Flow-based generative models for amortized Bayesian inference in regression and inverse PDE problems
Pith reviewed 2026-06-27 11:16 UTC · model grok-4.3
The pith
Flow-ABI trains a functional prior via flow matching and a set-conditioned sampler to deliver near-real-time posterior samples for new observations in regression and inverse PDE problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
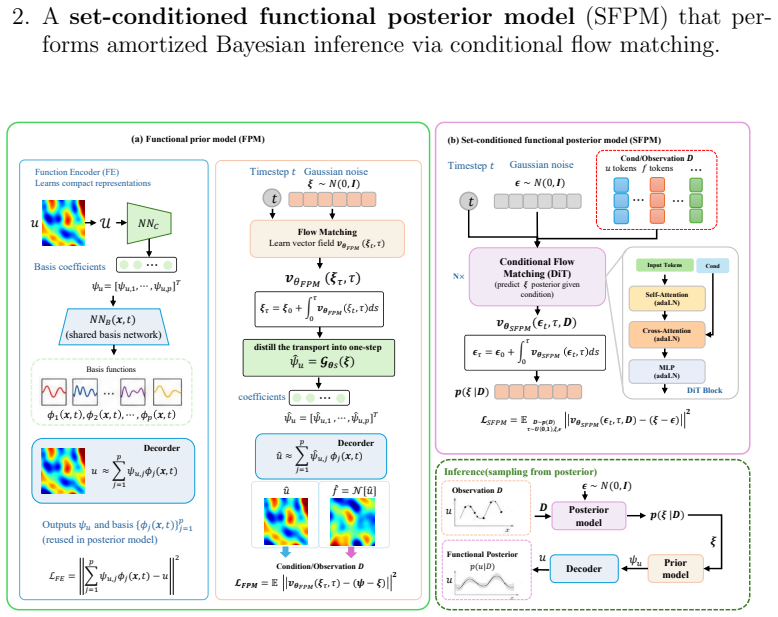
Flow-ABI consists of a functional prior model that learns expressive priors from historical data and physical knowledge through flow matching, together with a set-conditioned functional posterior sampler that maps observation sets to functional posterior distributions. The learned posterior model naturally accommodates varying, permutation-invariant observation sets and generalizes across different observation discretizations. Once trained, Flow-ABI enables near-real-time posterior sampling for previously unseen observations without retraining or iterative optimization, accurately captures both Gaussian and non-Gaussian posterior distributions, and achieves over two-order-of-magnitude speedu
What carries the argument
Flow-ABI framework whose two core components are the functional prior model learned through flow matching and the set-conditioned functional posterior sampler that processes permutation-invariant observation sets.
If this is right
- Near-real-time posterior sampling becomes possible for previously unseen observations without retraining or iterative optimization.
- Both Gaussian and non-Gaussian posterior distributions are captured accurately.
- Speedups of more than two orders of magnitude are obtained relative to Hamiltonian Monte Carlo.
- The framework integrates with physics-informed neural networks and neural operators for uncertainty-aware inverse PDE modeling.
- The sampler handles varying, permutation-invariant observation sets and generalizes across different observation discretizations.
Where Pith is reading between the lines
- Continuous sensor streams could be processed in digital-twin systems without restarting expensive inference each time new data arrives.
- The same amortization pattern may extend to other function-valued inference tasks where observation locations arrive irregularly.
- Because the sampler is permutation-invariant, problems with missing or unevenly spaced data could be handled without extra preprocessing steps.
Load-bearing premise
The functional prior model successfully learns expressive priors from historical data and physical knowledge through flow matching, and the set-conditioned functional posterior sampler generalizes across different observation discretizations and permutation-invariant sets.
What would settle it
For a new observation set, the distribution of samples drawn from the trained Flow-ABI posterior sampler differs from the distribution produced by Hamiltonian Monte Carlo in mean, variance, or higher-order statistics.
