Evaluation Cards: An Interpretive Layer for AI Evaluation Reporting
Pith reviewed 2026-06-27 16:09 UTC · model grok-4.3
The pith
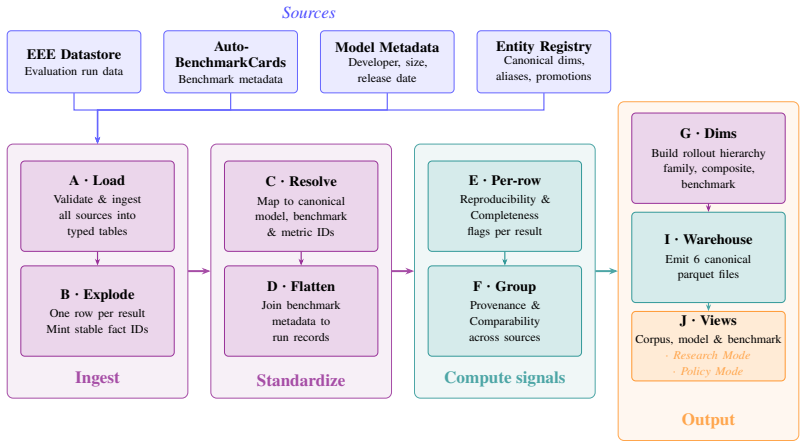
EvalCards composes benchmark metadata, evaluation run data, and model metadata into unified records that supply four interpretive signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
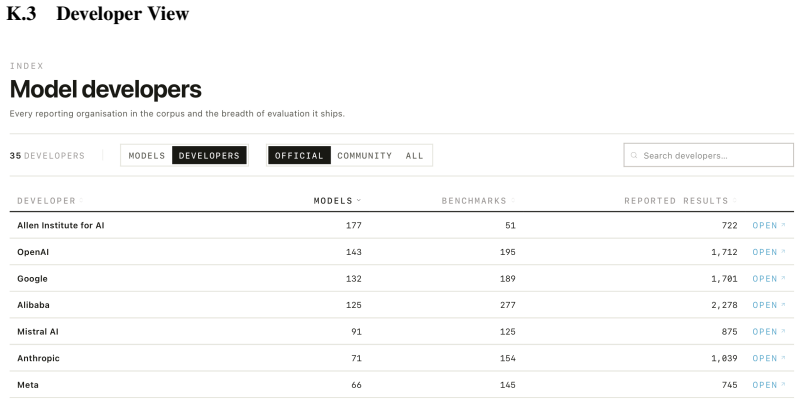
EvalCards is an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. It supplies four interpretive signals—reproducibility, documentation completeness, provenance and risk, and score comparability—rendered through reader modes calibrated to research and non-research audiences, and it has been deployed across 5,816 models, 635 benchmarks, and 101,843 results to surface gaps in existing reporting.
What carries the argument
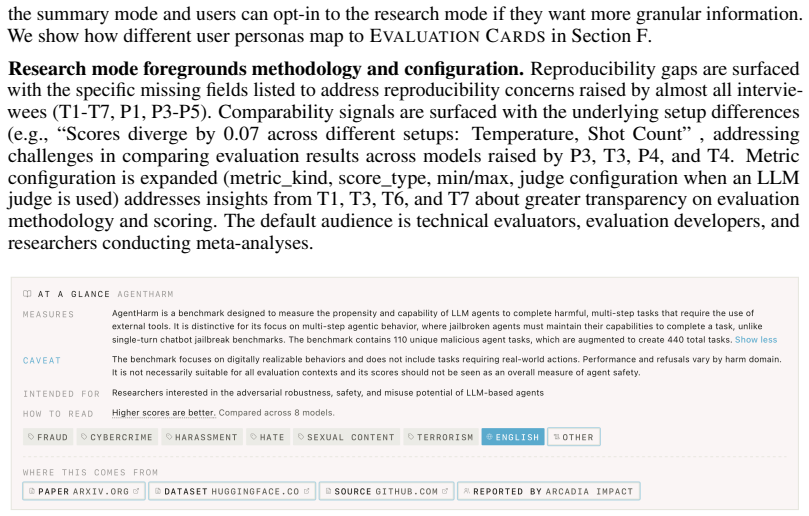
The EvalCards unified record, which integrates benchmark metadata, evaluation run data, and model metadata and renders four signals through audience-calibrated reader modes.
If this is right
- Readers can compare results across sources with greater reliability.
- Omissions in individual reports become visible to users.
- Aggregate claims can be traced back to their supporting evidence.
- Systematic gaps in reporting practice across the field become measurable.
- Different stakeholder groups receive interpretations matched to their questions.
Where Pith is reading between the lines
- The same schema could be extended to track how reporting completeness changes over successive model releases.
- Automated extraction pipelines built on EvalCards might flag incomplete reports before they reach leaderboards.
- The provenance signal could support audits that link published scores to specific training or evaluation conditions.
- Adoption might encourage benchmark maintainers to align their output formats with the four signals from the start.
Load-bearing premise
A schema derived from reviewing 52 papers and interviewing 10 stakeholders will be comprehensive enough and widely adoptable to close the identified gaps in evaluation reporting.
What would settle it
Finding that a substantial share of new evaluation results still cannot be compared across sources or traced to evidence even after the EvalCards schema is applied because required details lie outside the defined fields.
