SPACR: Single-Pass Adaptive Training of Uncertainty-Aware Conformal Regressors
Pith reviewed 2026-06-27 14:02 UTC · model grok-4.3
The pith
SPACR trains a single regressor with a differentiable loss so one model produces valid conformal intervals at any confidence level without data splits or retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPACR is a training procedure for regressors that uses a differentiable loss to enforce conformal validity guarantees directly inside gradient-based optimization. The procedure jointly minimizes interval width and maintains coverage without requiring a predefined confidence level or a separate calibration set during training, so that a single trained model supplies valid prediction intervals at any desired confidence level during inference.
What carries the argument
SPACR's differentiable loss that adapts interval construction on the fly during gradient descent to satisfy conformal coverage while minimizing width.
If this is right
- A single trained model supplies valid intervals at every confidence level without retraining.
- No data splitting between training and calibration sets is required.
- Computational cost drops because multiple confidence levels no longer demand separate models.
- Average interval widths decrease while coverage guarantees remain intact.
- Coverage-efficiency trade-offs improve relative to post-hoc conformal prediction and DOICR.
Where Pith is reading between the lines
- If the loss successfully embeds validity, conformal-style guarantees could be added to online or streaming regression pipelines without periodic recalibration.
- The method might reduce the data requirements of conformal approaches in small-sample regimes where splitting is expensive.
- End-to-end learned systems could incorporate uncertainty bounds without a separate post-processing stage.
- Similar differentiable losses could be explored for classification or structured prediction tasks that currently rely on post-hoc conformal methods.
Load-bearing premise
A loss can be written that remains differentiable yet still forces the trained model to satisfy the conformal coverage guarantee on unseen data without any later calibration step.
What would settle it
Train a SPACR model on a dataset, then measure empirical coverage of its prediction intervals on a fresh test set at several nominal confidence levels; coverage falling below the nominal rate at any level would falsify the validity claim.
Figures

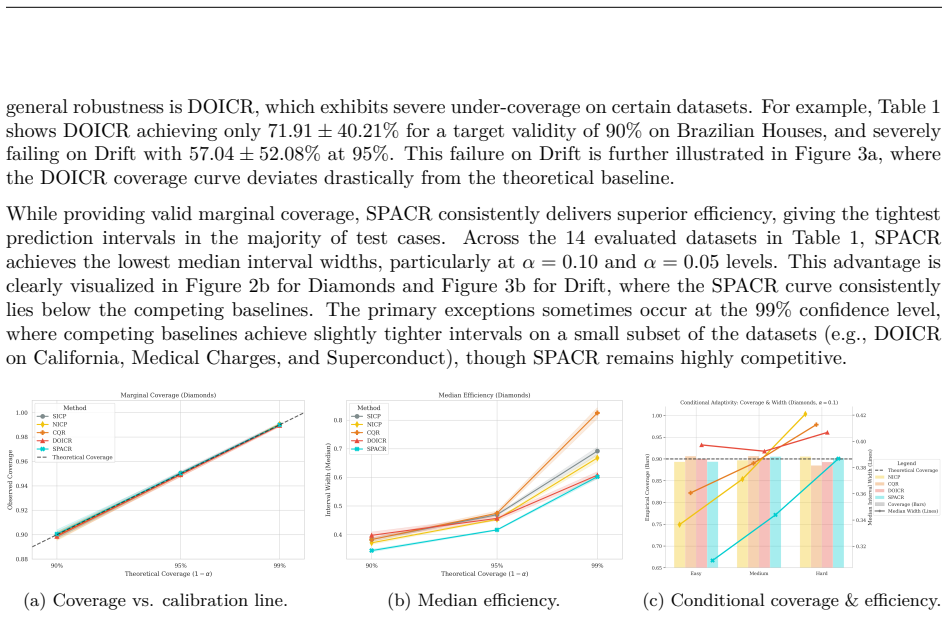
