Vector Map as Language: Toward Unified Remote Sensing Vector Mapping
Pith reviewed 2026-06-27 13:36 UTC · model grok-4.3
The pith
Treating vector maps as structured text in a GeoJSON-like language lets one model handle multiple map categories from imagery with cross-dataset generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
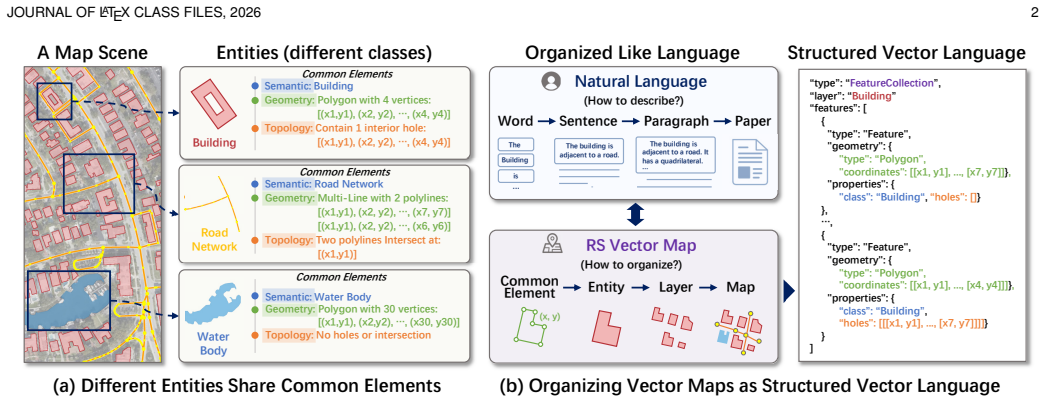
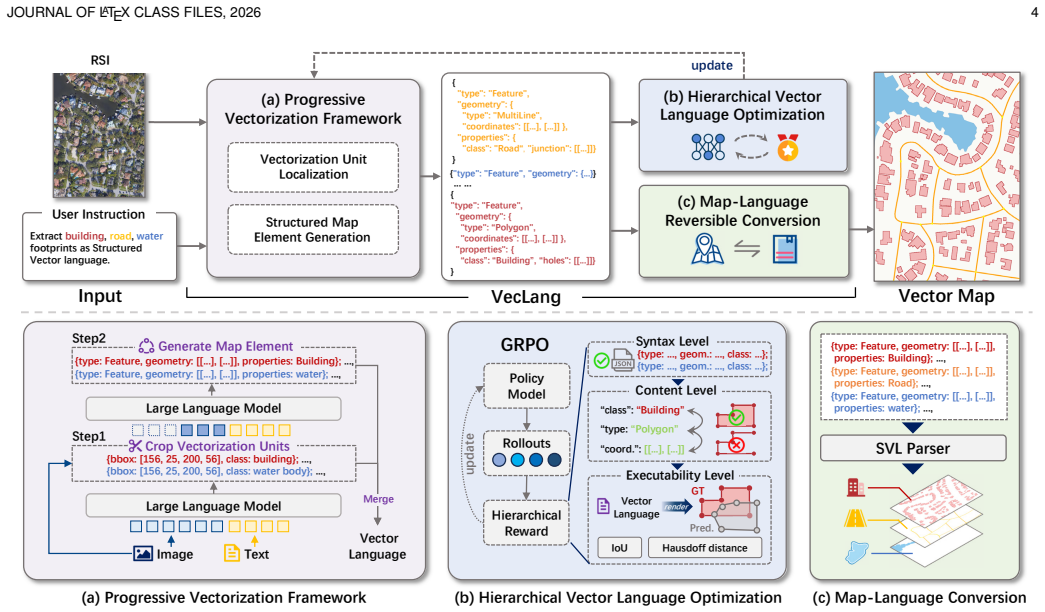
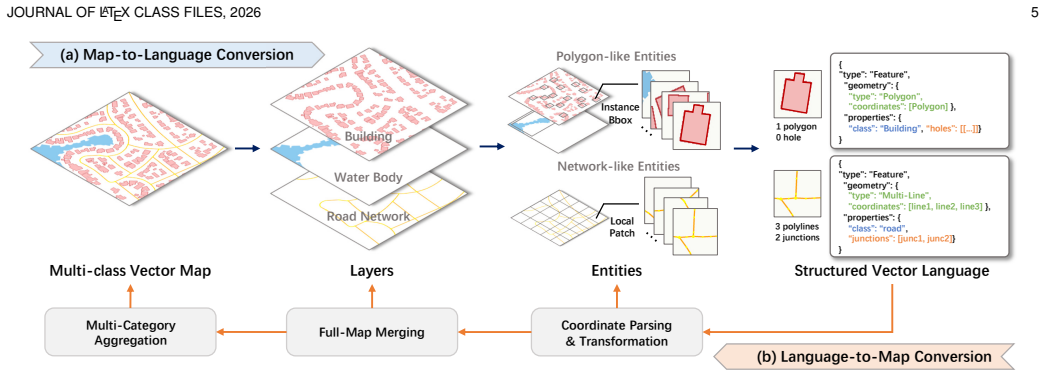
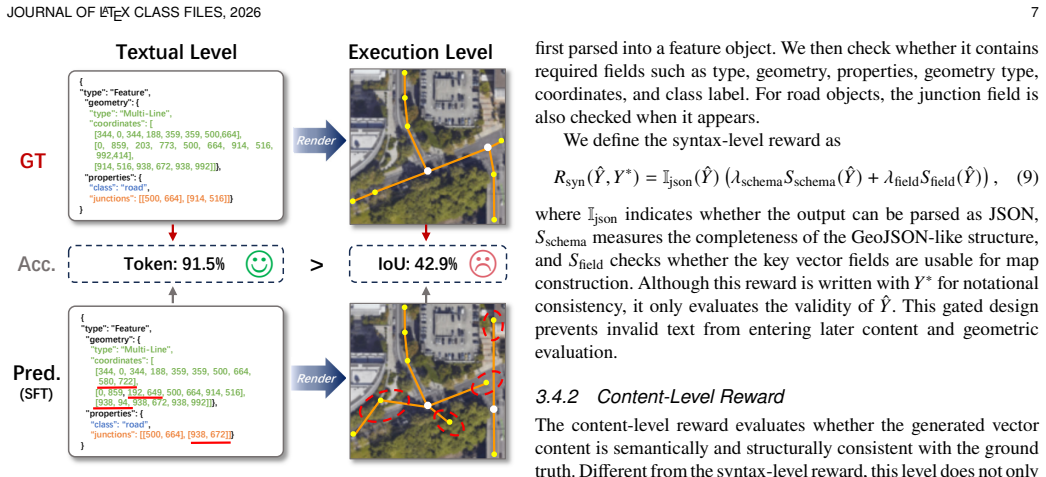
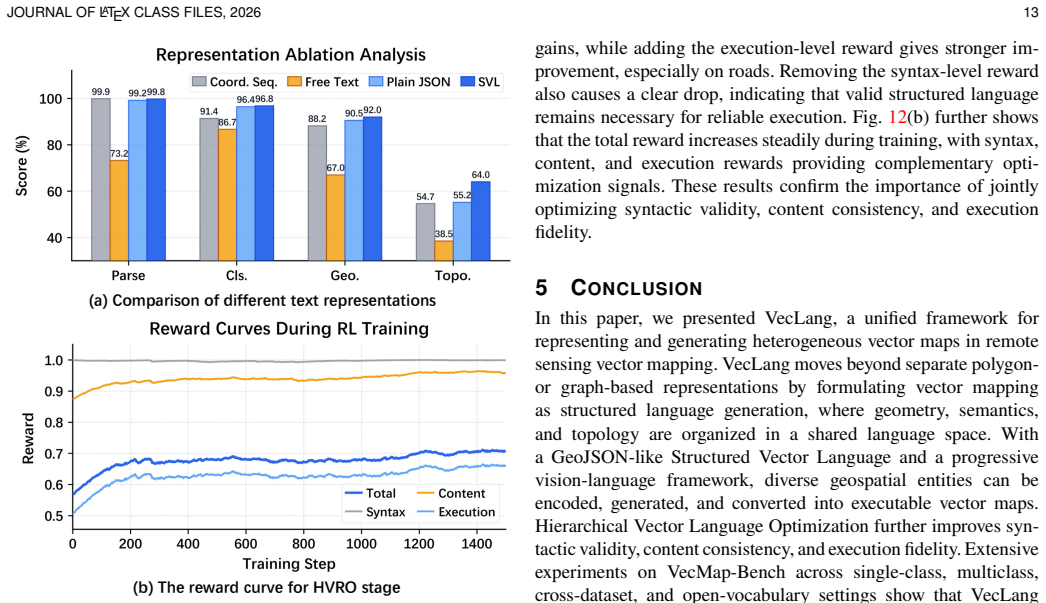
VecLang reformulates multiclass vector mapping as structured text generation. It encodes the common elements of different geospatial entities into a GeoJSON-like vector language that accommodates geometry, semantics, and topology within one textual format. A progressive vision-language mapping framework localizes vectorization units before generating the structured elements, and Hierarchical Vector Language Optimization applies reinforcement learning to improve syntax validity, content fidelity, and map executability.
What carries the argument
The GeoJSON-like vector language that encodes geometry, semantics, and topology of heterogeneous geospatial entities into a shared textual format for cross-category modeling.
If this is right
- A single model can perform both single-class and multiclass vector mapping tasks.
- The approach yields strong performance under cross-dataset evaluation settings.
- Open-vocabulary generalization becomes feasible for previously unseen map categories.