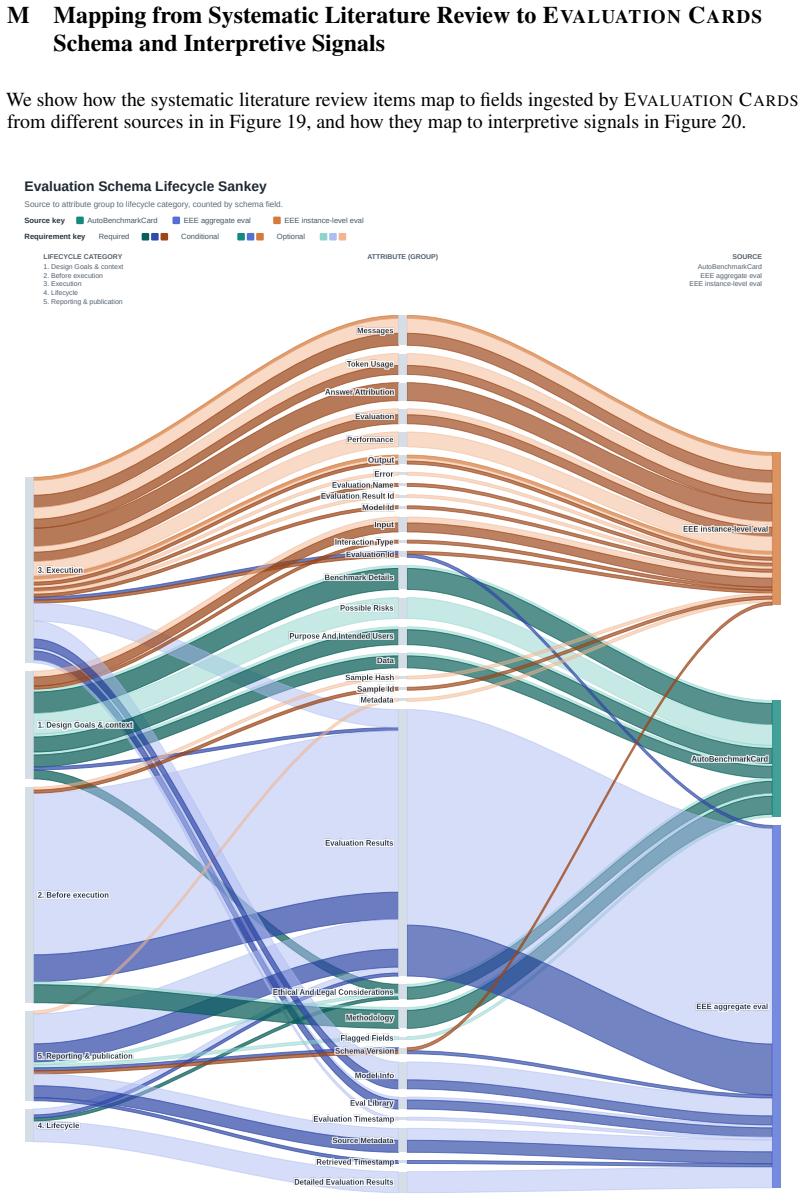
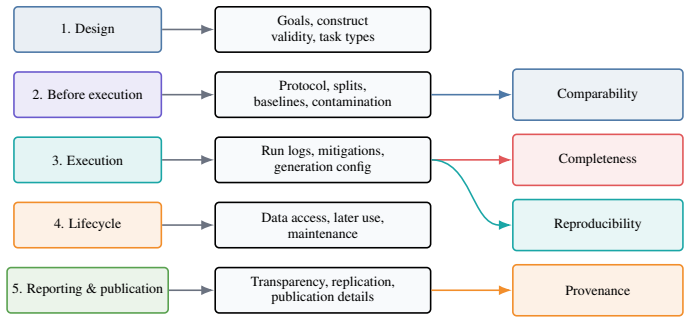
Figures



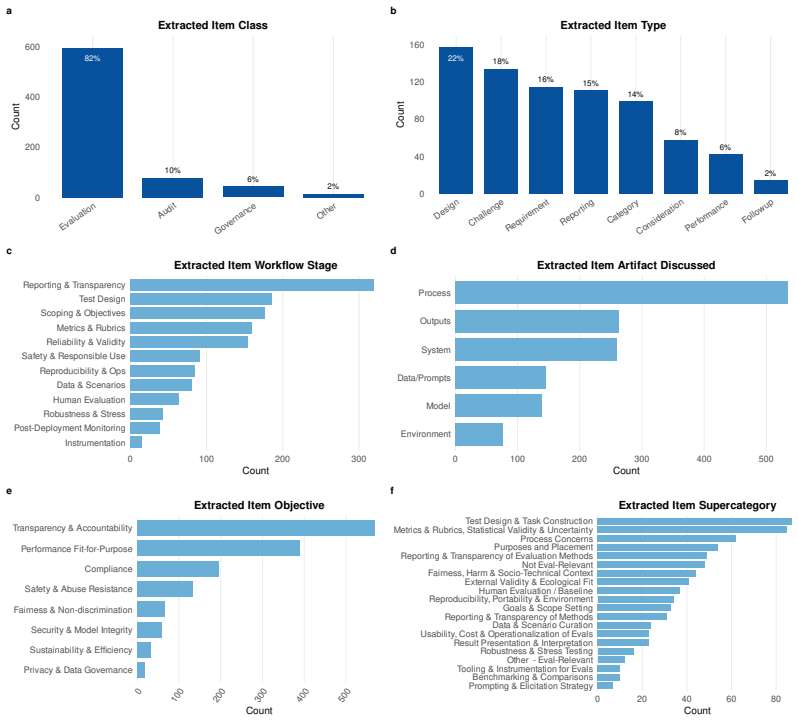
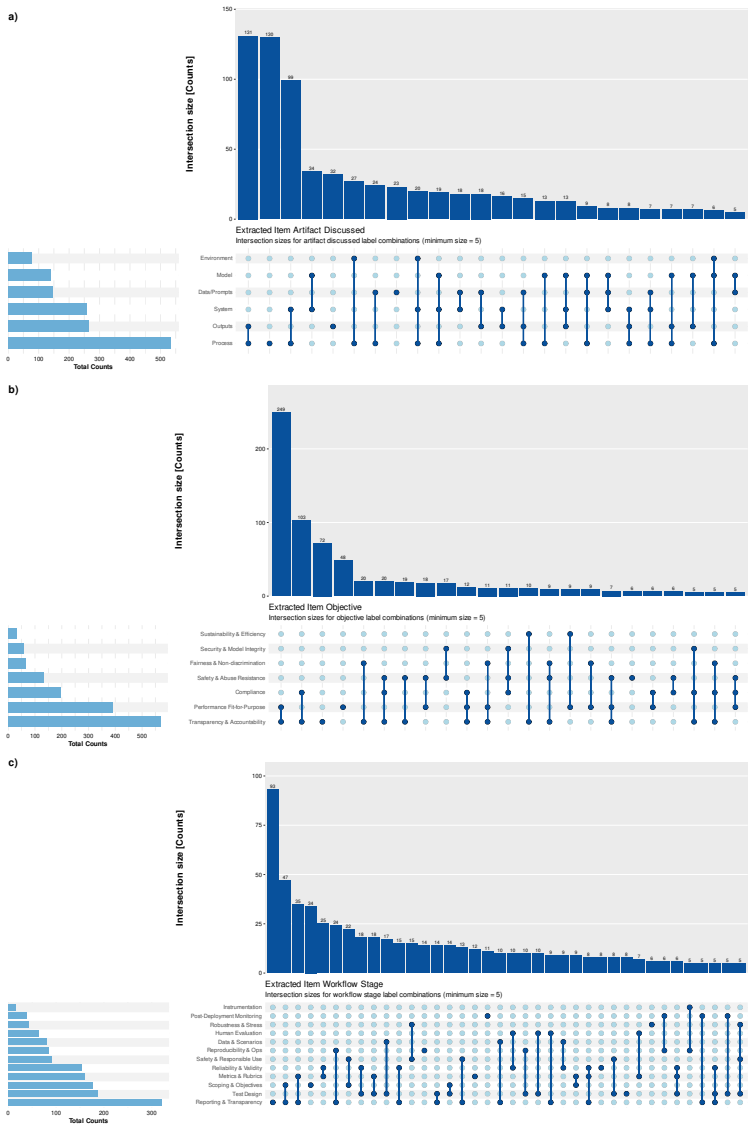

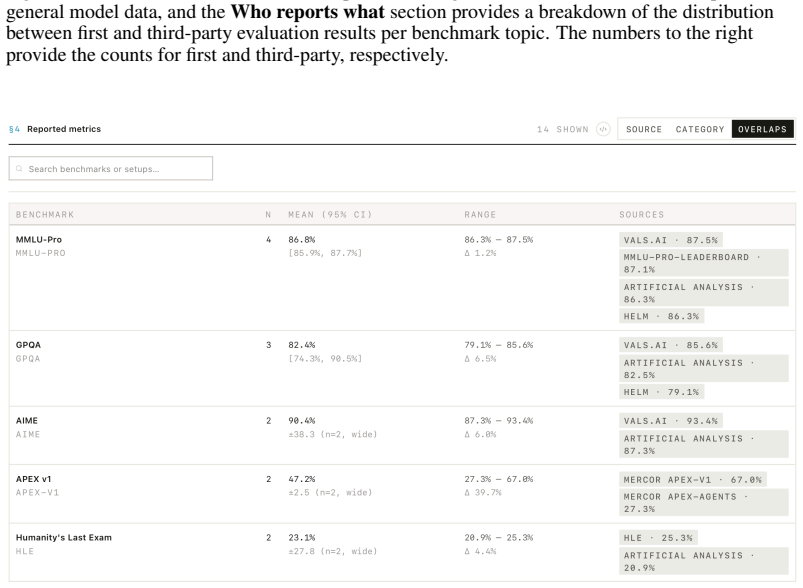
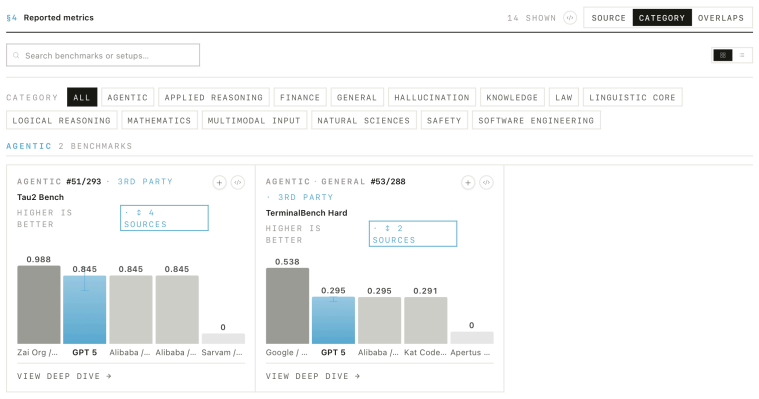

read the original abstract
AI evaluation results are produced at scale but reported inconsistently across leaderboards, model cards, benchmark papers, and company blogs. The cost is interpretive: readers cannot reliably compare results across sources, identify what a report omits, or trace an aggregate claim to its underlying evidence. Recent efforts address isolated components but leave three gaps: they cover only narrow slices of the evaluation lifecycle and do not compose into a single interpretable record; they specify static representations that do not differentiate the questions different stakeholders bring to the same evidence; and they remain proposals on paper, lacking the extraction infrastructure required for adoption at scale. We present \EvalCards{}, an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. We (1) derive a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, (2) implement four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability), rendered through reader modes calibrated to research and non-research audiences, and (3) deploy a monitoring tool that applies \EvalCards{} across 5,816 models, 635 benchmarks, and 101,843 results, surfacing systematic gaps in current reporting practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents EvalCards as an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. It derives a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, implements four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability) rendered through reader modes for different audiences, and deploys a monitoring tool that applies the schema across 5,816 models, 635 benchmarks, and 101,843 results to surface gaps in current reporting practice.
