TENP: Trapezoidal Expert Neuron Pruning For Mixture-of-Experts
Pith reviewed 2026-06-28 07:38 UTC · model grok-4.3
The pith
TENP prunes neurons inside less important experts of MoE models in a trapezoidal layer pattern, preserving accuracy at 40 percent expert sparsity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
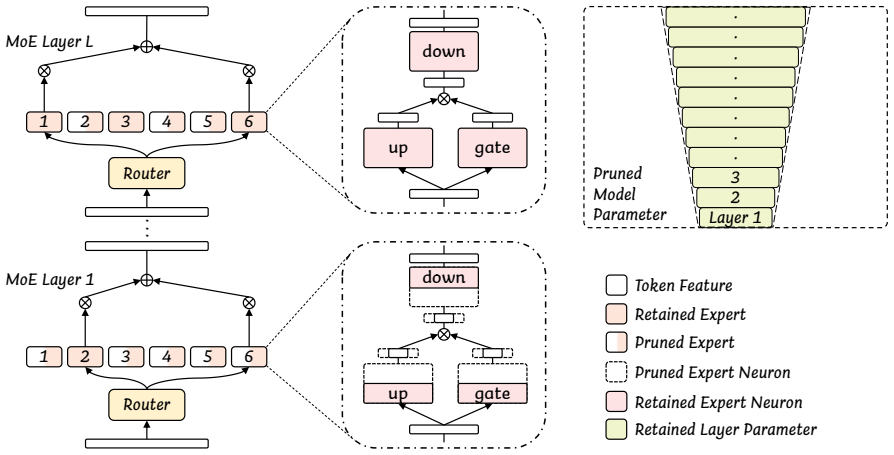
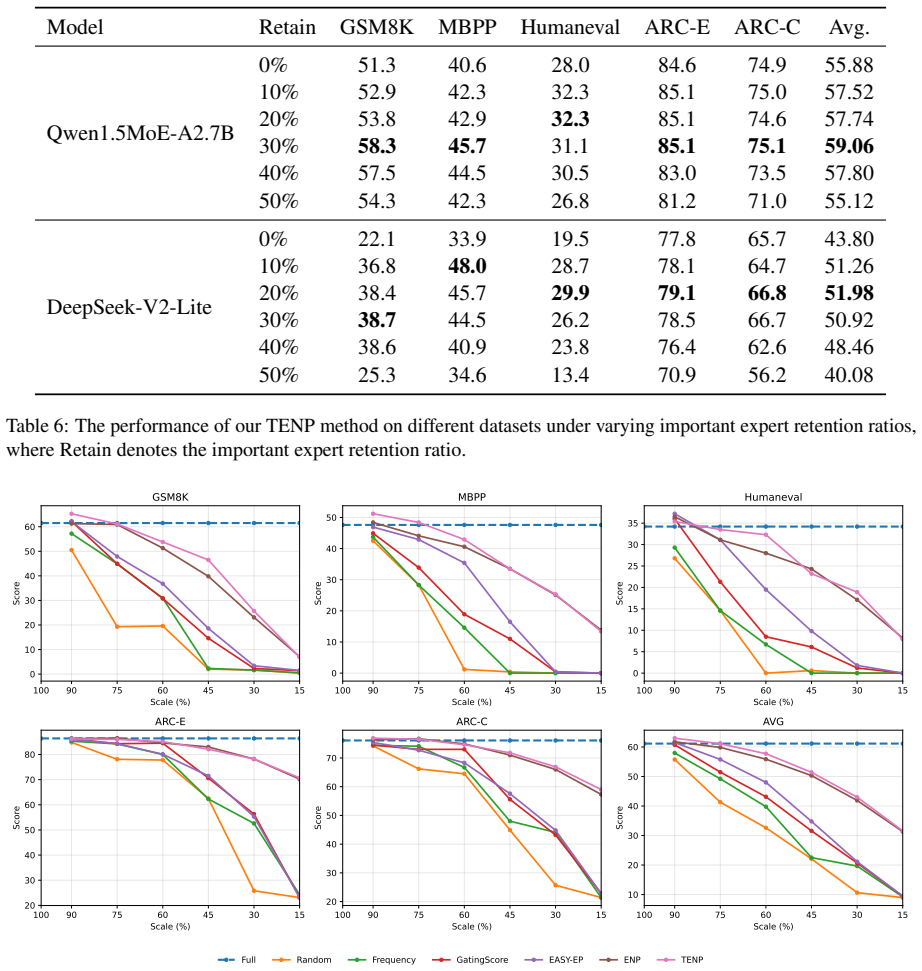
TENP is a structured Trapezoidal Expert Neuron Pruning framework. It identifies and fully retains important experts while applying expert neuron pruning to the remainder, reserving parameters in a trapezoidal pattern from shallow to deep layers. Expert importance is scored jointly from output magnitude and input-vector direction change. Neuron importance inside each pruned expert is measured by projected contribution to the expert output. Under 40 percent routing expert sparsity and an average of 63.76 percent activated expert parameters, the pruned DeepSeek model loses only one accuracy point relative to the full model and gains 10 percent on code generation tasks.
