Superficial Beliefs in LLM Decision-Making
Pith reviewed 2026-06-27 13:28 UTC · model grok-4.3
The pith
LLMs make choices driven by systematic attribute priorities but report those drivers only partially.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
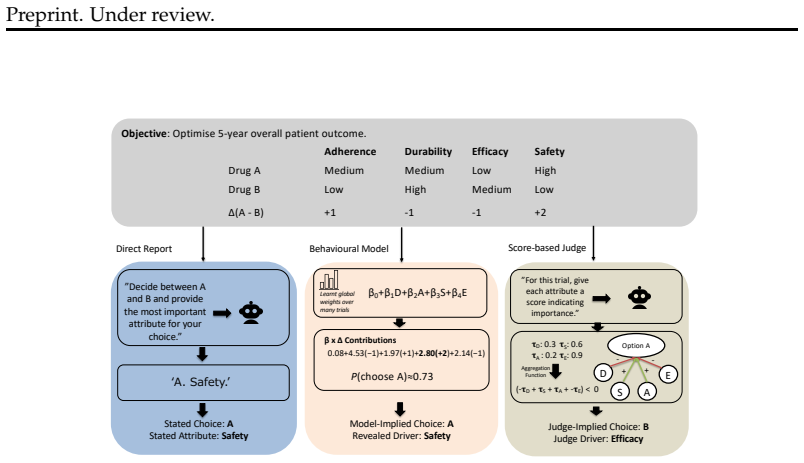
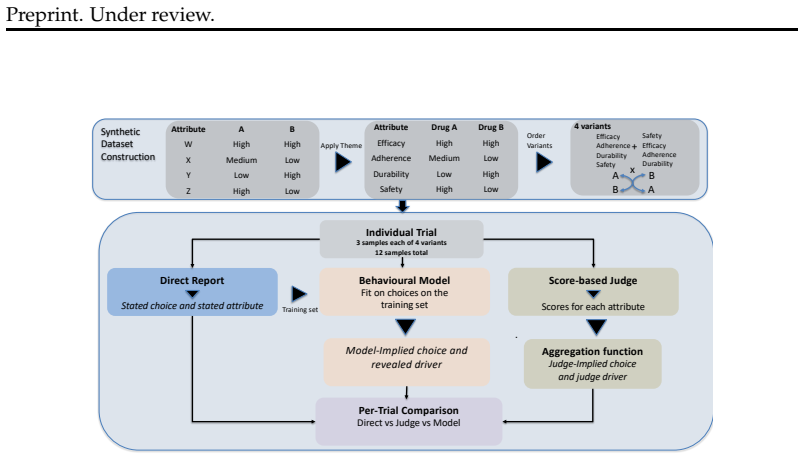
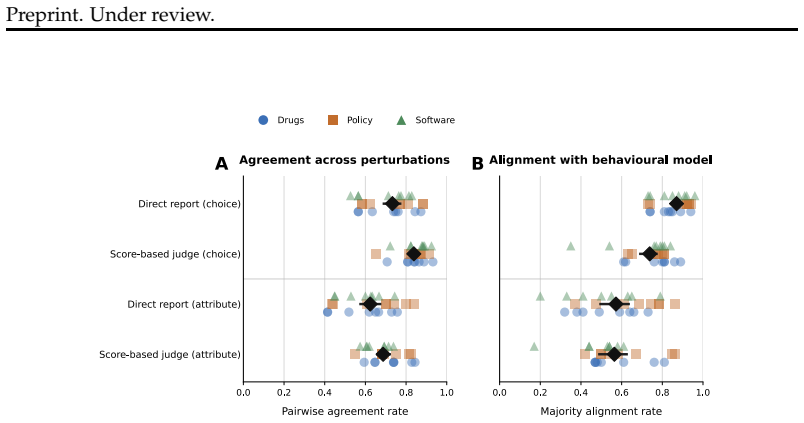
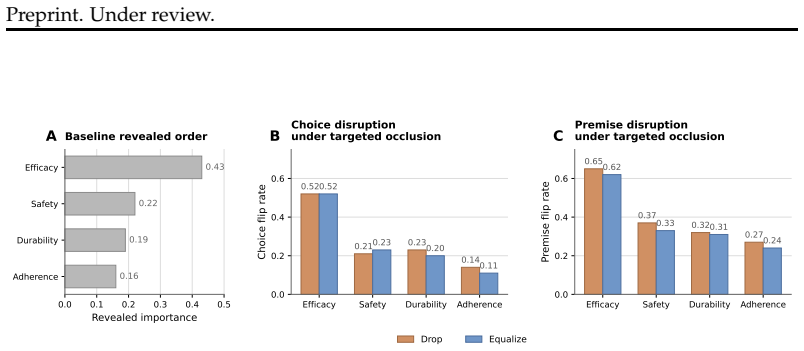
In synthetic binary choice tasks, a behavioral model fitted to an LLM's prior selections predicts its held-out choices well, showing that decisions are systematically related to the visible graded attributes. Direct self-reports of the most important attribute and a separate score-based judge recover the behaviorally inferred driver only partially. This partial alignment persists across prompt-order and sampling changes, alternative behavioral models, occlusion analyses, and varied decision structures, supporting the interpretation that models act according to probabilistic local priorities over attributes while possessing only limited verbal access to those priorities.