- Reinforcement learning optimization improves syntax validity, content fidelity, and map executability simultaneously.
Where Pith is reading between the lines
- The textual format could allow direct use of language model techniques for post-processing or querying generated maps.
- This representation might reduce the engineering effort needed when adding new entity types to an existing mapping system.
- Similar language encodings could be tested on other structured output tasks that mix geometry with semantics, such as diagram generation from images.
Load-bearing premise
A GeoJSON-like vector language can encode the common elements of heterogeneous geospatial entities across categories without loss of critical information that would prevent reliable map reconstruction.
What would settle it
A test case where a complex entity with specific topological relations or instance boundaries is converted to the vector language and the resulting map cannot be reconstructed to match the original topology or boundaries.
Figures

read the original abstract
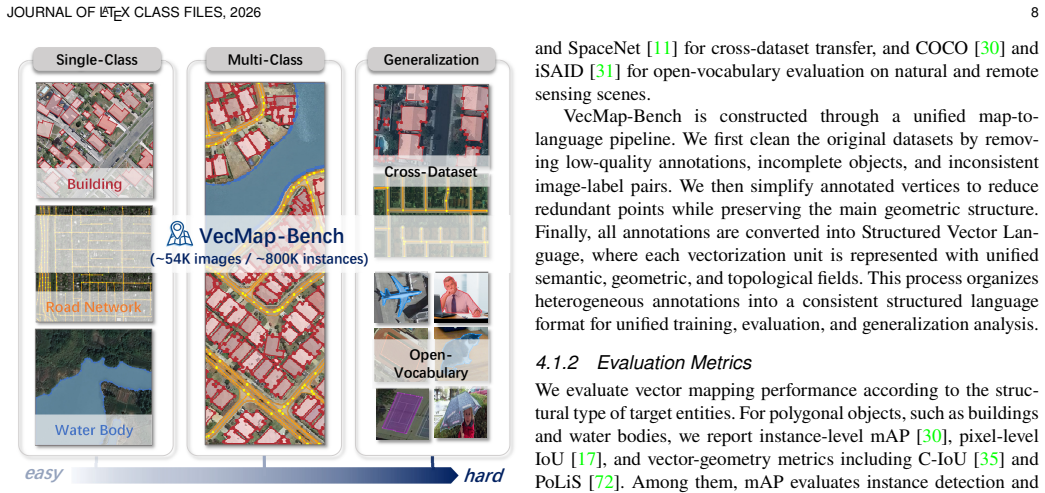
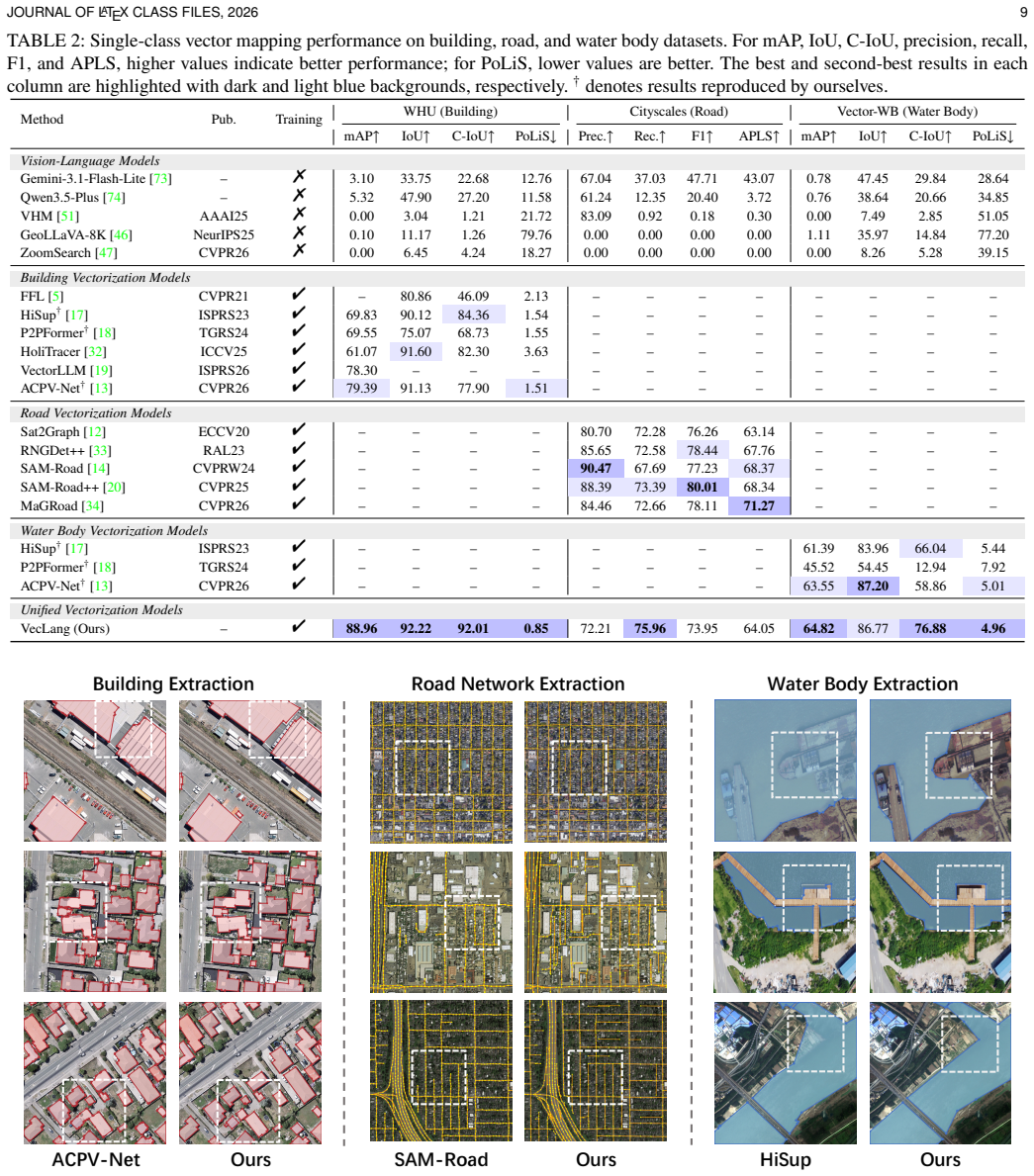
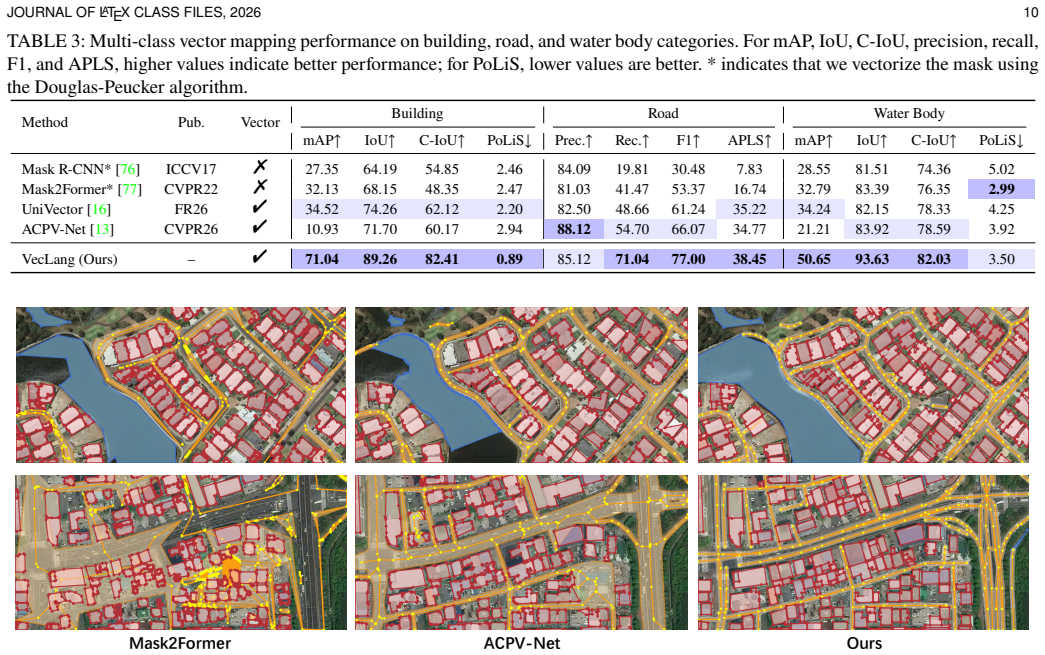
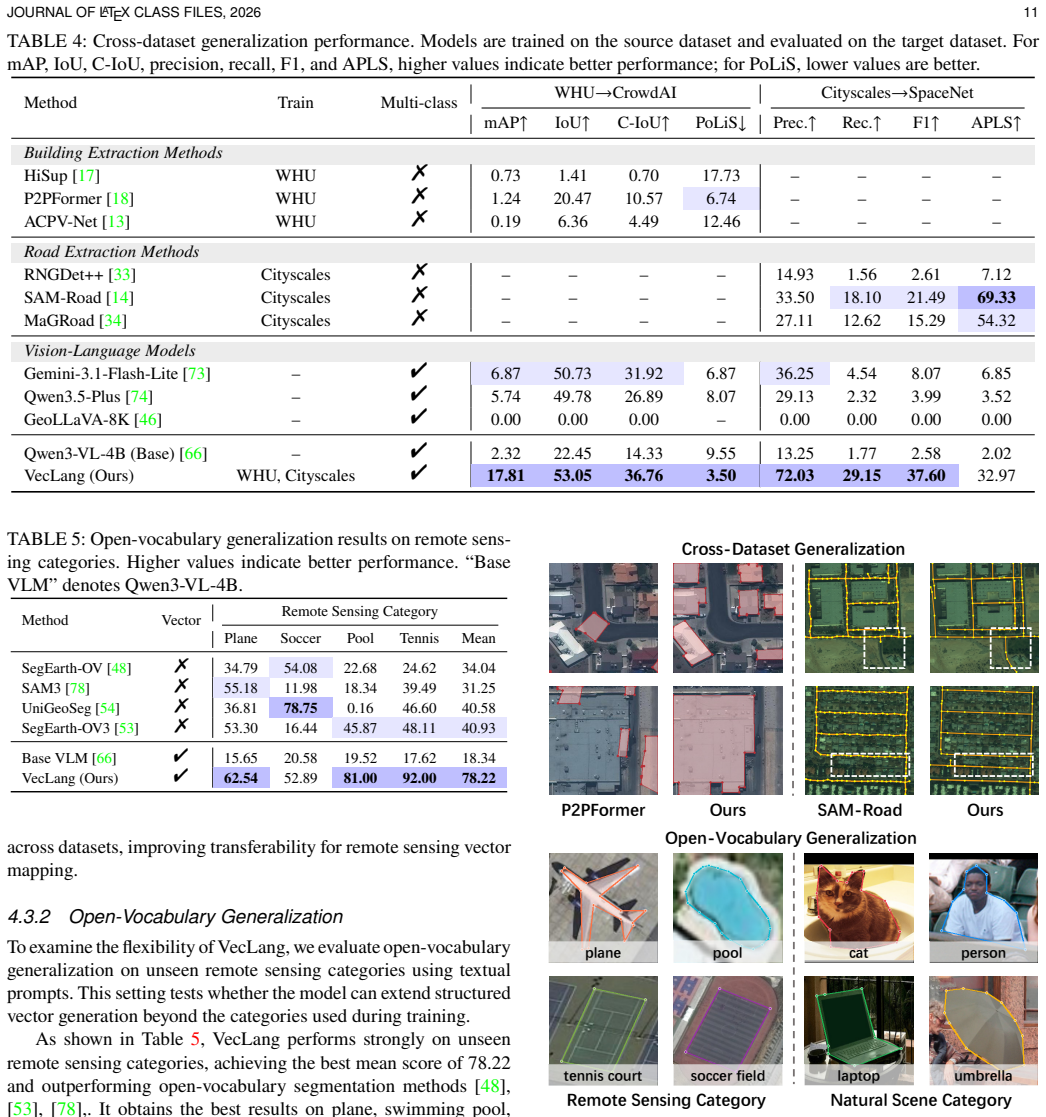
Remote sensing vector mapping aims to generate structured maps of geospatial entities, such as buildings, roads, and water bodies, from remote sensing imagery. In practice, vector maps usually contain multiple category layers and heterogeneous entity structures, requiring a unified model for diverse mapping needs. However, existing methods typically represent vector objects as