What carries the argument
Trapezoidal Expert Neuron Pruning (TENP), which scores experts jointly by output magnitude and input direction change, then retains neurons by projected contribution inside a layer-wise trapezoidal schedule.
If this is right
- MoE models reach 40 percent routing expert sparsity while keeping 63.76 percent of activated expert parameters.
- Accuracy on standard tasks drops by only one point on DeepSeek after pruning.
- Code generation performance rises by 10 percent relative to the unpruned model.
- The same procedure works on both Qwen and DeepSeek without requiring full retraining.
- Pruning follows a fixed trapezoidal pattern across layers rather than uniform removal.
Where Pith is reading between the lines
- The approach could lower memory use enough to fit larger MoE models on a single GPU during inference.
- The trapezoidal schedule may preserve deeper-layer specialization that uniform pruning would disrupt.
- The method might combine with quantization or distillation for further compression.
- Similar scoring and trapezoidal pruning could apply to other sparsely activated architectures beyond language models.
Load-bearing premise
That jointly scoring experts by output magnitude and input-vector direction change, then pruning neurons by projected contribution in a trapezoidal layer-wise pattern, reliably preserves downstream task performance without full retraining or extra validation data.
What would settle it
Run the same 40 percent sparsity TENP procedure on DeepSeek or Qwen and measure accuracy on a standard benchmark; a drop larger than two points would falsify the central performance claim.
Figures

read the original abstract
Mixture-of-Experts large language models (LLMs) scale efficiently through sparse activation, yet their deployment is fundamentally constrained by the large static parameter footprint of experts. Existing compression approaches either remove entire experts, disrupting routing topology and harming performance, or rely on unstructured weight pruning with limited practical efficiency. To address the limitations, we propose TENP, a structured Trapezoidal ExpertNeuron Pruning framework. Using a few samples, we identify and retain important experts, while applying expert neuron pruning (ENP) to less important experts, reserving model parameters in a trapezoidal pattern from shallow to deep layers. When evaluating expert importance, we jointly consider both the magnitude of the expert output and its ability to change the direction of the input vector. For ENP, we measure each neuron's projected contribution to the expert output to identify and retain important neurons. We conduct extensive experiments on the Qwen and DeepSeek models. Under a routing expert sparsity of 40% and an average of 63.76% activated expert parameters, the DeepSeek model suffers only a 1-point drop in accuracy compared to the full-parameter model. Moreover, it outperforms the full-parameter model by 10% on code generation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TENP, a structured Trapezoidal Expert Neuron Pruning framework for Mixture-of-Experts LLMs. Using a few samples, it scores expert importance by jointly considering output magnitude and the expert's effect on input vector direction, applies expert neuron pruning (ENP) via projected neuron contribution on less-important experts, and retains parameters in a trapezoidal layer-wise pattern (more retention in deeper layers). Experiments on Qwen and DeepSeek report that at 40% routing expert sparsity (63.76% activated parameters on average), DeepSeek shows a 1-point accuracy drop versus the dense model while gaining 10% on code generation tasks.
Significance. If the reported performance preservation is robust, TENP would provide a practical structured compression technique for large MoE models that avoids full expert removal and unstructured pruning, enabling lower memory footprints with limited or no accuracy loss and occasional task-specific gains. The combination of magnitude and directional-change scoring plus trapezoidal retention is a plausible extension of existing pruning ideas, but its value depends on generalization beyond the scoring samples.
major comments (3)
- [Abstract] Abstract: the central claim of a 1-point accuracy drop and 10% code-generation gain at 40% expert sparsity is presented with no experimental protocol, no description of the 'few samples' used for scoring (number, selection criteria, diversity, or relation to test distributions), no baseline comparisons, and no statistical significance or variance measures. This directly undermines verification of the performance-preservation result.
- [Method] Method description: the joint expert importance score (output magnitude plus input-vector direction change) and the projected neuron contribution for ENP are described at a high level but without explicit equations, combination weights, or thresholds; likewise, the trapezoidal retention pattern lacks a precise definition or formula for layer-wise allocation. These omissions make the load-bearing scoring and pruning rules impossible to reproduce or analyze for bias toward the scoring samples.
- [Experiments] Experiments: no ablation is reported that isolates the directional-change term versus magnitude alone, the trapezoidal pattern versus uniform or random retention, or the sensitivity of results to the choice/number of scoring samples. Without these, it is impossible to confirm that the proposed joint scoring reliably preserves downstream behavior rather than fitting the particular inputs used for pruning.
minor comments (2)
- [Abstract] The abstract introduces 'routing expert sparsity' and 'activated expert parameters' without defining the precise measurement (e.g., fraction of experts routed per token or total parameter count after masking).