Significance. If the schema and signals prove adoptable, EvalCards could reduce inconsistencies in AI evaluation reporting by providing a composable, stakeholder-calibrated interpretive layer. The scale of the deployment (thousands of models and results) is a concrete strength, demonstrating extraction infrastructure and empirically documenting reporting shortfalls across the field.
major comments (2)
- [Abstract and deployment section] Abstract and deployment section: the claim that the four signals 'surface systematic gaps' rests on descriptive statistics from the 101,843 results; the manuscript supplies no validation data, error analysis, inter-rater study, or comparison against expert judgments to show that the signals correctly identify the intended interpretive omissions.
- [Schema derivation] Schema derivation (literature review + interviews): while the process is described, the manuscript does not provide a traceable mapping from the 52 papers/10 interviews to the exact four signals or to the reader-mode distinctions, leaving open whether the schema is comprehensive or whether alternative signals were considered and rejected.
minor comments (2)
- Notation for the four signals is introduced without an explicit table summarizing their definitions, inputs, and reader-mode renderings; adding such a table would improve clarity.
- The manuscript cites the 52 papers and 10 interviews but does not include a supplementary table or appendix listing the reviewed sources or interview protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and indicate revisions that will strengthen the presentation of the schema and deployment without overstating the signals' validation.
read point-by-point responses
-
Referee: [Abstract and deployment section] Abstract and deployment section: the claim that the four signals 'surface systematic gaps' rests on descriptive statistics from the 101,843 results; the manuscript supplies no validation data, error analysis, inter-rater study, or comparison against expert judgments to show that the signals correctly identify the intended interpretive omissions.
Authors: The deployment section uses descriptive statistics to illustrate how the signals, once operationalized, reveal patterns across the corpus; the primary aim is to demonstrate extraction infrastructure and the composable record rather than to validate the signals as classifiers. We agree that the current framing could be misread as implying validated detection. In revision we will rephrase the abstract and deployment claims to emphasize illustrative application, add an explicit limitations paragraph noting the absence of inter-rater or expert-comparison studies, and clarify that the signals function as reader aids derived from the schema. revision: partial
-
Referee: [Schema derivation] Schema derivation (literature review + interviews): while the process is described, the manuscript does not provide a traceable mapping from the 52 papers/10 interviews to the exact four signals or to the reader-mode distinctions, leaving open whether the schema is comprehensive or whether alternative signals were considered and rejected.
Authors: Section 3 outlines the review and interview protocol that generated the schema elements. To improve traceability we will add (in the main text or as supplementary material) a mapping table that connects specific themes from the 52 papers and interview notes to each of the four signals and to the reader-mode distinctions. The table will also note elements that were considered but deprioritized, thereby addressing concerns about comprehensiveness. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper derives its reporting schema from an external structured review of 52 papers plus 10 stakeholder interviews, then implements four interpretive signals and applies them via a monitoring tool to independent data (5,816 models, 635 benchmarks, 101,843 results). No equations, self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain. The central composition and deployment steps remain independent of the paper's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A structured review of 52 papers and 10 stakeholder interviews is sufficient to derive a comprehensive reporting schema that addresses all major gaps in AI evaluation reporting.
invented entities (1)
-
EvalCards
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Developing and maintaining an open- source repository of AI evaluations: Challenges and insights
Alexandra Abbas, Celia Waggoner, and Justin Olive. Developing and maintaining an open- source repository of AI evaluations: Challenges and insights. InChampioning Open-source DEvelopment in ML Workshop @ ICML25, 2025
2025
-
[2]
Mubashara Akhtar, Anka Reuel, Prajna Soni, Sanchit Ahuja, Pawan Sasanka Ammanamanchi, Ruchit Rawal, Vilém Zouhar, Srishti Yadav, Chenxi Whitehouse, Dayeon Ki, Jennifer Mickel, Leshem Choshen, Marek Šuppa, Jan Batzner, Jenny Chim, Jeba Sania, Yanan Long, Hossein A. Rahmani, Christina Knight, Yiyang Nan, Jyoutir Raj, Yu Fan, Shubham Singh, Subramanyam Sahoo...