polygons or graphs, making them suitable only for specific categories: polygons poorly capture topological relations, while graphs often blur instance boundaries. We observe that language, as a natural medium for human communication, offers a flexible and expressive representation that can accommodate heterogeneous map elements, including geometry, semantics, and topolog. Motivated by this insight, we propose Vector Map as Language (VecLang), a unified paradigm that reformulates multiclass vector mapping as structured text generation. VecLang encodes the common elements of different geospatial entities into a GeoJSON-like vector language, enabling cross-category modeling within a shared textual format. To generate this language reliably, we design a progressive vision-language mapping framework that first localizes vectorization units and then generates structured map elements. We further introduce Hierarchical Vector Language Optimization, which uses reinforcement learning to improve syntax validity, content fidelity, and map executability. We also build VecMap-Bench with 54K images and 800K instances, supporting training and evaluation across standard and generalization settings. Extensive experiments demonstrate that VecLang handles both single-class and multiclass vector mapping while achieving strong cross-dataset and open-vocabulary generalization. The model and dataset are publicly available at https://github.com/yyyyll0ss/VecLang.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VecLang, a paradigm reformulating multiclass remote sensing vector mapping as structured text generation using a GeoJSON-like vector language to unify geometry, semantics, and topology across heterogeneous entities. It introduces a progressive vision-language framework that localizes vectorization units then generates map elements, augmented by Hierarchical Vector Language Optimization via reinforcement learning for syntax, fidelity, and executability. A new VecMap-Bench dataset (54K images, 800K instances) supports training and evaluation, with claims of strong single-class/multiclass performance plus cross-dataset and open-vocabulary generalization.
Significance. If the encoding preserves topology without irreversible loss and the reported generalization holds under full verification, this could offer a genuinely unified approach to vector mapping that leverages language model strengths for diverse geospatial categories, moving beyond category-specific polygon or graph representations. The public release of model and benchmark is a clear strength for reproducibility.
major comments (3)
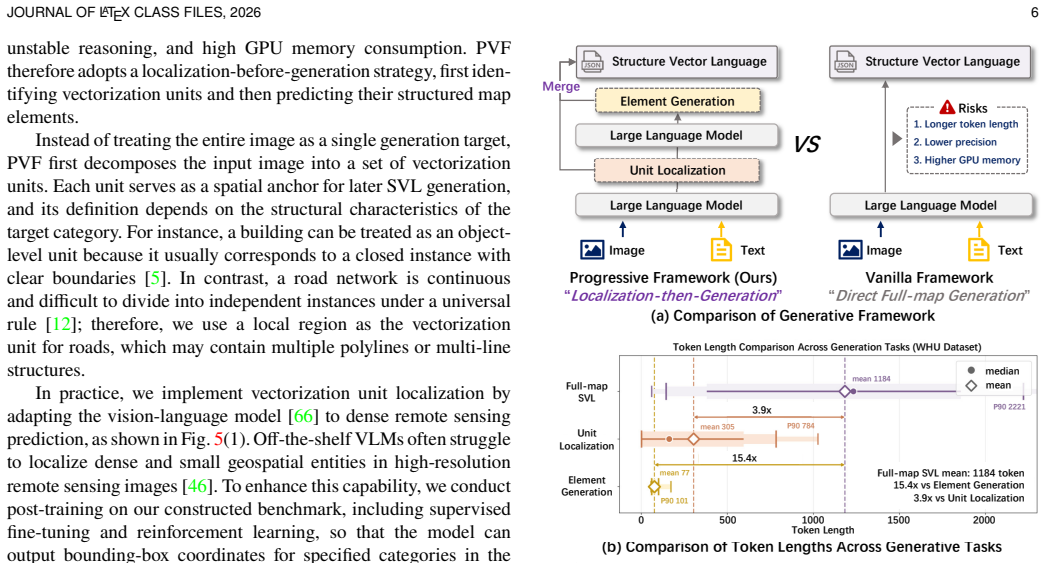
- [§3] §3 (Methods): The progressive vision-language mapping framework and Hierarchical Vector Language Optimization are described conceptually, but the manuscript provides no equations for the localization step, the RL reward formulation (syntax validity, content fidelity, executability), or the exact GeoJSON-like schema definition; without these, it is impossible to assess whether the central claim of reliable cross-category generation is supported or to reproduce the results.