- [Abstract] The acronym 'ENP' is used before any expansion or definition in the provided text.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our TENP framework. We will revise the manuscript to enhance reproducibility and provide additional experimental validation as detailed in our point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 1-point accuracy drop and 10% code-generation gain at 40% expert sparsity is presented with no experimental protocol, no description of the 'few samples' used for scoring (number, selection criteria, diversity, or relation to test distributions), no baseline comparisons, and no statistical significance or variance measures. This directly undermines verification of the performance-preservation result.
Authors: We agree that the abstract should provide more context for the reported results. In the revised manuscript, we will expand the abstract to include a high-level overview of the experimental protocol and refer readers to the detailed description of the scoring samples, baseline comparisons, and variance measures in the Experiments section. revision: yes
-
Referee: [Method] Method description: the joint expert importance score (output magnitude plus input-vector direction change) and the projected neuron contribution for ENP are described at a high level but without explicit equations, combination weights, or thresholds; likewise, the trapezoidal retention pattern lacks a precise definition or formula for layer-wise allocation. These omissions make the load-bearing scoring and pruning rules impossible to reproduce or analyze for bias toward the scoring samples.
Authors: We acknowledge that the method section would benefit from more precise formulations. We will include explicit equations for the joint importance score, the projected neuron contribution, any combination weights or thresholds, and a mathematical definition of the trapezoidal retention pattern with the layer-wise allocation formula in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments: no ablation is reported that isolates the directional-change term versus magnitude alone, the trapezoidal pattern versus uniform or random retention, or the sensitivity of results to the choice/number of scoring samples. Without these, it is impossible to confirm that the proposed joint scoring reliably preserves downstream behavior rather than fitting the particular inputs used for pruning.
Authors: The original manuscript prioritizes overall performance results. To strengthen the paper, we will add ablation studies in the revised version that isolate the directional-change component, compare the trapezoidal pattern to uniform and random retention, and evaluate sensitivity to the number and choice of scoring samples. revision: yes
Circularity Check
No circularity; empirical validation on external models
full rationale
The paper describes a pruning method (TENP) that scores experts via output magnitude plus input-vector direction change and prunes neurons via projected contribution, then reports measured accuracy and code-generation results on Qwen and DeepSeek models. No equations, fitted parameters, or self-citations are shown to reduce the reported performance numbers to quantities defined inside the paper; the claims remain direct empirical observations rather than derivations that collapse to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert importance is adequately captured by the product or combination of output magnitude and the expert's effect on input-vector direction
- domain assumption A neuron's projected contribution to expert output is a sufficient proxy for its importance
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
DiEP: Adaptive Mixture-of-Experts Compression through Differentiable Expert Pruning , author=. 2025 , eprint=
2025
-
[2]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[3]
2021 , eprint=
Program Synthesis with Large Language Models , author=. 2021 , eprint=
2021
-
[4]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[5]
2018 , eprint=
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
2018
-
[6]
T ruthful QA : Measuring How Models Mimic Human Falsehoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[7]
2023 , eprint=
LLM-Pruner: On the Structural Pruning of Large Language Models , author=. 2023 , eprint=
2023
-
[8]
Feng, Yuchen and Shen, Bowen and Gu, Naibin and Zhao, Jiaxuan and Fu, Peng and Lin, Zheng and Wang, Weiping. DIVE into M o E : Diversity-Enhanced Reconstruction of Large Language Models from Dense into Mixture-of-Experts. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/...