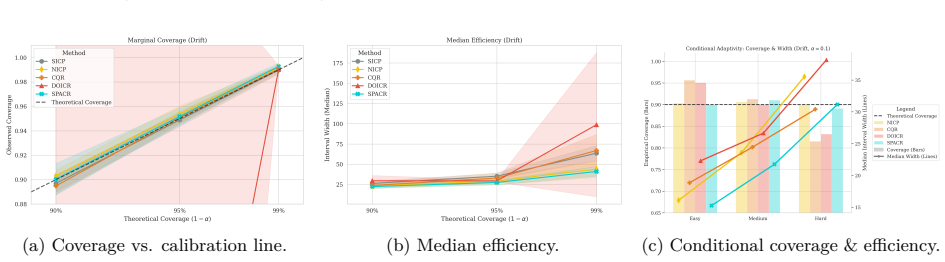
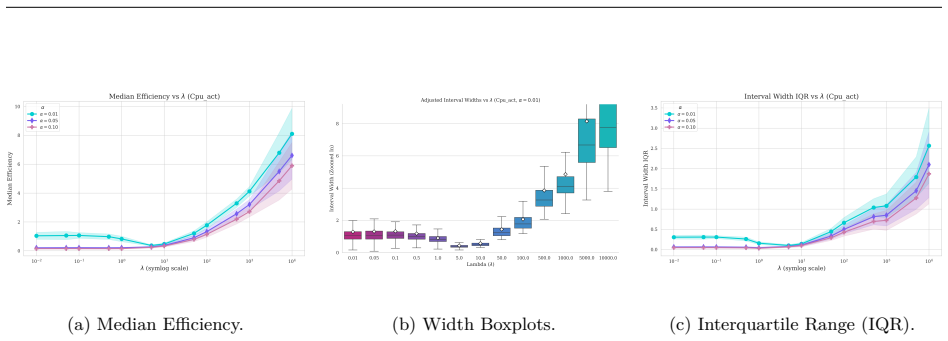
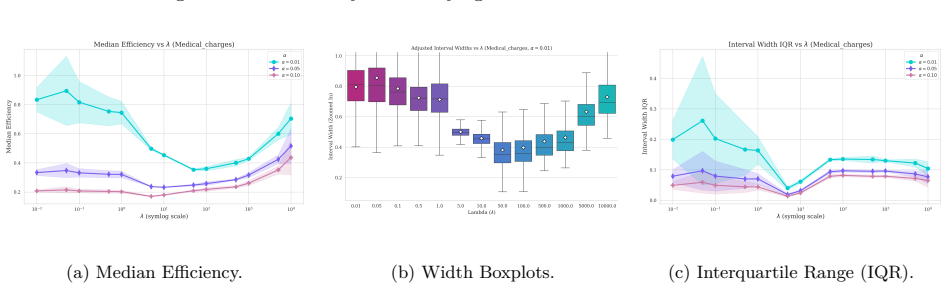
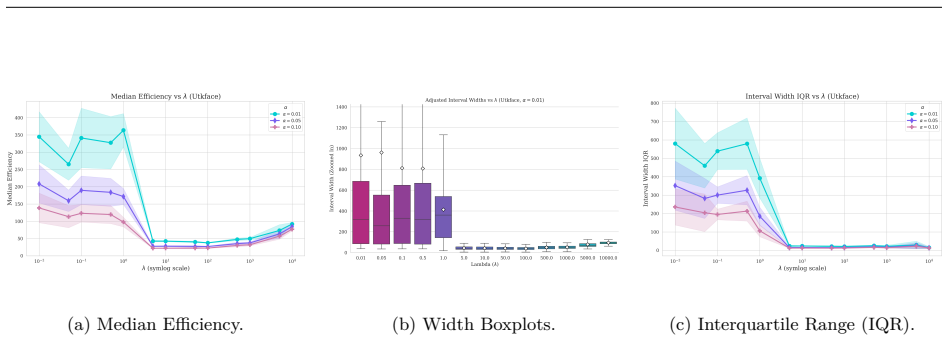

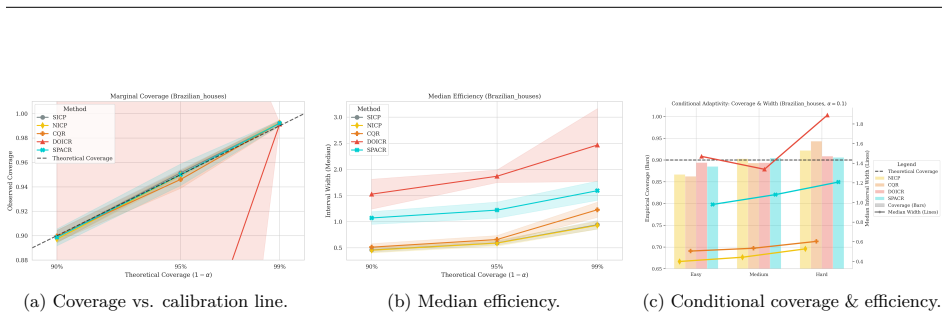
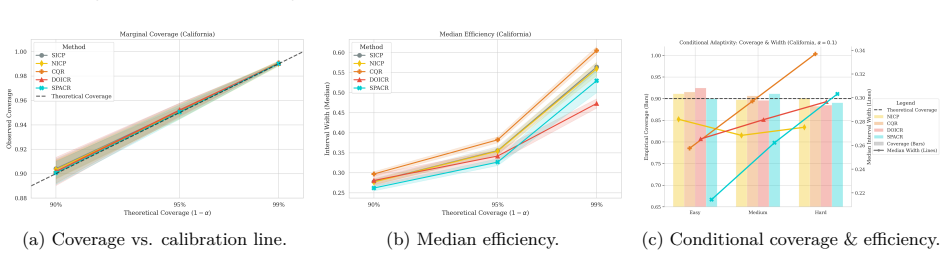
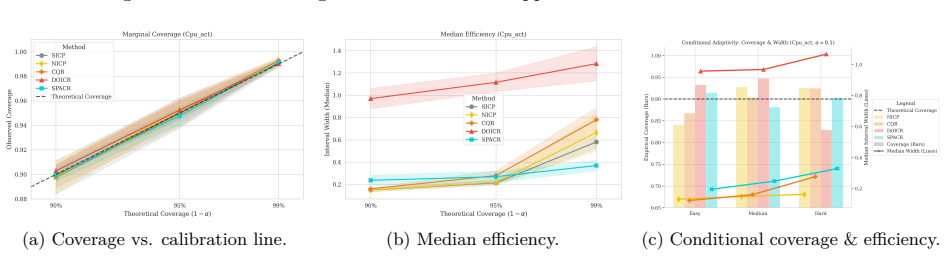
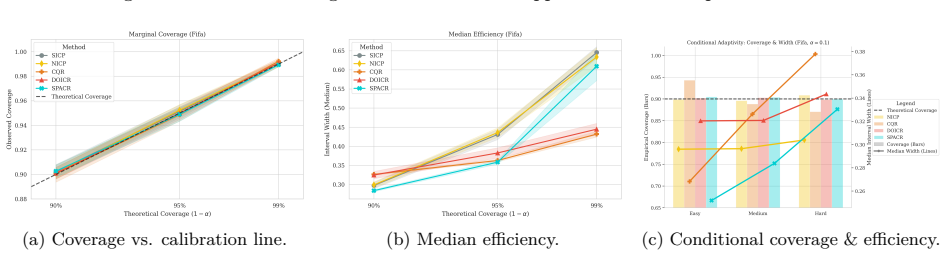
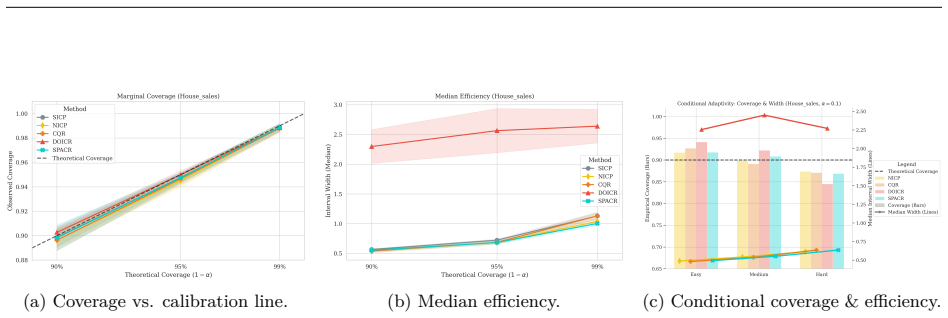
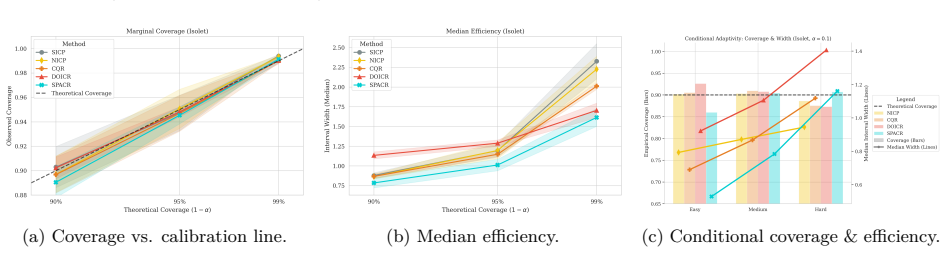
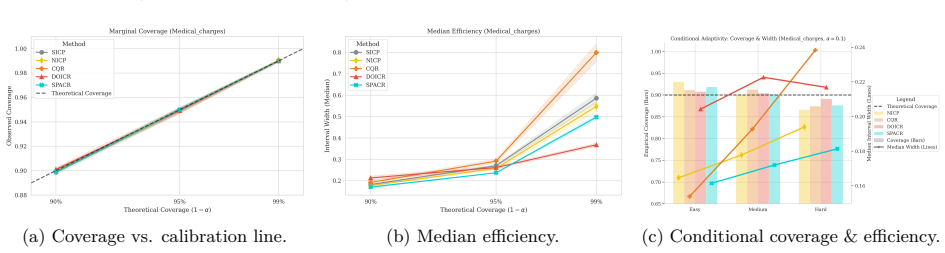
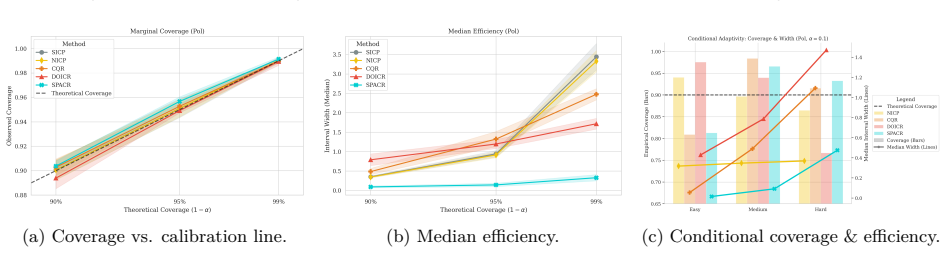
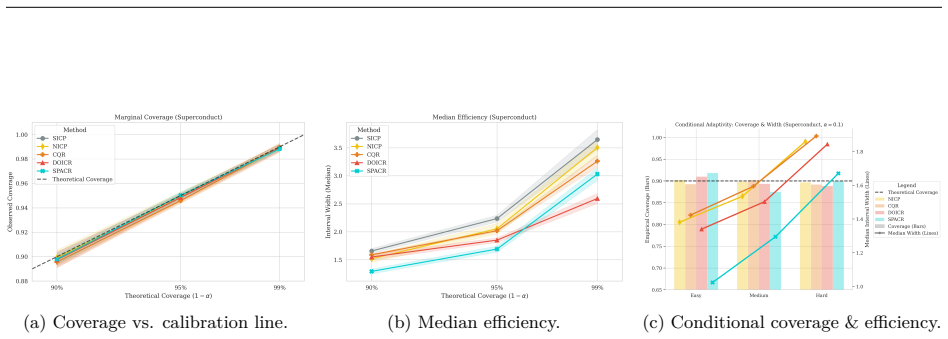
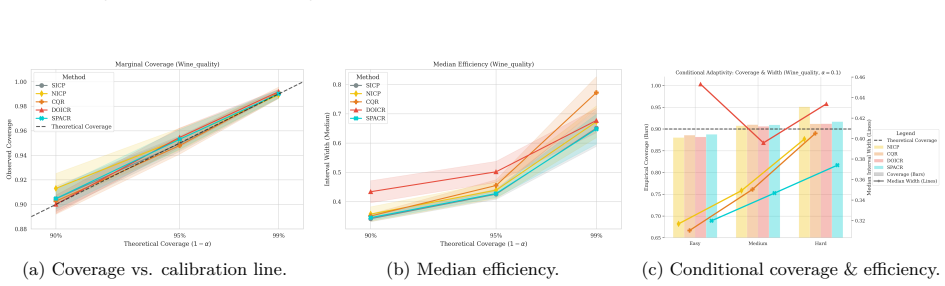
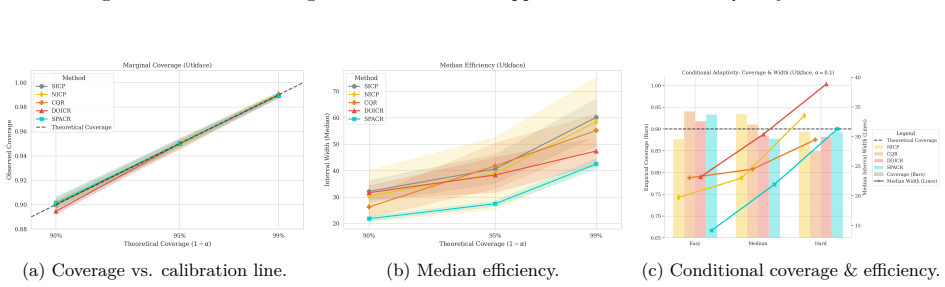
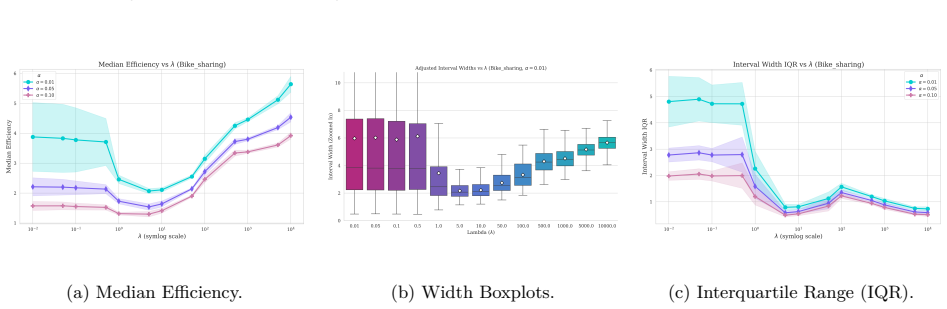
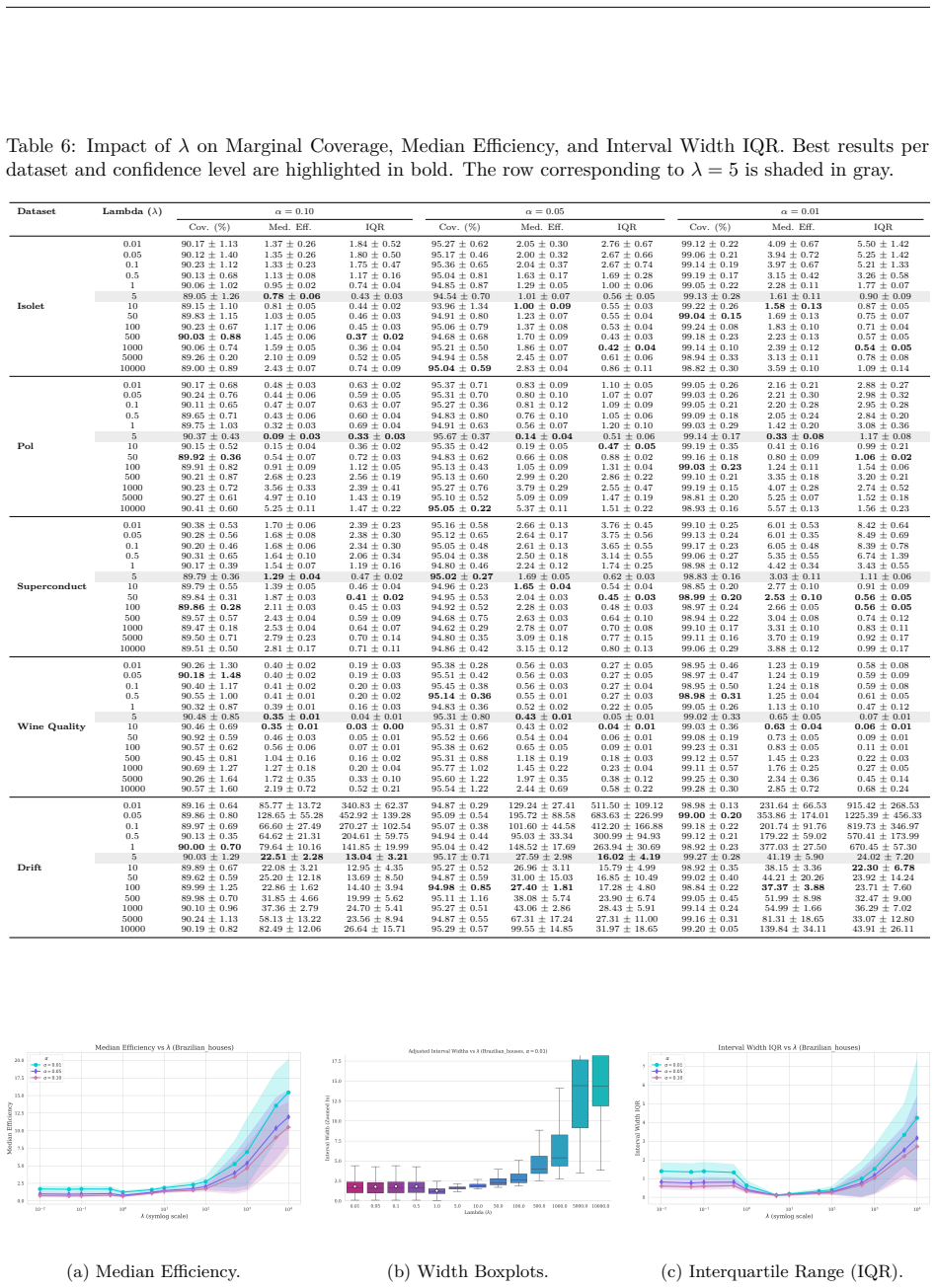
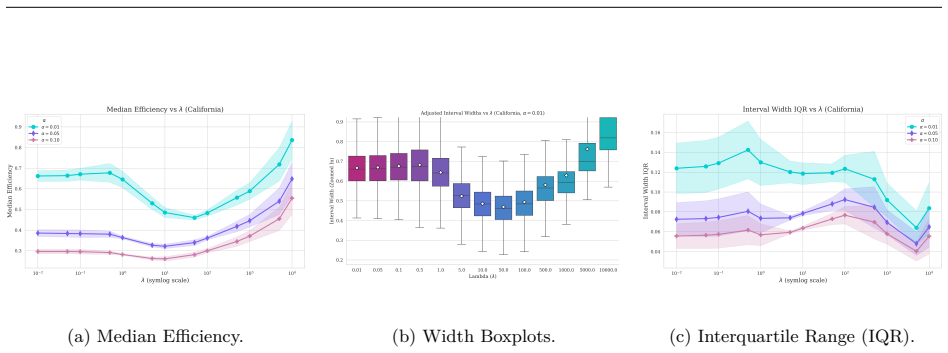
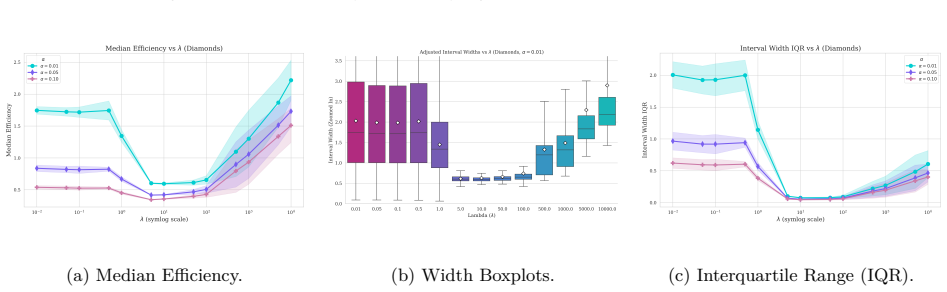
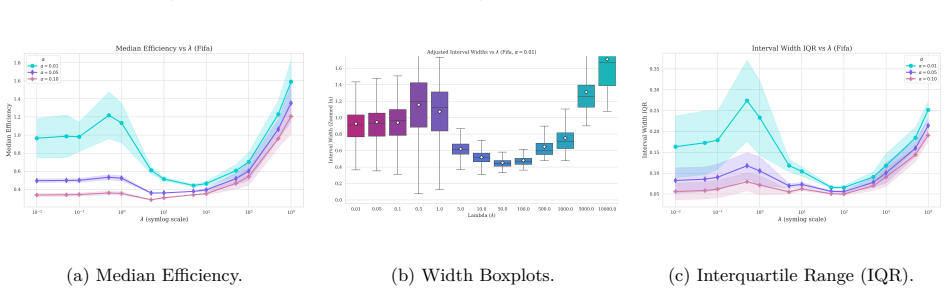
