ActiveMem: Distributed Active Memory for Long-Horizon LLM Reasoning
Pith reviewed 2026-06-27 13:00 UTC · model grok-4.3
The pith
ActiveMem decouples memory management from reasoning so LLM agents can scale long-horizon tasks without context overload.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
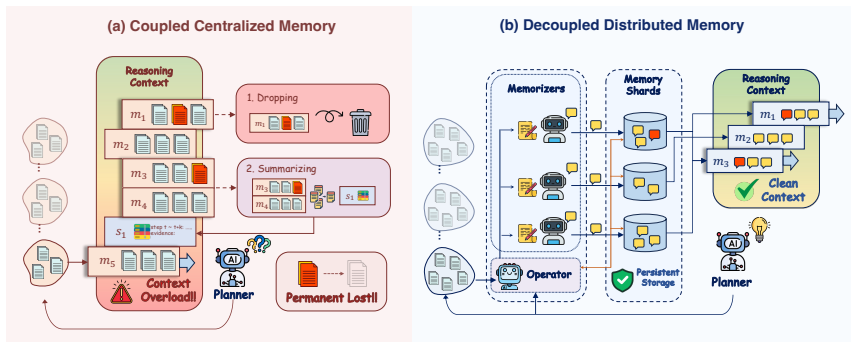
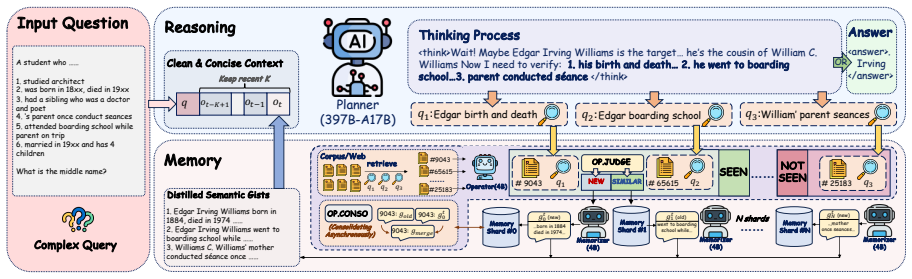
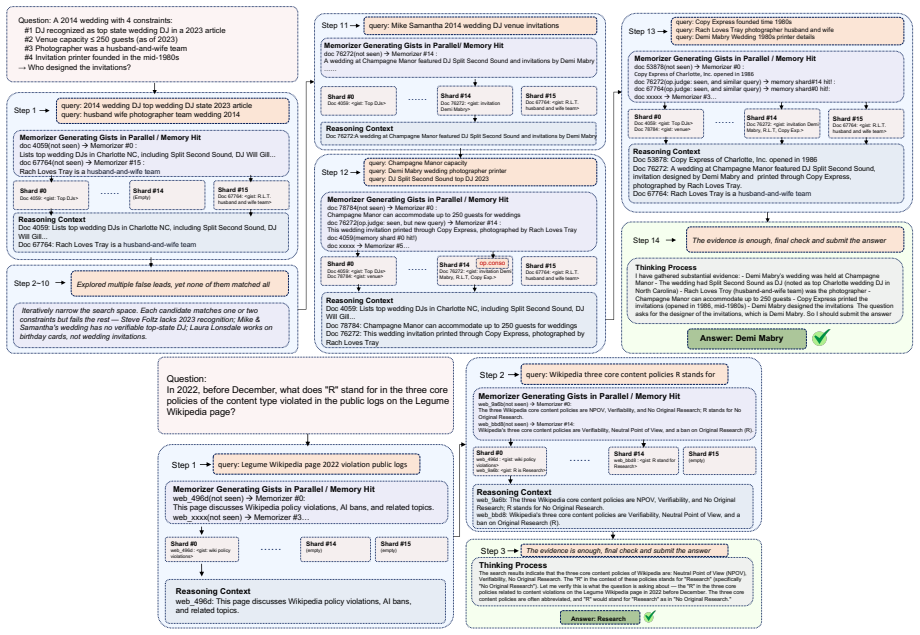
ActiveMem is a heterogeneous framework that decouples agent memory from the core reasoning process. A high-level Planner utilizes distilled semantic gists to execute reasoning, while a lightweight, distributed memory system operates in parallel to actively accumulate and consolidate these gists throughout the task. The design is motivated by the functional complementarity between the prefrontal cortex for executive control and the hippocampus for memory management, showing that centralized organization is not required for reliable long-horizon performance.