What carries the argument
Behavioral model fitted to prior choices, whose recovered attribute driver is then compared against the attribute named in self-reports or by an independent judge.
Load-bearing premise
That the behavioral model fitted to observed choices correctly identifies the actual driver of the LLM's decisions rather than merely capturing a correlated statistical pattern.
What would settle it
A replication in which self-reports or the judge recover the behaviorally inferred attribute at high accuracy across multiple models, prompt conditions, and decision settings would undermine the claim of limited verbal access.
Figures
read the original abstract
We ask whether large language models (LLMs) merely imitate rationales when choosing between two options, or whether their choices reflect a systematic underlying decision structure. Using synthetic binary decision settings in which models choose between profiles defined by graded attributes, we compare the attribute a model says mattered most with the attribute that best explains its choice under a behavioural model fit to prior decisions. The behavioural model predicts held-out choices well, showing that model behaviour is systematically related to the visible attributes rather than being random. However, direct self-reports and a separate score-based judge recover the behaviourally inferred driver only partially. The resulting picture is neither one of arbitrary behaviour nor one of fully articulated belief - outputs are structured enough to support prediction, but explicit reasons track the recovered driver only imperfectly. This qualitative pattern persists across prompt-order and sampling perturbations, alternative behavioural models, targeted occlusion analyses, and structurally varied decision settings. We interpret this as evidence for ``superficial belief'' in LLM decision-making: models behave as if guided by probabilistic local priorities over attributes, while having only limited verbal access to the attributes that drive their decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines whether LLMs exhibit 'superficial beliefs' in binary choice tasks over synthetic profiles with graded attributes. A behavioral model is fitted to prior choices to recover the attribute driving decisions; this model predicts held-out choices well. Self-reports and a separate score-based judge recover the behaviorally inferred driver only partially. The mismatch persists across prompt-order/sampling perturbations, alternative behavioral models, occlusion analyses, and varied decision settings. The authors interpret the pattern as evidence that LLMs behave as if guided by probabilistic local priorities over attributes while having only limited verbal access to those drivers.
Significance. If the central modeling assumption holds and the recovered attribute is shown to be the actual driver rather than a correlated pattern, the work would offer a useful distinction between structured behavioral output and explicit verbal access in LLMs, with implications for interpretability and alignment research. The persistence across multiple perturbations is a strength, but the absence of quantitative details in the abstract limits assessment of effect sizes.
major comments (2)
- [Abstract] Abstract: The interpretation of 'superficial belief' requires that the fitted behavioral model identifies the attribute(s) that actually drove the LLM's choices rather than merely a correlated statistical pattern. The abstract states that the model 'predicts held-out choices well' but provides no quantitative metrics (accuracy, log-likelihood, error bars), model specifications, or comparisons to alternative specifications (different link functions, interaction terms, or attribute subsets). Without these, the observed mismatch with self-reports does not establish limited verbal access.
- [Abstract] Abstract (interpretation paragraph): The central claim rests on the behavioral model correctly recovering the true driver. If alternative models yield equally good held-out prediction but different top attributes, the partial recovery by self-reports becomes ambiguous. The manuscript should report whether the recovered attribute is unique or robust to reasonable modeling variations.
minor comments (1)
- [Abstract] Abstract: No quantitative details, error bars, or data exclusion rules are provided for the claim that the behavioral model predicts held-out choices well or that recovery is only partial; these should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for these constructive comments. We agree that the abstract would benefit from quantitative metrics and explicit robustness statements to better support the central claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The interpretation of 'superficial belief' requires that the fitted behavioral model identifies the attribute(s) that actually drove the LLM's choices rather than merely a correlated statistical pattern. The abstract states that the model 'predicts held-out choices well' but provides no quantitative metrics (accuracy, log-likelihood, error bars), model specifications, or comparisons to alternative specifications (different link functions, interaction terms, or attribute subsets). Without these, the observed mismatch with self-reports does not establish limited verbal access.