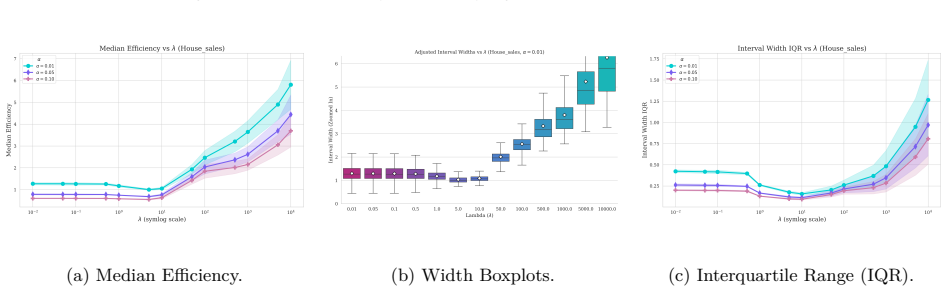
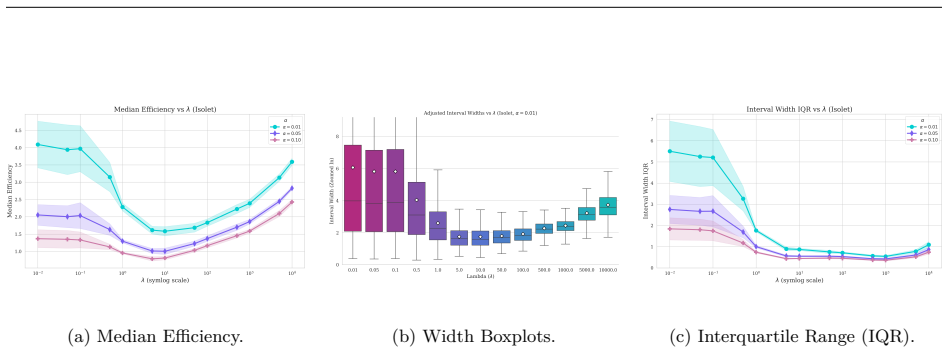
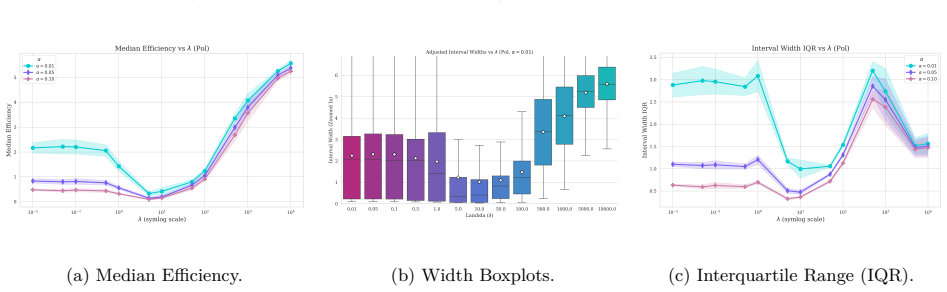
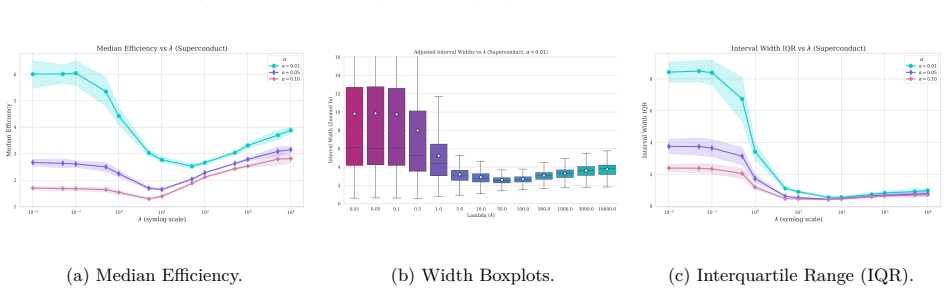
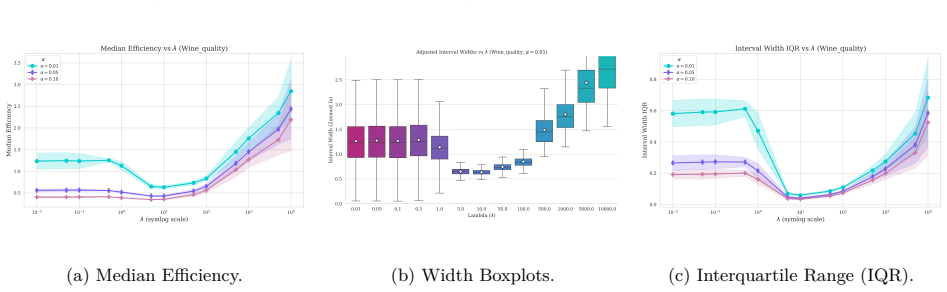
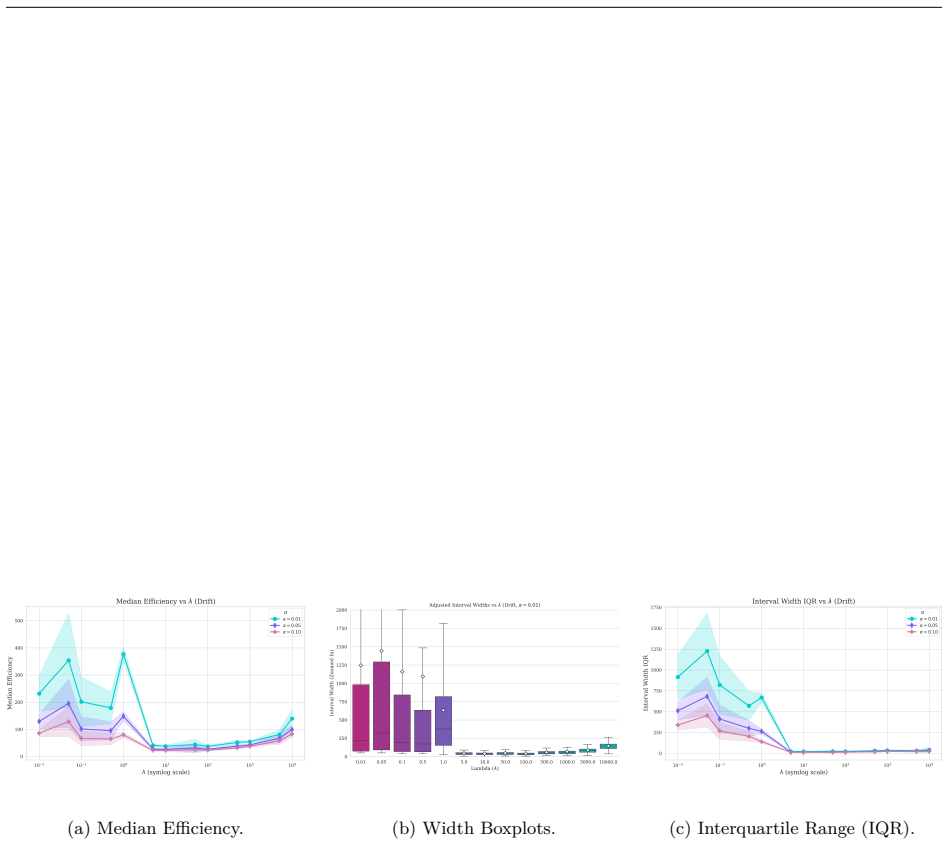
read the original abstract
Conformal Prediction (CP) provides robust uncertainty guarantees for predictive models, but is typically applied post hoc, which misaligns model training with the conformal goal of producing efficient (i.e, narrow) intervals. We propose SPACR (Single-Pass Adaptive Conformal Regressor), a novel method for directly training uncertainty-aware regressors within a differentiable loss. SPACR jointly optimizes efficiency and validity without batch-splitting or a predefined confidence levels during training. As a result, a single SPACR model yields valid prediction intervals at multiple confidence levels during inference, avoiding the costly retraining required by methods like DOICR. Experiments on diverse datasets show that SPACR consistently gives tighter intervals and better coverage-efficiency trade-offs compared to standard CP and DOICR, while significantly reducing computational costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SPACR, a method for single-pass training of uncertainty-aware regressors via a differentiable loss that jointly optimizes interval efficiency and validity without batch splitting or fixed confidence levels during training; a single trained model then produces valid prediction intervals at arbitrary confidence levels at inference time, with claimed improvements in coverage-efficiency trade-offs and reduced compute relative to post-hoc CP and DOICR.