What carries the argument
ActiveMem, a heterogeneous framework that separates a Planner operating on distilled semantic gists from a parallel lightweight distributed memory system that accumulates and consolidates those gists.
If this is right
- The Planner can sustain longer reasoning chains because it never receives the full raw history.
- Active accumulation and consolidation of gists can occur without interrupting or overloading the main reasoning loop.
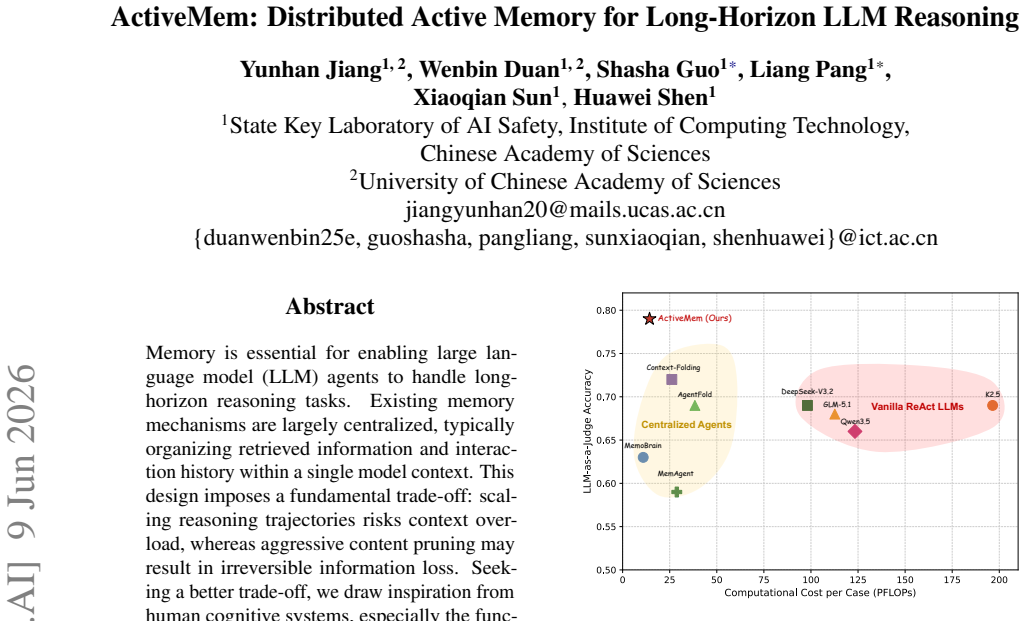
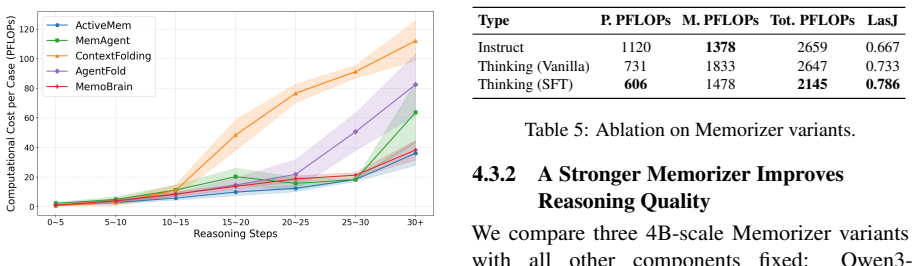
- State-of-the-art accuracy on BrowseComp-Plus and GAIA is achieved together with measurable reductions in computational overhead.
- Irreversible information loss from aggressive pruning inside a single context window is avoided by offloading consolidation to the separate memory layer.
