Prefilling-dLLM: Predictive Prefilling for Long-Context Inference in Diffusion Language Models
Pith reviewed 2026-06-27 13:28 UTC · model grok-4.3
The pith
Diffusion language models can use cached chunk KV states and top-K selection to make long-context denoising quadratic only in decode length while outperforming dense attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
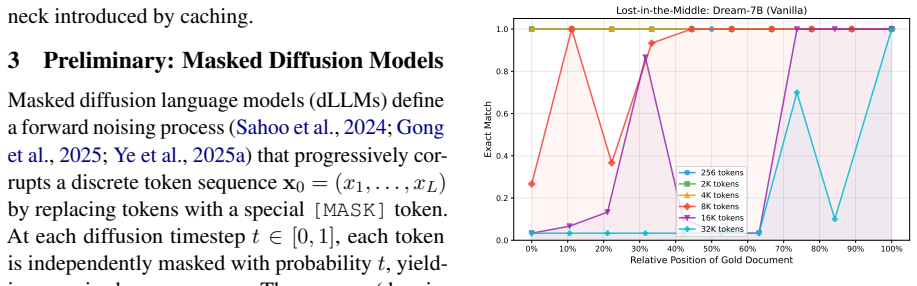
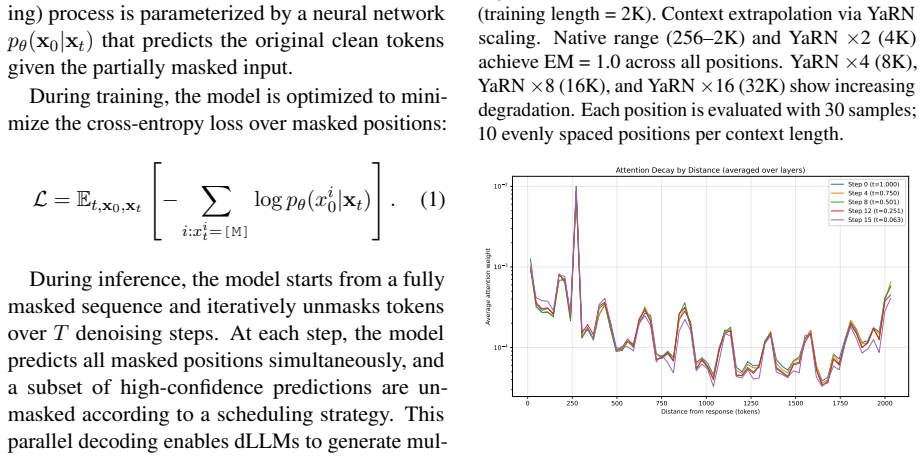
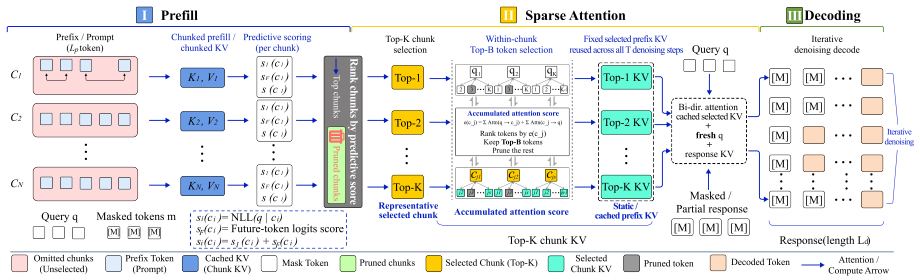
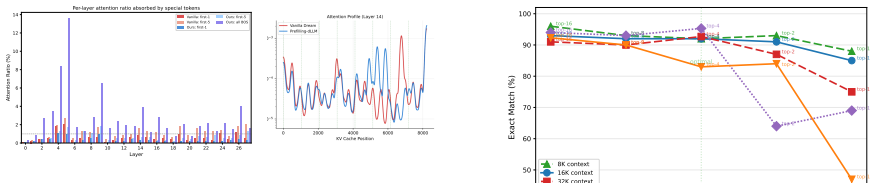
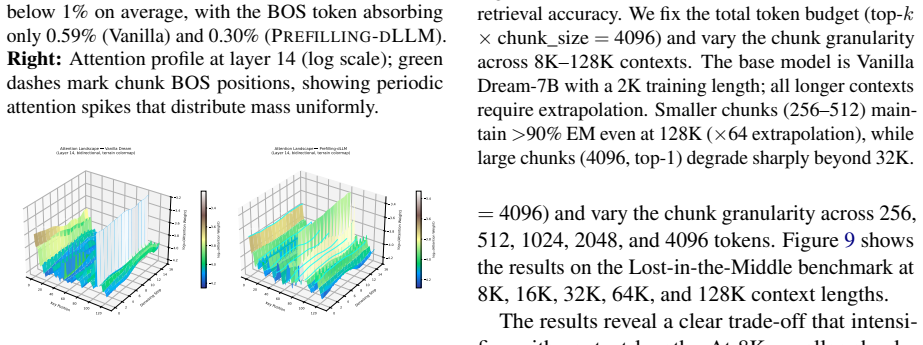
Prefilling-dLLM is a training-free prefill-decode disaggregation framework for dLLMs that partitions the prefix into N chunks, caches their KV representations once, and selects the top-K most relevant chunks with intra-chunk token sparsity for decoding. This shows that sparse prefilling can outperform dense attention while reducing per-step complexity from quadratic in the full sequence length to quadratic only in the decode length. Beginning-of-sequence tokens prepended to each chunk act as periodic attention anchors that eliminate the lost-in-the-middle phenomenon.
