Exploring the Design Space of Reward Backpropagation for Flow Matching
Pith reviewed 2026-06-27 14:08 UTC · model grok-4.3
The pith
FlowBP provides a unified framework for designing memory-bounded reward backpropagation trajectories in flow matching models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
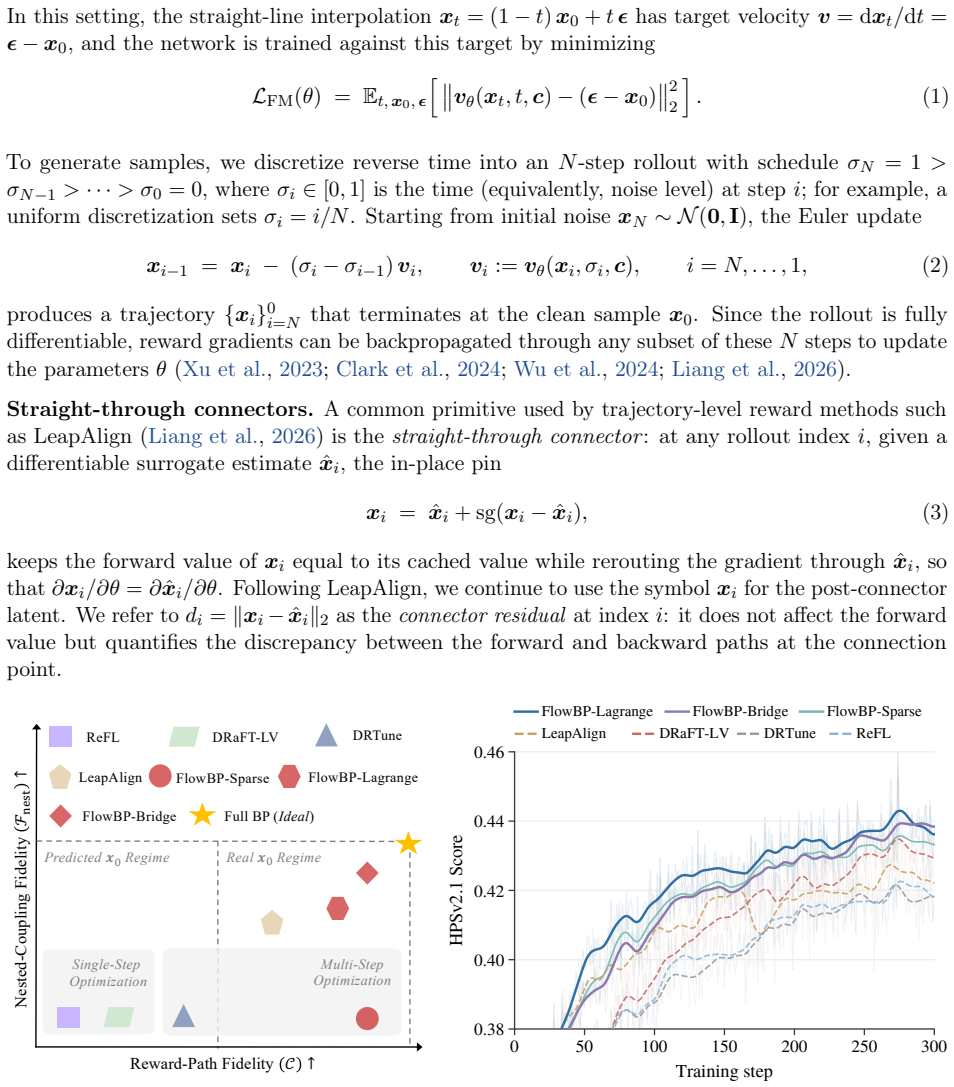
