Pushing the Limits of LLM Tool Calling via Experiential Knowledge Integration and Activation
Pith reviewed 2026-06-27 13:22 UTC · model grok-4.3
The pith
The KATE framework improves LLM multi-step tool execution by integrating instance-level experiential knowledge, reasoning-width expansion, and knowledge-aware training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present a systematic study on how knowledge influences tool-use performance, covering acquisition, activation, and internalization. Simple instance-level knowledge provides strong and reliable gains, while abstract intent-level knowledge offers limited benefits. Expanding reasoning width via parallel sampling with aggregation activates latent knowledge more effectively than deepening single paths. Post-training with knowledge-augmented data further improves performance, with reinforcement learning outperforming supervised fine-tuning. The resulting KATE framework integrates these elements and demonstrates consistent and substantial improvements over strong baselines across model scales on
What carries the argument
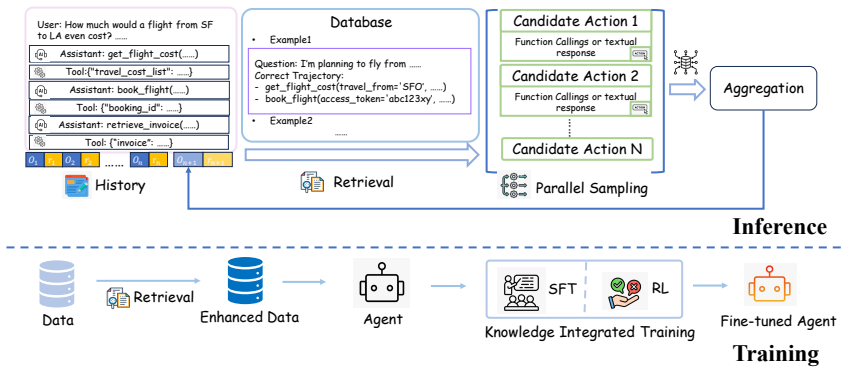
The Knowledge-Augmented Tool Execution (KATE) framework that integrates experiential knowledge acquisition, reasoning-width-expanded inference through parallel sampling and aggregation, and knowledge-aware training with reinforcement learning.
If this is right
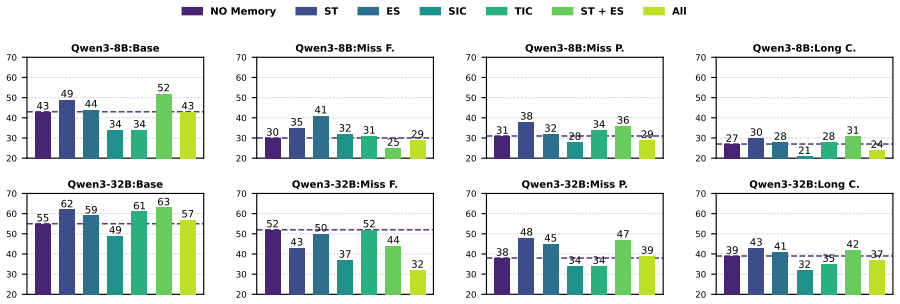
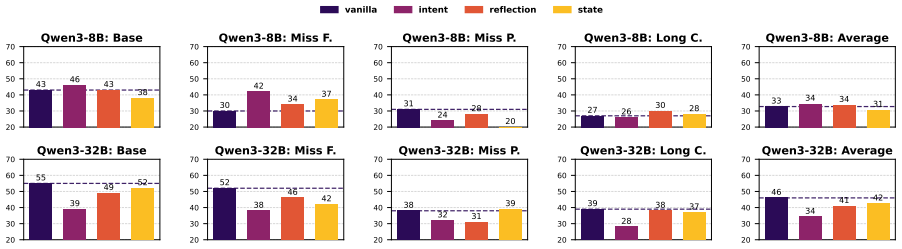
- Simple instance-level experiential knowledge yields strong and reliable gains in tool-calling performance.
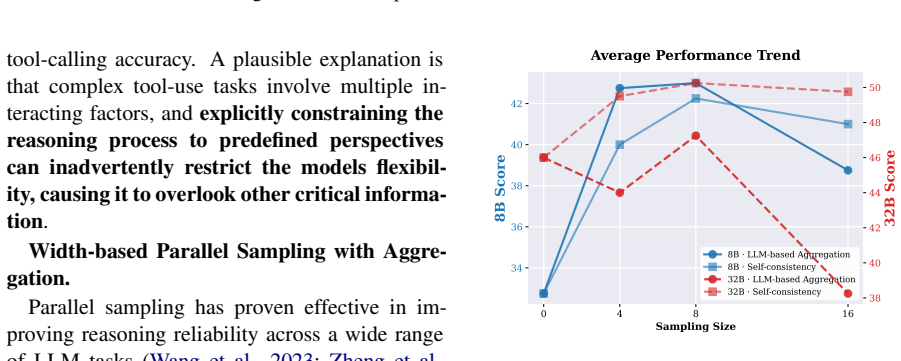
- Expanding reasoning width by parallel sampling with aggregation activates latent experiential knowledge more effectively than expanding the depth of a single reasoning chain.
