Towards Robust Arabic Speech Emotion Recognition with Deep Learning
Pith reviewed 2026-06-27 12:12 UTC · model grok-4.3
The pith
A CNN-Transformer model reaches 98.1 percent accuracy on Arabic speech emotion recognition tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
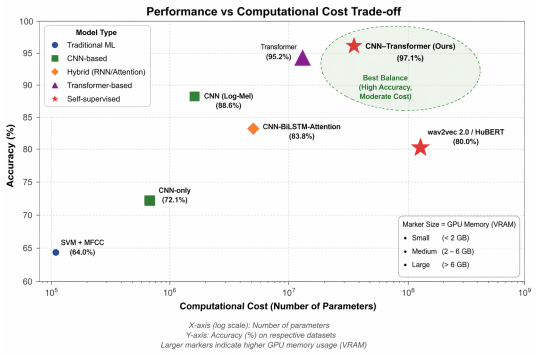
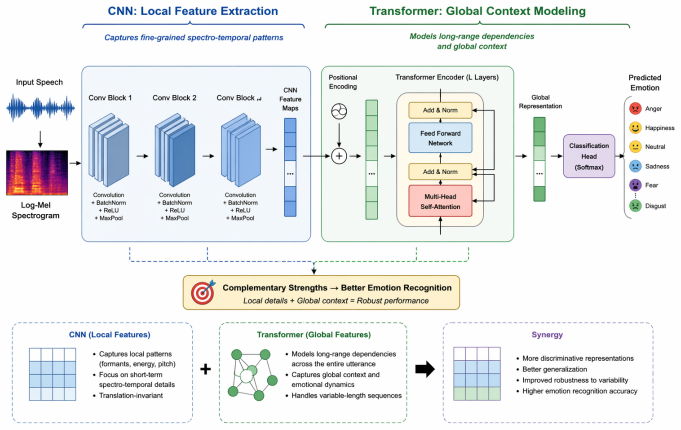
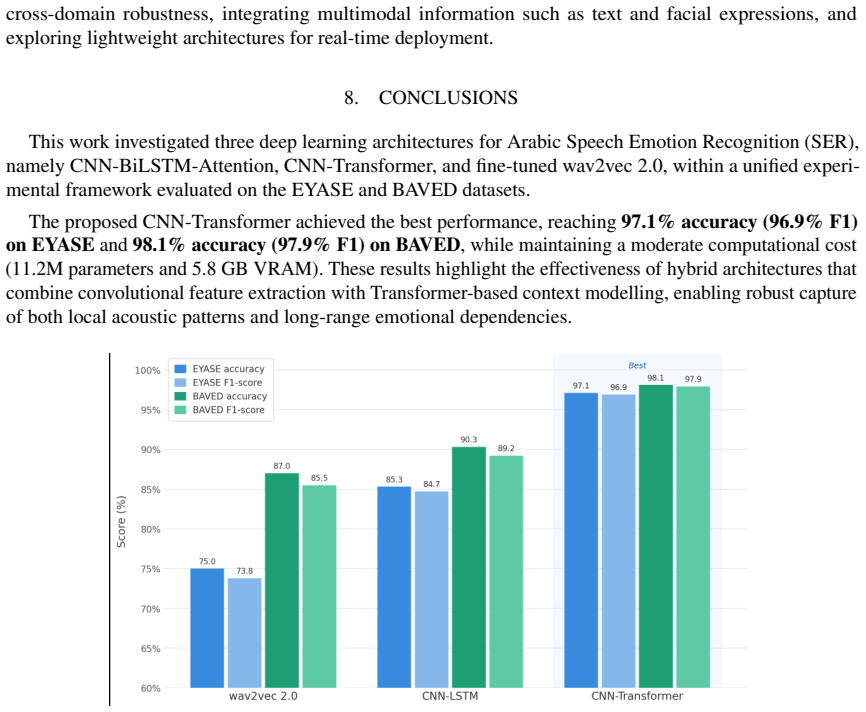
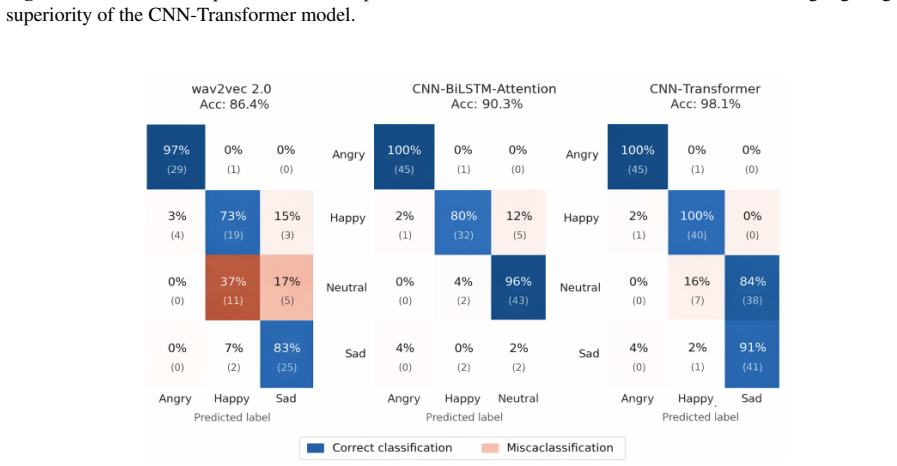
The central claim is that a CNN-Transformer architecture, by combining convolutional layers for local spectral features with transformer layers for global temporal context, achieves superior performance in Arabic speech emotion recognition, reaching 98.1% accuracy on the EYASE and BAVED datasets and outperforming both CNN-LSTM and fine-tuned wav2vec 2.0 models.
What carries the argument
The CNN-Transformer hybrid model that extracts features from MFCC and spectrogram inputs via convolutions before applying self-attention for long-range dependencies.
If this is right
- CNN-Transformer offers a robust solution for capturing spectral and long-range dependencies in low-resource Arabic SER.