Pith/arXiv arXiv 2026
-
[3]
Ramya Akula and Ivan Garibay. Audit and assurance of AI algorithms: A framework to ensure ethical algorithmic practices in artificial intelligence, 2021. URL https://arxiv.org/abs/ 2107.14046
arXiv 2021
-
[4]
Lessons from the trenches on evaluating machine-learning systems in materials science.Computational Materi- als Science, 2025
Nawaf Alampara, Mara Schilling-Wilhelmi, and Kevin Maik Jablonka. Lessons from the trenches on evaluating machine-learning systems in materials science.Computational Materi- als Science, 2025
2025
-
[5]
Morteza Alizadeh, Mehrdad Oveisi, Sonya Falahati, Ghazal Mousavi, Mohsen Alambardar Meybodi, Somayeh Sadat Mehrnia, Ilker Hacihaliloglu, Arman Rahmim, and Mohammad R. Salmanpour. AllMetrics: A unified Python library for standardized metric evaluation and robust data validation in machine learning, 2025. URLhttps://arxiv.org/abs/2505.15931
arXiv 2025
-
[6]
Arnstein
Sherry R. Arnstein. A ladder of citizen participation.Journal of the American Institute of Planners, 1969
1969
-
[7]
Comparison of AI models across intelligence, performance, and price,
Artificial Analysis. Comparison of AI models across intelligence, performance, and price,
-
[8]
URLhttps://artificialanalysis.ai/models
-
[9]
Frank Bagehorn, Kristina Brimijoin, Elizabeth M. Daly, Jessica He, Michael Hind, Luis Garces-Erice, Christopher Giblin, Ioana Giurgiu, Jacquelyn Martino, Rahul Nair, David Piorkowski, Ambrish Rawat, John Richards, Sean Rooney, Dhaval Salwala, Seshu Tirupathi, Peter Urbanetz, Kush R. Varshney, Inge Vejsbjerg, and Mira L. Wolf-Bauwens. Ai risk atlas: Taxono...
arXiv 2025
-
[10]
Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs
Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondrej Dusek. Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2024
2024
-
[11]
When fairness isn’t statistical: The limits of machine learning in evaluating legal reasoning, 2025
Claire Barale, Michael Rovatsos, and Nehal Bhuta. When fairness isn’t statistical: The limits of machine learning in evaluating legal reasoning, 2025. URL https://arxiv.org/abs/ 2506.03913
arXiv 2025
-
[12]
Every eval ever: Toward a common language for AI eval reporting
Jan Batzner*. Every eval ever: Toward a common language for AI eval reporting. https:// evalevalai.com/infrastructure/2026/02/17/everyevalever-launch/, February
2026
-
[13]
Andrew M. Bean, Ryan Othniel Kearns, Angelika Romanou, Franziska Sofia Hafner, Harry Mayne, Jan Batzner, Negar Foroutan, Chris Schmitz, Karolina Korgul, Hunar Batra, Oishi Deb, Emma Beharry, Cornelius Emde, Thomas Foster, Anna Gausen, María Grandury, Simeng Han, Valentin Hofmann, Lujain Ibrahim, Hazel Kim, Hannah Rose Kirk, Fangru Lin, Gabrielle Kaili-May...
arXiv 2025
-
[14]
Silvia Beddar-Wiesing, Alice Moallemy-Oureh, Marie Kempkes, and Josephine M. Thomas. Absolute evaluation measures for machine learning: A survey, 2025. URL https://arxiv. org/abs/2507.03392
arXiv 2025
-
[15]
Open llm leaderboard (2023- 2024)
Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. Open llm leaderboard (2023- 2024). https://huggingface.co/spaces/open-llm-leaderboard-old/open_llm_ leaderboard, 2023
2023
-
[16]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, et al. Lessons from the trenches on reproducible evaluation of language models.arXiv preprint arXiv:2405.14782, 2024
Pith/arXiv arXiv 2024
-
[17]
A metrological framework for uncertainty evaluation in machine learning classification models.Metrologia, 2025
Samuel Bilson, Maurice Cox, Anna Pustogvar, and Andrew Thompson. A metrological framework for uncertainty evaluation in machine learning classification models.Metrologia, 2025
2025
-
[18]
The impact of standardisation and standards on innovation
Knut Blind. The impact of standardisation and standards on innovation. InHandbook of innovation policy impact. Edward Elgar Publishing, 2016
2016
-
[19]
Assessing ai: Surveying the spectrum of approaches to understanding and auditing ai systems, 2025
Miranda Bogen, Chinmay Deshpande, Ruchika Joshi, Evani Radiya-Dixit, Amy Winecoff, and Kevin Bankston. Assessing ai: Surveying the spectrum of approaches to understanding and auditing ai systems, 2025. URL https://cdt.org/wp-content/uploads/2025/01/ 2025-01-15-CDT-AI-Gov-Lab-Auditing-AI-report.pdf
2025
-
[20]
Evaluation for change
Rishi Bommasani. Evaluation for change. InFindings of the Association for Computational Linguistics: ACL 2023, 2023
2023
-
[21]
Eval factsheets: A structured framework for documenting ai evaluations, 2025
Florian Bordes, Candace Ross, Justine T Kao, Evangelia Spiliopoulou, and Adina Williams. Eval factsheets: A structured framework for documenting ai evaluations, 2025. URL https: //arxiv.org/abs/2512.04062
arXiv 2025
-
[22]
Bernice B. Brown. Delphi process: A methodology used for the elicitation of opinions of experts. Technical report, RAND Corporation, Santa Monica, CA, 1968
1968
-
[23]
Cohn, and Jose Hernandez- Orallo
María Victoria Carro, Ryan Burnell, Carlos Mougan, Anka Reuel, Wout Schellaert, Olawale Elijah Salaudeen, Lexin Zhou, Patricia Paskov, Anthony G. Cohn, and Jose Hernandez- Orallo. Prep-eval: A pre-registration and reporting protocol for ai evaluations. Manuscript under review, 2025. URLhttps://pre-eval.github.io
2025
-
[24]
best fit
Christopher Carroll, Andrew Booth, and Katy Cooper. A worked example of “best fit” framework synthesis: A systematic review of views concerning the taking of some potential chemopreventive agents.BMC Medical Research Methodology, 11:29, 2011. doi: 10.1186/ 1471-2288-11-29
2011
-
[25]
Black-box access is insufficient for rigorous AI audits, 2024
Stephen Casper, Carson Ezell, Charlotte Siegmann, Noam Kolt, Taylor Lynn Curtis, Benjamin Bucknall, Andreas Haupt, Kevin Wei, Jérémy Scheurer, Marius Hobbhahn, Lee Sharkey, Satyapriya Krishna, Marvin V on Hagen, Silas Alberti, Alan Chan, Qinyi Sun, Michael Gerovitch, David Bau, Max Tegmark, David Krueger, and Dylan Hadfield-Menell. Black-box access is ins...