- Knowledge-augmented post-training with reinforcement learning outperforms supervised fine-tuning for improving tool-use capabilities.
- The integrated KATE framework produces consistent and substantial improvements over strong baselines across model scales on BFCL-V3 and AppWorld.
Where Pith is reading between the lines
- Curating high-quality sets of instance-level tool examples could become a practical, scalable route to stronger agent performance without larger models.
- The preference for reasoning width over depth implies that diversity among generated paths matters more than sequential length for surfacing stored knowledge during tool use.
- The same knowledge-acquisition and activation pattern may extend to other multi-step agent tasks such as web navigation or code generation.
- Combining KATE-style methods with retrieval mechanisms could test whether external knowledge sources amplify the observed internalization effects.
Load-bearing premise
That performance differences are attributable to the specific knowledge forms and activation methods rather than to differences in total inference compute, data selection, or unstated implementation details.
What would settle it
A controlled comparison in which a baseline matches KATE's total inference compute and training data volume but omits the instance-level knowledge, width expansion, and knowledge-augmented RL components, yet shows equivalent gains on BFCL-V3, would falsify the attribution.
Figures
read the original abstract
Large language models (LLMs) rely on tool use to act as autonomous agents, yet often fail in multi-step execution due to insufficient tool-related knowledge and ineffective knowledge activation. Therefore, we present a systematic study on how knowledge influences tool-use performance, covering the stages of knowledge acquisition, activation, and internalization. In the knowledge acquisition stage, we acquire and evaluate various forms of experiential knowledge, and our analysis shows that simple instance-level knowledge can already provide strong and reliable gains, while abstract intent-level knowledge offers limited benefits. At inference time, to activate knowledge, we find that prompting LLM to expand the depth of reasoning yields diminishing returns, whereas expanding the width of reasoning by parallel sampling with aggregation more effectively activates latent experiential knowledge. At training time, for knowledge internalization, post-training with knowledge-augmented data further improves performance, with reinforcement learning outperforming supervised fine-tuning. Based on these insights, we propose the Knowledge-Augmented Tool Execution (KATE), a knowledge-augmented tool execution framework that integrates experiential knowledge with reasoning-width-expanded inference and knowledge-aware training. Experiments on BFCL-V3 and AppWorld demonstrate consistent and substantial improvements over strong baselines across model scales. Our Code is available at https://github.com/hypasd-art/KATE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a systematic study of how experiential knowledge affects LLM tool-use performance across acquisition, activation, and internalization stages. It evaluates different knowledge forms, finds that width-expanded parallel sampling at inference activates knowledge more effectively than depth expansion, and shows that knowledge-augmented post-training (especially RL) improves results. These insights are combined into the KATE framework, which is reported to yield consistent and substantial gains over strong baselines on BFCL-V3 and AppWorld across model scales. Code is released publicly.
Significance. If the reported gains are shown to be attributable to the specific knowledge forms, width-expanded sampling, and knowledge-aware training rather than unmatched compute or data selection, the work would offer concrete, actionable guidance on knowledge integration for tool-calling agents. The public code release supports reproducibility and is a positive contribution.
major comments (2)
- [Abstract] Abstract: The abstract asserts 'consistent and substantial improvements' and 'strong and reliable gains' over baselines but supplies no quantitative results, error bars, baseline details, or ablation controls. This absence makes it impossible to evaluate the magnitude or reliability of the claimed improvements.
- [Abstract] Abstract / experimental claims: The central attribution of gains to KATE's knowledge forms, width-expanded inference, and knowledge-aware training requires explicit evidence that total inference compute (number of samples, tokens, or FLOPs) and data selection criteria are matched between the proposed method and the 'strong baselines.' Without such controls, observed differences cannot be confidently ascribed to the proposed components rather than compute or data confounds.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts 'consistent and substantial improvements' and 'strong and reliable gains' over baselines but supplies no quantitative results, error bars, baseline details, or ablation controls. This absence makes it impossible to evaluate the magnitude or reliability of the claimed improvements.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revision we will update the abstract to report specific improvement percentages (e.g., relative gains on BFCL-V3 and AppWorld), name the primary baselines, and reference the error bars and ablation results presented in the main body. revision: yes
-
Referee: [Abstract] Abstract / experimental claims: The central attribution of gains to KATE's knowledge forms, width-expanded inference, and knowledge-aware training requires explicit evidence that total inference compute (number of samples, tokens, or FLOPs) and data selection criteria are matched between the proposed method and the 'strong baselines.' Without such controls, observed differences cannot be confidently ascribed to the proposed components rather than compute or data confounds.