Figures
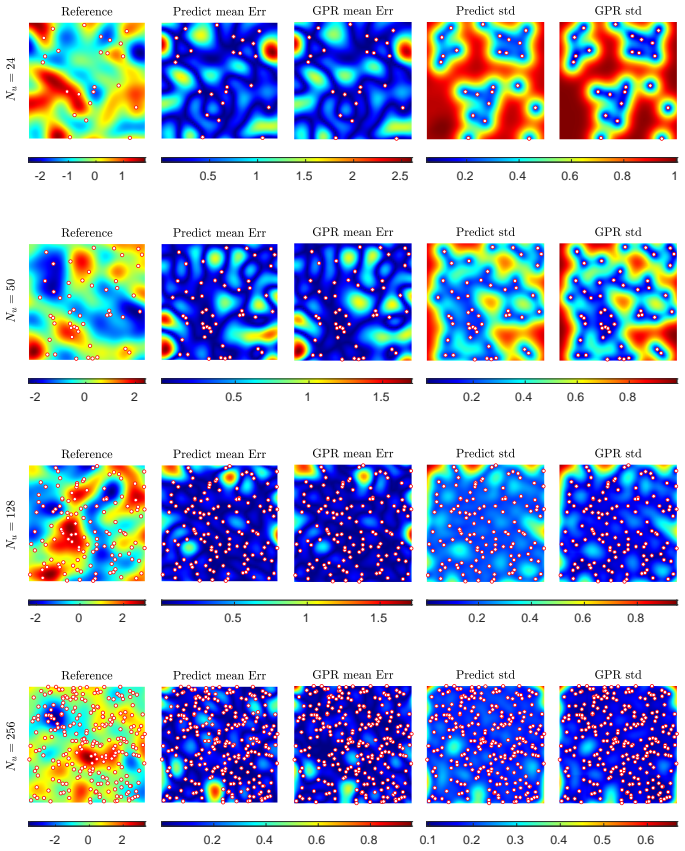
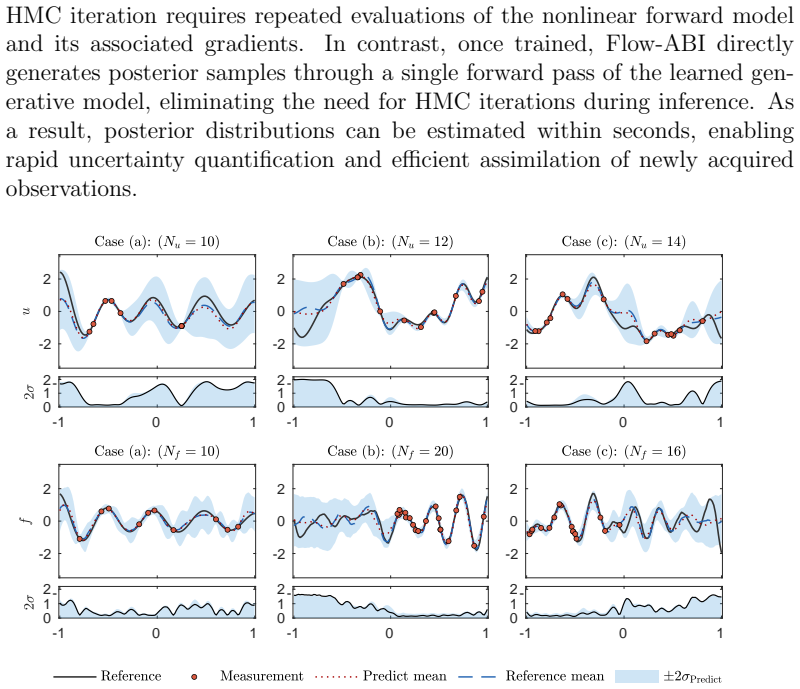
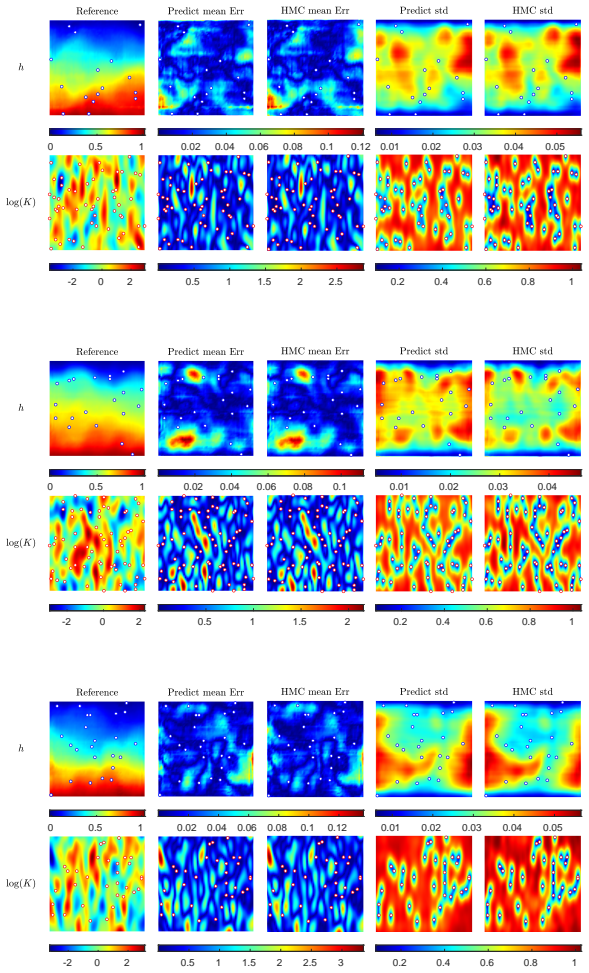
read the original abstract
Bayesian inference provides a principled framework for uncertainty quantification in scientific machine learning. However, conventional Bayesian approaches usually require solving a new inference problem for each observation set, causing substantial computational costs that hinder real-time applications like online monitoring and digital twins. Furthermore, inferring over infinite-dimensional function spaces with varying observation sets poses major challenges for existing amortized inference methods. In this work, we propose Flow-ABI, a flow-based generative framework for amortized Bayesian inference in regression and inverse partial differential equation (PDE) problems. It consists of two components: (i) a functional prior model that learns expressive priors from historical data and physical knowledge through flow matching, and (ii) a set-conditioned functional posterior sampler mapping observation sets to functional posterior distributions. The learned posterior model naturally accommodates varying, permutation-invariant observation sets, and generalizes across different observation discretizations. Once trained, Flow-ABI enables near-real-time posterior sampling for previously unseen observations without retraining or iterative optimization. The proposed methodology can be seamlessly integrated with a wide class of scientific machine learning frameworks, including physics-informed neural networks and neural operators, for uncertainty-aware inverse PDE modeling. Experiments demonstrate that Flow-ABI accurately captures both Gaussian and non-Gaussian posterior distributions while achieving over two-order-of-magnitude