Efficient RWKV-based Representation Learning for 3D Point Clouds
Pith reviewed 2026-06-27 14:17 UTC · model grok-4.3
The pith
P-RWKV adapts RWKV for point clouds by adding local perception and spatial enhancement while retaining linear complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
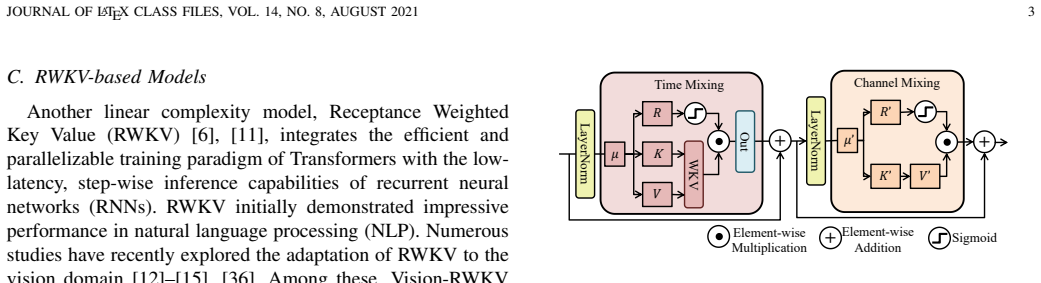
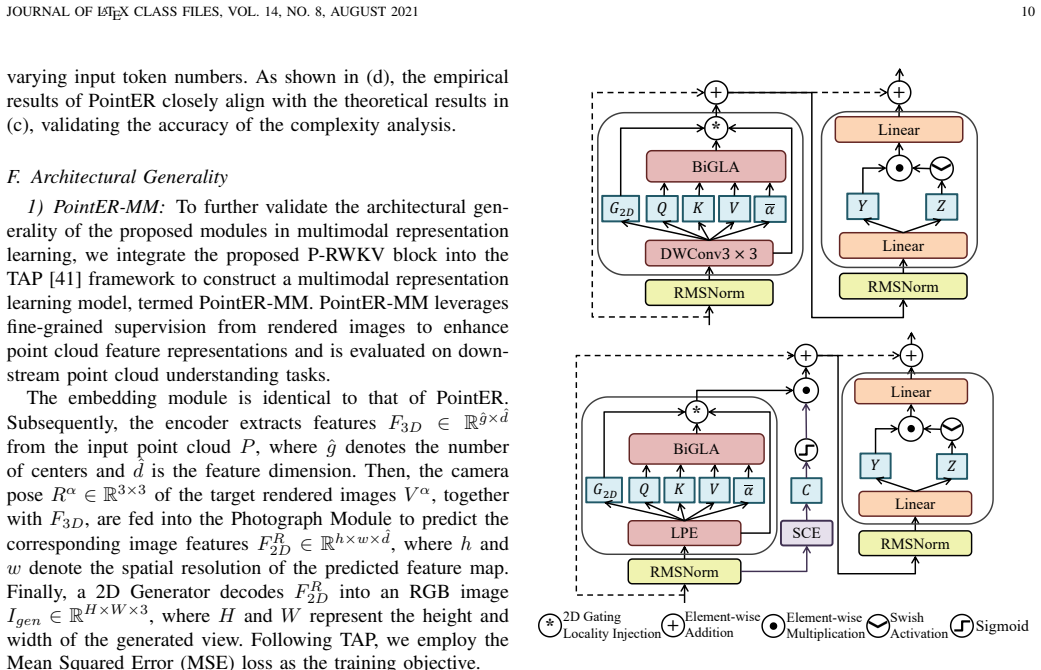
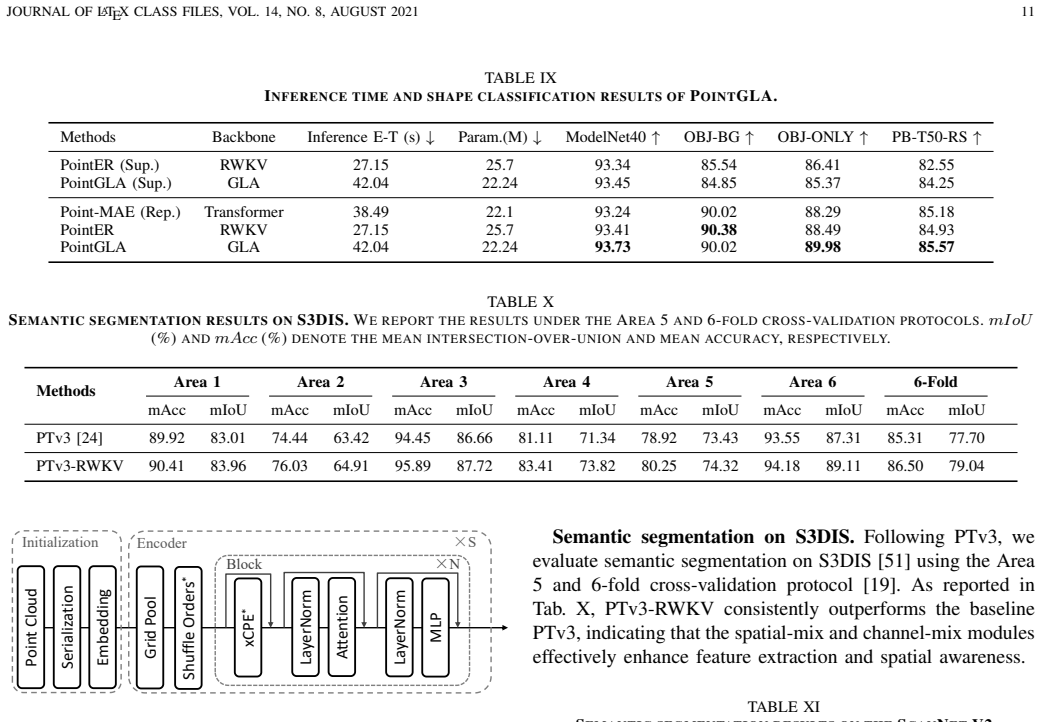
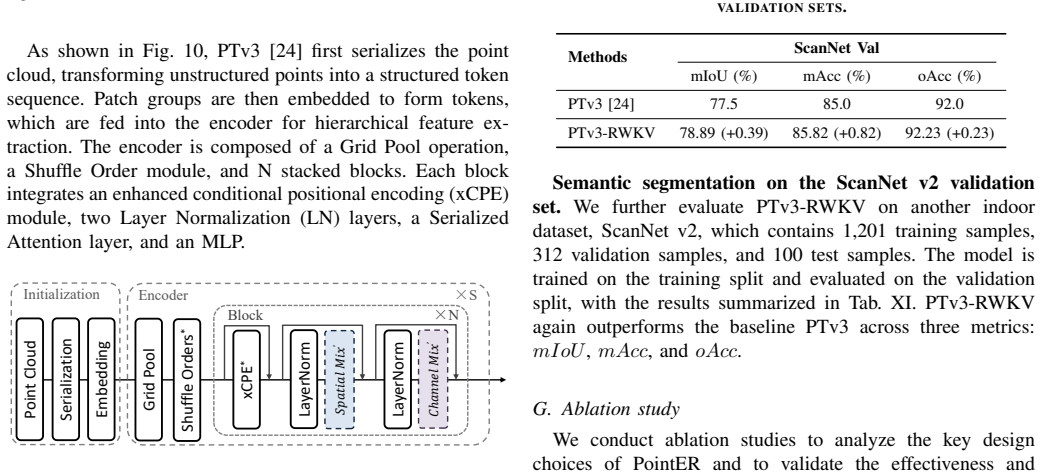
The P-RWKV block bridges sequence modeling and irregular 3D geometry while preserving RWKV efficiency; it consists of a Local Perception Expansion component to expand contextual perception along the spatio-temporal sequence and a Spatial Context Enhancement component to strengthen spatial awareness. Stacked P-RWKV blocks form the encoder of the single-modality PointER self-supervised framework, with the same sub-modules integrated into cross-modality settings and multiple architectures to demonstrate plug-and-play flexibility.