- It outperforms CNN-LSTM and wav2vec 2.0 on the tested datasets.
- Systematic comparison of hybrid and self-supervised methods aids development in dialectally diverse settings.
Where Pith is reading between the lines
- The same hybrid structure could be tested on other under-resourced languages facing dialect variation.
- Accuracy might change when the model encounters real-world noisy recordings instead of controlled datasets.
- Further gains could come from incorporating larger amounts of unlabeled Arabic audio during pretraining.
Load-bearing premise
The reported accuracy on the EYASE and BAVED datasets reflects genuine generalization rather than overfitting to those specific collections.
What would settle it
Evaluating the CNN-Transformer model on an unseen Arabic dataset from a different dialect or spontaneous speech condition and checking if accuracy falls substantially below 98.1 percent.
Figures
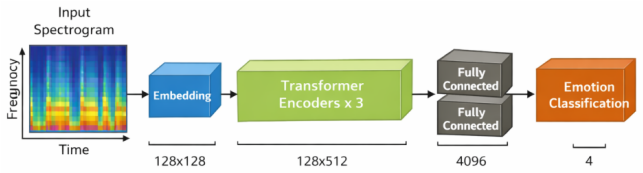
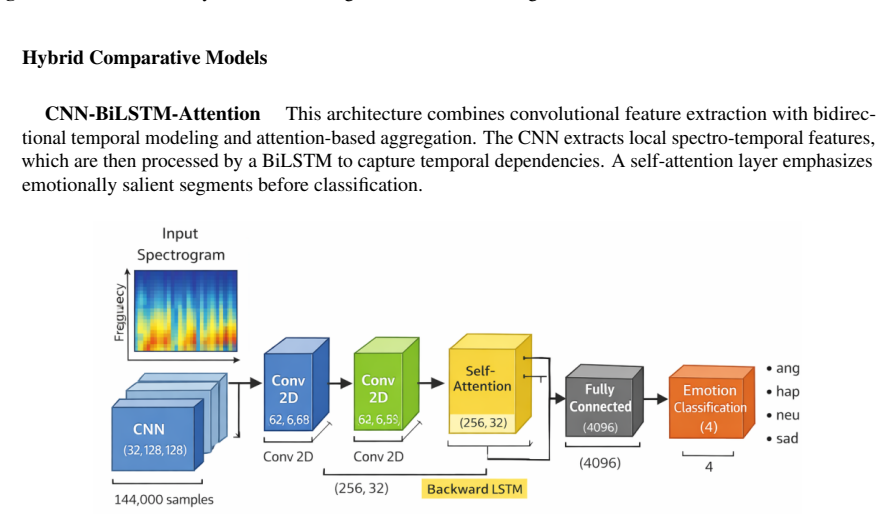
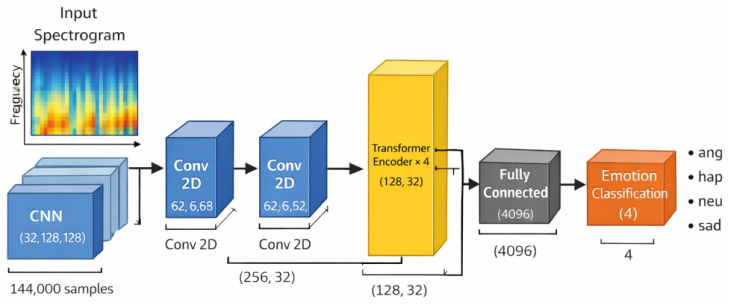
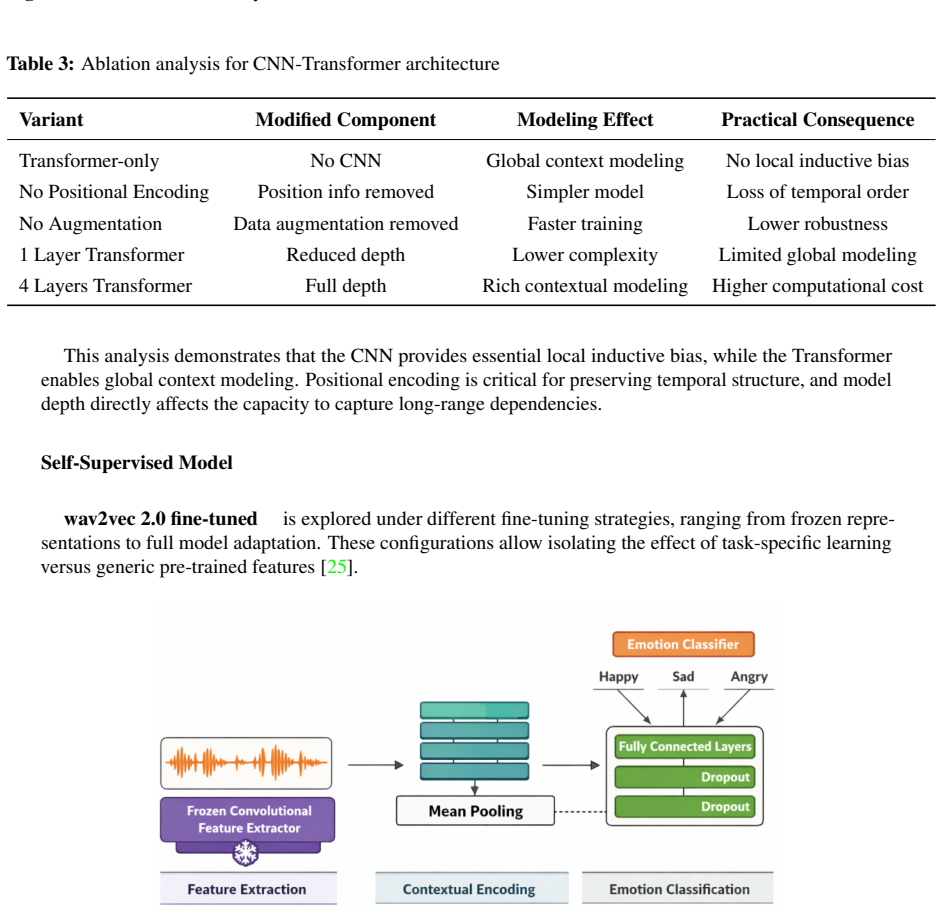


read the original abstract
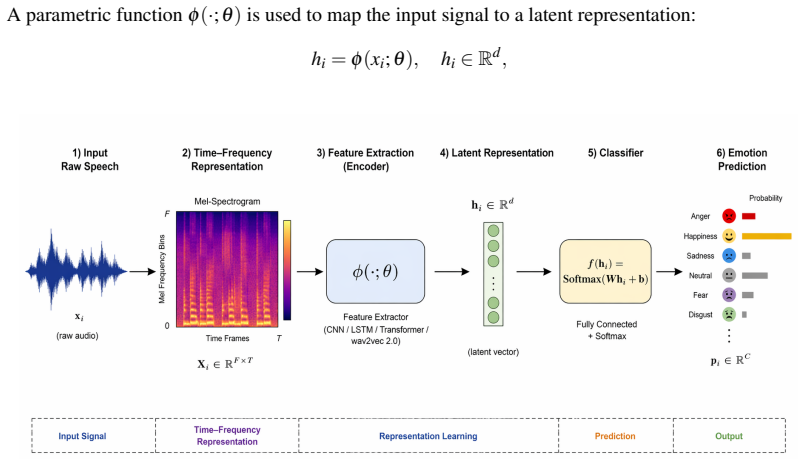
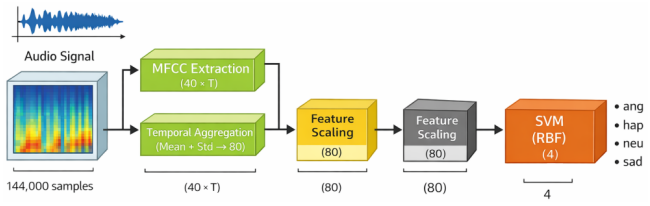