Where Pith is reading between the lines
- The same Planner-plus-distributed-memory split could be tested on tasks that combine tool use with multi-step planning beyond the two reported benchmarks.
- Coordination protocols between Planner and memory layer may need explicit failure-recovery mechanisms if the assumption of reliable gist consolidation does not hold under higher noise.
- Modular separation of memory management from reasoning may generalize to other agent architectures that currently embed everything inside one growing context window.
Load-bearing premise
A lightweight distributed memory system operating in parallel can reliably accumulate and consolidate semantic gists without introducing information loss or coordination failures.
What would settle it
An experiment on BrowseComp-Plus or GAIA in which ActiveMem produces lower accuracy than the reported baselines or shows higher rather than lower overhead would falsify the central effectiveness claim.
Figures
read the original abstract
Memory is essential for enabling large language model (LLM) agents to handle long-horizon reasoning tasks. Existing memory mechanisms are largely centralized, typically organizing retrieved information and interaction history within a single model context. This design imposes a fundamental trade-off: scaling reasoning trajectories risks context overload, whereas aggressive content pruning may result in irreversible information loss. Seeking a better trade-off, we draw inspiration from human cognitive systems, especially the functional complementarity between the prefrontal cortex (executive control) and the hippocampus (memory management), suggesting that such a trade-off need not be inherent, but may instead stem from centralized memory organization. To this end, we propose ActiveMem, a heterogeneous framework that decouples agent memory from the core reasoning process. Specifically, a high-level Planner utilizes distilled semantic gists to execute reasoning, while a lightweight, distributed memory system operates in parallel to actively accumulate and consolidate these gists throughout the task. Experiments on BrowseComp-Plus and GAIA show that ActiveMem achieves state-of-the-art accuracy with significantly reduced overhead, demonstrating the effectiveness of distributed active memory for long-horizon reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ActiveMem, a heterogeneous framework for LLM agents performing long-horizon reasoning. It decouples memory from reasoning by having a high-level Planner operate on distilled semantic gists while a lightweight distributed memory system runs in parallel to accumulate and consolidate those gists. The design draws an analogy to prefrontal cortex and hippocampus complementarity. Experiments on BrowseComp-Plus and GAIA are reported to achieve state-of-the-art accuracy with significantly reduced overhead compared to centralized memory baselines.
Significance. If the empirical claims hold after proper validation, the work could offer a practical path to scaling LLM agent trajectories beyond context-window limits without forced pruning. The distributed active-memory idea is a concrete architectural alternative to monolithic context management and may stimulate follow-up on coordination protocols for gist consolidation.
major comments (2)
- [Abstract] Abstract: the central claim that ActiveMem attains SOTA accuracy via distributed active memory rests on the untested premise that parallel gist accumulation and consolidation incur no irreversible semantic loss or coordination failures; no similarity metric, fidelity invariant, or ablation isolating consolidation quality from planner performance is supplied, so gains cannot be attributed to the heterogeneous design.
- [Abstract] Abstract and Experiments section: no quantitative results, baseline names, statistical tests, error bars, or ablation tables are presented to support the SOTA accuracy and reduced-overhead assertions, rendering the empirical contribution impossible to evaluate from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting gaps in empirical support and attribution. We agree that the submitted manuscript requires substantial additions to the abstract and experiments to make the claims evaluable and to isolate the contribution of the distributed design. We will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ActiveMem attains SOTA accuracy via distributed active memory rests on the untested premise that parallel gist accumulation and consolidation incur no irreversible semantic loss or coordination failures; no similarity metric, fidelity invariant, or ablation isolating consolidation quality from planner performance is supplied, so gains cannot be attributed to the heterogeneous design.
Authors: We agree that the current text does not supply a similarity metric, fidelity invariant, or ablation isolating consolidation quality. In the revision we will add (1) a quantitative semantic similarity metric (cosine similarity over sentence embeddings) between original and consolidated gists, (2) an explicit ablation that disables the distributed consolidation module while keeping the planner fixed, and (3) a short discussion of coordination failure modes and the safeguards already present in the architecture. These additions will allow readers to attribute performance differences more directly to the heterogeneous design. revision: yes
-
Referee: [Abstract] Abstract and Experiments section: no quantitative results, baseline names, statistical tests, error bars, or ablation tables are presented to support the SOTA accuracy and reduced-overhead assertions, rendering the empirical contribution impossible to evaluate from the given text.