What carries the argument
The P-RWKV block, built from Local Perception Expansion (LPE) to expand contextual perception and Spatial Context Enhancement (SCE) to strengthen spatial awareness.
If this is right
- Stacked P-RWKV blocks serve as an effective encoder for self-supervised point cloud representation learning in the PointER framework.
- P-RWKV extends to cross-modality settings while keeping its core sub-modules.
- The sub-modules integrate as plug-and-play components into multiple existing architectures.
- The approach delivers competitive task performance at lower computational cost and inference latency than attention-based alternatives.
Where Pith is reading between the lines
- The linear scaling could support processing denser point clouds on hardware with limited memory.
- Similar local and spatial additions might adapt RWKV-style models to other irregular structures such as meshes or graphs.
- The plug-and-play property suggests the block could replace attention layers in existing 3D pipelines with minimal redesign.
Load-bearing premise
Adding the Local Perception Expansion and Spatial Context Enhancement components lets RWKV capture local geometric structures and spatial dependencies in point clouds without losing its linear complexity advantage.
What would settle it
A benchmark run on large point clouds where P-RWKV exhibits quadratic scaling in time or memory, or where accuracy falls below standard attention baselines without the claimed latency reduction.
Figures




read the original abstract
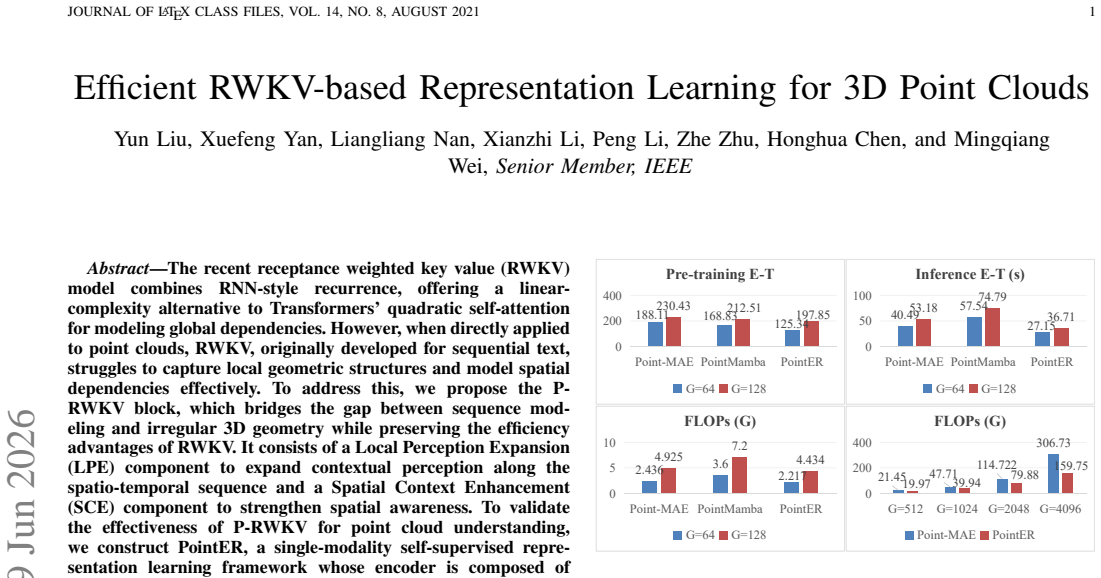
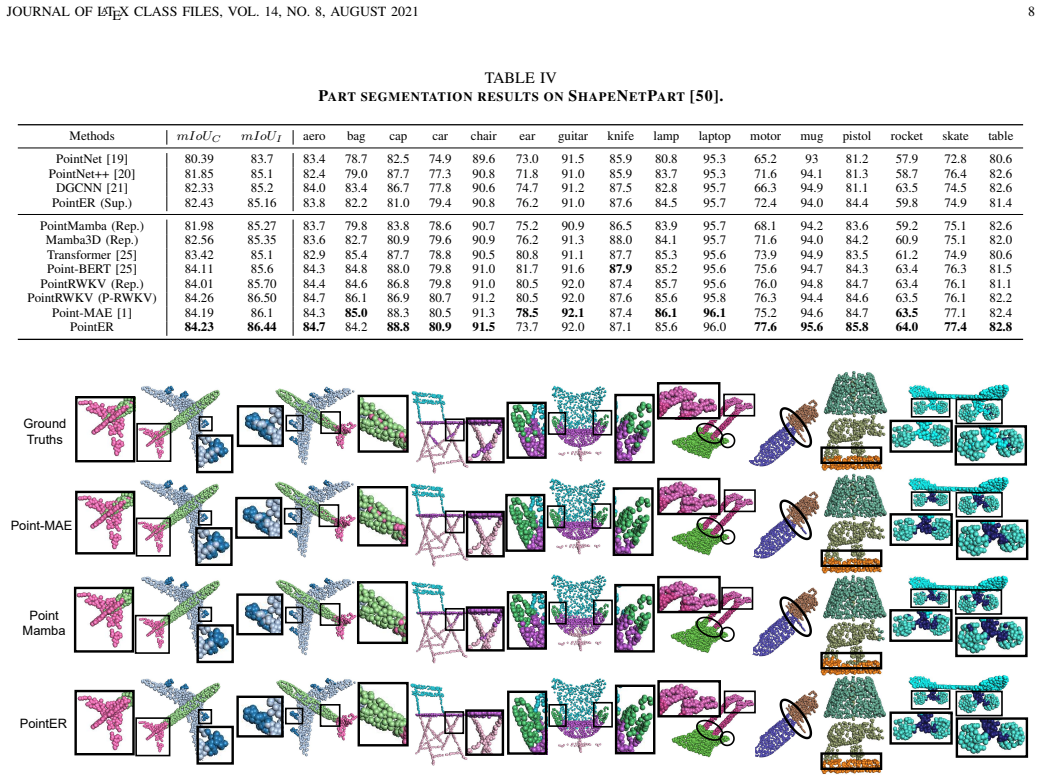
The recent receptance weighted key value (RWKV) model combines RNN-style recurrence, offering a linear-complexity alternative to Transformers' quadratic self-attention for modeling global dependencies. However, when directly applied to point clouds, RWKV, originally developed for sequential text, struggles to capture local geometric structures and model spatial dependencies effectively. To address this, we propose the \textbf{P-RWKV} block, which bridges the gap between sequence modeling and irregular 3D geometry while preserving the efficiency advantages of RWKV. It consists