Speaker Group Encoding in Self-supervised Speech Recognition Models
Pith reviewed 2026-06-27 13:13 UTC · model grok-4.3
The pith
Self-supervised speech models encode speaker groups such as gender, age, dialect, ethnicity and native status, with finetuning for speaker identification amplifying phonetic aspects while ASR finetuning discards them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
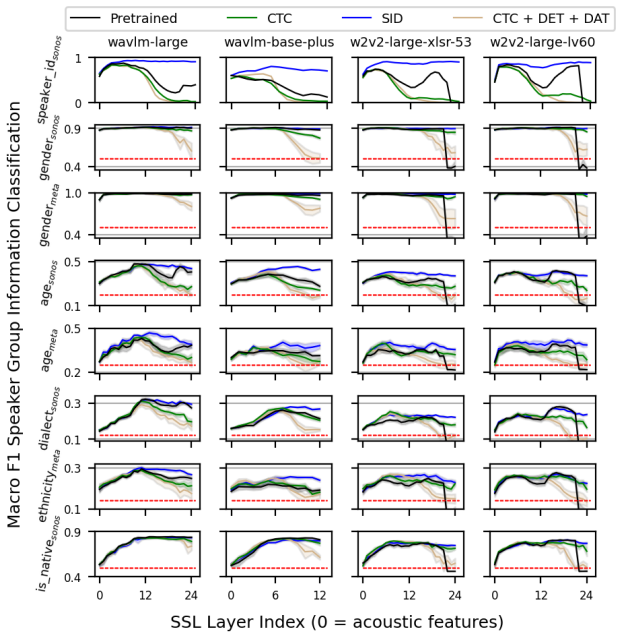
Self-supervised speech models encode information about speaker group categories including gender, age, dialect, ethnicity, and native speaker status. Finetuning for speaker identification amplifies speaker group information whose variance is more phonetic in nature but does not amplify information whose variance is more semantic in nature. Finetuning for automatic speech recognition discards phonetically variant speaker group information but retains semantically variant speaker group information. Fairness-enhancing ASR algorithms change the amount of speaker group information encoded, mainly for phonetically variant categories.
What carries the argument
Speaker group information (SGI) tracked through model embeddings, divided into phonetically variant versus semantically variant categories and measured before and after different finetuning tasks.
If this is right
- Finetuning on speaker identification increases the strength of phonetically driven group signals inside the model.
- Finetuning on automatic speech recognition removes phonetically driven group signals while leaving semantically driven ones in place.
- Fairness adjustments to ASR training mainly reduce phonetic group signals and leave semantic group signals largely unchanged.
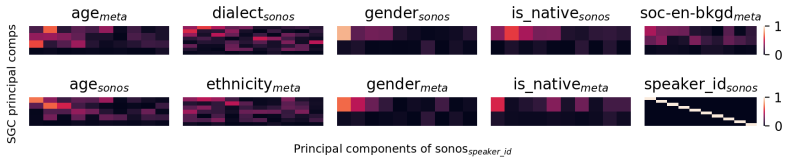
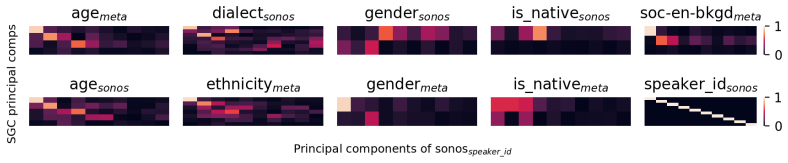
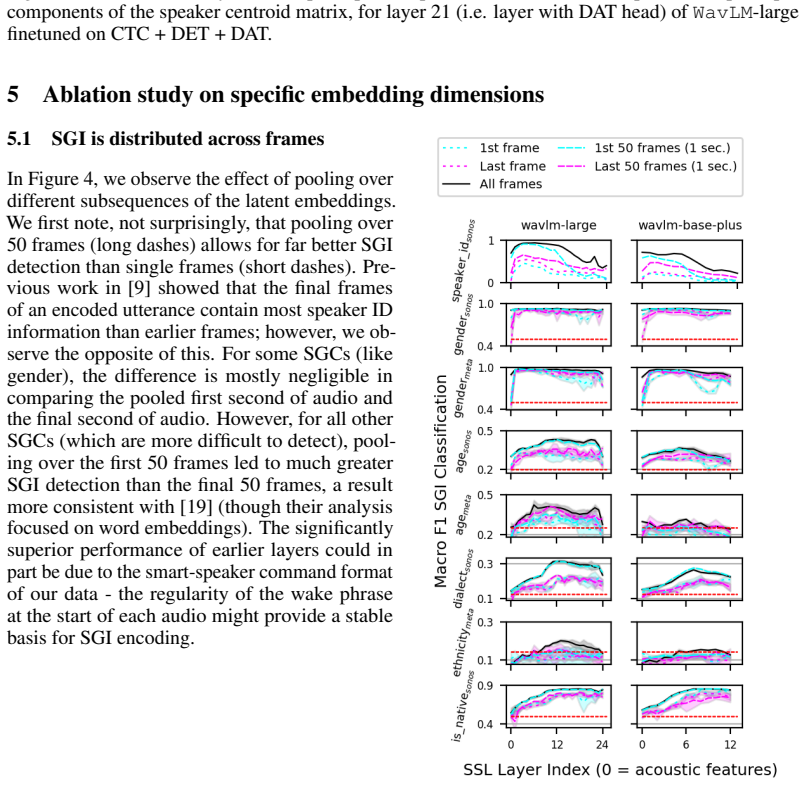
- Different speaker group categories are carried by distinct subdimensions of the embeddings and by different layers.