What carries the argument
Prefill-decode disaggregation via chunked KV caching and top-K selection with intra-chunk sparsity, augmented by periodic BOS anchors.
Load-bearing premise
The top-K chunk selection plus periodic BOS anchors preserve all information required for accurate denoising at every step without introducing new errors that dense attention would have avoided.
What would settle it
If the Prefilling-dLLM method produces lower accuracy than full dense attention on the same dLLM for tasks in InfiniteBench, that would falsify the claim that sparse prefilling outperforms dense attention.
Figures
read the original abstract
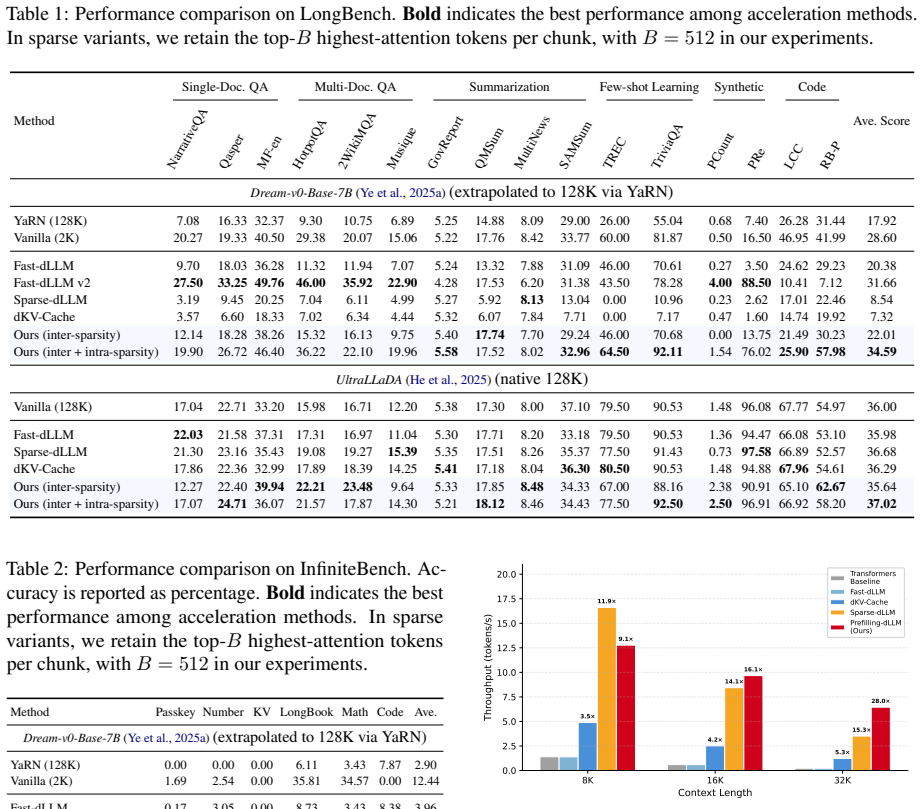
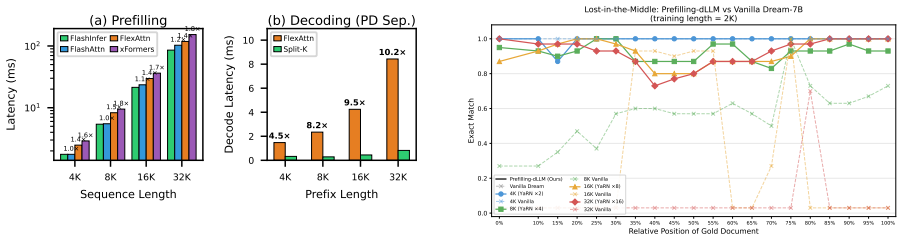
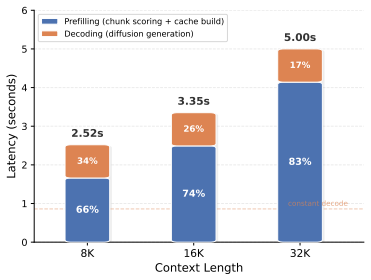
Diffusion large language models (dLLMs) re-encode the entire prefix at every denoising step, causing recomputation that scales quadratically with context length and becomes prohibitive for long-context scenarios. We propose Prefilling-dLLM, a training-free prefill-decode disaggregation framework for dLLMs that partitions the prefix into N chunks, caches their KV representations once, and selects the top-K most relevant chunks with intra-chunk token sparsity for decoding, showing that sparse prefilling can outperform dense attention while reducing per-step complexity from quadratic in the full sequence length to quadratic only in the decode length. On LongBench and InfiniteBench, Prefilling-dLLM achieves state-of-the-art quality among dLLM acceleration methods, and an attention kernel that parallelizes decoding over the non-contiguously cached chunk KV yields 9.1--28.0x speedup at 8K--32K contexts. We further show that beginning-of-sequence tokens prepended to each chunk act as periodic attention anchors that eliminate the lost-in-the-middle phenomenon. Code is available at https://github.com/menik1126/Prefilling-dLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents Prefilling-dLLM, a training-free prefill-decode disaggregation framework for diffusion language models. It partitions long prefixes into N chunks, caches their KV representations once, selects the top-K most relevant chunks using a relevance metric with intra-chunk sparsity, and prepends BOS tokens to each chunk as periodic anchors. The method claims to reduce per-step attention complexity from quadratic in full sequence length to quadratic only in decode length, while achieving SOTA quality among dLLM acceleration methods on LongBench and InfiniteBench and delivering 9.1-28x speedups at 8K-32K contexts via a parallel attention kernel over non-contiguous cached chunks. Code is released at the cited GitHub repository.