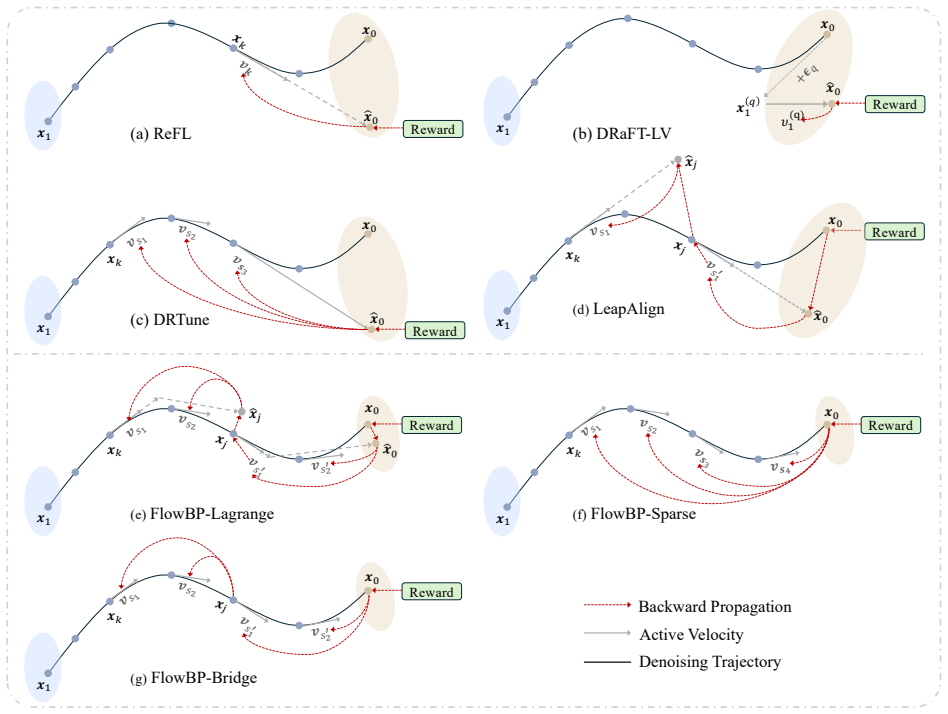
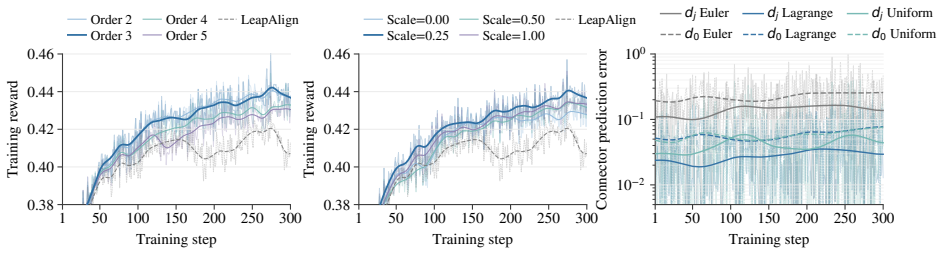
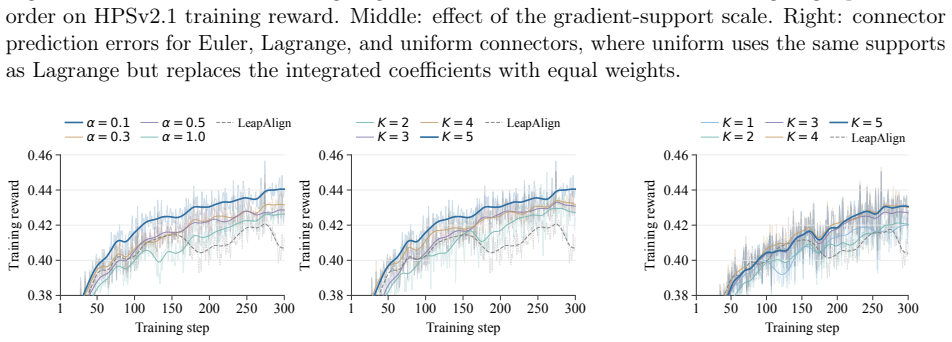
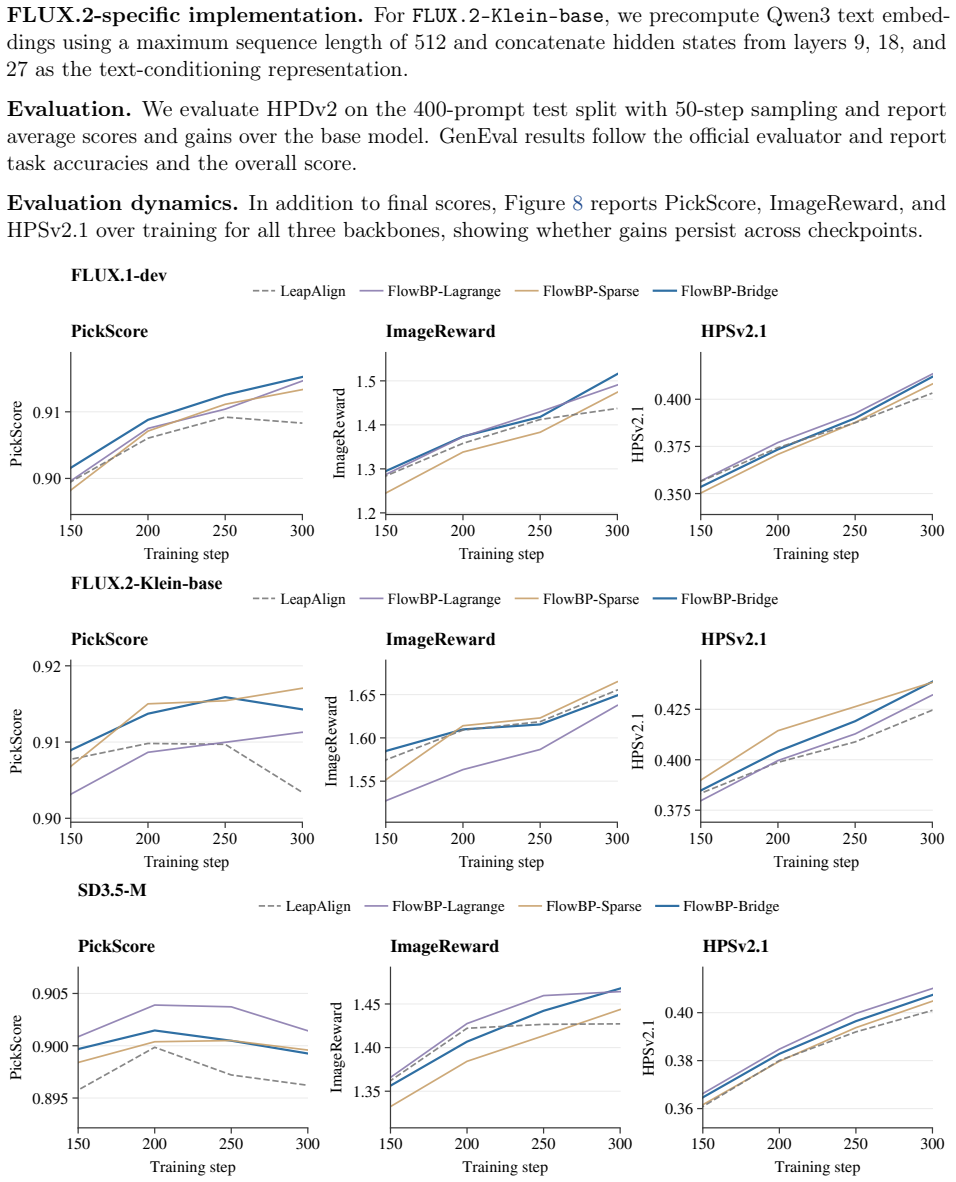
FlowBP is a surrogate-trajectory framework that keeps a no-gradient cached rollout for sampling and builds a lightweight backward surrogate from cached and selectively re-forwarded velocities. It separates four choices—reward-model input, active set, integration weights, and bridge coupling—and recovers prior methods as special cases. The three instantiated variants bound memory by active-set size and limit gradient chaining to at most one Jacobian factor, leading to improvements over direct-gradient baselines on most metrics for SD3.5-M, FLUX.1-dev, and FLUX.2-Klein-base.