Where Pith is reading between the lines
- Fairness methods may need separate handling for semantic speaker information to achieve uniform reduction across all group categories.
- Task-specific control of which speaker signals to retain could be added during pretraining rather than only at finetuning time.
- The phonetic-versus-semantic split may appear in other self-supervised audio models when similar finetuning experiments are run.
Load-bearing premise
Speaker group categories can be correctly split into those whose main differences are phonetic versus those whose main differences are semantic, and this split explains why finetuning affects them differently.
What would settle it
Re-label the speaker groups by direct acoustic measurements of phonetic variance versus semantic variance and check whether the amplification and discarding patterns still align with the speaker-ID versus ASR finetuning results.
Figures
read the original abstract
We investigate what self-supervised speech recognition models (S3Ms) learn about speaker groups (SGs). We examine several states of S3Ms: pretrained, finetuned on speaker identification (SID), finetuned on automatic speech recognition (ASR), and ASR-finetuned using a fairness enhancing algorithm. We find that S3Ms encode information about several speaker group categories (SGCs), including their gender, age, dialect, ethnicity, and whether they are a native speaker. We find that finetuning for SID amplifies certain SGCs, namely those whose variance is more phonetic in nature, though it does not amplify other SGCs, namely those whose variance is more semantic in nature. On the other hand, finetuning for ASR discards phonetically variant speaker group information (SGI) but retains semantically variant SGI. We find that ASR algorithms designed for fairness improvement change to what extent SGI is encoded in S3Ms; however, this is primarily true for for phonetically variant SGCs, and less true for semantically variant SGCs. We discuss how SGI is encoded by each layer, and identify subdimensions of embeddings responsible for encoding different SGCs. Finally, we discuss how our findings could be beneficial in designing fairer ASR algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates speaker group encoding in self-supervised speech recognition models (S3Ms). It compares pretrained models to those finetuned on speaker identification (SID), automatic speech recognition (ASR), and fairness-enhanced ASR. The central claims are that S3Ms encode information about speaker group categories (SGCs) including gender, age, dialect, ethnicity, and native-speaker status; that SID finetuning amplifies SGCs whose variance is primarily phonetic while leaving semantically variant SGCs unchanged; that ASR finetuning discards phonetically variant speaker group information (SGI) but retains semantically variant SGI; and that fairness algorithms primarily affect phonetic SGCs. Additional analyses cover layer-wise encoding and subdimensions of embeddings responsible for different SGCs.
Significance. If the phonetic-versus-semantic distinction can be independently validated and the probing results replicated with appropriate controls, the work would provide actionable measurements for controlling unwanted speaker attributes during ASR finetuning and for designing fairness interventions. The multi-state comparison (pretrained, SID, ASR, fairness) supplies concrete empirical data that could inform model development.
major comments (2)
- [Results and Discussion sections describing SGC categorization and finetuning effects] The assignment of SGCs to 'phonetic variance' (gender, age, dialect) versus 'semantic variance' (ethnicity, native-speaker status) is load-bearing for the interpretation of all finetuning effects, yet no explicit criteria, quantitative proxy (e.g., mutual information with formant or lexical features), pre-specified validation, or citation to independent classification is supplied. Without such grounding the differential amplification/discarding claims cannot be evaluated as causal rather than post-hoc.
- [Methods and Experimental Setup] The abstract and methods description supply no information on the datasets, number of speakers per SGC, probing classifier architecture, statistical tests, or controls for confounding acoustic or lexical factors. These omissions prevent assessment of whether the reported encoding differences are robust.
minor comments (2)
- [Methods] Clarify the operationalization of 'phonetic' versus 'semantic' variance for each SGC with a table or explicit decision rule.
