Isolation-aware Scheduling Framework for DNN-based End-to-End Autonomous Driving System on Tile-based Accelerators
Pith reviewed 2026-06-27 11:47 UTC · model grok-4.3
The pith
ADS-Tile bounds reallocation of tiles among colocated DNNs to meet end-to-end deadlines with up to 32% fewer tiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
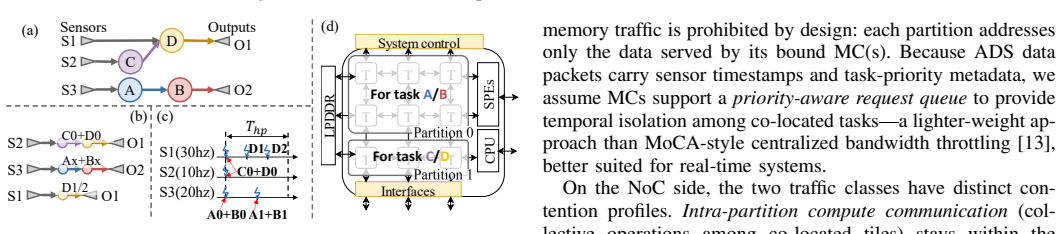
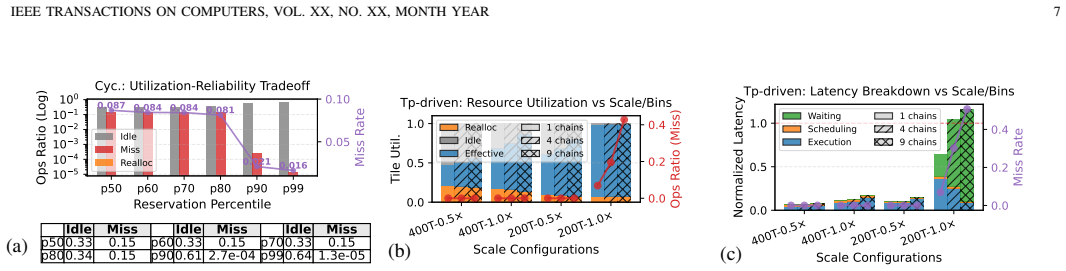
ADS-Tile combines configurable isolation and elastic reservation into a spatio-temporal isolation-sharing space that bounds where and when reallocation occurs; a probabilistic latency model and a DAG-aware runtime scheduler then use this space to decide task colocation and DoP under shared E2E deadlines. On an industry- and academia-derived ADS benchmark, ADS-Tile uses up to 32% fewer tiles than the work-conserving baseline in deadline-critical settings and cuts reallocation-induced wasted processing capacity from 17%-44% to below 1.2%.
What carries the argument
The spatio-temporal isolation-sharing space that restricts tile reallocation events among co-located DNNs along end-to-end DAGs.
If this is right
- Reservation-based schedulers that fix DoP leave flexibility unused and require more tiles overall.
- Work-conserving schedulers that ignore reallocation cost accumulate stalls along E2E chains and miss deadlines.
- Controlled sharing of tiles improves both resource efficiency and latency predictability compared with either extreme.
- The same isolation bounds allow higher task rates (10-240 Hz) without proportional growth in wasted capacity.
Where Pith is reading between the lines
- The same bounding technique could be tested on other real-time multi-DNN workloads such as robotics or surveillance pipelines that also face variable execution and reallocation costs.
- If the model holds across hardware generations, designers could reduce over-provisioning margins in future ADS chips.
- Explicitly exposing reallocation cost as a schedulable dimension may generalize to other accelerators that support dynamic partitioning.
Load-bearing premise
The probabilistic latency model must correctly predict execution time variation and reallocation costs for the specific colocation patterns and degree-of-parallelism changes that occur in the end-to-end DAGs.
What would settle it
Run the ADS-Tile scheduler on physical tile-based hardware with the benchmark workloads and measure whether observed tile count and wasted capacity match the reported 32% savings and sub-1.2% waste; any systematic exceedance of the claimed latency bounds would falsify the result.