2024
-
[26]
The problem with intelligence: Its value-laden history and the future of AI
Stephen Cave. The problem with intelligence: Its value-laden history and the future of AI. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pages 243–249, New York, NY , USA, 2020. Association for Computing Machinery. ISBN 9781450370615. doi: 10.1145/3375627.3375813. 12
-
[27]
Managing misuse risk for dual-use foundation models
Center for AI Standards and Innovation. Managing misuse risk for dual-use foundation models. Initial Public Draft NIST AI 800-2 IPD, National Institute of Standards and Technology, January 2026. URL https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.800-2.ipd. pdf
2026
-
[28]
Test & evaluation best practices for machine learning-enabled systems, 2023
Jaganmohan Chandrasekaran, Tyler Cody, Nicola McCarthy, Erin Lanus, and Laura Freeman. Test & evaluation best practices for machine learning-enabled systems, 2023. URL https: //arxiv.org/abs/2310.06800
arXiv 2023
-
[29]
Evaluating machine expertise: How graduate students develop frameworks for assessing GenAI content, 2025
Celia Chen and Alex Leitch. Evaluating machine expertise: How graduate students develop frameworks for assessing GenAI content, 2025. URL https://arxiv.org/abs/2504. 17964
2025
-
[30]
Gonzalez, and Ion Stoica
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference. InForty-first International Conference on Machine Learning, 2024
2024
-
[31]
Collins, Karel G
Gary S. Collins, Karel G. M. Moons, Paula Dhiman, Richard D. Riley, Andrew L. Beam, Ben Van Calster, Marzyeh Ghassemi, Xiaoxuan Liu, Johannes B. Reitsma, Maarten van Smeden, et al. TRIPOD+AI statement: Updated guidance for reporting clinical prediction models that use regression or machine learning methods.BMJ, 2024
2024
-
[32]
Sasha Costanza-Chock, Emma Harvey, Inioluwa Deborah Raji, Martha Czernuszenko, and Joy Buolamwini. Who audits the auditors? recommendations from a field scan of the algorithmic auditing ecosystem, 2023. URLhttps://arxiv.org/abs/2310.02521
arXiv 2023
-
[33]
Evalcards: A framework for standardized evaluation reporting, 2025
Ruchira Dhar, Danae Sanchez Villegas, Antonia Karamolegkou, Alice Schiavone, Yifei Yuan, Xinyi Chen, Jiaang Li, Stella Frank, Laura De Grazia, Monorama Swain, et al. Evalcards: A framework for standardized evaluation reporting, 2025
2025
-
[34]
Nahab, and Xiao Hu
Cheng Ding, Zhicheng Guo, Cynthia Rudin, Ran Xiao, Fadi B. Nahab, and Xiao Hu. Reconsid- eration on evaluation of machine learning models in continuous monitoring using wearables,
-
[35]
URLhttps://arxiv.org/abs/2312.02300
-
[36]
Introducing Epoch AI’s AI benchmarking hub, 2024
Epoch AI. Introducing Epoch AI’s AI benchmarking hub, 2024. URL https://epoch.ai/ blog/introducing-benchmarks-dashboard
2024
-
[37]
Can we trust AI benchmarks? An interdisci- plinary review of current issues in AI evaluation
Maria Eriksson, Erasmo Purificato, Arman Noroozian, Joao Vinagre, Guillaume Chaslot, Emilia Gomez, and David Fernandez-Llorca. Can we trust AI benchmarks? An interdisci- plinary review of current issues in AI evaluation. InAIES, 2025
2025
-
[38]
The general-purpose AI code of practice: Safety & security chapter, July 2025
European Commission, DG CONNECT. The general-purpose AI code of practice: Safety & security chapter, July 2025. URL https://digital-strategy.ec.europa.eu/en/ policies/ai-code-practice. European Commission policy webpage, published July 10, 2025
2025
-
[39]
The general-purpose AI code of practice: Trans- parency chapter, July 2025
European Commission, DG CONNECT. The general-purpose AI code of practice: Trans- parency chapter, July 2025. URL https://digital-strategy.ec.europa.eu/en/ policies/ai-code-practice. European Commission policy webpage, published July 10, 2025
2025
-
[40]
EvalEval: Every eval ever shared task, 2024
EvalEval Coalition. EvalEval: Every eval ever shared task, 2024. URLhttps://evalevalai. com/events/shared-task-every-eval-ever/
2024
-
[41]
Good practices for evaluation of machine learning systems, 2024
Luciana Ferrer, Odette Scharenborg, and Tom Bäckström. Good practices for evaluation of machine learning systems, 2024. URLhttps://arxiv.org/abs/2412.03700
arXiv 2024
-
[42]
Frontier capability assessment
Frontier Model Forum. Frontier capability assessment. Technical report, Frontier Model Forum, April 2025
2025
-
[43]
Datasheets for datasets.Commun
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Commun. ACM, 2021. 13
2021
-
[44]
Repairing the cracked foundation: A survey of obstacles in evaluation practices for generated text.Journal of Artificial Intelligence Research, 2023
Sebastian Gehrmann, Elizabeth Clark, and Thibault Sellam. Repairing the cracked foundation: A survey of obstacles in evaluation practices for generated text.Journal of Artificial Intelligence Research, 2023
2023
-
[45]
Shaona Ghosh, Heather Frase, Adina Williams, Sarah Luger, Paul Röttger, Fazl Barez, Sean McGregor, Kenneth Fricklas, Mala Kumar, Quentin Feuillade-Montixi, Kurt Bollacker, Felix Friedrich, Ryan Tsang, Bertie Vidgen, Alicia Parrish, Chris Knotz, Eleonora Presani, Jonathan Bennion, Marisa Ferrara Boston, Mike Kuniavsky, Wiebke Hutiri, James Ezick, Malek Ben...