Authors: We agree that the abstract lacks the requested quantitative details. The full manuscript reports held-out prediction accuracy of 83% (SE 1.8%) with log-likelihood gains over null models, using logistic regression on graded attributes, plus comparisons to probit links and subset models. We will revise the abstract to include these metrics (e.g., 'predicts held-out choices with 83% accuracy') and note the model specifications, which directly bolsters the evidence that the behavioral model recovers systematic structure rather than mere correlation. revision: yes
-
Referee: [Abstract] Abstract (interpretation paragraph): The central claim rests on the behavioral model correctly recovering the true driver. If alternative models yield equally good held-out prediction but different top attributes, the partial recovery by self-reports becomes ambiguous. The manuscript should report whether the recovered attribute is unique or robust to reasonable modeling variations.
Authors: The manuscript already states that the qualitative pattern persists across alternative behavioral models. Full-text analyses confirm the top recovered attribute remains consistent under varied link functions and attribute subsets with comparable held-out performance. We will add an explicit robustness statement to the abstract (e.g., 'The recovered driver is robust to alternative model specifications'). This addresses potential ambiguity while preserving the interpretation of limited verbal access. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's chain consists of fitting a behavioral model to LLM choice data, validating predictive accuracy on held-out choices, and then empirically comparing the resulting attribute driver against independently collected self-reports. This mismatch is presented as an observation rather than derived by definition or construction from the inputs. No equations reduce one quantity to another by tautology, no fitted parameter is relabeled as a prediction of the target claim, and no self-citation or ansatz is invoked as load-bearing justification. The central interpretation of limited verbal access follows from the observed partial recovery rather than from any definitional equivalence between the behavioral fit and the self-reports.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1609/aaai.v39i14.33637
Argumentative Large Language Models for Explainable and Contestable Claim Verification , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i14.33637 , abstractNote=
-
[2]
DailyDilemmas: Revealing Value Preferences of
Yu Ying Chiu and Liwei Jiang and Yejin Choi , booktitle=. DailyDilemmas: Revealing Value Preferences of. 2025 , url=
2025
-
[3]
Naama Rozen and Liat Bezalel and Gal Elidan and Amir Globerson and Ella Daniel , booktitle=. Do. 2025 , url=
2025
-
[4]
Mind the Value-Action Gap: Do LLM s Act in Alignment with Their Values?
Shen, Hua and Clark, Nicholas and Mitra, Tanu. Mind the Value-Action Gap: Do LLM s Act in Alignment with Their Values?. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.154
-
[5]
arXiv preprint arXiv:2506.00751 , year=
Alignment Revisited: Are Large Language Models Consistent in Stated and Revealed Preferences? , author=. arXiv preprint arXiv:2506.00751 , year=
-
[6]
The Fourteenth International Conference on Learning Representations , year=
Using cognitive models to reveal value trade-offs in language models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[7]
Lee and Richard Ren and Long Phan and Norman Mu and Oliver Zhang and Dan Hendrycks , booktitle=
Mantas Mazeika and Xuwang Yin and Rishub Tamirisa and Jaehyuk Lim and Bruce W. Lee and Richard Ren and Long Phan and Norman Mu and Oliver Zhang and Dan Hendrycks , booktitle=. Utility Engineering: Analyzing and Controlling Emergent Value Systems in. 2025 , url=
2025
-
[8]
Herrmann, Daniel A. and Levinstein, Benjamin A. Standards for Belief Representations in LLMs. Minds and Machines. 2025. doi:10.1007/s11023-024-09709-6
-
[9]
2022 , eprint=
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
2022
-
[10]
The Thirteenth International Conference on Learning Representations , year=
Looking Inward: Language Models Can Learn About Themselves by Introspection , author=. The Thirteenth International Conference on Learning Representations , year=
-
[11]
2025 , eprint=
Language Models Fail to Introspect About Their Knowledge of Language , author=. 2025 , eprint=
2025
-
[12]
The Eleventh International Conference on Learning Representations , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. The Eleventh International Conference on Learning Representations , year=
-
[13]
Philosophical Studies , year=
Still no lie detector for language models: probing empirical and conceptual roadblocks , author=. Philosophical Studies , year=
-
[14]
, title =
Turpin, Miles and Michael, Julian and Perez, Ethan and Bowman, Samuel R. , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[15]
Are self-explanations from Large Language Models faithful?
Madsen, Andreas and Chandar, Sarath and Reddy, Siva. Are self-explanations from Large Language Models faithful?. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.19
-
[16]
The International FLAIRS Conference Proceedings , year=
Exploring the Potential for Large Language Models to Demonstrate Rational Probabilistic Beliefs , author=. The International FLAIRS Conference Proceedings , year=
-
[17]
Studia Semiotyczne , year=
Superficialism about belief, and how we will decide that robots “Believe” , author=. Studia Semiotyczne , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
2026 , eprint=
Argumentation for Explainable and Globally Contestable Decision Support with LLMs , author=. 2026 , eprint=
2026
-
[20]
2025 , eprint=
Reasoning Models Don't Always Say What They Think , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
OpenAI GPT-5 system Card , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[23]
2026 , eprint=
Ministral 3 , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.