Figures





read the original abstract
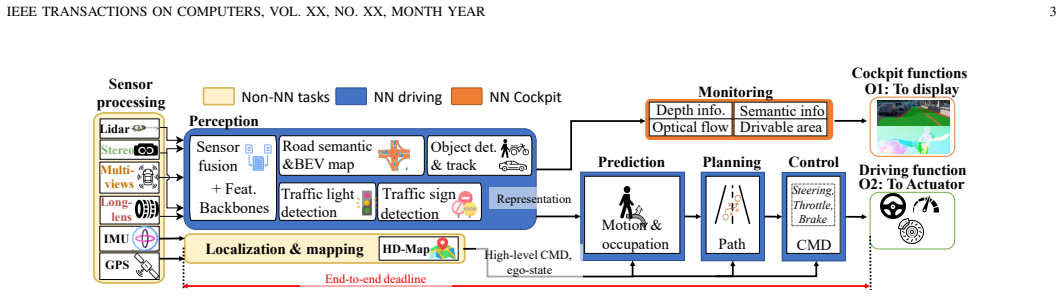
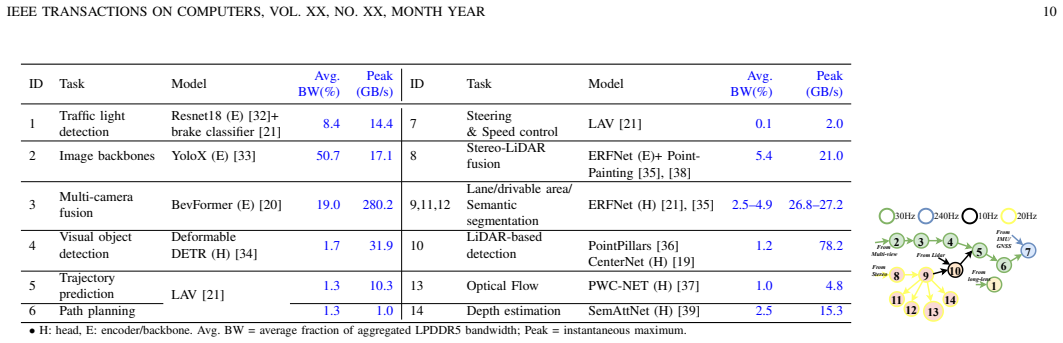
Level-4+ autonomous driving systems (ADS) must run dozens of heterogeneous deep neural networks (DNNs) as end-to-end (E2E) pipelines under a strict latency constraint (<=100 ms), even as execution time varies by up to 3.3x. Cost rules out dedicating isolated hardware to each function in mass-produced ADS, so these DNNs must be densely colocated on a single chip, which introduces shared-resource contention. Tile-based accelerators expose two scheduling opportunities that conventional ADS schedulers do not exploit. First, they provide a tunable degree of parallelism (DoP): assigning more tiles raises DoP and can shorten DNN execution time. Second, they provide hardware-native isolation: tiles can be physically partitioned among co-located DNNs. But using this flexibility is expensive: changing a task's DoP triggers a stop-migrate-restart reallocation of its weights and intermediate features. At ADS task rates of 10-240 Hz, these stalls accumulate along E2E chains and threaten deadlines. Reservation-based schedulers fix DoP and leave this flexibility unused; work-conserving schedulers exploit it but assume reallocation is cheap and treat deadlines as independent. We present ADS-Tile that combines configurable isolation and elastic reservation into a spatio-temporal isolation-sharing space that bounds where and when reallocation occurs; a probabilistic latency model and a DAG-aware runtime scheduler then use this space to decide task colocation and DoP under shared E2E deadlines. On an industry- and academia- derived ADS benchmark, ADS-Tile uses up to 32% fewer tiles than the work-conserving baseline in deadline-critical settings and cuts reallocation-induced wasted processing capacity from 17%-44% to below 1.2%. Controlled spatio-temporal sharing improves resource efficiency and latency predictability for tile-based ADS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ADS-Tile, an isolation-aware scheduling framework for DNN-based end-to-end autonomous driving systems on tile-based accelerators. It combines configurable isolation and elastic reservation in a spatio-temporal space, employs a probabilistic latency model to capture execution variation (up to 3.3x) and reallocation costs, and uses a DAG-aware runtime scheduler to select colocation and DoP while meeting <=100 ms E2E deadlines. On an industry- and academia-derived benchmark, it reports up to 32% fewer tiles than a work-conserving baseline and reduces reallocation-induced wasted capacity from 17-44% to below 1.2%.