Authors: The observation is accurate for the submitted version. We will expand the experiments section with (a) concrete accuracy numbers and overhead measurements on BrowseComp-Plus and GAIA, (b) explicit baseline names and descriptions (centralized memory, standard RAG, etc.), (c) error bars from multiple random seeds, (d) statistical significance tests, and (e) the ablation tables referenced above. The abstract will be updated to reference the key quantitative deltas. These changes will make the empirical contribution directly evaluable. revision: yes
Circularity Check
No circularity detected; derivation is self-contained via design proposal and experiments
full rationale
The paper presents ActiveMem as a proposed heterogeneous framework decoupling a Planner from a parallel distributed memory system, drawing inspiration from human cognition but without any equations, fitted parameters, self-citations, or ansatzes that reduce a claimed result to its own inputs by construction. The central effectiveness claim rests on benchmark experiments (BrowseComp-Plus, GAIA) rather than a mathematical derivation chain. No load-bearing step matches any of the enumerated circularity patterns; the consolidation premise is an unverified design assumption, not a self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chi and Nathanael Sch
Freda Shi and Xinyun Chen and Kanishka Misra and Nathan Scales and David Dohan and Ed H. Chi and Nathanael Sch. Large Language Models Can Be Easily Distracted by Irrelevant Context , booktitle =. 2023 , url =
2023
-
[2]
The Twelfth International Conference on Learning Representations,
Guangxuan Xiao and Yuandong Tian and Beidi Chen and Song Han and Mike Lewis , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[3]
Mosh Levy and Alon Jacoby and Yoav Goldberg , editor =. Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models , booktitle =. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.818 , timestamp =
-
[4]
Make Your
Shengnan An and Zexiong Ma and Zeqi Lin and Nanning Zheng and Jian. Make Your. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
2024
-
[5]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[6]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu and Zujie Liang and Kai Mei and Hang Gao and Juntao Tan and Yongfeng Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.12110 , eprinttype =. 2502.12110 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12110 2025
-
[7]
Mem0: Building Production-Ready
Prateek Chhikara and Dev Khant and Saket Aryan and Taranjeet Singh and Deshraj Yadav , editor =. Mem0: Building Production-Ready. 2025 , url =. doi:10.3233/FAIA251160 , timestamp =
-
[8]
Weiwei Sun and Miao Lu and Zhan Ling and Kang Liu and Xuesong Yao and Yiming Yang and Jiecao Chen , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.11967 , eprinttype =. 2510.11967 , timestamp =
-
[9]
Rui Ye and Zhongwang Zhang and Kuan Li and Huifeng Yin and Zhengwei Tao and Yida Zhao and Liangcai Su and Liwen Zhang and Zile Qiao and Xinyu Wang and Pengjun Xie and Fei Huang and Siheng Chen and Jingren Zhou and Yong Jiang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.24699 , eprinttype =. 2510.24699 , timestamp =
-
[10]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Hongli Yu and Tinghong Chen and Jiangtao Feng and Jiangjie Chen and Weinan Dai and Qiying Yu and Ya. MemAgent: Reshaping Long-Context. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.02259 , eprinttype =. 2507.02259 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.02259 2025
-
[11]
Yaorui Shi and Yuxin Chen and Siyuan Wang and Sihang Li and Hengxing Cai and Qi Gu and Xiang Wang and An Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.23040 , eprinttype =. 2509.23040 , timestamp =
-
[12]
HiAgent: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks with Large Language Model , booktitle =
Mengkang Hu and Tianxing Chen and Qiguang Chen and Yao Mu and Wenqi Shao and Ping Luo , editor =. HiAgent: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks with Large Language Model , booktitle =. 2025 , url =
2025
-
[13]
Hongjin Qian and Zhao Cao and Zheng Liu , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2601.08079 , eprinttype =. 2601.08079 , timestamp =
-
[14]
LEGOMem: Modular Procedural Memory for Multi-agent
Dongge Han and Camille Couturier and Daniel Madrigal D. LEGOMem: Modular Procedural Memory for Multi-agent. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.04851 , eprinttype =. 2510.04851 , timestamp =
-
[15]
MIRIX: Multi-Agent Memory System for LLM-Based Agents
Yu Wang and Xi Chen , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.07957 , eprinttype =. 2507.07957 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.07957 2025
-
[16]
Reiichiro Nakano and Jacob Hilton and Suchir Balaji and Jeff Wu and Long Ouyang and Christina Kim and Christopher Hesse and Shantanu Jain and Vineet Kosaraju and William Saunders and Xu Jiang and Karl Cobbe and Tyna Eloundou and Gretchen Krueger and Kevin Button and Matthew Knight and Benjamin Chess and John Schulman , title =. CoRR , volume =. 2021 , url...
