Audio-Visual Exchange-Aware Token Pruning for Efficient Audio-Visual Captioning
Pith reviewed 2026-06-27 13:52 UTC · model grok-4.3
The pith
AVEX-Prune uses token swaps between audio and visual modalities to select valuable tokens and keep full caption quality at 40 percent retention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
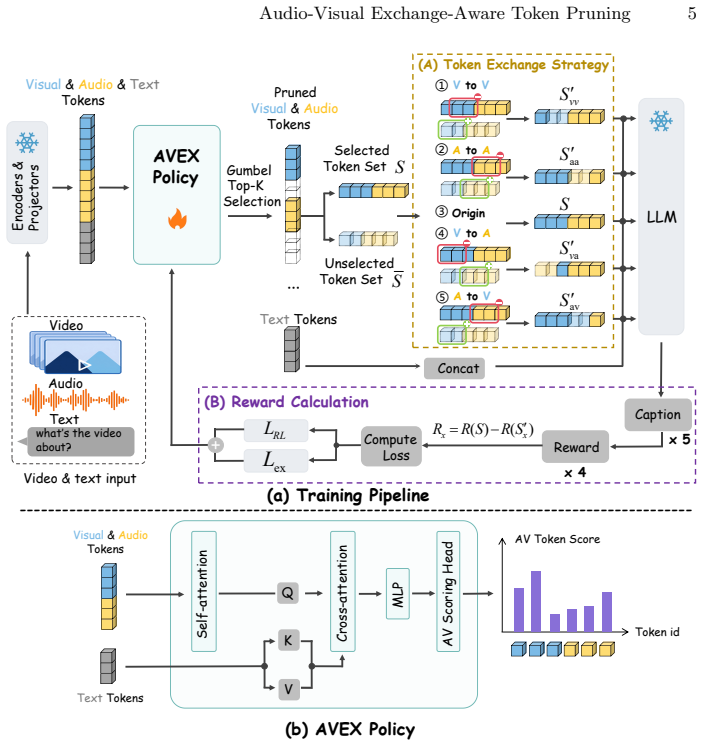
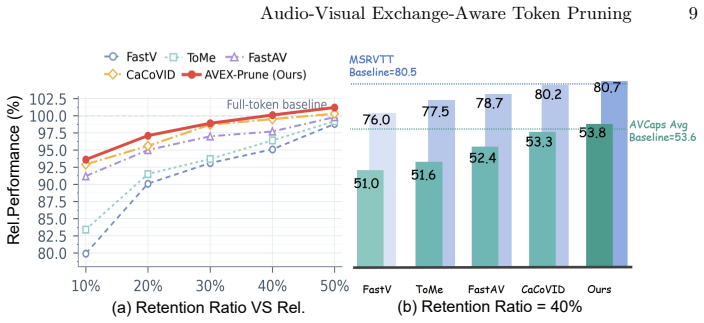
AVEX-Prune preserves full-token quality at a 40% retention ratio on both VILA 1.5-8B (54.5 vs. 54.6) and VideoLLaMA 2 (57.0 vs. 56.8) by using an audio-visual token exchange strategy that replaces low-confidence retained tokens with high-confidence candidate tokens from the same or the other modality and measures the differences in caption generation from those swaps.
What carries the argument
The audio-visual token exchange strategy that measures caption-generation differences after token swaps to identify and retain truly valuable tokens.
If this is right
- Dynamic token budgets can be set at inference time without retraining the underlying captioning model.
- Cross-modality swaps allow pruning decisions to draw evidence from both audio and visual streams simultaneously.
- The same exchange logic can be applied at different retention ratios while maintaining the quality parity shown at 40 percent.
Where Pith is reading between the lines
- The method may lower memory and compute costs for real-time audio-visual applications on edge devices.
- Similar exchange-based selection could be tested on pure video or pure audio tasks to check whether the cross-modal component is essential.