Significance. If the empirical claims are substantiated, the work would offer a practical, training-free route to scalable long-context inference in dLLMs by showing that relevance-based sparse prefilling can exceed dense attention quality. The open-sourced code is a clear strength that supports reproducibility and follow-on research.
major comments (3)
- [Abstract] Abstract: the central claim that sparse prefilling can outperform dense attention rests on the unverified assumption that top-K chunk selection (plus BOS anchors) never drops information required for accurate denoising; the manuscript must supply ablations that replace top-K with full dense selection or random selection while holding BOS and other factors fixed, to isolate whether the reported quality gains are attributable to the selection heuristic.
- [Experiments] Experiments section (LongBench/InfiniteBench tables): no error bars, standard deviations across runs, or sensitivity analysis for N and K are reported, so it is impossible to determine whether the SOTA quality and 9.1-28x speedups are statistically robust or sensitive to the heuristic top-K choices.
- [Method] Method (chunk selection paragraph): the per-step relevance metric for top-K selection is described only at a high level; without an explicit definition or pseudocode showing how it is computed from the current denoising state, it remains unclear whether the metric aligns with the true cross-token dependencies in the diffusion process at every step.
minor comments (1)
- [Abstract] Abstract: the speedup range 9.1-28.0x should be tied to the precise context lengths, model sizes, and values of N/K used in each measurement for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that sparse prefilling can outperform dense attention rests on the unverified assumption that top-K chunk selection (plus BOS anchors) never drops information required for accurate denoising; the manuscript must supply ablations that replace top-K with full dense selection or random selection while holding BOS and other factors fixed, to isolate whether the reported quality gains are attributable to the selection heuristic.
Authors: We agree that additional ablations are required to isolate the effect of the top-K heuristic and substantiate the claim that sparse prefilling can outperform dense attention. In the revised manuscript we will add experiments that replace top-K selection with full dense selection and with random selection while holding BOS anchors and all other factors fixed. revision: yes
-
Referee: [Experiments] Experiments section (LongBench/InfiniteBench tables): no error bars, standard deviations across runs, or sensitivity analysis for N and K are reported, so it is impossible to determine whether the SOTA quality and 9.1-28x speedups are statistically robust or sensitive to the heuristic top-K choices.