What carries the argument
The surrogate-trajectory framework that decouples the backward path into cached rollout and lightweight velocity-based surrogate, with separable design choices of reward-model input, active set, integration weights, and bridge coupling.
Load-bearing premise
The lightweight backward surrogate from cached and selectively re-forwarded velocities approximates the full backward trajectory with enough accuracy that the resulting gradients remain useful for optimization.
What would settle it
If experiments on models small enough for full backpropagation show that FlowBP variants yield worse alignment metrics than direct methods, or if the memory savings do not hold in practice, the central claim would be falsified.
Figures

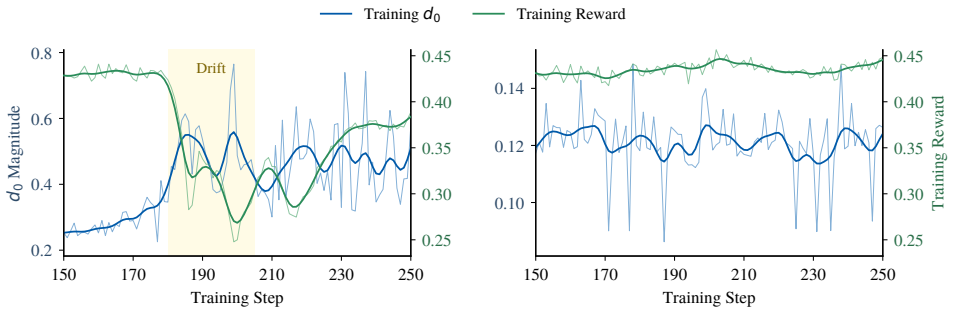



read the original abstract
Aligning text-to-image flow matching models with human preferences via direct reward backpropagation is sample-efficient but hampered by two well-known pathologies: activations cannot be stored across the full sampling trajectory at modern model scale, and chained Jacobian products across steps inflate the reward gradient as it travels back to early indices. Connector-based methods, such as LeapAlign, address these issues by replacing the full backward trajectory with a short pinned path, highlighting a useful decoupling between sampling and optimization. However, the quality of the resulting gradient depends on how accurately this short path approximates the full rollout, especially over long intervals. We propose FlowBP, a unified surrogate-trajectory framework that treats the backward trajectory itself as the design object. FlowBP keeps a no-gradient cached rollout for sampling, then builds a lightweight backward surrogate from cached and selectively re-forwarded velocities. This view separates four choices: the reward-model input, active set, integration weights, and bridge coupling, and recovers prior direct-gradient methods as particular settings. Within this framework, we instantiate three variants: FlowBP-Sparse uses sparse Euler reconstruction, FlowBP-Bridge adds controlled bridge coupling, and FlowBP-Lagrange raises the order of leap quadrature. All three bound memory by the active-set size and limit gradient chaining to at most one Jacobian factor. Across SD3.5-M, FLUX.1-dev, and FLUX.2-Klein-base on preference, quality, and compositional metrics, the three variants improve over direct-gradient baselines on most metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlowBP, a unified surrogate-trajectory framework for reward backpropagation in flow matching models. It treats the backward trajectory as a design object with four separable choices (reward-model input, active set, integration weights, bridge coupling), recovers prior direct-gradient methods as special cases, and instantiates three variants (FlowBP-Sparse with sparse Euler reconstruction, FlowBP-Bridge with controlled bridge coupling, FlowBP-Lagrange with higher-order leap quadrature). All variants bound memory by active-set size and limit gradient chaining to at most one Jacobian factor. Experiments across SD3.5-M, FLUX.1-dev, and FLUX.2-Klein-base report that the variants improve over direct-gradient baselines on most preference, quality, and compositional metrics.
