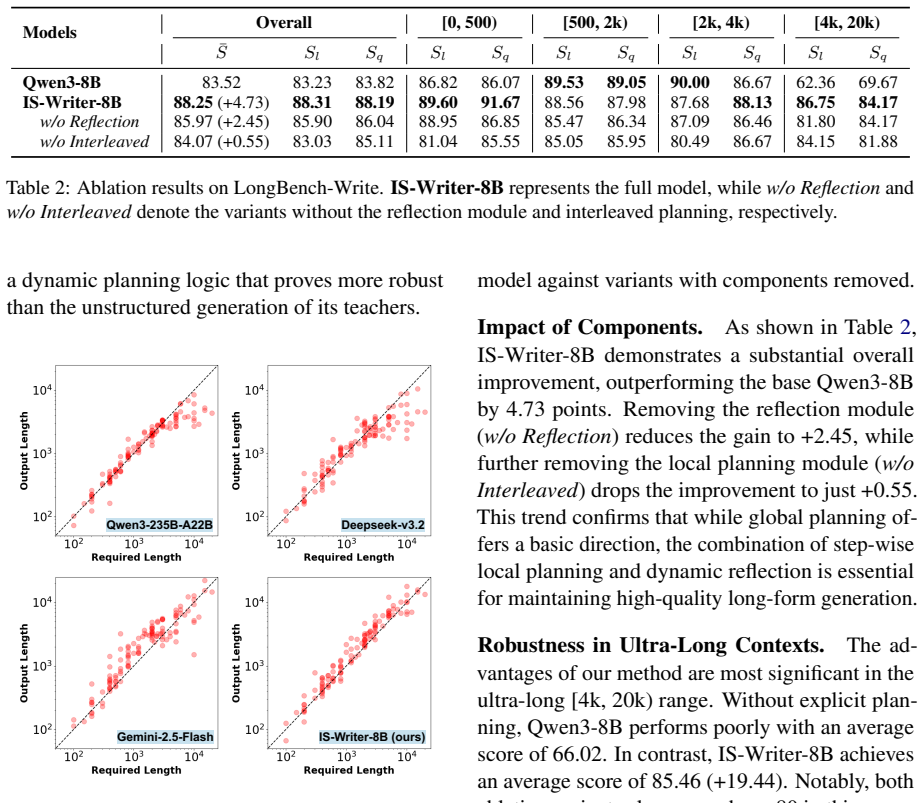
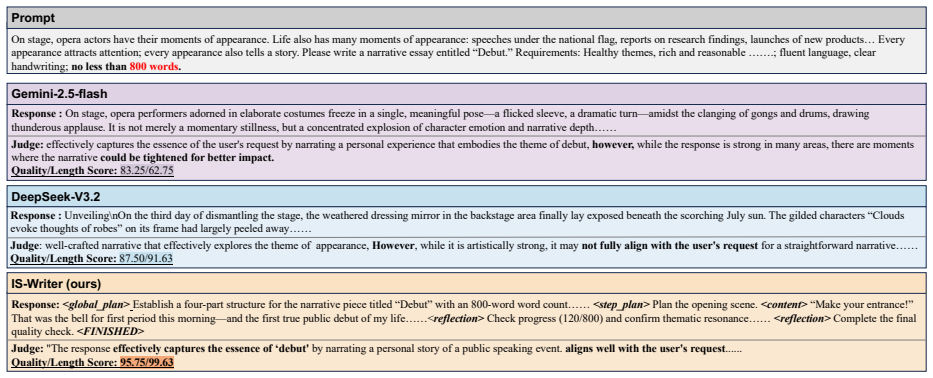
- IS-Writer-8B records +3.08 points over DeepSeek-V3.2 on LongBench-Write while showing stronger length adherence.
- The model reaches coherence levels competitive with much larger proprietary systems on long-form benchmarks.