of a Local Perception Expansion (LPE) component to expand contextual perception along the spatio-temporal sequence and a Spatial Context Enhancement (SCE) component to strengthen spatial awareness. To validate the effectiveness of P-RWKV for point cloud understanding, we construct PointER, a single-modality self-supervised representation learning framework whose encoder is composed of stacked P-RWKV blocks. Furthermore, we extend P-RWKV to a cross-modality setting and integrate the proposed core sub-modules into multiple architectures, demonstrating strong plug-and-play flexibility and architectural generality. Extensive experiments show that the P-RWKV block and its key sub-modules achieve competitive performance across various tasks with lower computational cost and inference latency. Code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the P-RWKV block as an adaptation of the RWKV model for 3D point clouds. It introduces Local Perception Expansion (LPE) to expand contextual perception along spatio-temporal sequences and Spatial Context Enhancement (SCE) to strengthen spatial awareness, while claiming to preserve RWKV's linear complexity. The work constructs the PointER self-supervised single-modality framework with stacked P-RWKV blocks and extends the core modules to cross-modality settings, asserting competitive performance on various tasks with lower computational cost and inference latency.
Significance. If the performance and efficiency claims are substantiated by experiments, the work could provide a practical linear-complexity alternative to quadratic-attention models for irregular 3D data, with plug-and-play flexibility as a notable strength for architectural generality in point cloud understanding.
major comments (2)
- [Abstract] Abstract: the central claims of 'competitive performance across various tasks with lower computational cost and inference latency' and effective bridging of sequence modeling with irregular 3D geometry rest entirely on experimental validation, yet the abstract supplies no quantitative metrics, baselines, ablation results, or error analysis, rendering it impossible to assess whether the data support the stated claims.