Significance. If the cached-velocity surrogate produces gradients sufficiently close in direction and magnitude to full-trajectory backpropagation, the work supplies a practical and modular approach to scalable direct reward optimization for large flow models while controlling memory and numerical pathologies; the explicit recovery of prior methods as particular settings of the design space is a clear strength.
major comments (2)
- [Abstract] Abstract: the central empirical claim that the three variants improve over direct-gradient baselines on most metrics is asserted without any quantitative tables, error bars, ablation details, or reported effect sizes, which is load-bearing for evaluating whether the observed gains are reliable or attributable to the surrogate construction.
- [Abstract and framework description] The load-bearing assumption is that the lightweight backward surrogate built from cached and selectively re-forwarded velocities yields reward gradients whose direction and magnitude remain useful for optimization; no quantitative validation (cosine similarity, relative norm difference, or per-step approximation error) of this surrogate against full-trajectory backpropagation is described, leaving open the possibility that gains arise from active-set or integration choices rather than approximation quality.
minor comments (1)
- [Abstract] The abstract states improvements 'on most metrics' without specifying which metrics or models show gains versus which do not; a summary table in the main text would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for surrogate validation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that the three variants improve over direct-gradient baselines on most metrics is asserted without any quantitative tables, error bars, ablation details, or reported effect sizes, which is load-bearing for evaluating whether the observed gains are reliable or attributable to the surrogate construction.
Authors: We agree the abstract states the empirical outcome at a high level without numbers. The full manuscript contains the supporting tables, per-metric comparisons, and ablations in the experimental sections. Due to abstract length limits we kept the summary concise, but we can revise the abstract to include one or two key quantitative effect sizes (e.g., average preference-score lift) if the editor permits. revision: partial
-
Referee: [Abstract and framework description] The load-bearing assumption is that the lightweight backward surrogate built from cached and selectively re-forwarded velocities yields reward gradients whose direction and magnitude remain useful for optimization; no quantitative validation (cosine similarity, relative norm difference, or per-step approximation error) of this surrogate against full-trajectory backpropagation is described, leaving open the possibility that gains arise from active-set or integration choices rather than approximation quality.
Authors: The manuscript does not report direct surrogate-quality metrics such as cosine similarity or per-step approximation error between the cached-velocity surrogate and full-trajectory gradients. Downstream task improvements across three models provide indirect evidence that the gradients remain useful, but we acknowledge this does not substitute for explicit gradient-level validation. We will add a targeted analysis (cosine similarity and relative-norm statistics on a subset of trajectories) in the revision. revision: yes
Circularity Check
No circularity: empirical framework evaluated on external benchmarks
full rationale
The paper defines a design space for surrogate backward trajectories in flow matching reward optimization, recovers prior methods as special cases, and reports empirical gains on preference/quality metrics across SD3.5-M, FLUX.1-dev, and FLUX.2-Klein-base. No equations, fitted parameters, or self-citations are shown to reduce the claimed improvements to quantities defined by construction. The central results rest on measured performance against independent baselines rather than algebraic identity with inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Forty-first International Conference on Machine Learning , year=
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author=. Forty-first International Conference on Machine Learning , year=
-
[5]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[6]
The Eleventh International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. The Eleventh International Conference on Learning Representations , year=
-
[7]
arXiv preprint arXiv:2505.05470 , year=
Flow-grpo: Training flow matching models via online rl , author=. arXiv preprint arXiv:2505.05470 , year=
-
[8]
The Twelfth International Conference on Learning Representations , year=
Directly Fine-Tuning Diffusion Models on Differentiable Rewards , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