- Extending the RL reward to include latency or energy measurements would make the pruning directly optimize for deployment constraints.
Load-bearing premise
Measuring caption differences after swapping low- and high-confidence tokens can reliably identify which tokens matter even when they sit near the decision boundary.
What would settle it
A measurable drop in caption quality on a held-out multimodal model or longer video set when the exchange step is removed or when the RL policy is trained without the swap signal.
Figures

read the original abstract
Audio-visual captioning generates natural language descriptions from video and audio content. Multimodal LLMs have advanced this task, but both modalities contribute many tokens to the LLM input, where prefill self-attention scales quadratically. Existing token-pruning methods usually retain tokens by attention, saliency, or cross-entropy loss, yet the hard threshold selection makes it difficult to retain tokens that are truly valuable, especially for high-confusing tokens near the decision boundary. To this end, we propose a AVEX-Prune, an RL-based audio-visual dynamic token pruning method in this work. In our AVEX-Prune, an audio-visual token exchange strategy is proposed to select truly valuable tokens by replacing low-confidence retained tokens with high-confidence candidate tokens from the same or the other modality, and measuring the differences in caption generation from token swaps. AVEX-Prune preserves full-token quality at a 40% retention ratio on both VILA 1.5-8B (54.5 vs. 54.6) and VideoLLaMA 2 (57.0 vs. 56.8).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AVEX-Prune, an RL-based dynamic token pruning method for audio-visual captioning in multimodal LLMs. It introduces an audio-visual token exchange strategy that replaces low-confidence retained tokens with high-confidence candidates (same or cross-modality) and uses resulting differences in generated captions as the value signal to drive token selection. The central empirical claim is that this preserves full-token quality at a 40% retention ratio, with scores of 54.5 vs. 54.6 on VILA 1.5-8B and 57.0 vs. 56.8 on VideoLLaMA 2.
Significance. If the token-exchange signal reliably identifies valuable tokens, the approach would address a practical scalability bottleneck in audio-visual LLMs by cutting quadratic self-attention cost by 60% with negligible quality loss; this would be a useful engineering contribution for efficient multimodal inference.
major comments (2)
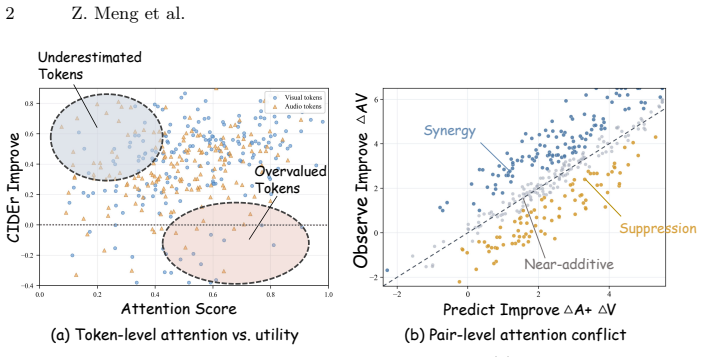
- [Abstract] Abstract: only two performance numbers are supplied with no experimental protocol, baseline comparisons, statistical significance tests, or ablation details, so it is impossible to verify whether the reported near-parity supports the claim that the exchange strategy correctly selects the retained 40% subset.
- [Method (AVEX-Prune)] Method description of the audio-visual exchange strategy: the caption-difference signal after a single token swap is asserted to identify truly valuable tokens even near decision boundaries, but no analysis is given showing that the metric difference exceeds generation stochasticity or is monotonic with token utility; if sampling variance dominates, the RL policy would retain an arbitrary subset and the observed scores would not demonstrate correct selection.
minor comments (1)
- [Abstract] The phrase 'high-confusing tokens' is nonstandard and should be replaced with a clearer term such as 'high-uncertainty tokens' or 'tokens near the decision boundary'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and commit to revisions that strengthen the presentation of our method and results.
read point-by-point responses
-
Referee: [Abstract] Abstract: only two performance numbers are supplied with no experimental protocol, baseline comparisons, statistical significance tests, or ablation details, so it is impossible to verify whether the reported near-parity supports the claim that the exchange strategy correctly selects the retained 40% subset.