speedups relative to the gold-standard Bayesian inference method, Hamiltonian Monte Carlo. These results show Flow-ABI is an effective, scalable, and computationally efficient framework for uncertainty quantification in scientific machine learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Flow-ABI, a flow-based generative framework for amortized Bayesian inference in regression and inverse PDE problems. It comprises (i) a functional prior model learned via flow matching from historical data and physical knowledge and (ii) a set-conditioned functional posterior sampler that maps varying, permutation-invariant observation sets to functional posteriors while generalizing across discretizations. Once trained, the model enables near-real-time posterior sampling for unseen observations without retraining or optimization, integrates with PINNs and neural operators, and is reported to capture both Gaussian and non-Gaussian posteriors with >100x speedups over HMC.
Significance. If the generalization of the set-conditioned sampler holds, the work would provide a meaningful advance for efficient uncertainty quantification in scientific machine learning, particularly for real-time and online applications such as digital twins.
major comments (2)
- [Abstract, paragraph 3] Abstract, paragraph 3 and the description of the set-conditioned sampler: the amortization guarantee rests on the claim that a single trained model maps arbitrary finite observation sets (varying cardinality, locations, and discretizations) to the correct functional posterior. The training distribution of observation sets must be shown to be sufficiently diverse; otherwise the reported generalization to unseen discretizations is at risk of producing biased samples even when in-distribution performance is good.