European Conference on Computer Vision , pages=
Deep reward supervisions for tuning text-to-image diffusion models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[10]
2024 , howpublished=
Black Forest Labs , title=. 2024 , howpublished=
2024
-
[11]
arXiv preprint arXiv:2306.09341 , year=
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis , author=. arXiv preprint arXiv:2306.09341 , year=
-
[12]
Advances in Neural Information Processing Systems , year=
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , author=. Advances in Neural Information Processing Systems , year=
-
[13]
Advances in Neural Information Processing Systems , year=
GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment , author=. Advances in Neural Information Processing Systems , year=
-
[14]
arXiv preprint arXiv:2503.05236 , year=
Unified Reward Model for Multimodal Understanding and Generation , author=. arXiv preprint arXiv:2503.05236 , year=
-
[15]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[16]
arXiv preprint arXiv:2207.12598 , year=
Classifier-Free Diffusion Guidance , author=. arXiv preprint arXiv:2207.12598 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Imagereward: Learning and evaluating human preferences for text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
arXiv preprint arXiv:2604.15311 , year=
LeapAlign: Post-Training Flow Matching Models at Any Generation Step by Building Two-Step Trajectories , author=. arXiv preprint arXiv:2604.15311 , year=
-
[19]
2026 , howpublished =
2026
-
[20]
The Twelfth International Conference on Learning Representations , year=
Training Diffusion Models with Reinforcement Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[21]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[22]
arXiv preprint arXiv:2505.07818 , year=
Dancegrpo: Unleashing grpo on visual generation , author=. arXiv preprint arXiv:2505.07818 , year=
-
[23]
arXiv preprint arXiv:2507.21802 , year=
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE , author=. arXiv preprint arXiv:2507.21802 , year=
-
[24]
Diffusion
Kaiwen Zheng and Huayu Chen and Haotian Ye and Haoxiang Wang and Qinsheng Zhang and Kai Jiang and Hang Su and Stefano Ermon and Jun Zhu and Ming-Yu Liu , booktitle=. Diffusion. 2026 , url=
2026
-
[25]
arXiv preprint arXiv:2509.25050 , year=
Advantage weighted matching: Aligning rl with pretraining in diffusion models , author=. arXiv preprint arXiv:2509.25050 , year=
-
[26]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[27]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[28]
International Conference on Learning Representations , year=
Progressive Distillation for Fast Sampling of Diffusion Models , author=. International Conference on Learning Representations , year=
-
[29]
2023 , eprint=
Aligning Text-to-Image Diffusion Models with Reward Backpropagation , author=. 2023 , eprint=
2023
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wallace, Bram and Dang, Meihua and Rafailov, Rafael and Zhou, Linqi and Lou, Aaron and Purushwalkam, Senthil and Ermon, Stefano and Xiong, Caiming and Joty, Shafiq and Naik, Nikhil , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Using human feedback to fine-tune diffusion models without any reward model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Self-Play Fine-tuning of Diffusion Models for Text-to-image Generation , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Liang, Zhanhao and Yuan, Yuhui and Gu, Shuyang and Chen, Bohan and Hang, Tiankai and Cheng, Mingxi and Li, Ji and Zheng, Liang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[34]
The Thirteenth International Conference on Learning Representations , year=
IterComp: Iterative Composition-Aware Feedback Learning from Model Gallery for Text-to-Image Generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[35]
2025 , eprint=
Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference , author=. 2025 , eprint=
2025
-
[36]
The Thirteenth International Conference on Learning Representations , year=
Adjoint Matching: Fine-tuning Flow and Diffusion Generative Models with Memoryless Stochastic Optimal Control , author=. The Thirteenth International Conference on Learning Representations , year=
-
[37]
2025 , url=
Huaisheng Zhu and Teng Xiao and Vasant G Honavar , booktitle=. 2025 , url=
2025
-
[38]
Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a
Kaiwen Zheng and Yongxin Chen and Huayu Chen and Guande He and Ming-Yu Liu and Jun Zhu and Qinsheng Zhang , booktitle=. Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a. 2025 , url=
2025
-
[39]
Forty-first International Conference on Machine Learning , year=
A Dense Reward View on Aligning Text-to-Image Diffusion with Preference , author=. Forty-first International Conference on Machine Learning , year=
-
[40]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.