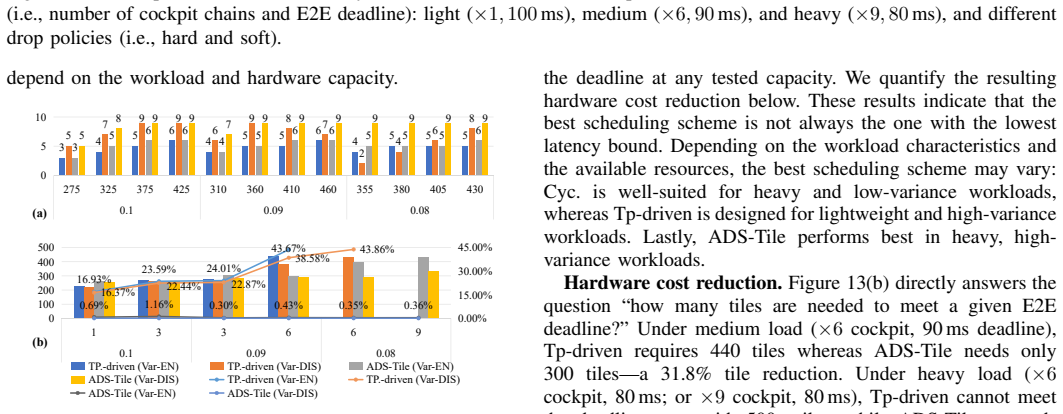
Significance. If the probabilistic model is shown to be accurate for the benchmark DAG colocation patterns, the framework would demonstrate how tile-based accelerators' DoP and isolation features can be exploited for better resource efficiency in latency-critical ADS without dedicating isolated hardware per function.
major comments (2)
- [Abstract / Probabilistic latency model] Abstract / Probabilistic latency model section: The 32% tile reduction and <1.2% waste claims rest on the model accurately predicting execution variation and stop-migrate-restart reallocation costs (at 10-240 Hz rates) for the specific E2E DAG colocation/DoP patterns in the benchmark. No derivation, fitting procedure, or hardware validation against measured tile-based accelerator traces is supplied, which is load-bearing for confirming that decisions provably meet the latency bounds.
- [Empirical evaluation] Empirical results: The reported improvements lack benchmark composition details, error bars, run counts, or explicit validation that the model holds for the colocation patterns arising in the industry/academia-derived ADS DAGs; without these, the cross-baseline comparison cannot be assessed.
minor comments (1)
- [Abstract] Abstract: The phrase 'industry- and academia-derived ADS benchmark' is used without naming the specific sources or pipeline composition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the probabilistic latency model and empirical evaluation. We address each point below and will revise the manuscript accordingly to provide the requested details and transparency.
read point-by-point responses
-
Referee: [Abstract / Probabilistic latency model] Abstract / Probabilistic latency model section: The 32% tile reduction and <1.2% waste claims rest on the model accurately predicting execution variation and stop-migrate-restart reallocation costs (at 10-240 Hz rates) for the specific E2E DAG colocation/DoP patterns in the benchmark. No derivation, fitting procedure, or hardware validation against measured tile-based accelerator traces is supplied, which is load-bearing for confirming that decisions provably meet the latency bounds.
Authors: The probabilistic latency model is presented to capture the up to 3.3x execution variation and reallocation costs at the cited rates for the E2E DAG patterns. We agree that the manuscript would benefit from explicit inclusion of the derivation, parameter fitting procedure (based on observed accelerator behavior under varying DoP and colocation), and direct comparison of model outputs to hardware traces for the benchmark colocation patterns. In the revision we will add a dedicated subsection detailing these elements, including the probabilistic formulation and validation results, to substantiate that the scheduler decisions respect the latency bounds. revision: yes
-
Referee: [Empirical evaluation] Empirical results: The reported improvements lack benchmark composition details, error bars, run counts, or explicit validation that the model holds for the colocation patterns arising in the industry/academia-derived ADS DAGs; without these, the cross-baseline comparison cannot be assessed.