Authors: We agree that the abstract, due to length constraints, provides insufficient context. In the revised version we will expand the abstract to briefly describe the experimental protocol, list the main baselines, note the retention ratio, and reference the key ablation results that support the near-parity claim. revision: yes
-
Referee: [Method (AVEX-Prune)] Method description of the audio-visual exchange strategy: the caption-difference signal after a single token swap is asserted to identify truly valuable tokens even near decision boundaries, but no analysis is given showing that the metric difference exceeds generation stochasticity or is monotonic with token utility; if sampling variance dominates, the RL policy would retain an arbitrary subset and the observed scores would not demonstrate correct selection.
Authors: We acknowledge that the current manuscript does not contain explicit analysis quantifying how the caption-difference signal compares to sampling variance or its monotonicity with token utility. In the revision we will add controlled experiments that (i) measure signal magnitude across repeated generations with different seeds and (ii) correlate the signal with downstream caption quality when tokens are ranked by utility, thereby demonstrating that the RL policy is driven by a reliable rather than arbitrary signal. revision: yes
Circularity Check
No circularity; empirical method with external validation
full rationale
The paper describes an RL-based token pruning method (AVEX-Prune) that uses an audio-visual exchange strategy to measure caption differences after token swaps, then reports direct experimental outcomes on VILA 1.5-8B and VideoLLaMA 2 (e.g., 54.5 vs. 54.6 at 40% retention). No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear. The performance numbers are external benchmark comparisons, not quantities defined in terms of the method's own outputs. The derivation chain is self-contained against the reported evaluations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
EMNLP System Demonstrations, 543–553 (2023)
Zhang, H., Li, X., Bing, L.: Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. EMNLP System Demonstrations, 543–553 (2023)
2023
-
[2]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Cheng, Z., Leng, S., Zhang, H., et al.: VideoLLaMA 2: Advancing spatial-temporal modeling and audio understanding in video-LLMs. arXiv:2406.07476 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
CVPR, 26689–26699 (2024)
Lin, J., Yin, H., Ping, W., Molchanov, P., Shoeybi, M., Han, S.: VILA: On pre- training for visual language models. CVPR, 26689–26699 (2024)
2024
-
[4]
ECCV, 19–35 (2024)
Chen, L., Zhao, H., Liu, T., et al.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for VLMs. ECCV, 19–35 (2024)
2024
-
[5]
ICML (2025)
Zhang, Y., Fan, C.-K., Ma, J., et al.: SparseVLM: Visual token sparsification for efficient vision-language model inference. ICML (2025)
2025
-
[6]
EMNLP, 20503–20518 (2024)
Guo, Z., Kamigaito, H., Watanabe, T.: Attention score is not all you need for token importance in KV cache reduction. EMNLP, 20503–20518 (2024)
2024
-
[7]
ICLR (2023)
Bolya, D., Fu, C.-Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your ViT but faster. ICLR (2023)