- [Layer-wise analysis] Add layer indices and embedding dimensions when discussing subdimensions responsible for specific SGCs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below. Where the comments identify gaps in justification or reporting, we agree that revisions are warranted and will incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Results and Discussion sections describing SGC categorization and finetuning effects] The assignment of SGCs to 'phonetic variance' (gender, age, dialect) versus 'semantic variance' (ethnicity, native-speaker status) is load-bearing for the interpretation of all finetuning effects, yet no explicit criteria, quantitative proxy (e.g., mutual information with formant or lexical features), pre-specified validation, or citation to independent classification is supplied. Without such grounding the differential amplification/discarding claims cannot be evaluated as causal rather than post-hoc.
Authors: We acknowledge that the phonetic-versus-semantic distinction requires more explicit grounding than is currently provided. The categorization was motivated by established linguistic distinctions: attributes such as gender, age, and dialect primarily modulate acoustic-phonetic realization (e.g., formant shifts, prosody), whereas ethnicity and native-speaker status more strongly influence lexical choice and semantic content in the datasets examined. However, we agree that this rationale should be stated with criteria and supporting citations rather than left implicit. In the revised manuscript we will add a dedicated subsection (likely in Methods or an expanded Results) that (i) states the pre-specified criteria used, (ii) supplies relevant linguistic references, and (iii) reports a simple quantitative check (e.g., correlation of each SGC with selected acoustic features). This will allow readers to evaluate the distinction independently. revision: yes
-
Referee: [Methods and Experimental Setup] The abstract and methods description supply no information on the datasets, number of speakers per SGC, probing classifier architecture, statistical tests, or controls for confounding acoustic or lexical factors. These omissions prevent assessment of whether the reported encoding differences are robust.
Authors: We agree that the current Methods section is insufficiently detailed for reproducibility and evaluation. Although the full manuscript contains the underlying data sources and probing setup, these elements are not presented with the required specificity. In the revision we will expand the Methods section to include: (a) exact dataset names and splits with speaker counts per SGC, (b) the architecture and hyperparameters of the probing classifiers, (c) the statistical tests and multiple-comparison corrections applied, and (d) any acoustic or lexical controls (or explicit statement that none were used). These additions will directly address the referee’s concern about robustness. revision: yes
Circularity Check
No circularity: purely empirical probing with no derivations or self-referential fits
full rationale
The work reports measurements of speaker group information in pretrained and finetuned S3Ms via probing classifiers. No equations, parameter fittings, or predictions are defined that reduce to the input data by construction. The phonetic-vs-semantic variance distinction is an interpretive label applied to observed categories; it does not appear as a self-definitional step, a fitted input renamed as prediction, or a load-bearing self-citation. The analysis is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Similarities between Arabic dialects: Investigating geographical proximity.Information Processing & Management, 59(1):102770, January
Abdulkareem Alsudais, Wafa Alotaibi, and Faye Alomary. Similarities between Arabic dialects: Investigating geographical proximity.Information Processing & Management, 59(1):102770, January
-
[2]
doi: 10.1016/j.ipm.2021.102770
ISSN 0306-4573. doi: 10.1016/j.ipm.2021.102770
-
[3]
Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations, October 2020
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations, October 2020
2020
-
[4]
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing , volume=
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing.IEEE Journal of Selected Topics in Signal Pr...
-
[5]
Self-Supervised Speech Representations are More Phonetic than Semantic, June 2024
Kwanghee Choi, Ankita Pasad, Tomohiko Nakamura, Satoru Fukayama, Karen Livescu, and Shinji Watanabe. Self-Supervised Speech Representations are More Phonetic than Semantic, June 2024
2024
-
[6]
Similarity Analysis of Self-Supervised Speech Representations, February 2021
Yu-An Chung, Yonatan Belinkov, and James Glass. Similarity Analysis of Self-Supervised Speech Representations, February 2021
2021
-
[7]
Proximité rythmique entre apprenants et natifs du français Évaluation d’une métrique basée sur le CEFC
Sylvain Coulange and Solange Rossato. Proximité rythmique entre apprenants et natifs du français Évaluation d’une métrique basée sur le CEFC. In Christophe Benzitoun, Chloé Braud, Laurine Huber, David Langlois, Slim Ouni, Sylvain Pogodalla, and Stéphane Schneider, editors, Actes de La 6e Conférence Conjointe Journées d’Études Sur La Parole (JEP, 33e Éditi...