Authors: We acknowledge that the initial submission omitted sufficient details on the benchmark composition, statistical reporting, and model validation for the specific colocation patterns. The benchmark combines industry-derived E2E ADS pipelines with academic DAGs; we will expand the evaluation section to list the exact DNN tasks and dependencies, report error bars and the number of experimental runs, and add targeted validation experiments confirming model accuracy on the observed colocation/DoP combinations. These additions will enable direct assessment of the baseline comparisons. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The manuscript describes an empirical scheduling system (ADS-Tile) that combines isolation and elastic reservation, a probabilistic latency model, and a DAG-aware runtime scheduler. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description. Performance numbers (32% tile reduction, waste <1.2%) are reported as benchmark outcomes rather than outputs forced by construction from inputs. The framework is therefore self-contained against external benchmarks with no load-bearing step that reduces to its own definitions or prior self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Taxonomy and definitions for terms related to driving automation systems for on-road motor vehicles J3016 202104,
Society of Automotive Engineering International, “Taxonomy and definitions for terms related to driving automation systems for on-road motor vehicles J3016 202104,”SAE Int., no. 724, p. 35, 2021. [Online]. Available: https://www.sae.org/standards/content/j3016 202104/
2021
-
[2]
GRV A guidelines for regulatory requirements and verifiable criteria for ADS safety validation — UNECE
“GRV A guidelines for regulatory requirements and verifiable criteria for ADS safety validation — UNECE.” [Online]. Avail- able: https://unece.org/transport/documents/2023/11/informal-documents/ grva-guidelines-regulatory-requirements-and
2023
-
[3]
Self-driving safety report 2024
“Self-driving safety report 2024.” [Online]. Available: https://images. nvidia.com/aem-dam/en-zz/Solutions/auto-self-driving-safety-report.pdf
2024
-
[4]
D3: A dynamic deadline-driven approach for building autonomous vehicles,
I. Goget al., “D3: A dynamic deadline-driven approach for building autonomous vehicles,”EuroSys 2022 - Proc. 17th Eur. Conf. Comput. Syst., pp. 453–471, 2022. IEEE TRANSACTIONS ON COMPUTERS, VOL. XX, NO. XX, MONTH YEAR 14
2022
-
[5]
The microarchitecture of DOJO, Tesla’s exa-scale computer,
E. Talpeset al., “The microarchitecture of DOJO, Tesla’s exa-scale computer,”IEEE Micro, vol. 43, no. 3, pp. 31–39, 2023
2023
-
[6]
NVIDIA DRIVE Thor unites A V and cockpit on a single SoC — NVIDIA blog
“NVIDIA DRIVE Thor unites A V and cockpit on a single SoC — NVIDIA blog.” [Online]. Available: https://blogs.nvidia.com/blog/drive- thor/
-
[7]
The Wormhole AI training processor,
D. Ignjatovi ´cet al., “The Wormhole AI training processor,” in2022 IEEE International Solid-State Circuits Conference (ISSCC), vol. 65, 2022, pp. 356–358
2022
-
[8]
Simba: Scaling deep-learning inference with multi-chip- module-based architecture,
Y . S. Shaoet al., “Simba: Scaling deep-learning inference with multi-chip- module-based architecture,” inProc. Annu. Int. Symp. Microarchitecture, MICRO. IEEE Computer Society, oct 2019, pp. 14–27
2019
-
[9]
Response-time analysis of ROS 2 processing chains under reservation-based scheduling,
D. Casiniet al., “Response-time analysis of ROS 2 processing chains under reservation-based scheduling,” 2019
2019
-
[10]
Mapping and scheduling automotive applications on ADAS platforms using metaheuristics,
S. D. McLeanet al., “Mapping and scheduling automotive applications on ADAS platforms using metaheuristics,”IEEE Int. Conf. Emerg. Technol. Fact. Autom. ETFA, vol. 2020-Septe, pp. 329–336, 2020
2020
-
[11]
The cyclic executive model and Ada,