Authors: We acknowledge the importance of demonstrating matched compute and data selection. Our experimental protocol already equates total inference budget across methods by fixing the number of samples and tokens for parallel sampling versus deeper-reasoning baselines; data selection follows identical criteria for all conditions. We will add an explicit paragraph and a small comparison table in the experimental setup section of the revised manuscript to document these controls. revision: yes
Circularity Check
Empirical study with no derivation chain or self-referential reductions
full rationale
The paper presents an empirical investigation of knowledge forms, inference strategies, and training methods for LLM tool use, culminating in the KATE framework and benchmark results on BFCL-V3 and AppWorld. No equations, derivations, or mathematical claims appear in the provided abstract or description. Performance improvements are reported as experimental outcomes rather than quantities derived from fitted parameters or prior self-citations. The work includes public code, making results externally verifiable without reduction to internal definitions. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption BFCL-V3 and AppWorld benchmarks are valid proxies for real-world multi-step tool-use performance.
Reference graph
Works this paper leans on
-
[1]
Building self-evolving agents via experience- driven lifelong learning: A framework and bench- mark. CoRR, abs/2508.19005. Zouying Cao, Jiaji Deng, Li Y u, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao. 2025. Re- member me, refine me: A dynamic procedural mem- ory framework for experience-driven agent evolu- tion. Preprint, arXiv:2512.10696. Silin C...
-
[2]
arXiv preprint arXiv:2503.23383 , year=
Torl: Scaling tool-integrated RL . CoRR, abs/2503.23383. Mingyang Liu, Gabriele Farina, and Asuman E. Ozdaglar. 2025a. UFT: unifying supervised and re- inforcement fine-tuning. CoRR, abs/2505.16984. Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Y u, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Y uanqing Y u, Zezhong Wang, Y ux- ian Wang, Wu N...
-
[3]
Simpletir: End-to-end reinforcement learn- ing for multi-turn tool-integrated reasoning . CoRR, abs/2509.02479. Jianhao Y an, Y afu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Y u Cheng, and Y ue Zhang. 2025.Learn- ing to reason under off-policy guidance . CoRR, abs/2504.14945. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bo...
-
[4]
React: Synergizing reasoning and act- ing in language models . In The Eleventh Inter- national Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . Open- Review.net. Shaokun Zhang, Yi Dong, Jieyu Zhang, Jan Kautz, Bryan Catanzaro, Andrew Tao, Qingyun Wu, Zhid- ing Y u, and Guilin Liu. 2025. Nemotron-research- tool-n1: Explori...
-
[9]
--- ### Output Format: ```python # The code for the current step in the task
**Iterative Refinement**: With each step, you should refine your approach based on what has been known so far, gradually moving towards a complete solution. --- ### Output Format: ```python # The code for the current step in the task. Add your code here ``` Prompt 2: Aggregation Prompt used in KA TE on dataset AppWorld Before invoking any tools, clearly i...
-
[10]
Identify the user 's current intent based on the conversation history and the latest user message
-
[11]
Break down this intent into clear, actionable subtasks or goals
-
[12]
Your reasoning should focus on *clarity* (what the user wants), *structure* (how to achieve it), and *efficiency* (which tool or reasoning step should come next)
Determine which tools (if any) are needed for each subtask, and specify their expected inputs and outputs. Your reasoning should focus on *clarity* (what the user wants), *structure* (how to achieve it), and *efficiency* (which tool or reasoning step should come next). You do not have to fully adhere to the above suggestions. But you need to analyze the r...
-
[13]
Determine whether the previous tool calls were correct, sufficient, or complete. If a tool call failed or produced suboptimal results due to insufficient or missing parameters or functions, reflect on what information was lacking, how it could be inferred or obtained
-
[14]
If issues exist (e.g., wrong parameters, missing calls, failed execution), explain briefly why they occurred
-
[15]
You do not have to fully adhere to the above suggestions
Analyze future multi-step tool calls during the analysis process, rather than just focusing on the next step. You do not have to fully adhere to the above suggestions. But you need to analyze the relevant points in the conversation history about the correctness and necessary of previous tool call in the thinking process. Prompt 4: Reflection prompt in Dept...