Pith/arXiv arXiv 2021
-
[17]
In-Context Retrieval-Augmented Language Models , journal =
Nelson F. Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title =. Trans. Assoc. Comput. Linguistics , volume =. 2024 , url =. doi:10.1162/TACL\_A\_00638 , timestamp =
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[18]
Frontiers in systems neuroscience , volume=
The role of prefrontal cortex in working memory: a mini review , author=. Frontiers in systems neuroscience , volume=. 2015 , publisher=
2015
-
[19]
Journal of Cognitive Neuroscience , pages=
Hippocampal Reactivation Trades Episodic Detail for Semantic Gist in Human Memory , author=. Journal of Cognitive Neuroscience , pages=. 2026 , publisher=
2026
-
[20]
Dynamic Parallel Tree Search for Efficient
Yifu Ding and Wentao Jiang and Shunyu Liu and Yongcheng Jing and Jinyang Guo and Yingjie Wang and Jing Zhang and Zengmao Wang and Ziwei Liu and Bo Du and Xianglong Liu and Dacheng Tao , editor =. Dynamic Parallel Tree Search for Efficient. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 202...
2025
-
[21]
Jingbo Yang and Bairu Hou and Wei Wei and Yujia Bao and Shiyu Chang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.07915 , eprinttype =. 2603.07915 , timestamp =
-
[22]
Zijian Chen and Xueguang Ma and Shengyao Zhuang and Ping Nie and Kai Zou and Andrew Liu and Joshua Green and Kshama Patel and Ruoxi Meng and Mingyi Su and Sahel Sharifymoghaddam and Yanxi Li and Haoran Hong and Xinyu Shi and Xuye Liu and Nandan Thakur and Crystina Zhang and Luyu Gao and Wenhu Chen and Jimmy Lin , title =. CoRR , volume =. 2025 , url =. do...