T. P. Baker and A. Shaw, “The cyclic executive model and Ada,”Real- Time Systems, vol. 1, no. 1, pp. 7–25, 1989
1989
-
[12]
VELTAIR: Towards high-performance multi-tenant deep learning services via adaptive compilation and scheduling,
Z. Liuet al., “VELTAIR: Towards high-performance multi-tenant deep learning services via adaptive compilation and scheduling,”Int. Conf. Archit. Support Program. Lang. Oper. Syst. - ASPLOS, pp. 388–401, 2022
2022
-
[13]
MoCA: Memory-centric, adaptive execution for multi- tenant deep neural networks,
S. Kimet al., “MoCA: Memory-centric, adaptive execution for multi- tenant deep neural networks,” inProc. - Int. Symp. High-Performance Comput. Archit., vol. 2023-Febru, 2023, pp. 828–841
2023
-
[14]
Planaria: Dynamic architecture fission for spatial multi-tenant acceleration of deep neural networks,
S. Ghodratiet al., “Planaria: Dynamic architecture fission for spatial multi-tenant acceleration of deep neural networks,”Proc. Annu. Int. Symp. Microarchitecture, MICRO, vol. 2020-Octob, pp. 681–697, 2020
2020
-
[15]
Deadline scheduling in the Linux kernel,
J. Lelliet al., “Deadline scheduling in the Linux kernel,”Softw. - Pract. Exp., vol. 46, no. 6, pp. 821–839, jun 2016. [Online]. Available: https://dl.acm.org/doi/10.1002/spe.2335
-
[16]
IRIS: Resource reservation in the Linux kernel,
L. Marzarioet al., “IRIS: Resource reservation in the Linux kernel,” in IEEE Real-Time Systems Symposium, 2002, pp. 252–259
2002
-
[17]
Greedy reclamation of unused bandwidth in constant-bandwidth servers,
G. Lipari and S. Baruah, “Greedy reclamation of unused bandwidth in constant-bandwidth servers,” inIEEE Real-Time Systems Symposium, 2000, pp. 193–202
2000
-
[18]
Lessons learned building a self-driving car on ROS,
N. Valigi, “Lessons learned building a self-driving car on ROS,”Robot Operating System (ROS) The Complete Reference (Volume 5), pp. 127– 155, 2021
2021
-
[19]
Center-based 3D object detection and tracking,
T. Yinet al., “Center-based 3D object detection and tracking,”Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., no. Figure 1, pp. 11 779–11 788, 2021
2021
-
[20]
Z. Liet al., “BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” pp. 1–20, 2022. [Online]. Available: http://arxiv.org/abs/2203.17270
arXiv 2022
-
[21]
Learning from all vehicles,
D. Chen and P. Krahenbuhl, “Learning from all vehicles,” 2022, pp. 17 201–17 210
2022
-
[22]
Planning-oriented autonomous driving,
Y . Huet al., “Planning-oriented autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 853–17 862
2023
-
[23]
End-to-end driving via conditional imitation learning,
F. Codevillaet al., “End-to-end driving via conditional imitation learning,” Proc. - IEEE Int. Conf. Robot. Autom., pp. 4693–4700, 2018
2018
-
[24]
MAGMA: An optimization framework for mapping multiple DNNs on multiple accelerator cores,
S. C. Kao and T. Krishna, “MAGMA: An optimization framework for mapping multiple DNNs on multiple accelerator cores,”Proc. - Int. Symp. High-Perform. Comput. Archit., vol. 2022-April, pp. 814–830, 2022
2022
-
[25]
Jigsaw: Taming BEV-centric perception on dual-SoC for autonomous driving,
L. Sunet al., “Jigsaw: Taming BEV-centric perception on dual-SoC for autonomous driving,” in2024 IEEE Real-Time Systems Symposium (RTSS). IEEE, 2024, pp. 280–293
2024
-
[26]
Time constraints and fault tolerance in autonomous driving systems,
Y . Luo, “Time constraints and fault tolerance in autonomous driving systems,”Tech. Rep. No. UCB/EECS-2019-39, pp. 1—-38, 2019. [Online]. Available: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2019/ EECS-2019-39.pdf
2019
-
[27]
Parameterized block-based statistical timing analysis with non-Gaussian parameters, nonlinear delay functions,
H. Changet al., “Parameterized block-based statistical timing analysis with non-Gaussian parameters, nonlinear delay functions,” p. 71, 2005
2005
-
[28]
Algorithms for unconstrained two-dimensional guillotine cutting,