-
[16]
Analyze the user 's question to detect any implicit state dependencies (e.g., user login status, file existence, context variables)
-
[17]
Determine what specific states must be confirmed before continuing
-
[18]
name": "api_docs
If verification is required, decide which tools should be invoked to confirm those states. If no state verification is needed, proceed with reasoning toward tool selection or response generation. You do not have to fully adhere to the above suggestions. But you need to analyze the relevant points in the conversation history about the state requirements in...
-
[19]
spotify_password) in the example above were only for demonstration
The email addresses, access tokens and variables (e.g. spotify_password) in the example above were only for demonstration. Obtain the correct information by calling relevant APIs yourself
-
[20]
Any thoughts should be put as code comments
Only generate valid code blocks, i.e., do not put them in ```...``` or add any extra formatting. Any thoughts should be put as code comments
-
[21]
You can use the variables from the previous code blocks in the subsequent code blocks
-
[22]
Make sure everything is working correctly before making any irreversible change
Write small chunks of code and only one chunk of code in every step. Make sure everything is working correctly before making any irreversible change
-
[23]
But modules and functions that have a risk of affecting the underlying OS, file system or process are disabled
The provided Python environment has access to its standard library. But modules and functions that have a risk of affecting the underlying OS, file system or process are disabled. You will get an error if do call them
-
[24]
So do not write code making calls to os-level modules and functions
Any reference to a file system in the task instructions means the file system *app*, operable via given APIs, and not the actual file system the code is running on. So do not write code making calls to os-level modules and functions
-
[25]
E.g., do NOT use `spotipy` for Spotify
To interact with apps, only use the provided APIs, and not the corresponding Python packages. E.g., do NOT use `spotipy` for Spotify. Remember, the environment only has the standard library
-
[26]
All calls to APIs and parsing its outputs must be as per this documentation
The provided API documentation has both the input arguments and the output JSON schemas. All calls to APIs and parsing its outputs must be as per this documentation
-
[27]
For APIs that return results in "pages", make sure to consider all pages
-
[28]
Do not rely on your existing knowledge of what the current date or time is
To obtain current date or time, use Python functions like `datetime.now()` or obtain it from the phone app. Do not rely on your existing knowledge of what the current date or time is
-
[29]
All requests are concerning a single, default (no) time zone
For all temporal requests, use proper time boundaries, e.g., if I ask for something that happened yesterday, make sure to consider the time between 00:00:00 and 23:59:59. All requests are concerning a single, default (no) time zone
-
[30]
Any reference to my friends, family or any other person or relation refers to the people in my phone 's contacts list
-
[31]
supervisor
All my personal information, and information about my app account credentials, physical addresses and owned payment cards are stored in the "supervisor" app. You can access them via the APIs provided by the supervisor app
-
[32]
If the task asks for some information, return it as the answer argument, i.e
Once you have completed the task, call `apis.supervisor.complete_task()`. If the task asks for some information, return it as the answer argument, i.e. call `apis.supervisor.complete_task(answer=<answer>)`. For tasks that do not require an answer, just skip the answer argument or pass it as None
-
[33]
How many songs are in the Spotify queue?
The answers, when given, should be just entity or number, not full sentences, e.g., `answer=10` for "How many songs are in the Spotify queue?". When an answer is a number, it should be in numbers, not in words, e.g., "10" and not "ten"
-
[34]
You can also pass `status="fail"` in the complete_task API if you are sure you cannot solve it and want to exit
-
[35]
### Instructions:
You must make all decisions completely autonomously and not ask for any clarifications or confirmations from me or anyone else. ### Instructions:
-
[36]
**Understand the Problem**: Thoroughly review the user 's question and the interaction history to grasp the context
-
[37]
Focus on one current step at a time
**Break Down the Task**: Start by identifying the most critical portion of the code that needs to be addressed first. Focus on one current step at a time
-
[38]
Do not try to complete the entire solution in one go
**Generate a Small Portion of Code**: Produce only the part of the code needed to address the first step of the task. Do not try to complete the entire solution in one go
-
[39]
Focus on understanding the specific issue and generating the next part of the solution, keeping previous code intact as much as possible
**Iterate Based on Feedback**: If previous steps have errors or issues, do not just fix them all at once. Focus on understanding the specific issue and generating the next part of the solution, keeping previous code intact as much as possible
-
[40]
note": "Preconditions and safety: ensure the user is authorized to control the vehicle, the vehicle is in Park/Neutral, and surroundings are safe
**Iterative Refinement**: With each step, you should refine your approach based on what has been known so far, gradually moving towards a complete solution. And you need to call apis.api_docs.show_app_descriptions(), apis.api_docs.show_api_descriptions(app_name='<app>') and apis.api_docs.show_api_doc(app_name='<app>', api_name= '<app_name>') before utiliz...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.