- [§4] §4 (Experiments): The abstract and results claim strong cross-dataset and open-vocabulary generalization, yet no quantitative metrics (e.g., mIoU, topological error rates, or reconstruction fidelity), ablation tables, or baseline comparisons are detailed in the visible material; this directly undermines verification of the multiclass and generalization claims that constitute the paper's main contribution.
- [§4.1] VecMap-Bench construction (§4.1): The benchmark is presented as supporting standard and generalization settings, but without explicit description of how the 800K instances were annotated for topology and semantics or how train/test splits avoid leakage across categories, the generalization results cannot be evaluated for robustness.
minor comments (2)
- [Abstract] Abstract: 'topolog' appears to be a typo for 'topology'.
- The GitHub link is provided but the manuscript does not specify the exact commit or release tag used for the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects for improving clarity and reproducibility. We address each major comment point by point below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [§3] §3 (Methods): The progressive vision-language mapping framework and Hierarchical Vector Language Optimization are described conceptually, but the manuscript provides no equations for the localization step, the RL reward formulation (syntax validity, content fidelity, executability), or the exact GeoJSON-like schema definition; without these, it is impossible to assess whether the central claim of reliable cross-category generation is supported or to reproduce the results.
Authors: We agree that explicit mathematical details would improve the methods section. In the revised manuscript, we will introduce equations for the localization step (including the progressive vision-language objective), the full Hierarchical Vector Language Optimization reward formulation (with components for syntax validity, content fidelity, and executability), and the precise GeoJSON-like schema definition. These additions will directly support evaluation of the cross-category claims and enable reproduction. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and results claim strong cross-dataset and open-vocabulary generalization, yet no quantitative metrics (e.g., mIoU, topological error rates, or reconstruction fidelity), ablation tables, or baseline comparisons are detailed in the visible material; this directly undermines verification of the multiclass and generalization claims that constitute the paper's main contribution.
Authors: The manuscript reports extensive quantitative results with the requested metrics (mIoU, topological error rates, reconstruction fidelity), ablation studies, and baseline comparisons for single-class, multiclass, cross-dataset, and open-vocabulary settings. To address visibility concerns, the revision will reorganize and expand these results with additional highlighted tables and clearer cross-references, ensuring all supporting evidence is immediately accessible. revision: partial
-
Referee: [§4.1] VecMap-Bench construction (§4.1): The benchmark is presented as supporting standard and generalization settings, but without explicit description of how the 800K instances were annotated for topology and semantics or how train/test splits avoid leakage across categories, the generalization results cannot be evaluated for robustness.
Authors: We will expand §4.1 in the revision to include a detailed account of the annotation pipeline for topology and semantics (including protocols and validation steps) and the train/test split design explicitly constructed to prevent cross-category leakage. This will allow robust assessment of the generalization results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes VecLang as a new paradigm reformulating vector mapping as structured text generation in a GeoJSON-like format, introduces a progressive vision-language framework and RL-based Hierarchical Vector Language Optimization, and constructs a new benchmark VecMap-Bench. No load-bearing step reduces by construction to fitted inputs, self-definitions, or self-citation chains; the central claims rest on experimental results across single-class, multiclass, cross-dataset, and open-vocabulary settings rather than renaming or deriving the target quantities from themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language offers a flexible representation that can accommodate heterogeneous map elements including geometry, semantics, and topology
invented entities (3)
-
VecLang paradigm
no independent evidence
-
Hierarchical Vector Language Optimization
no independent evidence
-
VecMap-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Full-scope vectorization of geographical elements from large-size remote sensing imagery,
Y. Li, W. Li, B. Dang, Y. Wang, W. Chen, L. Wang, B. Yang, and Y. Zhang, “Full-scope vectorization of geographical elements from large-size remote sensing imagery,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 48, no. 6, pp. 6897–6911, 2026
2026
-
[2]
Learning to extract building footprints from off-nadir aerial images,
J. Wang, L. Meng, W. Li, W. Yang, L. Yu, and G.-S. Xia, “Learning to extract building footprints from off-nadir aerial images,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 1, pp. 1294–1301, 2023
2023
-
[3]
Deep learning in remote sensing: A comprehensive review and list of resources,
X. X. Zhu, D. Tuia, L. Mou, G.-S. Xia, L. Zhang, F. Xu, and F. Fraundorfer, “Deep learning in remote sensing: A comprehensive review and list of resources,”IEEE Geosci. Remote Sens. Mag., vol. 5, no. 4, pp. 8–36, 2017
2017
-
[4]
P. A. Longley, M. F. Goodchild, D. J. Maguire, and D. W. Rhind, Geographic Information Science and Systems, 4th ed. John Wiley & Sons, 2015
2015
-
[5]
Polygonal building extraction by frame field learning,
N. Girard, D. Smirnov, J. Solomon, and Y. Tarabalka, “Polygonal building extraction by frame field learning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 5891–5900
2021
-
[6]
When vectorization meets change detection,
Y. Yan, J. Yue, J. Lin, Z. Guo, Y. Fang, Z. Li, W. Xie, and L. Fang, “When vectorization meets change detection,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–14, 2023. JOURNAL OF LATEX CLASS FILES, 2026 14
2023
-
[7]
Point processes for unsu- pervised line network extraction in remote sensing,