J. E. Beasley, “Algorithms for unconstrained two-dimensional guillotine cutting,”Journal of the Operational Research Society, vol. 36, no. 4, pp. 297–306, 1985
1985
-
[29]
A. H. Jianget al.,Mainstream: Dynamic Stem-Sharing for Multi-Tenant video processing, 2018. [Online]. Available: https://www.usenix.org/ conference/atc18/presentation/yan-francis
2018
-
[30]
Aurora: Virtualized accelerator orchestration for multi- tenant workloads,
S. Kimet al., “Aurora: Virtualized accelerator orchestration for multi- tenant workloads,” inProceedings of the 56th Annual IEEE/ACM Inter- national Symposium on Microarchitecture, 2023, pp. 62–76
2023
-
[31]
NVIDIA Deep Learning Accelerator (NVDLA),
NVIDIA, “NVIDIA Deep Learning Accelerator (NVDLA),” 2018. [Online]. Available: http://nvdla.org/
2018
-
[32]
Deep residual learning for image recognition,
K. Heet al., “Deep residual learning for image recognition,” inProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[33]
YOLOX: Exceeding YOLO series in 2021,
Z. Geet al., “YOLOX: Exceeding YOLO series in 2021,” pp. 1–7, 2021. [Online]. Available: http://arxiv.org/abs/2107.08430
Pith/arXiv arXiv 2021
-
[34]
Deformable DETR: Deformable transformers for end-to-end object detection,
X. Zhuet al., “Deformable DETR: Deformable transformers for end-to-end object detection,” 2020. [Online]. Available: http://arxiv.org/ abs/2010.04159
Pith/arXiv arXiv 2020
-
[35]
ERFNet: Efficient residual factorized ConvNet for real-time semantic segmentation,
L. M. Bergasaet al., “ERFNet: Efficient residual factorized ConvNet for real-time semantic segmentation,”IEEE Trans. Intell. Transp. Syst., pp. 1–10, 2018. [Online]. Available: https://github.com/Eromera/erfnet
2018
-
[36]
PointPillars: Fast encoders for object detection from point clouds,
A. H. Langet al., “PointPillars: Fast encoders for object detection from point clouds,”Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., vol. 2019-June, pp. 12 689–12 697, 2019
2019
-
[37]
PWC-Net: CNNs for optical flow using pyramid, warping, and cost volume,
D. Sunet al., “PWC-Net: CNNs for optical flow using pyramid, warping, and cost volume,”Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., vol. D, pp. 8934–8943, 2018
2018
-
[38]
PointPainting: Sequential fusion for 3D object detection,
S. V oraet al., “PointPainting: Sequential fusion for 3D object detection,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., pp. 4603– 4611, 2020
2020
-
[39]
SemAttNet: Toward attention-based semantic-aware guided depth completion,
D. Naziret al., “SemAttNet: Toward attention-based semantic-aware guided depth completion,”IEEE Access, vol. 10, pp. 120 781–120 791, 2022
2022
-
[40]
Cosa: Scheduling by constrained optimization for spatial accelerators,
Q. Huanget al., “Cosa: Scheduling by constrained optimization for spatial accelerators,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 554–566
2021
-
[41]
Timeloop: A systematic approach to DNN accelerator evaluation,
A. Parasharet al., “Timeloop: A systematic approach to DNN accelerator evaluation,”Proc. - 2019 IEEE Int. Symp. Perform. Anal. Syst. Software, ISPASS 2019, pp. 304–315, 2019
2019
-
[42]
W. J. Dally and B. P. Towles,Principles and practices of interconnection networks. Elsevier, 2004
2004
-
[43]
DREAM: A dynamic scheduler for dynamic real-time multi-model ML workloads,
S. Kimet al., “DREAM: A dynamic scheduler for dynamic real-time multi-model ML workloads,” pp. 73–86, 3 2023. [Online]. Available: https://dl.acm.org/doi/10.1145/3623278.3624753
-
[44]
V10: Hardware-assisted NPU multi-tenancy for improved resource utilization and fairness,
Y . Xueet al., “V10: Hardware-assisted NPU multi-tenancy for improved resource utilization and fairness,” pp. 1–15, 6 2023. [Online]. Available: https://dl.acm.org/doi/10.1145/3579371.3589059 Chenguang Zhangreceived the B.S. degree in electronic engineering from Tianjin University, Tianjin, China, in 2016, and the master’s degree in computer science from ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.