-
[23]
Nature communications , volume=
Evidence for holistic episodic recollection via hippocampal pattern completion , author=. Nature communications , volume=. 2015 , publisher=
2015
-
[24]
Kimi K2.5: Visual Agentic Intelligence
Kimi. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.02276 , eprinttype =. 2602.02276 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02276 2026
-
[25]
The Twelfth International Conference on Learning Representations,
Gr. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[26]
GLM-5: from Vibe Coding to Agentic Engineering
GLM , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.15763 , eprinttype =. 2602.15763 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.15763 2026
-
[27]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , journal =. 2025 , url =. doi:10.48550/ARXIV.2512.02556 , eprinttype =. 2512.02556 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.02556 2025
-
[28]
A Survey on the Memory Mechanism of Large Language Model-based Agents , journal =
Zeyu Zhang and Quanyu Dai and Xiaohe Bo and Chen Ma and Rui Li and Xu Chen and Jieming Zhu and Zhenhua Dong and Ji. A Survey on the Memory Mechanism of Large Language Model-based Agents , journal =. 2025 , url =. doi:10.1145/3748302 , timestamp =
-
[29]
A survey on large language model based autonomous agents , volume=
Lei Wang and Chen Ma and Xueyang Feng and Zeyu Zhang and Hao Yang and Jingsen Zhang and Zhiyuan Chen and Jiakai Tang and Xu Chen and Yankai Lin and Wayne Xin Zhao and Zhewei Wei and Jirong Wen , title =. Frontiers Comput. Sci. , volume =. 2024 , url =. doi:10.1007/S11704-024-40231-1 , timestamp =
-
[30]
Hinton and Oriol Vinyals and Jeffrey Dean , title =
Geoffrey E. Hinton and Oriol Vinyals and Jeffrey Dean , title =. CoRR , volume =. 2015 , url =. 1503.02531 , timestamp =
Pith/arXiv arXiv 2015
-
[31]
Memory in the Age of AI Agents
Yuyang Hu and Shichun Liu and Yanwei Yue and Guibin Zhang and Boyang Liu and Fangyi Zhu and Jiahang Lin and Honglin Guo and Shihan Dou and Zhiheng Xi and Senjie Jin and Jiejun Tan and Yanbin Yin and Jiongnan Liu and Zeyu Zhang and Zhongxiang Sun and Yutao Zhu and Hao Sun and Boci Peng and Zhenrong Cheng and Xuanbo Fan and Jiaxin Guo and Xinlei Yu and Zhen...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.13564 2025
-
[32]
A Survey of Context Engineering for Large Language Models
Lingrui Mei and Jiayu Yao and Yuyao Ge and Yiwei Wang and Baolong Bi and Yujun Cai and Jiazhi Liu and Mingyu Li and Zhong. A Survey of Context Engineering for Large Language Models , journal =. 2025 , url =. doi:10.48550/ARXIV.2507.13334 , eprinttype =. 2507.13334 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.13334 2025
-
[33]
MemGPT: Towards LLMs as Operating Systems
Charles Packer and Vivian Fang and Shishir G. Patil and Kevin Lin and Sarah Wooders and Joseph E. Gonzalez , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.08560 , eprinttype =. 2310.08560 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[34]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong and Lianghong Guo and Qiqi Gao and He Ye and Yanlin Wang , title =. Thirty-Eighth. 2024 , url =. doi:10.1609/AAAI.V38I17.29946 , timestamp =
-
[35]
Qwen3 Technical Report , journal =. 2025 , url =. doi:10.48550/ARXIV.2505.09388 , eprinttype =. 2505.09388 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[36]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2408.03314 , eprinttype =. 2408.03314 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03314 2024
-
[37]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zijian Zhou and Ao Qu and Zhaoxuan Wu and Sunghwan Kim and Alok Prakash and Daniela Rus and Jinhua Zhao and Bryan Kian Hsiang Low and Paul Pu Liang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.15841 , eprinttype =. 2506.15841 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.15841 2025
-
[38]
Xixi Wu and Kuan Li and Yida Zhao and Liwen Zhang and Litu Ou and Huifeng Yin and Zhongwang Zhang and Yong Jiang and Pengjun Xie and Fei Huang and Minhao Cheng and Shuai Wang and Hong Cheng and Jingren Zhou , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.13313 , eprinttype =. 2509.13313 , timestamp =
-
[39]
Sikuan Yan and Xiufeng Yang and Zuchao Huang and Ercong Nie and Zifeng Ding and Zonggen Li and Xiaowen Ma and Hinrich Sch. Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2508.19828 , eprinttype =. 2508.19828 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.19828 2025
-
[40]
Mem-{\alpha}: Learning Memory Construction via Reinforcement Learning
Yu Wang and Ryuichi Takanobu and Zhiqi Liang and Yuzhen Mao and Yuanzhe Hu and Julian J. McAuley and Xiaojian Wu , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.25911 , eprinttype =. 2509.25911 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.25911 2025
-
[41]
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Yuxiang Zhang and Jiangming Shu and Ye Ma and Xueyuan Lin and Shangxi Wu and Jitao Sang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.12635 , eprinttype =. 2510.12635 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.12635 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.