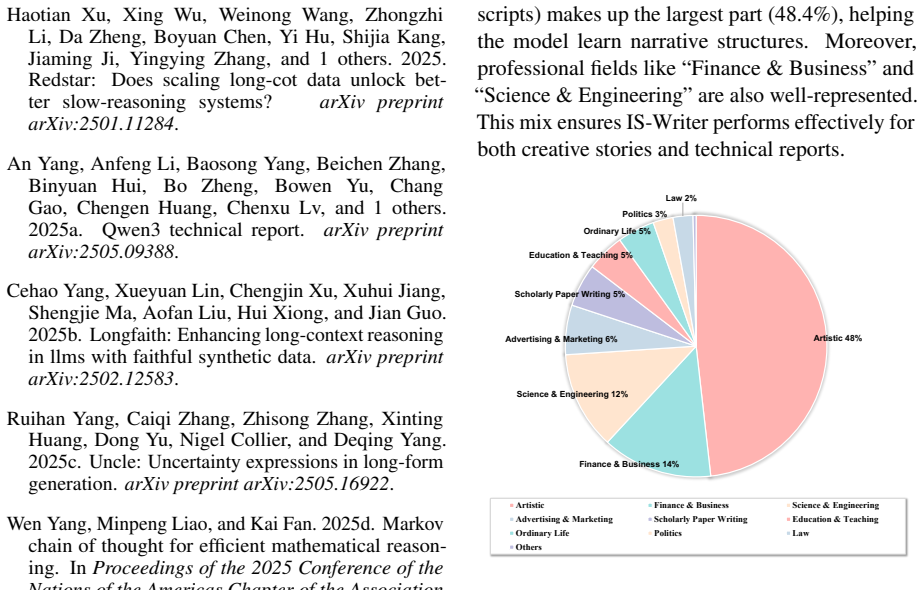
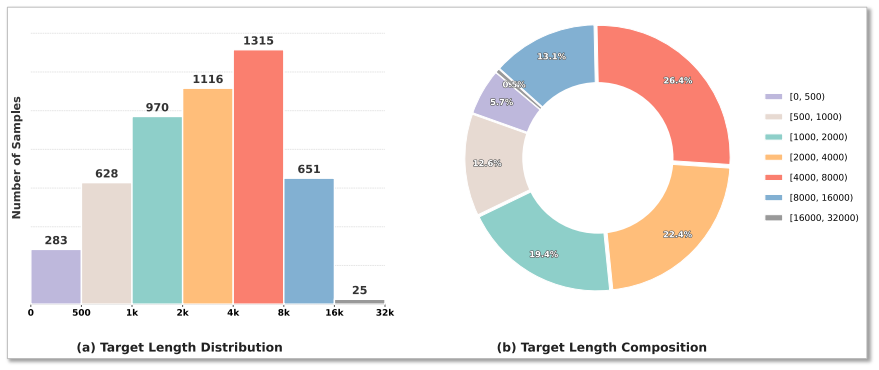
- High-quality interleaved reasoning traces can be generated via a multi-teacher pipeline and used for supervised training.
- Dynamic internal adaptation removes the need for separate external agentic workflows during inference.
Where Pith is reading between the lines
- The same interleaved cycle could be tested on long-context tasks outside writing, such as extended code generation or multi-step planning.
- Training data that records explicit reflection steps may prove reusable for improving controllability in other open-ended domains.
- If the cycle works without extra parameters, it suggests internal scaffolding can substitute for model scale in length-sensitive generation.
Load-bearing premise
Static hierarchical planning is the main cause of severe length collapse in reasoning-enhanced models once target lengths exceed 2,000 words.
What would settle it
Replace the interleaved Plan-Write-Reflect cycle with static hierarchical planning inside the same trained model and measure whether length compliance on open-ended tasks over 2,000 words drops to the levels seen in prior reasoning models.
Figures



read the original abstract
Generating coherent and controllable long-form content remains a persistent challenge for Large Language Models (LLMs). While reasoning-enhanced models have demonstrated success in logic-intensive domains, our evaluation reveals that they suffer from a severe length collapse in open-ended writing, where performance degrades sharply as target lengths exceed 2,000 words. We attribute this failure to the limitation of static hierarchical planning, which struggles to provide dynamic guidance over extended contexts. To bridge this gap, we introduce the Interleaved Structural Chain-of-Thought (IS-CoT) framework. Unlike external agentic workflows, IS-CoT embeds a dynamic Plan-Write-Reflect cycle into the generation process, enabling continuous strategy adaptation and global alignment without additional assistance. Based on this framework, we construct a high-quality dataset of interleaved reasoning traces via a multi-teacher pipeline and train IS-Writer-8B. Experiments demonstrate that IS-Writer-8B achieves state-of-the-art performance on challenging long-form benchmarks (e.g., +3.08 vs. DeepSeek-V3.2 on LongBench-Write), exhibiting robust length compliance and coherence competitive with significantly larger proprietary models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Interleaved Structural Chain-of-Thought (IS-CoT) framework to address severe length collapse in reasoning-enhanced LLMs during open-ended long-form writing tasks exceeding 2,000 words. The authors attribute the collapse to limitations of static hierarchical planning and propose embedding a dynamic Plan-Write-Reflect cycle directly into the generation process. They construct a dataset of interleaved reasoning traces via a multi-teacher pipeline, train the IS-Writer-8B model, and report state-of-the-art results on long-form benchmarks such as LongBench-Write (+3.08 over DeepSeek-V3.2), with improved length compliance and coherence competitive with larger proprietary models.