2023
-
[8]
Findings of ACL, 19959–19973 (2025)
Huang, X., Zhou, H., Han, K.: PruneVid: Visual token pruning for efficient video large language models. Findings of ACL, 19959–19973 (2025)
2025
-
[9]
NeurIPS (2025)
Shao, K., Tao, K., Qin, C., You, H., Sui, Y., Wang, H.: HoliTom: Holistic token merging for fast video large language models. NeurIPS (2025)
2025
-
[10]
AAAI (2026)
Ma, Y., Zhou, Q., Wang, Z., et al.: Contribution-aware token compression for efficient video understanding via reinforcement learning. AAAI (2026)
2026
-
[11]
CVPR, 15710–15719 (2024)
Cao, J., Ye, P., Li, S., et al.: MADTP: Multimodal alignment-guided dynamic token pruning for VLM acceleration. CVPR, 15710–15719 (2024)
2024
-
[12]
Findings of ACL, 20724–20735 (2025)
Yeo, J.H., Rha, H., Park, S.J., Ro, Y.M.: MMS-LLaMA: Efficient audio-visual speech recognition with minimal multimodal speech tokens. Findings of ACL, 20724–20735 (2025)
2025
-
[13]
ICML, 5178–5193 (2023)
Chen, S., Wu, Y., Wang, C., et al.: BEATs: Audio pre-training with acoustic tokenizers. ICML, 5178–5193 (2023)
2023
-
[14]
CVPR, 5288–5296 (2016)
Xu, J., Mei, T., Yao, T., Rui, Y.: MSR-VTT: A large video description dataset for bridging video and language. CVPR, 5288–5296 (2016)
2016
-
[15]
IEEE OJSP, 6:691–704 (2025)
Sudarsanam, P., Martin-Morato, I., Hakala, A., Virtanen, T.: AVCaps: An audio- visual dataset with modality-specific captions. IEEE OJSP, 6:691–704 (2025)
2025
-
[16]
ICASSP (2026)
Jung, C., Jang, Y., Lee, S., Chung, J.S.: FastAV: Efficient token pruning for audio-visual large language model inference. ICASSP (2026)
2026
-
[17]
ICCV (2025)
Zhong, Y., Dou, Z.-Y., Yang, J., et al.: AIM: Adaptive inference of multi-modal LLMs via token merging and pruning. ICCV (2025)
2025
-
[18]
Yang, A., Yang, B., Hui, B., et al.: Qwen2 technical report. arXiv:2407.10671 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
CVPR, 4566–4575 (2015)
Vedantam, R., Zitnick, C.L., Parikh, D.: CIDEr: Consensus-based image description evaluation. CVPR, 4566–4575 (2015)
2015
-
[20]
ICCV, 11975–11986 (2023)
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. ICCV, 11975–11986 (2023)
2023
-
[21]
CVPR, 26574–26585 (2024)
Han, J., Gong, K., Zhang, Y., et al.: OneLLM: One framework to align all modalities with language. CVPR, 26574–26585 (2024)
2024
-
[22]
Shu, F., Zhang, L., Jiang, H., Xie, C.: Audio-visual LLM for video understanding. arXiv:2312.06720 (2023)
-
[23]
TLLM Workshop (2023) 12 Z
Su, Y., Lan, T., Li, H., Xu, J., Wang, Y., Cai, D.: PandaGPT: One model to instruction-follow them all. TLLM Workshop (2023) 12 Z. Meng et al
2023
-
[24]
Lyu, C., Wu, M., Wang, L., et al.: Macaw-LLM: Multi-modal language modeling with image, audio, video, and text integration. arXiv:2306.09093 (2023)
-
[25]
LLaVA-VL Blog (2024)
Liu, H., Li, B., Zhang, Y., et al.: LLaVA-NeXT: A strong zero-shot video under- standing model. LLaVA-VL Blog (2024)
2024
-
[26]
EMNLP, 9769–9786 (2024)
Zhang, L., Zhao, T., Ying, H., et al.: OmAgent: A multi-modal agent framework for complex video understanding. EMNLP, 9769–9786 (2024)
2024
-
[27]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-LLaVA: Learning united visual representation by alignment before projection. arXiv:2311.10122 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