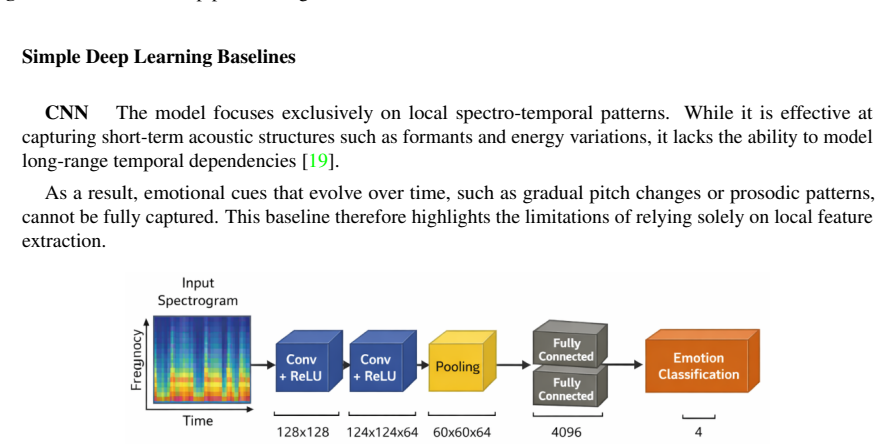
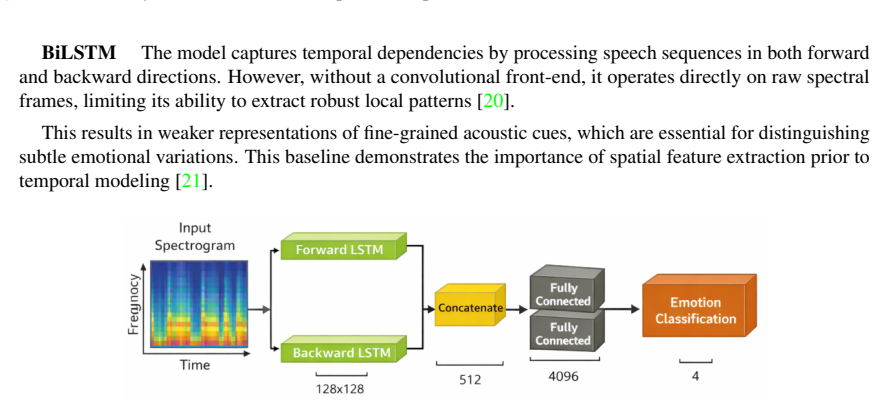
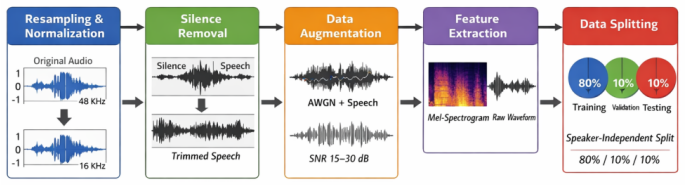
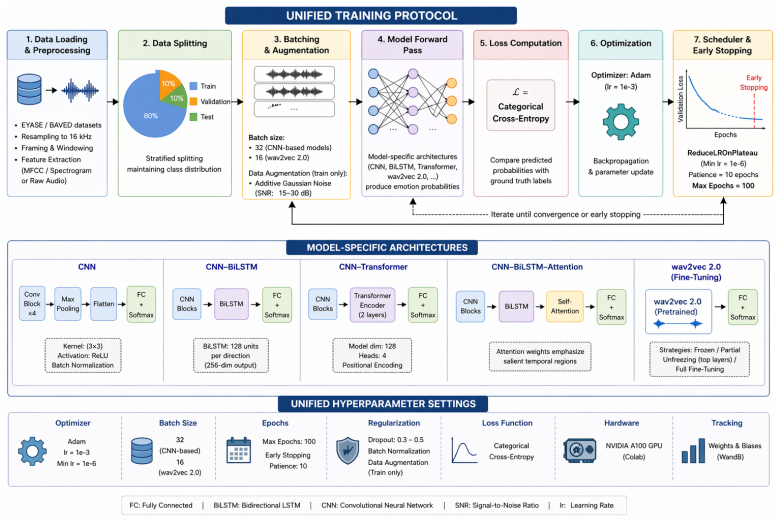
Speech Emotion Recognition (SER) aims to identify a speaker's emotional state from audio signals. While recent advances in deep learning have significantly improved SER performance in Indo-European languages, Arabic SER remains underexplored and challenging due to dialectal diversity, limited annotated datasets, and the difficulty of modeling both local spectral cues and long-range temporal dependencies. To address these limitations, this study investigates whether hybrid architectures that jointly model spatial and contextual information can improve emotion recognition in Arabic speech. We propose and evaluate a comparative framework involving three architectures: a CNN-LSTM model, a CNN-Transformer model, and a fine-tuned wav2vec 2.0 model. The first two models leverage MFCC and spectrogram-based representations, while wav2vec 2.0 operates directly on raw audio through self-supervised representations. Experiments conducted on the EYASE and BAVED datasets demonstrate that the