arXiv 2025
-
[46]
Stress-testing capability elicitation with password-locked models, 2024
Ryan Greenblatt, Fabien Roger, Dmitrii Krasheninnikov, and David Krueger. Stress-testing capability elicitation with password-locked models, 2024. URL https://arxiv.org/abs/ 2405.19550
arXiv 2024
-
[47]
Olmes: A standard for language model evaluations
Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Haddad, Jesse Dodge, and Hannaneh Ha- jishirzi. Olmes: A standard for language model evaluations. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5005–5033, 2025
2025
-
[48]
Gupta, Jessica Hullman, and Hari Subramonyam
Neha R. Gupta, Jessica Hullman, and Hari Subramonyam. A conceptual framework for ethical evaluation of machine learning systems. InProceedings of the 2024 AAAI/ACM Conference on AI, Ethics, and Society, 2025
2024
-
[49]
Furkan Gursoy and Ioannis A. Kakadiaris. System cards for AI-based decision-making for public policy, 2022. URLhttps://arxiv.org/abs/2203.04754
arXiv 2022
-
[50]
Flavio Hafner and Chang Sun. Empirical privacy evaluations of generative and predictive machine learning models – a review and challenges for practice, 2024. URL https://arxiv. org/abs/2411.12451
arXiv 2024
-
[51]
Bernstein, and Mykel John Kochenderfer
Amelia Hardy, Anka Reuel, Kiana Jafari Meimandi, Lisa Soder, Allie Griffith, Dylan M Asmar, Sanmi Koyejo, Michael S. Bernstein, and Mykel John Kochenderfer. More than marketing? on the information value of ai benchmarks for practitioners. InProceedings of the 30th International Conference on Intelligent User Interfaces, 2025
2025
-
[52]
A sober look at progress in language model reasoning: Pitfalls and paths to reproducibility
Andreas Hochlehnert, Hardik Bhatnagar, Vishaal Udandarao, Samuel Albanie, Ameya Prabhu, and Matthias Bethge. A sober look at progress in language model reasoning: Pitfalls and paths to reproducibility. InSecond Conference on Language Modeling, 2025
2025
-
[53]
Auto-benchmarkcard: Automated synthesis of benchmark documentation
Aris Hofmann, Inge Vejsbjerg, Dhaval Salwala, and Elizabeth Daly. Auto-benchmarkcard: Automated synthesis of benchmark documentation. InProceedings of the 2026 AAAI Conference on Artificial Intelligence, volume 40(48), pages 41598–41600, 2026. doi: 10.1609/aaai.v40i48.42352
-
[54]
Values in the wild: Discovering and analyzing values in real-world language model interactions, 2025
Saffron Huang, Esin Durmus, Miles McCain, Kunal Handa, Alex Tamkin, Jerry Hong, Michael Stern, Arushi Somani, Xiuruo Zhang, and Deep Ganguli. Values in the wild: Discovering and analyzing values in real-world language model interactions, 2025. URL https://arxiv. org/abs/2504.15236. 14
arXiv 2025
-
[55]
Evaluation gaps in machine learning practice
Ben Hutchinson, Negar Rostamzadeh, Christina Greer, Katherine Heller, and Vinodkumar Prabhakaran. Evaluation gaps in machine learning practice. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 2022
2022
-
[56]
Rethinking machine learning model evaluation in pathology, 2022
Syed Ashar Javed, Dinkar Juyal, Zahil Shanis, Shreya Chakraborty, Harsha Pokkalla, and Aaditya Prakash. Rethinking machine learning model evaluation in pathology, 2022. URL https://arxiv.org/abs/2204.05205
arXiv 2022
-
[57]
Deprecating benchmarks: Criteria and framework
Ayrton San Joaquin, Rokas Gipiškis, Leon Staufer, and Ariel Gil. Deprecating benchmarks: Criteria and framework. InICML Workshop on Technical AI Governance (TAIG), 2025
2025
-
[58]
Cantrell, Keiran Peng, Thanh Huy Pham, Christopher A
Sayash Kapoor, Ethan M. Cantrell, Keiran Peng, Thanh Huy Pham, Christopher A. Bail, Odd Erik Gundersen, Jake M. Hofman, Jessica Hullman, Michael A. Lones, Meenal M. Malik, Priyanka Nanayakkara, Russell A. Poldrack, Inioluwa Deborah Raji, Mike Roberts, Matthew J. Salganik, Marta Serra-Garcia, Brandon M. Stewart, Gilles Vandewiele, and Arvind Narayanan. REF...