2020
-
[8]
Dialect-Specific Models for Automatic Speech Recognition of African American Vernacular English
Rachel Dorn. Dialect-Specific Models for Automatic Speech Recognition of African American Vernacular English. In Venelin Kovatchev, Irina Temnikova, Branislava Šandrih, and Ivelina Nikolova, editors,Proceedings of the Student Research Workshop Associated with RANLP 2019, pages 16–20, Varna, Bulgaria, September 2019. INCOMA Ltd. doi: 10.26615/issn.2603-282...
-
[9]
Solene Evain, Ha Nguyen, Hang Le, Marcely Zanon Boito, Salima Mdhaffar, Sina Alisamir, Ziyi Tong, Natalia Tomashenko, Marco Dinarelli, Titouan Parcollet, Alexandre Allauzen, Yannick Esteve, Benjamin Lecouteux, Francois Portet, Solange Rossato, Fabien Ringeval, Didier Schwab, and Laurent Besacier. LeBenchmark: A Reproducible Framework for Assessing Self-Su...
-
[10]
Silence is Sweeter Than Speech: Self- Supervised Model Using Silence to Store Speaker Information, May 2022
Chi-Luen Feng, Po-chun Hsu, and Hung-yi Lee. Silence is Sweeter Than Speech: Self- Supervised Model Using Silence to Store Speaker Information, May 2022
2022
-
[11]
Towards inclusive automatic speech recognition.Computer Speech & Language, 84:101567, March 2024
Siyuan Feng, Bence Mark Halpern, Olya Kudina, and Odette Scharenborg. Towards inclusive automatic speech recognition.Computer Speech & Language, 84:101567, March 2024. ISSN 0885-2308. doi: 10.1016/j.csl.2023.101567
-
[12]
Domain-Adversarial Training of Neural Networks
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-Adversarial Training of Neural Networks. In Gabriela Csurka, editor,Domain Adaptation in Computer Vision Applications, pages 189–209. Springer International Publishing, Cham, 2017. ISBN 978-3-319-58346-4 978-3-...
-
[13]
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units, June 2021
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units, June 2021
2021
-
[14]
Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings, October 2021
Jialu Li, Vimal Manohar, Pooja Chitkara, Andros Tjandra, Michael Picheny, Frank Zhang, Xiaohui Zhang, and Yatharth Saraf. Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings, October 2021
2021
-
[15]
Nuanced metrics for measuring unintended bias with real data for text classification
Lanna Lima, Vasco Furtado, Elizabeth Furtado, and Virgilio Almeida. Empirical Analysis of Bias in V oice-based Personal Assistants. InCompanion Proceedings of The 2019 World Wide Web Conference, pages 533–538, San Francisco USA, May 2019. ACM. ISBN 978-1-4503-6675-5. doi: 10.1145/3308560.3317597
-
[16]
Self-supervised Predictive Coding Models Encode Speaker and Phonetic Information in Orthogonal Subspaces, December 2023
Oli Liu, Hao Tang, and Sharon Goldwater. Self-supervised Predictive Coding Models Encode Speaker and Phonetic Information in Orthogonal Subspaces, December 2023
2023
-
[17]
Orthogonality and isotropy of speaker and phonetic information in self-supervised speech representations, June 2024
Mukhtar Mohamed, Oli Danyi Liu, Hao Tang, and Sharon Goldwater. Orthogonality and isotropy of speaker and phonetic information in self-supervised speech representations, June 2024
2024
-
[18]
Layer-wise Analysis of a Self-supervised Speech Representation Model, December 2022
Ankita Pasad, Ju-Chieh Chou, and Karen Livescu. Layer-wise Analysis of a Self-supervised Speech Representation Model, December 2022
2022
-
[19]
Comparative layer-wise analysis of self- supervised speech models, March 2023
Ankita Pasad, Bowen Shi, and Karen Livescu. Comparative layer-wise analysis of self- supervised speech models, March 2023
2023
-
[20]
What Do Self-Supervised Speech Models Know About Words?, January 2024
Ankita Pasad, Chung-Ming Chien, Shane Settle, and Karen Livescu. What Do Self-Supervised Speech Models Know About Words?, January 2024
2024
-
[21]
SpeechBrain: A General-Purpose Speech Toolkit, June 2021
Mirco Ravanelli, Titouan Parcollet, Peter Plantinga, Aku Rouhe, Samuele Cornell, Loren Lugosch, Cem Subakan, Nauman Dawalatabad, Abdelwahab Heba, Jianyuan Zhong, Ju-Chieh Chou, Sung-Lin Yeh, Szu-Wei Fu, Chien-Feng Liao, Elena Rastorgueva, François Grondin, William Aris, Hwidong Na, Yan Gao, Renato De Mori, and Yoshua Bengio. SpeechBrain: A General-Purpose...