VideoChat: Chat-Centric Video Understanding
Lin, B., Zhu, B., Ye, Y., Ning, M., Jin, P., Yuan, L.: VideoChat: Chat-centric video understanding. arXiv:2305.06355 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
ACL, 12585–12602 (2024)
Maaz, M., Rasheed, H., Khan, S., Khan, F.S.: Video-ChatGPT: Towards detailed video understanding via large vision and language models. ACL, 12585–12602 (2024)
2024
-
[30]
CVPR, 13040–13051 (2024)
Ye, Q., Xu, H., Ye, J., Yan, M., Zhou, H., Huang, F.: mPLUG-Owl2: Revolutionizing multi-modal large language model with modality collaboration. CVPR, 13040–13051 (2024)
2024
-
[31]
NeurIPS (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. NeurIPS (2023)
2023
-
[32]
NeurIPS (2022)
Alayrac, J.-B., Donahue, J., Luc, P., et al.: Flamingo: A visual language model for few-shot learning. NeurIPS (2022)
2022
-
[33]
ICML, 19730–19742 (2023)
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. ICML, 19730–19742 (2023)
2023
-
[34]
NeurIPS (2023)
Dai, W., Li, J., Li, D., et al.: InstructBLIP: Towards general-purpose vision-language models with instruction tuning. NeurIPS (2023)
2023
-
[35]
CVPR, 10714–10726 (2023)
Yang, A., Nagrani, A., Seo, P.H., et al.: Vid2Seq: Large-scale pretraining of a visual language model for dense video captioning. CVPR, 10714–10726 (2023)
2023
-
[36]
TMLR (2022)
Wang, J., Yang, Z., Hu, X., et al.: GIT: A generative image-to-text transformer for vision and language. TMLR (2022)
2022
-
[37]
ICML, 8748–8763 (2021)
Radford, A., Kim, J.W., Hallacy, C., et al.: Learning transferable visual models from natural language supervision. ICML, 8748–8763 (2021)
2021
-
[38]
Ryoo, M.S., Piergiovanni, A., Arnab, A., Dehghani, M., Angelova, A.: TokenLearner: What can 8 learned tokens do for images and videos? NeurIPS (2021)
2021
-
[39]
NeurIPS (2021)
Rao, Y., Zhao, W., Liu, B., Lu, J., Zhou, J., Hsieh, C.-J.: DynamicViT: Efficient vision transformers with dynamic token sparsification. NeurIPS (2021)
2021
-
[40]
ICLR (2022)
Liang, Y., Ge, C., Tong, Z., Song, Y., Wang, J., Xie, P.: EViT: Expediting vision transformers via token reorganizations. ICLR (2022)
2022
-
[41]
ICCV, 5455–5465 (2023)
Li, K., Wang, Y., He, Y., et al.: UniFormerV2: Spatiotemporal learning by arming image ViTs with video UniFormer. ICCV, 5455–5465 (2023)
2023
-
[42]
arXiv preprint arXiv:2306.07207 , year=
Luo, R., Zhao, Z., Yang, M., et al.: Valley: Video assistant with large language model enhanced ability. arXiv:2306.07207 (2023)
-
[43]
CVPR, 15180–15190 (2023)
Girdhar, R., El-Nouby, A., Liu, Z., et al.: ImageBind: One embedding space to bind them all. CVPR, 15180–15190 (2023)
2023
-
[44]
ACM Multimedia (2024)
Ye, C., Chen, W., Li, J., Zhang, L., Mao, Z.: Dual-path collaborative generation network for emotional video captioning. ACM Multimedia (2024)
2024
-
[45]
See Different, Think Better: Visual Variations Mitigating Hallucinations in LVLMs , url=
Ye, C., Chen, W., Song, P., Liu, X., Zhang, L., Mao, Z.: Multi-round mutual emotion- cause pair extraction for emotion-attributed video captioning. ACM Multimedia (2025). doi:10.1145/3746027.3755048
-
[46]
IEEE Trans- actions on Image Processing 35, 540–555 (2026) Audio-Visual Exchange-Aware Token Pruning 13