C. Lacoste, X. Descombes, and J. Zerubia, “Point processes for unsu- pervised line network extraction in remote sensing,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 27, no. 10, pp. 1568–1579, 2005
2005
-
[8]
Maptrv2: An end-to-end framework for online vectorized hd map construction,
B. Liao, S. Chen, Y. Zhang, B. Jiang, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Maptrv2: An end-to-end framework for online vectorized hd map construction,”Int. J. Comput. Vis., vol. 133, no. 3, pp. 1352–1374, 2025
2025
-
[9]
Farseg++: Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery,
Z. Zheng, Y. Zhong, J. Wang, A. Ma, and L. Zhang, “Farseg++: Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 11, pp. 13 715–13 729, 2023
2023
-
[10]
Generating any changes in the noise domain,
Q. Liu, Y. Kuang, J. Yue, P. Ghamisi, W. Xie, and L. Fang, “Generating any changes in the noise domain,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 48, no. 3, pp. 3698–3713, 2026
2026
-
[11]
SpaceNet: A Remote Sensing Dataset and Challenge Series
A. Van Etten, D. Lindenbaum, and T. M. Bacastow, “Spacenet: A remote sensing dataset and challenge series,”arXiv preprint arXiv:1807.01232, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Sat2graph: Road graph extraction through graph-tensor encoding,
S. He, F. Bastani, S. Jagwani, M. Alizadeh, H. Balakrishnan, S. Chawla, M. M. Elshrif, S. Madden, and M. A. Sadeghi, “Sat2graph: Road graph extraction through graph-tensor encoding,” inProc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2020, pp. 51–67
2020
-
[13]
Acpv-net: All-class polygonal vectorization for seamless vector map generation from aerial imagery,
W. Jiao, H. Cheng, G. Vosselman, and C. Persello, “Acpv-net: All-class polygonal vectorization for seamless vector map generation from aerial imagery,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2026
2026
-
[14]
Segment anything model for road network graph extraction,
C. Hetang, H. Xue, C. Le, T. Yue, W. Wang, and Y. He, “Segment anything model for road network graph extraction,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2024, pp. 2556– 2566
2024
-
[15]
Topological map extraction from overhead images,
Z. Li, J. D. Wegner, and A. Lucchi, “Topological map extraction from overhead images,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2019, pp. 1715–1724
2019
-
[16]
Univector: Unified vector extraction via instance-geometry interaction,
Y. Yan, J. Yue, S. Xia, H. Sun, T. Ying, C. Wu, S. Lan, M. He, P. Ghamisi, and L. Fang, “Univector: Unified vector extraction via instance-geometry interaction,”arXiv preprint arXiv:2510.13234, 2025
-
[17]
Hisup: Accurate polygonal mapping of buildings in satellite imagery with hierarchical supervision,
M. Weiet al., “Hisup: Accurate polygonal mapping of buildings in satellite imagery with hierarchical supervision,”ISPRS J. Photogramm. Remote Sens., vol. 198, pp. 284–296, 2023
2023
-
[18]
P2pformer: A primitive-to-polygon method for regular building contour extraction from remote sensing images,
T. Zhang, S. Wei, Y. Zhou, M. Luo, W. Yu, and S. Ji, “P2pformer: A primitive-to-polygon method for regular building contour extraction from remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–12, 2024, art. no. 4414012
2024
-
[19]
Vectorllm: Human- like extraction of structured building contours via multimodal llms,
T. Zhang, S. Wei, S. Chen, W. Yu, M. Luo, and S. Ji, “Vectorllm: Human- like extraction of structured building contours via multimodal llms,”ISPRS J. Photogramm. Remote Sens., vol. 233, pp. 55–68, 2026
2026
-
[20]
Towards satellite image road graph extraction: A global-scale dataset and a novel method,
P. Yin, K. Li, X. Cao, J. Yao, L. Liu, X. Bai, F. Zhou, and D. Meng, “Towards satellite image road graph extraction: A global-scale dataset and a novel method,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 1527–1537
2025
-
[21]
Language is primarily a tool for communication rather than thought,
E. Fedorenko, S. T. Piantadosi, and E. A. F. Gibson, “Language is primarily a tool for communication rather than thought,”Nature, vol. 630, no. 8017, pp. 575–586, 2024
2024
-
[22]
Human-like systematic generalization through a meta-learning neural network,
B. M. Lake and M. Baroni, “Human-like systematic generalization through a meta-learning neural network,”Nature, vol. 623, no. 7985, pp. 115–121, 2023
2023
-
[23]
The geojson format,
H. Butler, M. Daly, A. Doyle, S. Gillies, S. Hagen, and T. Schaub, “The geojson format,” Internet Engineering Task Force, RFC 7946, August 2016
2016
-
[24]
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set,
S. Ji, S. Wei, and M. Lu, “Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 1, pp. 574–586, 2019
2019
-
[25]
Learning dual multi-scale manifold ranking for semantic segmentation of high-resolution images,
M. Zhang, X. Hu, L. Zhao, Y. Lv, M. Luo, and S. Pang, “Learning dual multi-scale manifold ranking for semantic segmentation of high-resolution images,”Remote Sens., vol. 9, no. 5, p. 500, 2017
2017
-
[26]
Land-cover classification with high-resolution remote sensing images using transferable deep models,
X.-Y. Tong, G.-S. Xia, Q. Lu, H. Shen, S. Li, S. You, and L. Zhang, “Land-cover classification with high-resolution remote sensing images using transferable deep models,”Remote Sens. Environ., vol. 237, p. 111322, 2020
2020
-
[27]
On the automatic quality assessment of annotated sample data for object extraction from remote sensing imagery,
Z. Zhang, Q. Zhang, X. Hu, M. Zhang, and D. Zhu, “On the automatic quality assessment of annotated sample data for object extraction from remote sensing imagery,”ISPRS J. Photogramm. Remote Sens., vol. 201, pp. 153–173, 2023
2023
-
[28]
Irsamap: Toward large-scale, high-resolution land cover map vectorization,
Y. Meng, L. Deng, Z. Xi, J. Chen, J. Chen, A. Yue, D. Liu, K. Li, C. Wang, K. Li, Y. Deng, and X. Sun, “Irsamap: Toward large-scale, high-resolution land cover map vectorization,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–19, 2025
2025
-
[29]
Deep learning for understanding satellite imagery: An experimental survey,
S. P. Mohanty, J. Czakon, K. A. Kaczmarek, A. Pyskir, P. Tarasiewicz, S. Kunwar, J. Rohrbach, D. Luo, M. Prasad, S. Fleer, J. P. G ¨opfert, A. Tandon, G. Mollard, N. Rayaprolu, M. Salath´e, and M. Schilling, “Deep learning for understanding satellite imagery: An experimental survey,” Front. Artif. Intell., vol. 3, p. 534696, 2020