2021
-
[22]
Linear Adversarial Concept Erasure, December 2024
Shauli Ravfogel, Michael Twiton, Yoav Goldberg, and Ryan Cotterell. Linear Adversarial Concept Erasure, December 2024
2024
-
[23]
Analyzing Acoustic Word Embeddings from Pre-trained Self-supervised Speech Models, March 2023
Ramon Sanabria, Hao Tang, and Sharon Goldwater. Analyzing Acoustic Word Embeddings from Pre-trained Self-supervised Speech Models, March 2023. 9
2023
-
[24]
Sonos V oice Control Bias Assessment Dataset: A Methodology for Demographic Bias Assessment in V oice Assistants
Chloe Sekkat, Fanny Leroy, Salima Mdhaffar, Blake Perry Smith, Yannick Estève, Joseph Dureau, and Alice Coucke. Sonos V oice Control Bias Assessment Dataset: A Methodology for Demographic Bias Assessment in V oice Assistants. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors,Proceedings of the...
2024
-
[25]
2020, in ICASSP 2020, 1434–1438, doi: 10.1109/ICASSP40776.2020.9053284
Suwon Shon, Ahmed Ali, Younes Samih, Hamdy Mubarak, and James Glass. ADI17: A Fine-Grained Arabic Dialect Identification Dataset. InICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8244–8248, Barcelona, Spain, May 2020. IEEE. ISBN 978-1-5090-6631-5. doi: 10.1109/ICASSP40776.2020.9052982
-
[26]
X- Vectors: Robust DNN Embeddings for Speaker Recognition
David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur. X- Vectors: Robust DNN Embeddings for Speaker Recognition. In2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5329–5333, April 2018. doi: 10.1109/ ICASSP.2018.8461375
arXiv 2018
-
[27]
Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing, August 2021
Benjamin van Niekerk, Leanne Nortje, Matthew Baas, and Herman Kamper. Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing, August 2021
2021
-
[28]
Irina-Elena Veliche, Zhuangqun Huang, Vineeth Ayyat Kochaniyan, Fuchun Peng, Ozlem Kalinli, and Michael L. Seltzer. Towards measuring fairness in speech recognition: Fair-Speech dataset, August 2024
2024
-
[29]
Open Implementation and Study of BEST-RQ for Speech Processing, September 2024
Ryan Whetten, Titouan Parcollet, Marco Dinarelli, and Yannick Estève. Open Implementation and Study of BEST-RQ for Speech Processing, September 2024
2024
-
[30]
Doyle, Leigh Clark, and Benjamin R
Yunhan Wu, Daniel Rough, Anna Bleakley, Justin Edwards, Orla Cooney, Philip R. Doyle, Leigh Clark, and Benjamin R. Cowan. See What I’m Saying? Comparing Intelligent Personal Assistant Use for Native and Non-Native Language Speakers. In22nd International Conference on Human-Computer Interaction with Mobile Devices and Services, MobileHCI ’20, pages 1–9, Ne...
-
[31]
Jeff Lai, Kushal Lakhotia, Yist Y
Shu-wen Yang, Po-Han Chi, Yung-Sung Chuang, Cheng-I. Jeff Lai, Kushal Lakhotia, Yist Y . Lin, Andy T. Liu, Jiatong Shi, Xuankai Chang, Guan-Ting Lin, Tzu-Hsien Huang, Wei-Cheng Tseng, Ko-tik Lee, Da-Rong Liu, Zili Huang, Shuyan Dong, Shang-Wen Li, Shinji Watanabe, Abdelrahman Mohamed, and Hung-yi Lee. SUPERB: Speech processing Universal PERformance Benchm...
2021
-
[32]
Less Forgetting for Better Generalization: Exploring Continual-learning Fine-tuning Methods for Speech Self-supervised Representations, June 2024
Salah Zaiem, Titouan Parcollet, and Slim Essid. Less Forgetting for Better Generalization: Exploring Continual-learning Fine-tuning Methods for Speech Self-supervised Representations, June 2024
2024
-
[33]
Wei Zhou, Haotian Wu, Jingjing Xu, Mohammad Zeineldeen, Christoph Lüscher, Ralf Schlüter, and Hermann Ney. Enhancing and Adversarial: Improve ASR with Speaker Labels. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, June 2023. doi: 10.1109/ICASSP49357.2023.10096722. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.