Chen, W., Ye, C., Song, P., Zhang, L., Zhang, Y., Mao, Z.: Subjective-objective emotion-correlated generation network for subjective video captioning. IEEE Trans- actions on Image Processing 35, 540–555 (2026) Audio-Visual Exchange-Aware Token Pruning 13
2026
-
[47]
IEEE Transactions on Image Processing 34, 5369–5384 (2025)
Ye, C., Chen, W., Hu, B., Zhang, L., Zhang, Y., Mao, Z.: Improving video sum- marization by exploring the coherence between corresponding captions. IEEE Transactions on Image Processing 34, 5369–5384 (2025)
2025
-
[48]
IEEE Transactions on Multimedia 27, 6740–6751 (2025)
Song, P., Zhang, L., Lan, L., Chen, W., Guo, D., Yang, X., Wang, M.: Towards efficient partially relevant video retrieval with active moment discovering. IEEE Transactions on Multimedia 27, 6740–6751 (2025)
2025
-
[49]
Qin, X., Hong, D., Chen, W., Ye, C., Liu, X., Song, P., Zhang, L.: Query-based col- laborative multimodal token pruning for audio-visual question answering. AIHCIR (2025). doi:10.1109/AIHCIR67580.2025.11405267
-
[50]
ACM Trans
Li, J., Mao, Z., Li, H., Chen, W., Zhang, Y.: Exploring visual relationships via transformer-based graphs for enhanced image captioning. ACM Trans. Multim. Comput. Commun. Appl. 20(5), 133:1–133:23 (2024)
2024
-
[51]
ACM Trans
Fu, F., Fang, S., Chen, W., Mao, Z.: Sentiment-oriented transformer-based vari- ational autoencoder network for live video commenting. ACM Trans. Multim. Comput. Commun. Appl. 20(4), 104:1–104:24 (2024)
2024
-
[52]
ICASSP, 2215–2219 (2024)
Jin, Y., Chen, W., Tian, Y., Song, Y., Yan, C., Mao, Z.: Improving radiology report generation with D 2-Net: When diffusion meets discriminator. ICASSP, 2215–2219 (2024)
2024
-
[53]
AAAI (2024)
Liu, C., Tian, Y., Chen, W., Song, Y., Zhang, Y.: Bootstrapping large language models for radiology report generation. AAAI (2024)
2024
-
[54]
SIGIR, 833–843 (2025)
Li, Z., Zhang, L., Zhang, K., Chen, W., Zhang, Y., Mao, Z.: Rethinking pseudo word learning in zero-shot composed image retrieval: From an object-aware perspective. SIGIR, 833–843 (2025)
2025
-
[55]
EmoVerse: A MLLMs-Driven Emotion Representation Dataset for Interpretable Visual Emotion Analysis
Guo, Y., Hong, D., Chen, W., She, Z., Ye, C., Chang, X., Mao, Z.: EmoVerse: A MLLMs-driven emotion representation dataset for interpretable visual emotion analysis. arXiv:2511.12554 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Wang, L., Ye, C., Chen, W., Song, P., Hu, B., Mao, Z.: A multi-agent framework with structured reasoning and reflective refinement for multimodal empathetic response generation. arXiv:2604.18988 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
ICLR (2026)
Zhang, H., Hong, D., Yang, M., Cheng, Y., Zhang, Z., Chen, W., Shao, J., Wu, X., Wu, Z., Jiang, Y.-G.: CreatiDesign: A unified multi-conditional diffusion transformer for creative graphic design. ICLR (2026)
2026
-
[58]
CreatiParser: Generative Image Parsing of Raster Graphic Designs into Editable Layers
Chen, W., Hong, D., Mao, Z., Cheng, Y., Liu, X., Zhang, L., Zhang, Y.: Creati- Parser: Generative image parsing of raster graphic designs into editable layers. arXiv:2604.19632 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
ACM Multimedia, 4053–4062 (2021)