- [§3 (P-RWKV block description)] The assumption that LPE and SCE additions preserve linear complexity while capturing local geometric structures and spatial dependencies in point clouds is load-bearing for the efficiency advantage; without an explicit complexity analysis or proof that no quadratic terms are introduced (e.g., in the spatio-temporal sequence handling), the efficiency claim cannot be verified.
minor comments (2)
- [Abstract] The abstract would benefit from at least one key quantitative result (e.g., mIoU or latency comparison) to ground the performance claims.
- [Method] Notation for the LPE and SCE components should be introduced with explicit equations or pseudocode early in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'competitive performance across various tasks with lower computational cost and inference latency' and effective bridging of sequence modeling with irregular 3D geometry rest entirely on experimental validation, yet the abstract supplies no quantitative metrics, baselines, ablation results, or error analysis, rendering it impossible to assess whether the data support the stated claims.
Authors: We agree that the abstract would be strengthened by including quantitative support for the claims. In the revised version, we will incorporate key experimental results (e.g., task accuracies, FLOPs reductions, and latency comparisons versus baselines) directly into the abstract while keeping it concise. revision: yes
-
Referee: [§3 (P-RWKV block description)] The assumption that LPE and SCE additions preserve linear complexity while capturing local geometric structures and spatial dependencies in point clouds is load-bearing for the efficiency advantage; without an explicit complexity analysis or proof that no quadratic terms are introduced (e.g., in the spatio-temporal sequence handling), the efficiency claim cannot be verified.
Authors: We acknowledge the value of an explicit complexity breakdown. The design of LPE and SCE intentionally reuses the linear-time recurrence of RWKV and avoids any quadratic operations (e.g., no dense pairwise interactions). In the revision we will add a dedicated complexity subsection in §3 that derives the O(N) cost for each component, including the spatio-temporal sequence handling, to make the linear-complexity claim fully verifiable. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript text provided (abstract plus placeholder for full content) contains no equations, parameter fits, derivation chains, or self-citations that reduce any claimed result to its own inputs by construction. The P-RWKV proposal, LPE/SCE components, and PointER framework are described as architectural additions without any visible self-definitional loops, fitted-input predictions, or load-bearing self-citations. The central claims therefore remain independent of the patterns that would trigger a positive circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Masked autoencoders for point cloud self-supervised learning,
Y . Pang, W. Wang, F. E. H. Tay, W. Liu, Y . Tian, and L. Yuan, “Masked autoencoders for point cloud self-supervised learning,” inComputer Vision - ECCV, 2022, pp. 604–621
2022
-
[2]
Point-m2ae: Multi-scale masked autoencoders for hierarchical point cloud pre-training,
R. Zhang, Z. Guo, P. Gao, R. Fang, B. Zhao, D. Wang, Y . Qiao, and H. Li, “Point-m2ae: Multi-scale masked autoencoders for hierarchical point cloud pre-training,” inNeurIPS, 2022, pp. 27 061–27 074
2022
-
[3]
Point- gpt: Auto-regressively generative pre-training from point clouds,
G. Chen, M. Wang, Y . Yang, K. Yu, L. Yuan, and Y . Yue, “Point- gpt: Auto-regressively generative pre-training from point clouds,” in NeurIPS, 2023
2023
-
[4]
Pointmamba: A simple state space model for point cloud analysis,
D. Liang, X. Zhou, W. Xu, X. Zhu, Z. Zou, X. Ye, X. Tan, and X. Bai, “Pointmamba: A simple state space model for point cloud analysis,” in NeurIPS, 2024
2024
-
[5]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”CoRR, vol. abs/2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
RWKV: reinventing rnns for the transformer era,
B. Peng, E. Alcaide, Q. Anthony, A. Albalak, S. Arcadinho, S. Bider- man, H. Cao, X. Cheng, M. Chung, L. Derczynski, X. Du, M. Grella, K. K. GV , X. He, H. Hou, P. Kazienko, J. Kocon, J. Kong, B. Koptyra, H. Lau, J. Lin, K. S. I. Mantri, F. Mom, A. Saito, G. Song, X. Tang, J. S. Wind, S. Wozniak, Z. Zhang, Q. Zhou, J. Zhu, and R. Zhu, “RWKV: reinventing r...