2020
-
[30]
Microsoft coco: Common objects in context,
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2014, pp. 740–755
2014
-
[31]
isaid: A large-scale dataset for instance segmentation in aerial images,
S. W. Zamir, A. Arora, A. Gupta, S. Khan, G. Sun, F. Shahbaz Khan, F. Zhu, L. Shao, G.-S. Xia, and X. Bai, “isaid: A large-scale dataset for instance segmentation in aerial images,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2019, pp. 28–37
2019
-
[32]
Holitracer: Holistic vector- ization of geographic objects from large-size remote sensing imagery,
Y. Wang, B. Dang, W. Li, W. Chen, and Y. Li, “Holitracer: Holistic vector- ization of geographic objects from large-size remote sensing imagery,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2025, pp. 8482–8491
2025
-
[33]
Rngdet++: Road network graph detection by transformer with instance segmentation and multi- scale features enhancement,
Z. Xu, Y. Liu, Y. Sun, M. Liu, and L. Wang, “Rngdet++: Road network graph detection by transformer with instance segmentation and multi- scale features enhancement,”IEEE Robot. Autom. Lett., vol. 8, no. 5, pp. 2991–2998, 2023
2023
-
[34]
Beyond endpoints: Path-centric reasoning for vectorized off-road network extraction,
W. Guan, J. Mei, T. Shen, X. Wu, S. Wang, Chen Min, and Y. Hu, “Beyond endpoints: Path-centric reasoning for vectorized off-road network extraction,”arXiv preprint arXiv:2512.10416, 2025
-
[35]
Polyworld: Polygonal building extraction with graph neural networks in satellite images,
S. Zorzi, S. Bazrafkan, S. Habenschuss, and F. Fraundorfer, “Polyworld: Polygonal building extraction with graph neural networks in satellite images,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 1848–1857
2022
-
[36]
Topdig: Class- agnostic topological directional graph extraction from remote sensing images,
B. Yang, M. Zhang, Z. Zhang, Z. Zhang, and X. Hu, “Topdig: Class- agnostic topological directional graph extraction from remote sensing images,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 1265–1274
2023
-
[37]
Re: Polyworld-a graph neural network for polygonal scene parsing,
S. Zorzi and F. Fraundorfer, “Re: Polyworld-a graph neural network for polygonal scene parsing,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 16 762–16 771
2023
-
[38]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollar, and R. Girshick, “Segment anything,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 4015–4026
2023
-
[39]
Multimodal machine learning: A survey and taxonomy,
T. Baltru ˇsaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 2, pp. 423–443, 2019
2019
-
[40]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 8, pp. 5625–5644, 2024
2024
-
[41]
X2-vlm: All- in-one pre-trained model for vision-language tasks,
Y. Zeng, X. Zhang, H. Li, J. Wang, J. Zhang, and W. Zhou, “X2-vlm: All- in-one pre-trained model for vision-language tasks,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 5, pp. 3156–3168, 2024
2024
-
[42]
Skysense: A multi-modal remote sensing foundation model towards uni- versal interpretation for earth observation imagery,
X. Guo, J. Lao, B. Dang, Y. Zhang, L. Yu, L. Ru, L. Zhong, Z. Huang, K. Wu, D. Hu, H. He, J. Wang, J. Chen, M. Yang, Y. Zhang, and Y. Li, “Skysense: A multi-modal remote sensing foundation model towards uni- versal interpretation for earth observation imagery,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 27 672–27 683
2024
-
[43]
Skysense v2: A unified foundation model for multi-modal remote sensing,
Y. Zhang, L. Ru, K. Wu, L. Yu, L. Liang, Y. Li, and J. Chen, “Skysense v2: A unified foundation model for multi-modal remote sensing,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2025, pp. 9136–9146
2025
-
[44]
A survey on open-vocabulary detection and segmentation: Past, present, and future,
C. Zhu and L. Chen, “A survey on open-vocabulary detection and segmentation: Past, present, and future,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 8954–8975, 2024
2024
-
[45]
Geochat: Grounded large vision-language model for remote sensing,
K. Kuckreja, M. S. Danish, M. Naseer, A. Das, S. Khan, and F. S. Khan, “Geochat: Grounded large vision-language model for remote sensing,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 27 831–27 840
2024
-
[46]
Geollava- 8k: Scaling remote-sensing multimodal large language models to 8k resolution,
F. Wang, M. Chen, Y. Li, D. Wang, H. Wang, Z. Guo, Z. Wang, B. Shan, L. Long, Y. Wang, H. Wang, W. Yang, B. Du, and J. Zhang, “Geollava- 8k: Scaling remote-sensing multimodal large language models to 8k resolution,” inAdv. Neural Inf. Process. Syst. (NeurIPS), vol. 38, 2025
2025
-
[47]
Look where it matters: Training- free ultra-hr remote sensing vqa via adaptive zoom search,
Y. Zhou, C. Jiang, C. Yuan, and J. Li, “Look where it matters: Training- free ultra-hr remote sensing vqa via adaptive zoom search,”arXiv preprint arXiv:2511.20460, 2025
-
[48]
Segearth-ov: Towards training-free open-vocabulary segmentation for remote sensing images,
K. Li, R. Liu, X. Cao, X. Bai, F. Zhou, D. Meng, and Z. Wang, “Segearth-ov: Towards training-free open-vocabulary segmentation for remote sensing images,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 10 545–10 556
2025
-
[49]
Openrsd: Towards open-prompts for object detection in remote sensing images,
Z. Huang, Y. Feng, Z. Liu, S. Yang, Q. Liu, and Y. Wang, “Openrsd: Towards open-prompts for object detection in remote sensing images,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2025, pp. 8384–8394. JOURNAL OF LATEX CLASS FILES, 2026 15
2025
-
[50]
Rsgpt: A remote sensing vision language model and benchmark,
Y. Hu, J. Yuan, C. Wen, X. Lu, Y. Liu, and X. Li, “Rsgpt: A remote sensing vision language model and benchmark,”ISPRS J. Photogramm. Remote Sens., vol. 224, pp. 272–286, 2025
2025
-
[51]
VHM: Versatile and honest vision language model for remote sensing image analysis,
C. Pang, X. Weng, J. Wu, J. Li, Y. Liu, J. Sun, W. Li, S. Wang, L. Feng, G.-S. Xia, and C. He, “VHM: Versatile and honest vision language model for remote sensing image analysis,”Proc. AAAI Conf. Artif. Intell., vol. 39, no. 6, pp. 6381–6388, 2025
2025
-
[52]
Remoteclip: A vision language foundation model for remote sensing,
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “Remoteclip: A vision language foundation model for remote sensing,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–16, 2024