Chen, W., Li, G., Zhang, X., Yu, H., Wang, S., Huang, Q.: Cascade cross-modal attention network for video actor and action segmentation from a sentence. ACM Multimedia, 4053–4062 (2021)
2021
-
[60]
ACM Trans
Chen, W., Li, G., Zhang, X., Wang, S., Li, L., Huang, Q.: Weakly supervised text-based actor-action video segmentation by clip-level multi-instance learning. ACM Trans. Multim. Comput. Commun. Appl. 19(1), 1–21 (2022)
2022
-
[61]
ACM Multimedia (2022)
Chen, W., Hong, D., Qi, Y., Han, Z., Wang, S., Qing, L., Huang, Q., Li, G.: Multi-attention network for compressed video referring object segmentation. ACM Multimedia (2022)
2022
-
[62]
AAAI, 17476– 17484 (2025)
Huang, X., Chen, W., Hu, B., Mao, Z.: Graph mixture of experts and memory- augmented routers for multivariate time series anomaly detection. AAAI, 17476– 17484 (2025)
2025
-
[63]
Findings of NAACL, 3730– 3740 (2024) 14 Z
Lin, Z., Chen, W., Song, Y., Zhang, Y.: Prompting few-shot multi-hop question generation via comprehending type-aware semantics. Findings of NAACL, 3730– 3740 (2024) 14 Z. Meng et al
2024
-
[64]
EMNLP, 10031–10045 (2023)
Wang, T., Chen, W., Tian, Y., Song, Y., Mao, Z.: Improving image captioning via predicting structured concepts. EMNLP, 10031–10045 (2023)
2023
-
[65]
ACL, 7809–7824 (2023)
Han, J., Wang, Q., Zhang, L., Chen, W., Song, Y., Mao, Z.: Text style transfer with contrastive transfer pattern mining. ACL, 7809–7824 (2023)
2023
-
[66]
Neurocomputing 600, 128122 (2024)
Jin, Y., Chen, W., Tian, Y., Song, Y., Yan, C.: Improving radiology report generation with multi-grained abnormality prediction. Neurocomputing 600, 128122 (2024)
2024
-
[67]
Findings of ACL, 13597–13609 (2023)
Tian, Y., Chen, W., Hu, B., Song, Y., Xia, F.: End-to-end aspect-based sentiment analysis with combinatory categorial grammar. Findings of ACL, 13597–13609 (2023)
2023
-
[68]
ACM Multimedia, 14229–14235 (2025)
Wang, C., Chen, W., Cui, X., Zhao, Y., Qi, Z., Huang, P., Liu, X., Zhang, W.: Combatting data imbalance and noise in micro-action recognition. ACM Multimedia, 14229–14235 (2025)
2025
-
[69]
ICANN, 180–191 (2023)
Wang, T., Chen, W., Li, J., Peng, Y., Mao, Z.: Contour-augmented concept predic- tion network for image captioning. ICANN, 180–191 (2023)
2023
-
[70]
ICASSP (2026)
Zhang, Z., Song, P., Hu, J., Chen, W., Ni, L., Yang, X.: Stimuli-aware emotion adaptor for enhancing LLM in affective explanation captioning. ICASSP (2026)
2026
-
[71]
Chen, W., Ye, C., Mao, Z., Song, P., Liu, X., Zhang, L., Chang, X., Zhang, Y.: FACE-net: Factual calibration and emotion augmentation for retrieval-enhanced emotional video captioning. arXiv:2603.17455 (2026)
-
[72]
AIHCIR (2025)
Zhou, Q., Yao, J., Tang, S., Chen, W., Cheng, L., Tang, J.: Hierarchical knowledge distillation for cross-lingual stance detection. AIHCIR (2025)
2025
-
[73]
UAV Multimedia Workshop, 25–33 (2025)
Liu, X., Chen, W., Qi, Z., Zhang, B., Zhang, W.: Matching street view and satellite images via drone imagery and semantic descriptions. UAV Multimedia Workshop, 25–33 (2025)
2025
-
[74]
ICME, 276–281 (2023)
Zhao, B., Chen, W., Hu, B., Xie, H., Mao, Z.: Difference-aware iterative reasoning network for key relation detection. ICME, 276–281 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.