- [Experiments section] Experiments section (results on posterior accuracy and speedups): the reported two-order-of-magnitude speedups and accurate capture of non-Gaussian posteriors are presented without explicit controls for implementation differences versus HMC or error bars on the sampled posteriors, leaving the quantitative claims difficult to verify as robust.
minor comments (1)
- [Notation and Methods] The notation distinguishing the functional prior model from the set-conditioned posterior sampler would benefit from an explicit early definition of the flow-matching objective and the permutation-invariant architecture.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract, paragraph 3] Abstract, paragraph 3 and the description of the set-conditioned sampler: the amortization guarantee rests on the claim that a single trained model maps arbitrary finite observation sets (varying cardinality, locations, and discretizations) to the correct functional posterior. The training distribution of observation sets must be shown to be sufficiently diverse; otherwise the reported generalization to unseen discretizations is at risk of producing biased samples even when in-distribution performance is good.
Authors: We agree that the diversity of the training distribution is key to supporting the generalization claims. The manuscript describes that observation sets are sampled with varying cardinalities and locations, but to address this concern, we will expand the methods section to provide more details on the specific distribution used for training, including the ranges and sampling strategies. Additionally, we will include results on a broader set of unseen discretizations to demonstrate robustness. revision: yes
-
Referee: [Experiments section] Experiments section (results on posterior accuracy and speedups): the reported two-order-of-magnitude speedups and accurate capture of non-Gaussian posteriors are presented without explicit controls for implementation differences versus HMC or error bars on the sampled posteriors, leaving the quantitative claims difficult to verify as robust.
Authors: The referee raises a valid point regarding the presentation of quantitative results. We will revise the experiments section to include more detailed controls, such as specifying the HMC hyperparameters and computational setup for fair comparison, and report standard deviations or error bars from repeated sampling runs to better support the accuracy and speedup claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and context contain no equations, self-citations, or derivations that reduce any claimed prediction or result to fitted inputs or prior author work by construction. Claims about generalization of the set-conditioned sampler and speedups are presented as empirical outcomes of the proposed architecture rather than tautological re-statements of training data. No load-bearing steps match the enumerated circularity patterns; the methodology is described as self-contained against external benchmarks like HMC.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Physics- informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics- informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378:686–707, 2019
2019
-
[2]
Dgm: A deep learning algorithm for solving partial differential equations.Journal of computa- tional physics, 375:1339–1364, 2018
Justin Sirignano and Konstantinos Spiliopoulos. Dgm: A deep learning algorithm for solving partial differential equations.Journal of computa- tional physics, 375:1339–1364, 2018
2018
-
[3]
Learning nonlinear operators via deeponet based on the uni- versal approximation theorem of operators.Nature machine intelligence, 3(3):218–229, 2021
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the uni- versal approximation theorem of operators.Nature machine intelligence, 3(3):218–229, 2021
2021
-
[4]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Neu- ral operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neu- ral operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023. 33
2023
-
[6]
Uncertainty quantification in scientific machine learning: Methods, metrics, and comparisons.Journal of Computational Physics, 477:111902, 2023
Apostolos F Psaros, Xuhui Meng, Zongren Zou, Ling Guo, and George Em Karniadakis. Uncertainty quantification in scientific machine learning: Methods, metrics, and comparisons.Journal of Computational Physics, 477:111902, 2023