proposed CNN-Transformer architecture significantly outperforms the other models, achieving an accuracy of 98.1 percent. This result highlights the effectiveness of combining convolutional feature extraction with Transformer-based global context modeling. The main contribution of this work lies in providing a systematic comparison of hybrid and self-supervised approaches for Arabic SER, and in demonstrating that CNN-Transformer architectures offer a robust solution for capturing both spectral and long-range dependencies in low-resource and dialectally diverse settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a comparative study of three deep learning architectures (CNN-LSTM, CNN-Transformer, and fine-tuned wav2vec 2.0) for Arabic Speech Emotion Recognition using MFCC/spectrogram and raw audio inputs. It reports that the CNN-Transformer achieves 98.1% accuracy on the EYASE and BAVED datasets, outperforming the baselines, and positions this as evidence for the value of hybrid spatial-contextual modeling in low-resource, dialectally diverse Arabic SER.
Significance. If the accuracy claim is supported by a speaker-independent held-out evaluation with full protocol details, the work would add value by addressing the relative scarcity of Arabic SER benchmarks and by providing a direct comparison of hybrid CNN-Transformer models against self-supervised baselines in a low-resource setting.
major comments (1)
- [Abstract / Experiments] Abstract (and Experiments section): The headline result of 98.1% accuracy for the CNN-Transformer on EYASE + BAVED is presented without any description of the train-test split (e.g., speaker-independent leave-one-speaker-out, stratified k-fold, or fixed partition with speaker IDs), hyperparameter search, regularization, or error analysis. This detail is load-bearing for the central claim of architectural superiority and generalization, because Arabic SER corpora are small and the reported number is consistent with either genuine performance or overfitting to dataset artifacts.
minor comments (1)
- [Abstract] The abstract states that the CNN-Transformer is 'proposed' while simultaneously describing a comparative framework of three models; the distinction between proposed contribution and baseline comparison should be clarified in the introduction or methods.