-
[9]
EAC - M o E : Expert-Selection Aware Compressor for Mixture-of-Experts Large Language Models
Chen, Yuanteng and Shao, Yuantian and Wang, Peisong and Cheng, Jian. EAC - M o E : Expert-Selection Aware Compressor for Mixture-of-Experts Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.633
-
[10]
STUN : Structured-Then-Unstructured Pruning for Scalable M o E Pruning
Lee, Jaeseong and Hwang, Seung-won and Qiao, Aurick and Campos, Daniel F and Yao, Zhewei and He, Yuxiong. STUN : Structured-Then-Unstructured Pruning for Scalable M o E Pruning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.671
-
[11]
A Survey on Mixture of Experts in Large Language Models , ISSN=
Cai, Weilin and Jiang, Juyong and Wang, Fan and Tang, Jing and Kim, Sunghun and Huang, Jiayi , year=. A Survey on Mixture of Experts in Large Language Models , ISSN=. doi:10.1109/tkde.2025.3554028 , journal=
-
[12]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[14]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[15]
2017 , eprint=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. 2017 , eprint=
2017
-
[16]
2022 , eprint=
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author=. 2022 , eprint=
2022
-
[17]
2020 , eprint=
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding , author=. 2020 , eprint=
2020
-
[18]
2024 , eprint=
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models , author=. 2024 , eprint=
2024
-
[19]
Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters" , url =
Qwen Team , month =. Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters" , url =
-
[20]
2024 , eprint=
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
Mixtral of Experts , author=. 2024 , eprint=
2024
-
[22]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2025 , eprint=
2025
-
[25]
2024 , eprint=
DA-MoE: Addressing Depth-Sensitivity in Graph-Level Analysis through Mixture of Experts , author=. 2024 , eprint=
2024
-
[26]
2024 , eprint=
XMoE: Sparse Models with Fine-grained and Adaptive Expert Selection , author=. 2024 , eprint=
2024
-
[27]
2024 , eprint=
Higher Layers Need More LoRA Experts , author=. 2024 , eprint=
2024
-
[28]
2025 , eprint=
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts , author=. 2025 , eprint=
2025
-
[29]
2024 , eprint=
SEER-MoE: Sparse Expert Efficiency through Regularization for Mixture-of-Experts , author=. 2024 , eprint=
2024
-
[30]
2024 , eprint=
A Simple and Effective Pruning Approach for Large Language Models , author=. 2024 , eprint=
2024
-
[31]
2024 , eprint=
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models , author=. 2024 , eprint=
2024
-
[32]
2025 , eprint=
Domain-Specific Pruning of Large Mixture-of-Experts Models with Few-shot Demonstrations , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
Mixture of Neuron Experts , author=. 2025 , eprint=
2025
-
[34]
2024 , eprint=
MoE-I ^2 : Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition , author=. 2024 , eprint=
2024
-
[35]
2022 , eprint=
Task-Specific Expert Pruning for Sparse Mixture-of-Experts , author=. 2022 , eprint=
2022
-
[36]
2023 , eprint=
SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot , author=. 2023 , eprint=
2023
-
[37]
2024 , eprint=
MoE-Pruner: Pruning Mixture-of-Experts Large Language Model using the Hints from Its Router , author=. 2024 , eprint=
2024
-
[38]
2024 , eprint=
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs , author=. 2024 , eprint=
2024
-
[39]
2024 , eprint=
Merge, Then Compress: Demystify Efficient SMoE with Hints from Its Routing Policy , author=. 2024 , eprint=
2024
-
[40]
2025 , eprint=
CoMoE: Collaborative Optimization of Expert Aggregation and Offloading for MoE-based LLMs at Edge , author=. 2025 , eprint=
2025
-
[41]
2023 , eprint=
Merging Experts into One: Improving Computational Efficiency of Mixture of Experts , author=. 2023 , eprint=
2023
-
[42]
2025 , eprint=
Condense, Don't Just Prune: Enhancing Efficiency and Performance in MoE Layer Pruning , author=. 2025 , eprint=
2025
-
[43]
A Comprehensive Evaluation of Quantization Strategies for Large Language Models
Jin, Renren and Du, Jiangcun and Huang, Wuwei and Liu, Wei and Luan, Jian and Wang, Bin and Xiong, Deyi. A Comprehensive Evaluation of Quantization Strategies for Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.726
-
[44]
Companion Proceedings of the ACM on Web Conference 2025 , pages =
Du, Jiangcun and Jin, Renren and Huang, Wuwei and Liu, Wei and Luan, Jian and Xiong, Deyi , title =. Companion Proceedings of the ACM on Web Conference 2025 , pages =. 2025 , isbn =. doi:10.1145/3701716.3717578 , abstract =
-
[45]
ArXiv , year=
Multilingual Large Language Models: A Systematic Survey , author=. ArXiv , year=
-
[46]
F uxi T ranyu: A Multilingual Large Language Model Trained with Balanced Data
Sun, Haoran and Jin, Renren and Xu, Shaoyang and Pan, Leiyu and Supryadi and Cui, Menglong and Du, Jiangcun and Lei, Yikun and Yang, Lei and Shi, Ling and Xiao, Juesi and Zhu, Shaolin and Xiong, Deyi. F uxi T ranyu: A Multilingual Large Language Model Trained with Balanced Data. Proceedings of the 2024 Conference on Empirical Methods in Natural Language P...
-
[47]
ArXiv , year=
Advancing Large Language Models for Tibetan with Curated Data and Continual Pre-Training , author=. ArXiv , year=
-
[48]
S hort GPT : Layers in Large Language Models are More Redundant Than You Expect
Men, Xin and Xu, Mingyu and Zhang, Qingyu and Yuan, Qianhao and Wang, Bingning and Lin, Hongyu and Lu, Yaojie and Han, Xianpei and Chen, Weipeng. S hort GPT : Layers in Large Language Models are More Redundant Than You Expect. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1035
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.