2024
-
[53]
SegEarth-OV3: Exploring SAM 3 for Open-Vocabulary Semantic Segmentation in Remote Sensing Images
K. Li, S. Zhang, Y. Wang, Y. Deng, Z. Wang, D. Meng, and X. Cao, “Segearth-ov3: Exploring sam 3 for open-vocabulary semantic segmenta- tion in remote sensing images,”arXiv preprint arXiv:2512.08730, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
UniGeoSeg: Towards Unified Open-World Segmentation for Geospatial Scenes
S. Ni, D. Wang, H. Chen, H. Guo, N. Zhang, and J. Zhang, “Unigeoseg: Towards unified open-world segmentation for geospatial scenes,”arXiv preprint arXiv:2511.23332, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Multimodal learning with transformers: A survey,
P. Xu, X. Zhu, and D. A. Clifton, “Multimodal learning with transformers: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 10, pp. 12 113–12 132, 2023
2023
-
[56]
Renaissance: A survey into ai text-to-image generation in the era of large model,
F. Bie, Y. Yang, Z. Zhou, A. Ghanem, M. Zhang, Z. Yao, X. Wu, C. Holmes, P. Golnari, D. Clifton, Y. He, D. Tao, S. L. Song, and S. Song, “Renaissance: A survey into ai text-to-image generation in the era of large model,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 3, pp. 2212– 2231, 2025
2025
-
[57]
Prompting is program- ming: A query language for large language models,
L. Beurer-Kellner, M. Fischer, and M. Vechev, “Prompting is program- ming: A query language for large language models,”Proc. ACM Program. Lang., vol. 7, no. PLDI, pp. 1946–1969, 2023
1946
-
[58]
Picard: Parsing incrementally for constrained auto-regressive decoding from language models,
T. Scholak, N. Schucher, and D. Bahdanau, “Picard: Parsing incrementally for constrained auto-regressive decoding from language models,” inProc. Conf. Empirical Methods Natural Lang. Process. (EMNLP). Association for Computational Linguistics, 2021, pp. 9895–9901
2021
-
[59]
Competition-level code generation with alphacode,
Y. Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lago, T. H´ ubert, P. Choy, C. de Masson d’ Autume, I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. Suther- land Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals, “Competition-le...
2022
-
[60]
Svgdreamer++: Advancing editability and diversity in text-guided svg generation,
X. Xing, Q. Yu, C. Wang, H. Zhou, J. Zhang, and D. Xu, “Svgdreamer++: Advancing editability and diversity in text-guided svg generation,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 7, pp. 5397–5413, 2025
2025
-
[61]
Deepcad: A deep generative network for computer-aided design models,
R. Wu, C. Xiao, and C. Zheng, “Deepcad: A deep generative network for computer-aided design models,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 6752–6762
2021
-
[62]
Skexgen: Autoregressive generation of cad construction sequences with disentangled codebooks,
X. Xu, K. D. D. Willis, J. G. Lambourne, C.-Y. Cheng, P. K. Jayaraman, and Y. Furukawa, “Skexgen: Autoregressive generation of cad construction sequences with disentangled codebooks,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2022, pp. 24 698–24 724
2022
-
[63]
Deepsvg: A hierarchical generative network for vector graphics animation,
A. Carlier, M. Danelljan, A. Alahi, and R. Timofte, “Deepsvg: A hierarchical generative network for vector graphics animation,” inAdv. Neural Inf. Process. Syst. (NeurIPS), vol. 33, 2020, pp. 16 351–16 361
2020
-
[64]
A comprehensive survey of scene graphs: Generation and application,
X. Chang, P. Ren, P. Xu, Z. Li, X. Chen, and A. G. Hauptmann, “A comprehensive survey of scene graphs: Generation and application,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 1, pp. 1–26, 2023
2023
-
[65]
arXiv preprint arXiv:2506.07491 , year=
Y. Mao, J. Zhong, C. Fang, J. Zheng, R. Tang, H. Zhu, P. Tan, and Z. Zhou, “Spatiallm: Training large language models for structured indoor modeling,”arXiv preprint arXiv:2506.07491, 2025
-
[66]
S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y. Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y. Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang, Q....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. K. Li, Y. Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Rsground-r1: Rethinking remote sensing visual grounding through spatial reasoning,
S. Huang, S. He, and B. Wen, “Rsground-r1: Rethinking remote sensing visual grounding through spatial reasoning,”arXiv preprint arXiv:2601.21634, 2026
-
[69]
Towards pixel-level vlm perception via simple points prediction,
T. Song, H. Lu, H. Yang, L. Sui, H. Wu, Z. Zhou, Z. Huang, Y. Bao, Y. Charles, X. Zhou, and L. Wang, “Towards pixel-level vlm perception via simple points prediction,”arXiv preprint arXiv:2601.19228, 2026
-
[70]
Evaluation of automatic road extraction,
C. Heipke, H. Mayer, C. Wiedemann, and O. Jamet, “Evaluation of automatic road extraction,” inInt. Arch. Photogramm. Remote Sens., vol. 32, no. 3-4W2, 1997, pp. 151–160
1997
-
[71]
Comparing images using the hausdorff distance,
D. P. Huttenlocher, G. A. Klanderman, and W. J. Rucklidge, “Comparing images using the hausdorff distance,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 15, no. 9, pp. 850–863, 1993
1993
-
[72]
A metric for polygon comparison and building extraction evaluation,
J. Avbelj, R. M¨ uller, and R. Bamler, “A metric for polygon comparison and building extraction evaluation,”IEEE Geosci. Remote Sens. Lett., vol. 12, no. 1, pp. 170–174, 2015
2015
-
[73]
Gemini 3.1 Flash-Lite,
Google DeepMind, “Gemini 3.1 Flash-Lite,” 2026
2026
-
[74]
Supported Models and Capabilities Overview: Qwen3.5- Plus,
Alibaba Cloud, “Supported Models and Capabilities Overview: Qwen3.5- Plus,” 2026
2026
-
[75]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2022
2022
-
[76]
Mask r-cnn,
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 2961–2969
2017
-
[77]
Masked- attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked- attention mask transformer for universal image segmentation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 1290–1299
2022
-
[78]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y.-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V. Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. R¨adle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y. Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Doll ´ar, N. Ravi, K. Sae...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.