Simulated Author's Rebuttal
We thank the referee for the constructive comment highlighting the need for detailed experimental protocols. We agree that these details are essential to support the central claims, particularly given the limited size of Arabic SER datasets, and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract (and Experiments section): The headline result of 98.1% accuracy for the CNN-Transformer on EYASE + BAVED is presented without any description of the train-test split (e.g., speaker-independent leave-one-speaker-out, stratified k-fold, or fixed partition with speaker IDs), hyperparameter search, regularization, or error analysis. This detail is load-bearing for the central claim of architectural superiority and generalization, because Arabic SER corpora are small and the reported number is consistent with either genuine performance or overfitting to dataset artifacts.
Authors: We agree that the manuscript does not currently provide these details in the abstract or Experiments section. In the revised version, we will expand the Experiments section to fully describe the train-test split (including whether it is speaker-independent), the hyperparameter search process, regularization techniques, and an error analysis. This will allow proper assessment of generalization. revision: yes
Circularity Check
No derivation chain present; purely empirical comparison
full rationale
The manuscript reports experimental accuracies from training and evaluating three neural architectures (CNN-LSTM, CNN-Transformer, fine-tuned wav2vec 2.0) on the named EYASE and BAVED corpora. No equations, first-principles derivations, uniqueness theorems, or parameter-fitting steps are described whose outputs are later re-labeled as predictions. The central claim is therefore an empirical observation rather than a derived result, rendering circularity analysis inapplicable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Survey on speech emotion recognition: Features, clas- sification schemes, and databases,
M. El Ayadi, M.S. Kamel, and F. Karray, “Survey on speech emotion recognition: Features, clas- sification schemes, and databases,”Pattern Recognit., vol. 44, no. 3, pp. 572–587, 2011. https: //doi.org/10.1016/j.patcog.2010.09.020
-
[2]
ASERS-CNN: Arabic speech emotion recog- nition system based on CNN model,
M. Tajalsir, S.M. Hernandez, and F.A. Mohammed, “ASERS-CNN: Arabic speech emotion recog- nition system based on CNN model,”Signal Image Process.: Int. J., 2023. https://www. signalimageprocessingjournal.com/
2023
-
[3]
Egyptian Arabic speech emotion recognition using prosodic, spectral and wavelet fea- tures,
L. Abdel-Hamid, “Egyptian Arabic speech emotion recognition using prosodic, spectral and wavelet fea- tures,”Speech Commun., vol. 122, pp. 19–30, 2020. https://doi.org/10.1016/j.specom. 2020.04.005
-
[4]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” inProc. ICML, 2015, pp. 448–456.https://proceedings.mlr.press/v37/ ioffe15.html
2015
-
[5]
Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers,
M. B. Akçay and K. O ˘guz, “Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers,”Speech Communication, vol. 116, pp. 56–76, 2020
2020
-
[6]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and A. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” inAdv. Neural Inf. Process. Syst., vol. 33, pp. 12449–12460, 2020
2020
-
[7]
A.H. Meftah, Y .A. Alotaibi, and S.-A. Selouani, ‘King Saud University Emotions corpus: Construction, analysis, evaluation, and comparison,”IEEE Access, vol. 9, pp. 54201–54219, 2021. https://doi. org/10.1109/ACCESS.2021.3070882
-
[8]
Dropout: A simple way to prevent neural networks from overfitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,”J. Mach. Learn. Res., vol. 15, pp. 1929–1958, 2014. https://jmlr.org/papers/v15/srivastava14a.html
1929
-
[9]
R.W. Picard,Affective Computing. MIT Press, Cambridge, MA, 2000. https://mitpress.mit. edu/9780262161701/affective-computing/
arXiv 2000
-
[10]
Dynamics of affective states during complex learning,