Authors: We acknowledge that the current results lack error bars and sensitivity analysis. We will rerun all LongBench and InfiniteBench evaluations across multiple random seeds, report means with standard deviations, and add sensitivity plots for N and K in the revised experiments section. revision: yes
-
Referee: [Method] Method (chunk selection paragraph): the per-step relevance metric for top-K selection is described only at a high level; without an explicit definition or pseudocode showing how it is computed from the current denoising state, it remains unclear whether the metric aligns with the true cross-token dependencies in the diffusion process at every step.
Authors: We will revise the method section to include an explicit mathematical definition of the per-step relevance metric together with pseudocode that shows its computation from the current denoising state at each diffusion step. revision: yes
Circularity Check
No circularity; algorithmic framework is self-contained
full rationale
The paper describes a training-free algorithmic procedure: partition prefix into chunks, cache KV once, select top-K by relevance, prepend BOS anchors. The complexity reduction (quadratic in decode length only) follows directly from the stated partitioning and selection without any fitted parameters, self-referential equations, or predictions that equal their inputs by construction. Quality claims rest on benchmark measurements rather than derivations. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the abstract or described method. This matches the default case of an independent algorithmic contribution.
Axiom & Free-Parameter Ledger
free parameters (2)
- N (number of prefix chunks)
- K (top chunks selected)
axioms (2)
- domain assumption KV representations computed once per chunk remain valid across all subsequent denoising steps
- domain assumption Top-K relevance scoring selects chunks containing all necessary context for correct denoising
Reference graph
Works this paper leans on
-
[1]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
\ DistServe \ : Disaggregating prefill and decoding for goodput-optimized large language model serving , author=. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
-
[2]
ACM Transactions on Storage , year=
Mooncake: A kvcache-centric disaggregated architecture for llm serving , author=. ACM Transactions on Storage , year=
-
[3]
arXiv preprint arXiv:2510.08544 , year=
SPAD: Specialized Prefill and Decode Hardware for Disaggregated LLM Inference , author=. arXiv preprint arXiv:2510.08544 , year=
-
[4]
arXiv preprint arXiv:2504.19867 , year=
semi-pd: Towards efficient llm serving via phase-wise disaggregated computation and unified storage , author=. arXiv preprint arXiv:2504.19867 , year=
-
[5]
Advances in Neural Information Processing Systems , volume=
dkv-cache: The cache for diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
2025 , eprint=
SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs , author=. 2025 , eprint=
2025
-
[7]
International Conference on Machine Learning (ICML) , year=
c sparse attention accelerating any model inference , author=. International Conference on Machine Learning (ICML) , year=
-
[8]
International Conference on Learning Representations , volume=
Sageattention: Accurate 8-bit attention for plug-and-play inference acceleration , author=. International Conference on Learning Representations , volume=
-
[9]
International Conference on Machine Learning (ICML) , year=
Sageattention2: Efficient attention with thorough outlier smoothing and per-thread int4 quantization , author=. International Conference on Machine Learning (ICML) , year=
-
[10]
International Conference on Learning Representations , year=
Efficient Streaming Language Models with Attention Sinks , author=. International Conference on Learning Representations , year=
-
[11]
2025 , eprint=
When Attention Sink Emerges in Language Models: An Empirical View , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
CTR-Sink: Attention Sink for Language Models in Click-Through Rate Prediction , author=. 2025 , eprint=
2025
-
[13]
arXiv preprint arXiv:2509.13866 , year=
Masked Diffusion Models as Energy Minimization , author=. arXiv preprint arXiv:2509.13866 , year=
-
[14]
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
Llada-v: Large language diffusion models with visual instruction tuning , author=. arXiv preprint arXiv:2505.16933 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
A Survey on Diffusion Language Models
A survey on diffusion language models , author=. arXiv preprint arXiv:2508.10875 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2025 , eprint=
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=. 2025 , eprint=
2025
-
[17]
2025 , eprint=
LLaDA2.0: Scaling Up Diffusion Language Models to 100B , author=. 2025 , eprint=
2025
-
[18]
2025 , eprint=
Scaling Diffusion Language Models via Adaptation from Autoregressive Models , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
SlimInfer: Accelerating Long-Context LLM Inference via Dynamic Token Pruning , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
InfLLM-V2: Dense-Sparse Switchable Attention for Seamless Short-to-Long Adaptation , author=. 2025 , eprint=
2025
-
[21]
2024 , eprint=
InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory , author=. 2024 , eprint=
2024
-
[22]
2025 , eprint=
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Dream 7B: Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[26]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[27]
2025 , eprint=
Attention Sinks in Diffusion Language Models , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
Sparse-dLLM: Accelerating Diffusion LLMs with Dynamic Cache Eviction , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
Mask Tokens as Prophet: Fine-Grained Cache Eviction for Efficient dLLM Inference , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