2023
-
[7]
Mamba3d: Enhancing local features for 3d point cloud analysis via state space model,
X. Han, Y . Tang, Z. Wang, and X. Li, “Mamba3d: Enhancing local features for 3d point cloud analysis via state space model,” inACM International Conference on Multimedia, 2024, pp. 4995–5004
2024
-
[8]
Vmamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, J. Jiao, and Y . Liu, “Vmamba: Visual state space model,” inNeurIPS, 2024
2024
-
[9]
Vision mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,” inInternational Conference on Machine Learning. Open- Review.net, 2024
2024
-
[10]
Vig: Linear- complexity visual sequence learning with gated linear attention,
B. Liao, X. Wang, L. Zhu, Q. Zhang, and C. Huang, “Vig: Linear- complexity visual sequence learning with gated linear attention,” inAAAI Conference on Artificial Intelligence, 2025, pp. 5182–5190
2025
-
[11]
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
B. Peng, D. Goldstein, Q. Anthony, A. Albalak, E. Alcaide, S. Biderman, E. Cheah, X. Du, T. Ferdinan, H. Hou, P. Kazienko, K. K. GV , J. Kocon, B. Koptyra, S. Krishna, R. M. Jr., N. Muennighoff, F. Obeid, A. Saito, G. Song, H. Tu, S. Wozniak, R. Zhang, B. Zhao, Q. Zhao, P. Zhou, J. Zhu, and R. Zhu, “Eagle and finch: RWKV with matrix-valued states and dyna...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Mamba or RWKV: exploring high-quality and high-efficiency segment anything model,
H. Yuan, X. Li, L. Qi, T. Zhang, M. Yang, S. Yan, and C. C. Loy, “Mamba or RWKV: exploring high-quality and high-efficiency segment anything model,”CoRR, vol. abs/2406.19369, 2024
-
[13]
RWKV- CLIP: A robust vision-language representation learner,
T. Gu, K. Yang, X. An, Z. Feng, D. Liu, W. Cai, and J. Deng, “RWKV- CLIP: A robust vision-language representation learner,” inEMNLP, 2024, pp. 4799–4812
2024
-
[14]
Video rwkv:video action recognition based RWKV,
Z. Yin, C. Li, and X. Dong, “Video rwkv:video action recognition based RWKV,”CoRR, vol. abs/2411.05636, 2024
-
[15]
Vision-rwkv: Efficient and scalable visual perception with rwkv-like architectures,
Y . Duan, W. Wang, Z. Chen, X. Zhu, L. Lu, T. Lu, Y . Qiao, H. Li, J. Dai, and W. Wang, “Vision-rwkv: Efficient and scalable visual perception with rwkv-like architectures,” inInternational Conference on Learning Representations, 2025, pp. 1–17. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2025
-
[16]
Pointrwkv: Efficient rwkv-like model for hierarchical point cloud learning,
Q. He, J. Zhang, J. Peng, H. He, X. Li, Y . Wang, and C. Wang, “Pointrwkv: Efficient rwkv-like model for hierarchical point cloud learning,” inAAAI Conference on Artificial Intelligence, 2025, pp. 3410– 3418
2025
-
[17]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2019, pp. 12 697–12 705
2019
-
[18]
V oxnet: A 3d convolutional neural network for real-time object recognition,
D. Maturana and S. A. Scherer, “V oxnet: A 3d convolutional neural network for real-time object recognition,” inIEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2015, pp. 922– 928
2015
-
[19]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inIEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 77–85
2017
-
[20]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space,
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” inNeurIPS, 2017, pp. 5099–5108
2017
-
[21]
Dynamic graph CNN for learning on point clouds,
Y . Wang, Y . Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon, “Dynamic graph CNN for learning on point clouds,”ACM Trans. Graph., vol. 38, no. 5, pp. 146:1–146:12, 2019
2019
-
[22]
Point trans- former,
H. Zhao, L. Jiang, J. Jia, P. H. S. Torr, and V . Koltun, “Point trans- former,” inIEEE International Conference on Computer Vision, 2021, pp. 16 239–16 248
2021
-
[23]
Point transformer V2: grouped vector attention and partition-based pooling,
X. Wu, Y . Lao, L. Jiang, X. Liu, and H. Zhao, “Point transformer V2: grouped vector attention and partition-based pooling,” inNeurIPS, 2022
2022
-
[24]
Point transformer V3: simpler, faster, stronger,