S.K. D’Mello and A. Graesser, “Dynamics of affective states during complex learning,”Learn. Instr., vol. 22, no. 2, pp. 145–157, 2012. https://doi.org/10.1016/j.learninstruc.2011. 10.001
-
[11]
Arabic speech emotion recognition using deep neural network,
O. Mahmoudi and M.F. Bouami, “Arabic speech emotion recognition using deep neural network,” in Int. Conf. on Digital Technologies and Applications, Springer, 2023, pp. 124–133. https://doi. org/10.1007/978-3-031-29860-8_13
-
[12]
I. Shahin, A.B. Nassif, N. Hamsa, et al., “An efficient feature selection method for Arabic and English speech emotion recognition using Grey Wolf Optimizer,”Appl. Acoust., vol. 205, p. 109279, 2023. https://doi.org/10.1016/j.apacoust.2023.109279
-
[13]
Arabic English speech emotion recognition system,
M. El Seknedy and S. Fawzi, “Arabic English speech emotion recognition system,” inProc. 20th Learn. Technol. Conf. (L&T), IEEE, 2023, pp. 167–170. https://doi.org/10.1109/LT58023. 2023.10092316
-
[14]
Emotion recognition in Arabic speech signal,
D. Djeridi and R. Kedidi, “Emotion recognition in Arabic speech signal,” M.Sc. Thesis, University of Kasdi Merbah Ouargla, Algeria, 2020
2020
-
[15]
R. Rakan, S. Safwat, and M.A.-M. Salem, “Advancing Egyptian Arabic speech emotion recognition: Insights from 2D representations and model evaluations,” inProc. 11th ICICIS, IEEE, 2023, pp. 154– 159.https://doi.org/10.1109/ICICIS58388.2023.10391592
-
[16]
Biotech- 11 nology Advances 30, 1344–1353
O. Atila and A. ¸ Sengür, “Attention guided 3D CNN-LSTM model for accurate speech based emo- tion recognition,”Appl. Acoust., vol. 182, p. 108260, 2021. https://doi.org/10.1016/j. apacoust.2021.108260
work page doi:10.1016/j 2021
-
[17]
Transformer-based Arabic speech emotion recognition with feature fusion and data augmentation,
B. Al-onazi, S. Alyahya, M. Alahmadi, et al., “Transformer-based Arabic speech emotion recognition with feature fusion and data augmentation,” 2022. 20
2022
-
[18]
Arabic speech emotion recognition employing wav2vec2.0 and HuBERT based on BA VED dataset,
O. Mohamed and S. A. Aly, “Arabic speech emotion recognition employing wav2vec2.0 and HuBERT based on BA VED dataset,”arXiv preprint arXiv:2110.04425, 2021.https://arxiv.org/abs/ 2110.04425
arXiv 2021
-
[19]
ImageNet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,”Advances in Neural Information Processing Systems (NeurIPS), 2012. https://papers.nips.cc/paper_files/paper/2012/hash/ c399862d3b9d6b76c8436e924a68c45b-Abstract.html
2012
-
[20]
Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.https://doi.org/10.1162/neco.1997.9.8.1735
-
[21]
Framewise phoneme classification with bidirectional LSTM and other neural network architectures,
A. Graves and J. Schmidhuber, “Framewise phoneme classification with bidirectional LSTM and other neural network architectures,”Neural Networks, vol. 18, no. 5–6, pp. 602–610, 2005. https: //doi.org/10.1016/j.neunet.2005.03.001
-
[22]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, et al., “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017. https://papers.nips.cc/paper_files/ paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
2017
-
[23]
An efficient speech emotion recognition based on a dual-stream CNN-Transformer fusion network,
M. Tellai, L. Gao, and Q. Mao, “An efficient speech emotion recognition based on a dual-stream CNN-Transformer fusion network,”Int. J. Speech Technol., vol. 26, no. 2, pp. 541–557, 2023. https: //doi.org/10.1007/s10772-023-10020-7
-
[24]
A. Abdalla, N. Sharaf, and C. Sabty, “An enhanced Compact Convolution Transformer for age, gender and emotion detection in Egyptian Arabic speech,” inProc. Int. Conf. on Speech and Computer, Springer, 2024, pp. 30–42.https://doi.org/10.1007/978-3-031-72775-6_3
-
[25]
Building an Egyptian-Arabic speech corpus for emotion analysis using deep learning,
S. Safwat, M.A.-M. Salem, and N. Sharaf, “Building an Egyptian-Arabic speech corpus for emotion analysis using deep learning,” inPacific Rim Int. Conf. on Artificial Intelligence, Springer, 2023, pp. 320–332.https://doi.org/10.1007/978-981-99-7022-3_28 21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.