Significance. If the finite-sample distribution-free validity guarantee is preserved while allowing end-to-end optimization, the approach would meaningfully advance conformal prediction by removing the usual separation between model fitting and calibration, lowering the cost of multi-level inference, and potentially yielding tighter intervals in practice.
major comments (2)
- [Method / loss definition (around the differentiable quantile construction)] The central claim that SPACR delivers exact finite-sample conformal coverage rests on the differentiable loss enforcing the same exchangeability property that standard CP relies upon; however, because the nonconformity scores and the effective quantile are both functions of the same training data and model parameters, the exchangeability argument no longer applies directly, and no alternative finite-sample guarantee is supplied.
- [Experiments / results tables] Experiments are reported to show valid coverage and superior trade-offs, yet without an independent calibration set or explicit verification that coverage remains at or above 1-α for every α after training, the results are consistent with heuristic interval regression rather than conformal validity; a table or figure showing empirical coverage across multiple α on held-out data with exact counts would be required to support the claim.
minor comments (2)
- [Inference procedure] Notation for the multi-level inference procedure is introduced without an explicit algorithm box or pseudocode, making it difficult to verify that a single forward pass truly suffices for arbitrary α.
- [Experimental setup] Dataset details (sizes, splits, preprocessing) and hyper-parameter choices for the baselines (standard CP, DOICR) are not fully specified, hindering reproducibility of the reported efficiency gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the theoretical positioning and empirical support for SPACR. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Method / loss definition (around the differentiable quantile construction)] The central claim that SPACR delivers exact finite-sample conformal coverage rests on the differentiable loss enforcing the same exchangeability property that standard CP relies upon; however, because the nonconformity scores and the effective quantile are both functions of the same training data and model parameters, the exchangeability argument no longer applies directly, and no alternative finite-sample guarantee is supplied.
Authors: We agree that the standard finite-sample exchangeability argument does not apply, as the nonconformity scores are produced by a model whose parameters are optimized on the same data used to define the quantile. No alternative finite-sample guarantee is provided in the manuscript. In the revision we will explicitly state that SPACR does not claim exact finite-sample, distribution-free coverage and will instead describe the method as producing empirically valid intervals via the joint differentiable loss. We will revise the abstract, introduction, and method sections accordingly to remove any implication of an exact conformal guarantee while retaining the computational and optimization contributions. revision: yes
-
Referee: [Experiments / results tables] Experiments are reported to show valid coverage and superior trade-offs, yet without an independent calibration set or explicit verification that coverage remains at or above 1-α for every α after training, the results are consistent with heuristic interval regression rather than conformal validity; a table or figure showing empirical coverage across multiple α on held-out data with exact counts would be required to support the claim.