X. Wu, L. Jiang, P. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao, “Point transformer V3: simpler, faster, stronger,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2024, pp. 4840–4851
2024
-
[25]
Point-bert: Pre- training 3d point cloud transformers with masked point modeling,
X. Yu, L. Tang, Y . Rao, T. Huang, J. Zhou, and J. Lu, “Point-bert: Pre- training 3d point cloud transformers with masked point modeling,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 19 291–19 300
2022
-
[26]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inNeurIPS, 2017, pp. 5998–6008
2017
-
[27]
BERT: pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019, pp. 4171–4186
2019
-
[28]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[29]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations, 2021, pp. 1–22
2021
-
[30]
Blackmamba: Mixture of experts for state-space models,
Q. Anthony, Y . Tokpanov, P. Glorioso, and B. Millidge, “Blackmamba: Mixture of experts for state-space models,”CoRR, vol. abs/2402.01771, 2024
-
[31]
Moe- mamba: Efficient selective state space models with mixture of experts,
M. Pi ´oro, K. Ciebiera, K. Kr ´ol, J. Ludziejewski, and S. Jaszczur, “Moe- mamba: Efficient selective state space models with mixture of experts,” CoRR, vol. abs/2401.04081, 2024
-
[32]
Mobilemamba: Lightweight multi-receptive visual mamba network,
H. He, J. Zhang, Y . Cai, H. Chen, X. Hu, Z. Gan, Y . Wang, C. Wang, Y . Wu, and L. Xie, “Mobilemamba: Lightweight multi-receptive visual mamba network,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2025, pp. 4497–4507
2025
-
[33]
Mambaad: Exploring state space models for multi- class unsupervised anomaly detection,
H. He, Y . Bai, J. Zhang, Q. He, H. Chen, Z. Gan, C. Wang, X. Li, G. Tian, and L. Xie, “Mambaad: Exploring state space models for multi- class unsupervised anomaly detection,” inNeurIPS, 2024
2024
-
[34]
Vivim: a video vision mamba for medical video object segmentation,
Y . Yang, Z. Xing, and L. Zhu, “Vivim: a video vision mamba for medical video object segmentation,”CoRR, vol. abs/2401.14168, 2024
-
[35]
Point cloud mamba: Point cloud learning via state space model,
T. Zhang, H. Yuan, L. Qi, J. Zhang, Q. Zhou, S. Ji, S. Yan, and X. Li, “Point cloud mamba: Point cloud learning via state space model,” in AAAI Conference on Artificial Intelligence, vol. 39, no. 10, 2025, pp. 10 121–10 130
2025
-
[36]
Onboard deep lossless and near-lossless predictive coding of hyperspectral images with line-based attention,
D. Valsesia, T. Bianchi, and E. Magli, “Onboard deep lossless and near-lossless predictive coding of hyperspectral images with line-based attention,”IEEE Trans. Geosci. Remote. Sens., vol. 62, pp. 1–14, 2024
2024
-
[37]
Pytorch: An imperative style, high- performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. K ¨opf, E. Z. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high- performance deep learning library,” inNeurIPS, 2019, pp. 8024–8035
2019
-
[38]
L. J. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”CoRR, vol. abs/1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[40]
A point set generation network for 3d object reconstruction from a single image,
H. Fan, H. Su, and L. J. Guibas, “A point set generation network for 3d object reconstruction from a single image,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 2463–2471
2017
-
[41]
Take-a-photo: 3d- to-2d generative pre-training of point cloud models,
Z. Wang, X. Yu, Y . Rao, J. Zhou, and J. Lu, “Take-a-photo: 3d- to-2d generative pre-training of point cloud models,” inIEEE/CVF International Conference on Computer Vision, 2023, pp. 5617–5627
2023
-
[42]
Relation-shape convolutional neural network for point cloud analysis,
Y . Liu, B. Fan, S. Xiang, and C. Pan, “Relation-shape convolutional neural network for point cloud analysis,” inIEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 8895–8904
2019
-
[43]
ShapeNet: An Information-Rich 3D Model Repository