2023
-
[7]
Neuraluq: A comprehensive library for uncertainty quantification in neural differential equations and operators.SIAM Review, 66(1):161– 190, 2024
Zongren Zou, Xuhui Meng, Apostolos F Psaros, and George E Karni- adakis. Neuraluq: A comprehensive library for uncertainty quantification in neural differential equations and operators.SIAM Review, 66(1):161– 190, 2024
2024
-
[8]
Multi-fidelity bayesian neural networks: Algorithms and applications.Journal of Com- putational Physics, 438:110361, 2021
Xuhui Meng, Hessam Babaee, and George Em Karniadakis. Multi-fidelity bayesian neural networks: Algorithms and applications.Journal of Com- putational Physics, 438:110361, 2021
2021
-
[9]
Bayesian physics informed neural networks for real-world nonlinear dynamical systems.Computer Methods in Applied Mechanics and Engineering, 402:115346, 2022
Kevin Linka, Amelie Sch¨ afer, Xuhui Meng, Zongren Zou, George Em Kar- niadakis, and Ellen Kuhl. Bayesian physics informed neural networks for real-world nonlinear dynamical systems.Computer Methods in Applied Mechanics and Engineering, 402:115346, 2022
2022
-
[10]
Adversarial uncertainty quantification in physics-informed neural networks.Journal of Computational Physics, 394:136–152, 2019
Yibo Yang and Paris Perdikaris. Adversarial uncertainty quantification in physics-informed neural networks.Journal of Computational Physics, 394:136–152, 2019
2019
-
[11]
Amirhossein Mollaali, Christian B Moya, Amanda Howard, Alexander Heinlein, Panos Stinis, and Guang Lin. Conformalized-kans: Uncertainty quantification with coverage guarantees for kolmogorov-arnold networks (kans) in scientific machine learning.Machine Learning: Science and Technology, 2025
2025
-
[12]
Springer Science & Business Media, 2012
Radford M Neal.Bayesian learning for neural networks, volume 118. Springer Science & Business Media, 2012
2012
-
[13]
Expressive priors in bayesian neural networks: Kernel com- binations and periodic functions
Tim Pearce, Russell Tsuchida, Mohamed Zaki, Alexandra Brintrup, and Andy Neely. Expressive priors in bayesian neural networks: Kernel com- binations and periodic functions. InUncertainty in artificial intelligence, pages 134–144. PMLR, 2020
2020
-
[14]
Sim- ple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Sim- ple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30, 2017. 34
2017
-
[15]
Dropout as a bayesian approxima- tion: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approxima- tion: Representing model uncertainty in deep learning. Ininternational conference on machine learning, pages 1050–1059. PMLR, 2016
2016
-
[16]
B-pinns: Bayesian physics-informed neural networks for forward and inverse pde problems with noisy data.Journal of Computational Physics, 425:109913, 2021
Liu Yang, Xuhui Meng, and George Em Karniadakis. B-pinns: Bayesian physics-informed neural networks for forward and inverse pde problems with noisy data.Journal of Computational Physics, 425:109913, 2021
2021
-
[17]
Discovering and forecasting extreme events via active learning in neural operators.Nature Computational Science, 2(12):823– 833, 2022
Ethan Pickering, Stephen Guth, George Em Karniadakis, and Themis- toklis P Sapsis. Discovering and forecasting extreme events via active learning in neural operators.Nature Computational Science, 2(12):823– 833, 2022
2022
-
[18]
Physics- informed generative adversarial networks for stochastic differential equa- tions.SIAM Journal on Scientific Computing, 42(1):A292–A317, 2020
Liu Yang, Dongkun Zhang, and George Em Karniadakis. Physics- informed generative adversarial networks for stochastic differential equa- tions.SIAM Journal on Scientific Computing, 42(1):A292–A317, 2020
2020
-
[19]
Learning functional priors and posteriors from data and physics.Journal of Computational Physics, 457:111073, 2022
Xuhui Meng, Liu Yang, Zhiping Mao, Jos´ e del ´Aguila Ferrandis, and George Em Karniadakis. Learning functional priors and posteriors from data and physics.Journal of Computational Physics, 457:111073, 2022
2022
-
[20]
L-hydra: Multi-head physics- informed neural networks.arXiv preprint arXiv:2301.02152, 2023
Zongren Zou and George Em Karniadakis. L-hydra: Multi-head physics- informed neural networks.arXiv preprint arXiv:2301.02152, 2023
-
[21]
Shaoqian Zhou, Wen You, Ling Guo, and Xuhui Meng. Scalable physics- informed deep generative model for solving forward and inverse stochastic differential equations.arXiv preprint arXiv:2503.18012, 2025