Significance. If the empirical gains and the causal role of the interleaved cycle are substantiated by detailed experiments, the work provides a practical internal mechanism for controllable long-form generation that avoids external agentic systems. This could meaningfully advance the design of reasoning-augmented models for open-ended writing, particularly by enabling smaller open-weight models to match or approach the performance of much larger closed models on coherence and length adherence.
minor comments (1)
- The abstract references specific benchmark improvements and model comparisons, but the provided text does not include dataset statistics, baseline implementations, ablation studies, or error bars, making it difficult to assess the robustness of the reported gains.
Simulated Author's Rebuttal
We thank the referee for their review and positive assessment of the potential significance of IS-CoT if the empirical claims are substantiated. The report does not enumerate any specific major comments, so we have no individual points requiring point-by-point rebuttal or revision at this stage. We remain available to supply additional experiments, ablations, or clarifications should the editor or referee request them to strengthen the causal evidence for the interleaved cycle.
Circularity Check
No significant circularity in empirical framework
full rationale
The paper describes an empirical training pipeline (IS-CoT framework, multi-teacher dataset construction, and fine-tuning of IS-Writer-8B) evaluated on benchmarks. No equations, derivations, or mathematical claims are present that could reduce predictions to fitted inputs or self-definitions. Central performance claims rest on experimental results rather than any load-bearing self-citation chain or ansatz smuggling. This is a standard empirical methods paper with no circularity burden.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2306.15595 , year=
Extending context window of large language models via positional interpolation , author=. arXiv preprint arXiv:2306.15595 , year=
-
[2]
Advances in neural information processing systems , volume=
Autosurvey: Large language models can automatically write surveys , author=. Advances in neural information processing systems , volume=
-
[3]
Ntk-aware scaled rope allows llama models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation , author=
-
[4]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[5]
arXiv preprint arXiv:2510.18234 , year=
Deepseek-ocr: Contexts optical compression , author=. arXiv preprint arXiv:2510.18234 , year=
-
[6]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
PIC: Unlocking Long-Form Text Generation Capabilities of Large Language Models via Position ID Compression , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
Advances in Neural Information Processing Systems , volume=
Make your llm fully utilize the context , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
arXiv preprint arXiv:2412.10079 , year=
Lost in the Middle, and In-Between: Enhancing Language Models' Ability to Reason Over Long Contexts in Multi-Hop QA , author=. arXiv preprint arXiv:2412.10079 , year=
-
[9]
arXiv preprint arXiv:2502.12583 , year=
LongFaith: Enhancing Long-Context Reasoning in LLMs with Faithful Synthetic Data , author=. arXiv preprint arXiv:2502.12583 , year=
-
[10]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
VeriFact: Enhancing long-form factuality evaluation with refined fact extraction and reference facts , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[11]
arXiv preprint arXiv:2505.16922 , year=
Uncle: Uncertainty expressions in long-form generation , author=. arXiv preprint arXiv:2505.16922 , year=
-
[12]
arXiv preprint arXiv:2505.23912 , year=
Reinforcement Learning for Better Verbalized Confidence in Long-Form Generation , author=. arXiv preprint arXiv:2505.23912 , year=
-
[13]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
What are the essential factors in crafting effective long context multi-hop instruction datasets? insights and best practices , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
arXiv preprint arXiv:2503.06692 , year=
Inftythink: Breaking the length limits of long-context reasoning in large language models , author=. arXiv preprint arXiv:2503.06692 , year=
-
[15]
Proceedings of the 41st International Conference on Machine Learning , pages=
Data engineering for scaling language models to 128K context , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[16]
The Thirteenth International Conference on Learning Representations , year=
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs , author=. The Thirteenth International Conference on Learning Representations , year=
-
[17]
arXiv preprint arXiv:2506.04180 , year=
SuperWriter: Reflection-Driven Long-Form Generation with Large Language Models , author=. arXiv preprint arXiv:2506.04180 , year=
-
[18]
arXiv preprint arXiv:2506.05760 , year=