A. X. Chang, T. A. Funkhouser, L. J. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, J. Xiao, L. Yi, and F. Yu, “Shapenet: An information-rich 3d model repository,”CoRR, vol. abs/1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[44]
3d shapenets: A deep representation for volumetric shapes,
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao, “3d shapenets: A deep representation for volumetric shapes,” inIEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 1912–1920
2015
-
[45]
Pointnext: Revisiting pointnet++ with improved training and scaling strategies,
G. Qian, Y . Li, H. Peng, J. Mai, H. Hammoud, M. Elhoseiny, and B. Ghanem, “Pointnext: Revisiting pointnet++ with improved training and scaling strategies,” inNeurIPS, 2022
2022
-
[46]
Rethinking network design and local geometry in point cloud: A simple residual MLP framework,
X. Ma, C. Qin, H. You, H. Ran, and Y . Fu, “Rethinking network design and local geometry in point cloud: A simple residual MLP framework,” inInternational Conference on Learning Representations, 2022, pp. 1– 14
2022
-
[47]
Masked discrimination for self-supervised learning on point clouds,
H. Liu, M. Cai, and Y . J. Lee, “Masked discrimination for self-supervised learning on point clouds,” inComputer Vision - ECCV, vol. 13662, 2022, pp. 657–675
2022
-
[48]
Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data,
M. A. Uy, Q. Pham, B. Hua, D. T. Nguyen, and S. Yeung, “Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data,” inIEEE International Conference on Com- puter Vision. IEEE, 2019, pp. 1588–1597
2019
-
[49]
Unsuper- vised point cloud pre-training via occlusion completion,
H. Wang, Q. Liu, X. Yue, J. Lasenby, and M. J. Kusner, “Unsuper- vised point cloud pre-training via occlusion completion,” inIEEE/CVF International Conference on Computer Vision, 2021, pp. 9762–9772
2021
-
[50]
A scalable active framework for region annotation in 3d shape collections,
L. Yi, V . G. Kim, D. Ceylan, I. Shen, M. Yan, H. Su, C. Lu, Q. Huang, A. Sheffer, and L. J. Guibas, “A scalable active framework for region annotation in 3d shape collections,”ACM Trans. Graph., vol. 35, no. 6, pp. 210:1–210:12, 2016
2016
-
[51]
3d semantic parsing of large-scale indoor spaces,
I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. K. Brilakis, M. Fischer, and S. Savarese, “3d semantic parsing of large-scale indoor spaces,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1534–1543
2016
-
[52]
Gated linear attention transformers with hardware-efficient training,
S. Yang, B. Wang, Y . Shen, R. Panda, and Y . Kim, “Gated linear attention transformers with hardware-efficient training,” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
2024
-
[53]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou, “Training data-efficient image transformers & distillation through attention,” inProceedings of the 38th International Conference on Machine Learning, ICML, ser. Proceedings of Machine Learning Research, vol. 139, 2021, pp. 10 347–10 357
2021
-
[54]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inIEEE/CVF International Conference on Computer Vision. IEEE, 2021, pp. 9992–10 002
2021
-
[55]
Towards large-scale 3d representation learning with multi-dataset point prompt training,
X. Wu, Z. Tian, X. Wen, B. Peng, X. Liu, K. Yu, and H. Zhao, “Towards large-scale 3d representation learning with multi-dataset point prompt training,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. IEEE, 2024, pp. 19 551–19 562
2024
-
[56]
Sonata: Self-supervised learning of reliable point representations,
X. Wu, D. DeTone, D. P. Frost, T. Shen, C. Xie, N. Yang, J. J. Engel, R. A. Newcombe, H. Zhao, and J. Straub, “Sonata: Self-supervised learning of reliable point representations,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. Computer Vision Foundation / IEEE, 2025, pp. 22 193–22 204
2025
-
[57]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. A. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 2432–2443
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.