-
[22]
Flow matching for scalable simulation-based inference.Advances in Neural Information Processing Systems, 36:16837–16864, 2023
Jonas Wildberger, Maximilian Dax, Simon Buchholz, Stephen Green, Jakob H Macke, and Bernhard Sch¨ olkopf. Flow matching for scalable simulation-based inference.Advances in Neural Information Processing Systems, 36:16837–16864, 2023
2023
-
[23]
The frontier of simulation-based inference.Proceedings of the National Academy of Sci- ences, 117(48):30055–30062, 2020
Kyle Cranmer, Johann Brehmer, and Gilles Louppe. The frontier of simulation-based inference.Proceedings of the National Academy of Sci- ences, 117(48):30055–30062, 2020
2020
-
[24]
Louis Sharrock, Jack Simons, Song Liu, and Mark Beaumont. Sequential neural score estimation: Likelihood-free inference with conditional score based diffusion models.arXiv preprint arXiv:2210.04872, 2022. 35
-
[25]
Score modeling for simulation-based inference
Tomas Geffner, George Papamakarios, and Andriy Mnih. Score modeling for simulation-based inference. InNeurIPS 2022 workshop on score-based methods, 2022
2022
-
[26]
Bayesflow: Learning complex stochastic models with invertible neural networks.IEEE transactions on neural networks and learning systems, 33(4):1452–1466, 2020
Stefan T Radev, Ulf K Mertens, Andreas Voss, Lynton Ardizzone, and Ullrich K¨ othe. Bayesflow: Learning complex stochastic models with invertible neural networks.IEEE transactions on neural networks and learning systems, 33(4):1452–1466, 2020
2020
-
[27]
Bo Yuan, Yun Zhou, Zhichao Xu, Kiran Ramnath, Aosong Feng, and Balasubramaniam Srinivasan. Bayesflow: A probability inference framework for meta-agent assisted workflow generation.arXiv preprint arXiv:2601.22305, 2026
-
[28]
Bayesflow++: A unified frame- work for amortized bayesian inference in complex systems
Himanshu Kumar and Rishabh Agrawal. Bayesflow++: A unified frame- work for amortized bayesian inference in complex systems. In2025 61st Allerton Conference on Communication, Control, and Computing Pro- ceedings. Allerton Conference on Communication, Control, and Comput- ing, 2025
2025
-
[29]
Real-time gravitational wave science with neural posterior estimation.Physical review letters, 127(24):241103, 2021
Maximilian Dax, Stephen R Green, Jonathan Gair, Jakob H Macke, Alessandra Buonanno, and Bernhard Sch¨ olkopf. Real-time gravitational wave science with neural posterior estimation.Physical review letters, 127(24):241103, 2021
2021
-
[30]
Bayesian optimization for likelihood-free cosmological inference.Physical Review D, 98(6):063511, 2018
Florent Leclercq. Bayesian optimization for likelihood-free cosmological inference.Physical Review D, 98(6):063511, 2018
2018
-
[31]
Pinghe Ni, Qiang Han, Xiuli Du, and Xiaowei Cheng. Bayesian model updating of civil structures with likelihood-free inference approach and response reconstruction technique.Mechanical Systems and Signal Pro- cessing, 164:108204, 2022
2022
-
[32]
Jice Zeng, Yuanzhe Wang, Alexandre M Tartakovsky, and David A Barajas-Solano. Solving high-dimensional inverse problems using amor- tized likelihood-free inference with noisy and incomplete data.Computer Methods in Applied Mechanics and Engineering, 443:118064, 2025
2025
-
[33]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 36
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Scalable diffusion models with trans- formers
William Peebles and Saining Xie. Scalable diffusion models with trans- formers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[36]
Random features for large-scale kernel machines.Advances in neural information processing systems, 20, 2007
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines.Advances in neural information processing systems, 20, 2007
2007
-
[37]
Alberto Cabezas, Adrien Corenflos, Junpeng Lao, R´ emi Louf, Antoine Carnec, Kaustubh Chaudhari, Reuben Cohn-Gordon, Jeremie Coullon, Wei Deng, Sam Duffield, et al. Blackjax: composable bayesian inference in jax.arXiv preprint arXiv:2402.10797, 2024
-
[38]
Physics- informed semantic inpainting: Application to geostatistical modeling
Qiang Zheng, Lingzao Zeng, and George Em Karniadakis. Physics- informed semantic inpainting: Application to geostatistical modeling. Journal of Computational Physics, 419:109676, 2020. 37
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.