Authors: We accept that the current experimental presentation lacks the explicit per-α coverage counts needed to substantiate the validity claims. In the revised manuscript we will add a dedicated table (or supplementary figure) reporting empirical coverage on a held-out test set for several values of α, including the exact number of covered and uncovered samples so that readers can verify whether coverage meets or exceeds the nominal 1-α level. This table will use data completely separate from training and will be referenced in the experimental section. revision: yes
Circularity Check
No circularity: SPACR loss is an independent differentiable construction
full rationale
The paper introduces a novel differentiable loss that jointly targets efficiency and validity during training, without batch splitting or fixed confidence levels. No step in the provided abstract or description reduces a claimed validity guarantee or performance prediction to a fitted parameter or self-referential definition by construction. The central claim rests on the design of the loss and subsequent empirical evaluation rather than tautological renaming or self-citation chains. Standard CP exchangeability arguments are not invoked as load-bearing within the training procedure itself, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Statistical Planning and Inference , volume=
Online learning for quantile regression and support vector regression , author=. Journal of Statistical Planning and Inference , volume=. 2012 , publisher=
2012
-
[2]
Advances in neural information processing systems , volume=
Conformalized quantile regression , author=. Advances in neural information processing systems , volume=
-
[3]
IEEE transactions on pattern analysis and machine intelligence , volume=
Support vector machine classifier with pinball loss , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[4]
Advances in neural information processing systems , volume=
Why do tree-based models still outperform deep learning on typical tabular data? , author=. Advances in neural information processing systems , volume=
-
[5]
Proceedings of the AAAI conference on artificial intelligence , volume=
Robust loss functions under label noise for deep neural networks , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A general and adaptive robust loss function , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
Advances in neural information processing systems , volume=
Support vector method for function approximation, regression estimation and signal processing , author=. Advances in neural information processing systems , volume=
-
[8]
Journal of Healthcare Informatics Research , volume=
Conformal prediction in clinical medical sciences , author=. Journal of Healthcare Informatics Research , volume=. 2022 , publisher=
2022
-
[9]
1996 , publisher=
The DELVE manual , author=. 1996 , publisher=
1996
-
[10]
Computational Materials Science , volume=
A data-driven statistical model for predicting the critical temperature of a superconductor , author=. Computational Materials Science , volume=. 2018 , publisher=
2018
-
[11]
2018 , howpublished =
Hamidieh, Kam , title =. 2018 , howpublished =
2018
-
[12]
Statistics & Probability Letters , volume=
Sparse spatial autoregressions , author=. Statistics & Probability Letters , volume=. 1997 , publisher=
1997
-
[13]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[14]
Information and Inference: A Journal of the IMA , volume=
The limits of distribution-free conditional predictive inference , author=. Information and Inference: A Journal of the IMA , volume=. 2021 , publisher=
2021
-
[15]
Advances in neural information processing systems , volume=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. Advances in neural information processing systems , volume=
-
[16]
arXiv preprint arXiv:2510.08748 , year=
Conformal Risk Training: End-to-End Optimization of Conformal Risk Control , author=. arXiv preprint arXiv:2510.08748 , year=
-
[17]
European Conference on Computer Vision , pages=
Get Your Embedding Space in Order: Domain-Adaptive Regression for Forest Monitoring , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[18]
Pattern Recognition , booktitle=
Copula-based conformal prediction for multi-target regression , author=. Pattern Recognition , booktitle=. 2021 , publisher=
2021
-
[19]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Age progression/regression by conditional adversarial autoencoder , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[20]
Computers in Biology and Medicine , volume=
Application of uncertainty quantification to artificial intelligence in healthcare: A review of last decade (2013--2023) , author=. Computers in Biology and Medicine , volume=. 2023 , publisher=
2013
-
[21]
Proceedings of Machine Learning Research , volume=
Copula-based conformal prediction for object detection: a more efficient approach , author=. Proceedings of Machine Learning Research , volume=
-
[22]
2020 IEEE international conference on robotics and automation (ICRA) , pages=
Uncertainty quantification with statistical guarantees in end-to-end autonomous driving control , author=. 2020 IEEE international conference on robotics and automation (ICRA) , pages=. 2020 , organization=
2020
-
[23]
Applied Mathematical Modelling , volume=
Novel method for a posteriori uncertainty quantification in wildland fire spread simulation , author=. Applied Mathematical Modelling , volume=. 2021 , publisher=
2021
-
[24]
Journal of Hydrology , volume=
Bayesian flood forecasting methods: A review , author=. Journal of Hydrology , volume=. 2017 , publisher=
2017
-
[25]
2005 , publisher=
Algorithmic learning in a random world , author=. 2005 , publisher=
2005
-
[26]
2008 , publisher=
Inductive conformal prediction: Theory and application to neural networks , author=. 2008 , publisher=
2008
-
[27]
Neural Networks , volume=
Reliable prediction intervals with regression neural networks , author=. Neural Networks , volume=. 2011 , publisher=
2011
-
[28]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
A gentle introduction to conformal prediction and distribution-free uncertainty quantification , author=. arXiv preprint arXiv:2107.07511 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Conformal and Probabilistic Prediction and Applications , pages=
Training conformal predictors , author=. Conformal and Probabilistic Prediction and Applications , pages=. 2020 , organization=
2020
-
[30]
arXiv preprint arXiv:2105.11255 , year=
Optimized conformal classification using gradient descent approximation , author=. arXiv preprint arXiv:2105.11255 , year=
-
[31]
International Conference on Learning Representations , year =
Stutz, David and Dvijotham, Krishnamurthy and Cemgil, Ali Taylan and Doucet, Arnaud , title =. International Conference on Learning Representations , year =
-
[32]
Neural Networks , volume=
Reliable prediction intervals with directly optimized inductive conformal regression for deep learning , author=. Neural Networks , volume=. 2023 , publisher=
2023
-
[33]
Journal of Artificial Intelligence Research , volume=
Regression conformal prediction with nearest neighbours , author=. Journal of Artificial Intelligence Research , volume=
-
[34]
European Conference on Machine Learning , pages=
Inductive confidence machines for regression , author=. European Conference on Machine Learning , pages=. 2002 , organization=
2002
-
[35]
Proceedings of the IASTED International Conference on Artificial Intelligence and Applications (AIA 2008) , pages=
Normalized nonconformity measures for regression conformal prediction , author=. Proceedings of the IASTED International Conference on Artificial Intelligence and Applications (AIA 2008) , pages=
2008
-
[36]
Journal of biomedical informatics , volume=
Targeting the uncertainty of predictions at patient-level using an ensemble of classifiers coupled with calibration methods, Venn-ABERS, and Conformal Predictors: A case study in AD , author=. Journal of biomedical informatics , volume=. 2020 , publisher=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.