Attention Is All You Need for KV Cache in Diffusion LLMs , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
d ^2 Cache: Accelerating Diffusion-Based LLMs via Dual Adaptive Caching , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
Discrete Diffusion in Large Language and Multimodal Models: A Survey , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
A Survey on Diffusion Language Models , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
UltraLLaDA: Scaling the Context Length to 128K for Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[36]
arXiv preprint arXiv:2112.05682 , year=
Self-attention Does Not Need O(n^2) Memory , author=. arXiv preprint arXiv:2112.05682 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Infllm: Training-free long-context extrapolation for llms with an efficient context memory , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Quest: Query-aware sparsity for efficient long-context llm inference , author=. arXiv preprint arXiv:2406.10774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Advances in Neural Information Processing Systems , volume=
Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
arXiv preprint arXiv:2502.20766 , year=
Flexprefill: A context-aware sparse attention mechanism for efficient long-sequence inference , author=. arXiv preprint arXiv:2502.20766 , year=
-
[43]
arXiv preprint arXiv:2509.24014 , year=
SparseD: Sparse Attention for Diffusion Language Models , author=. arXiv preprint arXiv:2509.24014 , year=
-
[44]
2025 , eprint=
Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing , author=. 2025 , eprint=
2025
-
[45]
2023 , eprint=
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
2023
-
[46]
2025 , eprint=
What are you sinking? A geometric approach on attention sink , author=. 2025 , eprint=
2025
-
[47]
2023 , eprint=
Qwen Technical Report , author=. 2023 , eprint=
2023
-
[48]
2025 , url=
Ruyi Xu and Guangxuan Xiao and Haofeng Huang and Junxian Guo and Song Han , booktitle=. 2025 , url=
2025
-
[49]
2025 , eprint=
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , author=. 2025 , eprint=
2025
-
[50]
2025 , eprint=
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[51]
arXiv preprint arXiv:2509.26328 , year=
Fast-dllm v2: Efficient block-diffusion llm , author=. arXiv preprint arXiv:2509.26328 , year=
-
[52]
Advances in neural information processing systems , volume=
Structured denoising diffusion models in discrete state-spaces , author=. Advances in neural information processing systems , volume=
-
[53]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Diffusionbert: Improving generative masked language models with diffusion models , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[54]
DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models
Diffuseq: Sequence to sequence text generation with diffusion models , author=. arXiv preprint arXiv:2210.08933 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Advances in neural information processing systems , volume=
Diffusion-lm improves controllable text generation , author=. Advances in neural information processing systems , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete diffusion modeling by estimating the ratios of the data distribution , author=. arXiv preprint arXiv:2310.16834 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[59]
OpenCompass: A Universal Evaluation Platform for Foundation Models , author=
-
[60]
, title =
Kamradt, G. , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[61]
Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages , pages=
Triton: an intermediate language and compiler for tiled neural network computations , author=. Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages , pages=
-
[62]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Bench: Extending long context evaluation beyond 100K tokens , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[63]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Flash. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[64]
Advances in Neural Information Processing Systems , volume=
Flashattention-3: Fast and accurate attention with asynchrony and low-precision , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Transactions of the Association for Computational Linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the Association for Computational Linguistics , volume=
-
[66]
2024 , url=
Dong, Juechu and Feng, Boyuan and Guessous, Driss and Liang, Yanbo and He, Horace , journal=. 2024 , url=
2024
-
[67]
xFormers: A modular and hackable Transformer modelling library , author=
-
[68]
Proceedings of Machine Learning and Systems , volume=
Flashinfer: Efficient and customizable attention engine for llm inference serving , author=. Proceedings of Machine Learning and Systems , volume=
-
[69]
YaRN: Efficient Context Window Extension of Large Language Models
YaRN: Efficient Context Window Extension of Large Language Models , author=. arXiv preprint arXiv:2309.00071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Transformers: State-of-the-Art Natural Language Processing , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2020
-
[71]
LoSA: Locality Aware Sparse Attention for Block-Wise Diffusion Language Models
LoSA: Locality Aware Sparse Attention for Block-Wise Diffusion Language Models , author=. arXiv preprint arXiv:2604.12056 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
arXiv preprint arXiv:2602.02159 , year=
Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing , author=. arXiv preprint arXiv:2602.02159 , year=
-
[73]
Proceedings of the 41st International Conference on Machine Learning , articleno =
An, Chenxin and Huang, Fei and Zhang, Jun and Gong, Shansan and Qiu, Xipeng and Zhou, Chang and Kong, Lingpeng , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.