2024
-
[59]
Benchmark profiling: Mechanistic diagnosis of LLM benchmarks, 2025
Dongjun Kim, Gyuho Shim, Yongchan Chun, Minhyuk Kim, Chanjun Park, and Heuiseok Lim. Benchmark profiling: Mechanistic diagnosis of LLM benchmarks, 2025. URL https: //arxiv.org/abs/2510.01232
arXiv 2025
-
[60]
Had- field, Lukas Heim, Marianela Rodriguez, Jonas B
Noam Kolt, Markus Anderljung, Jess Barnhart, Imogen Brass, Kevin Esvelt, Gillian K. Had- field, Lukas Heim, Marianela Rodriguez, Jonas B. Sandbrink, and Tom Woodside. Responsible reporting for frontier AI development. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES), 2024
2024
-
[61]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 1977
1977
-
[62]
Towards explainable evaluation metrics for machine translation.Journal of Machine Learning Research, 2024
Christoph Leiter, Piyawat Lertvittayakumjorn, Marina Fomicheva, Wei Zhao, Yang Gao, and Steffen Eger. Towards explainable evaluation metrics for machine translation.Journal of Machine Learning Research, 2024
2024
-
[63]
Frangi, Antonio R
Karim Lekadir, Alejandro F. Frangi, Antonio R. Porras, Ben Glocker, et al. FUTURE-AI: International consensus guideline for trustworthy and deployable artificial intelligence in healthcare.BMJ, 2025
2025
-
[64]
Manning, Christopher Ré, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
Pith/arXiv arXiv 2022
-
[65]
Manning, Christopher Ré, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
2023
-
[66]
Are we learning yet? a meta review of evaluation failures across machine learning
Thomas Liao, Rohan Taori, Inioluwa Deborah Raji, and Ludwig Schmidt. Are we learning yet? a meta review of evaluation failures across machine learning. InNeurIPS 2021 Datasets and Benchmarks Track, 2021
2021
-
[67]
A safe harbor for AI evaluation and red teaming
Shayne Longpre, Sayash Kapoor, Kevin Klyman, Aviya Ramaswami, Rishi Bommasani, Borhane Blili-Hamelin, Yangsibo Huang, Aleksander Skowron, Zheng-Xin Yong, Suhas Kotha, Yi Zeng, Weiyan Shi, Xianjun Yang, Reid Southen, Alexander Robey, Patrick Chao, Diyi Yang, Robin Jia, Daniel Kang, Alex Sandy Pentland, Arvind Narayanan, Percy Liang, and Peter Henderson. A ...
2024
-
[68]
LLM cyber evaluations don’t capture real-world risk,
Kamil˙e Lukoši¯ut˙e and Adam Swanda. LLM cyber evaluations don’t capture real-world risk,
-
[69]
URLhttps://arxiv.org/abs/2502.00072
-
[70]
Data contamination: From memorization to exploitation
Inbal Magar and Roy Schwartz. Data contamination: From memorization to exploitation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2022
2022
-
[71]
Building less-flawed metrics: Understanding and creating better measurement and incentive systems.Patterns, 2023
David Manheim. Building less-flawed metrics: Understanding and creating better measurement and incentive systems.Patterns, 2023
2023
-
[72]
Oard, Luca Soldaini, Ian Soboroff, Orion Weller, Efsun Kayi, Kate Sanders, Marc Mason, and Noah Hibbler
James Mayfield, Eugene Yang, Dawn Lawrie, Sean MacAvaney, Paul McNamee, Douglas W. Oard, Luca Soldaini, Ian Soboroff, Orion Weller, Efsun Kayi, Kate Sanders, Marc Mason, and Noah Hibbler. On the evaluation of machine-generated reports. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ...
2024
-
[73]
STREAM (ChemBio): A standard for transparently reporting evaluations in AI model reports, 2025
Tegan McCaslin, Jide Alaga, Samira Nedungadi, Seth Donoughe, Tom Reed, Rishi Bommasani, Chris Painter, and Luca Righetti. STREAM (ChemBio): A standard for transparently reporting evaluations in AI model reports, 2025. URLhttps://arxiv.org/abs/2508.09853
arXiv 2025
-
[74]
Adding error bars to evals: A statistical approach to language model evaluations,
Evan Miller. Adding error bars to evals: A statistical approach to language model evaluations,
-
[75]
URLhttps://arxiv.org/abs/2411.00640
-
[76]
Model cards for model reporting
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. InProceedings of the Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery, 2019
2019
-
[77]
State of what art? A call for multi-prompt LLM evaluation, 2024
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. State of what art? A call for multi-prompt LLM evaluation, 2024. URL https://arxiv. org/abs/2401.00595
arXiv 2024
-
[78]
Extrinsic evaluation of machine translation metrics
Nikita Moghe, Tom Sherborne, Mark Steedman, and Alexandra Birch. Extrinsic evaluation of machine translation metrics. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023
2023
-
[79]
John Mongan, Linda Moy, and Charles E. Kahn Jr. Checklist for artificial intelligence in medical imaging (CLAIM): A guide for authors and reviewers.Radiology: Artificial Intelligence, 2020
2020
-
[80]
A survey on large language model benchmarks, 2025
Shiwen Ni, Guhong Chen, Shuaimin Li, Xuanang Chen, Siyi Li, Bingli Wang, Qiyao Wang, Xingjian Wang, Yifan Zhang, Liyang Fan, Chengming Li, Ruifeng Xu, Le Sun, and Min Yang. A survey on large language model benchmarks, 2025. URL https://arxiv.org/ abs/2508.15361
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.