Writing-RL: Advancing Long-form Writing via Adaptive Curriculum Reinforcement Learning , author=. arXiv preprint arXiv:2506.05760 , year=
-
[19]
arXiv preprint arXiv:2509.06160 , year=
Reverse-engineered reasoning for open-ended generation , author=. arXiv preprint arXiv:2509.06160 , year=
-
[20]
Ping, Bowen and Zeng, Jiali and Meng, Fandong and Wang, Shuo and Zhou, Jie and Zhang, Shanghang. L ong DPO : Unlock Better Long-form Generation Abilities for LLM s via Critique-augmented Stepwise Information. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.395
-
[21]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[22]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[23]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[24]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[25]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[26]
Nature , volume=
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[27]
arXiv preprint arXiv:2406.12793 , year=
Chatglm: A family of large language models from glm-130b to glm-4 all tools , author=. arXiv preprint arXiv:2406.12793 , year=
-
[28]
Proceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS 2025) , year=
Precise Information Control in Long-Form Text Generation , author=. Proceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS 2025) , year=
2025
-
[29]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[30]
2024 , howpublished =
Introducing Claude 3.5 Sonnet , author =. 2024 , howpublished =
2024
-
[31]
2025 , eprint=
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=. 2025 , eprint=
2025
-
[32]
S uri: Multi-constraint Instruction Following in Long-form Text Generation
Pham, Chau Minh and Sun, Simeng and Iyyer, Mohit. S uri: Multi-constraint Instruction Following in Long-form Text Generation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.94
-
[33]
2025 , eprint=
WritingBench: A Comprehensive Benchmark for Generative Writing , author=. 2025 , eprint=
2025
-
[34]
Wang, Ruida and Li, Yuxin and Fung, Yi R. and Zhang, Tong. Let ' s Reason Formally: Natural-Formal Hybrid Reasoning Enhances LLM ' s Math Capability. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.850
-
[35]
Markov chain of thought for efficient mathematical reasoning , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[36]
The Thirteenth International Conference on Learning Representations , year=
Unicott: A unified framework for structural chain-of-thought distillation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[37]
arXiv preprint arXiv:2405.19737 , year=
Beyond imitation: Learning key reasoning steps from dual chain-of-thoughts in reasoning distillation , author=. arXiv preprint arXiv:2405.19737 , year=
-
[38]
2025 , eprint=
Writing-RL: Advancing Long-form Writing via Adaptive Curriculum Reinforcement Learning , author=. 2025 , eprint=
2025
-
[39]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Plan Dynamically, Express Rhetorically: A Debate-Driven Rhetorical Framework for Argumentative Writing , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[40]
arXiv preprint arXiv:2501.11284 , year=
Redstar: Does scaling long-cot data unlock better slow-reasoning systems? , author=. arXiv preprint arXiv:2501.11284 , year=
-
[41]
Generating long-form story using dynamic hierarchical outlining with memory-enhancement , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[42]
N exus S um: Hierarchical LLM Agents for Long-Form Narrative Summarization
Kim, Hyuntak and Kim, Byung-Hak. N exus S um: Hierarchical LLM Agents for Long-Form Narrative Summarization. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.500
-
[43]
A Cognitive Writing Perspective for Constrained Long-Form Text Generation
Wan, Kaiyang and Mu, Honglin and Hao, Rui and Luo, Haoran and Gu, Tianle and Chen, Xiuying. A Cognitive Writing Perspective for Constrained Long-Form Text Generation. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.511
-
[44]
Second Conference on Language Modeling , year=
Learning to Reason for Long-Form Story Generation , author=. Second Conference on Language Modeling , year=
-
[45]
arXiv preprint arXiv:2506.18841 , year=
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning , author=. arXiv preprint arXiv:2506.18841 , year=
-
[46]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[47]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[48]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[49]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Marco-o1 v2: Towards Widening The Distillation Bottleneck for Reasoning Models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
Proceedings of the 41st International Conference on Machine Learning , pages=
Keypoint-based progressive chain-of-thought distillation for LLMs , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[51]
arXiv preprint arXiv:2410.06203 , year=
Integrating planning into single-turn long-form text generation , author=. arXiv preprint arXiv:2410.06203 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.