P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
Pith reviewed 2026-06-27 13:46 UTC · model grok-4.3
The pith
P3D-Bench shows MLLMs recover global 3D shapes and semantics but fail to match precise parametric geometry and part structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
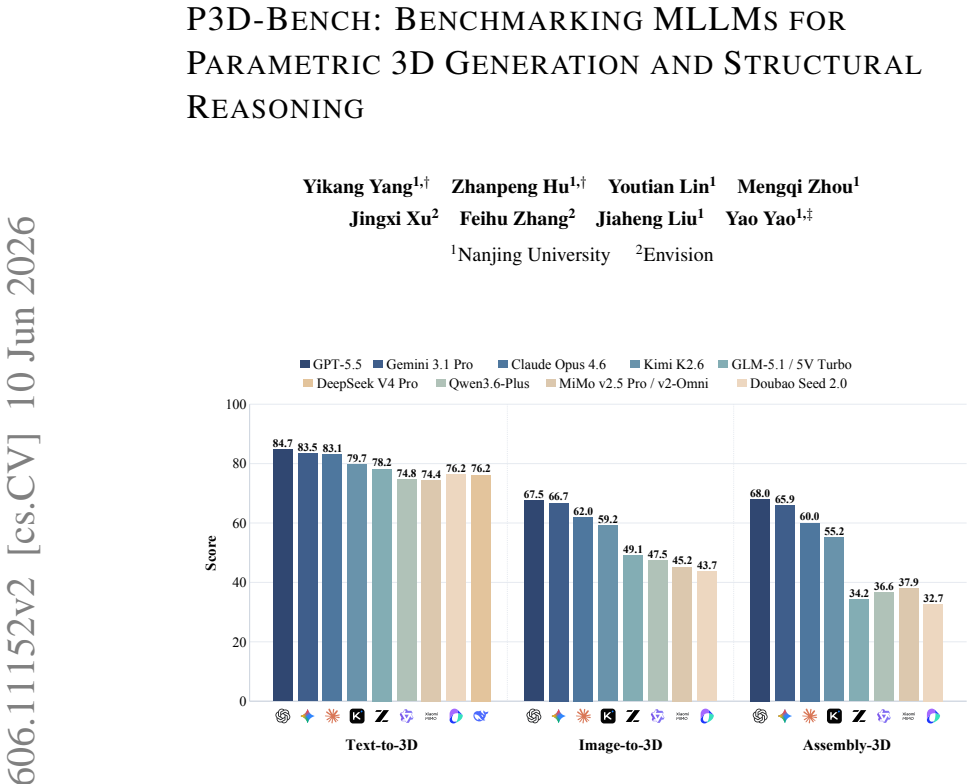
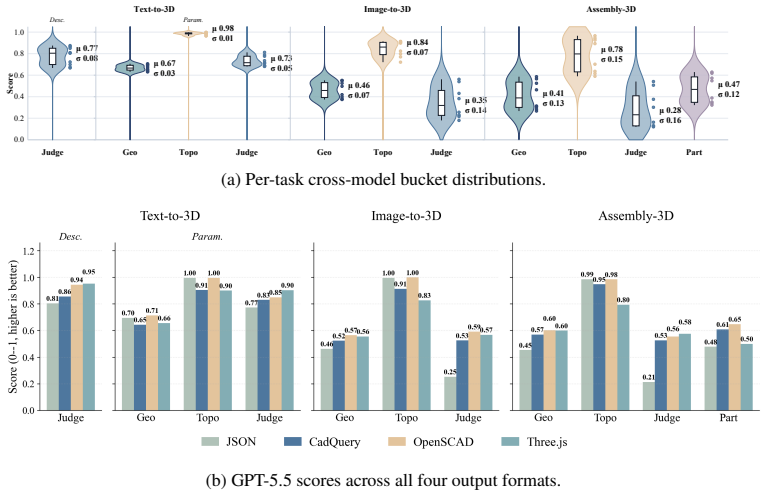
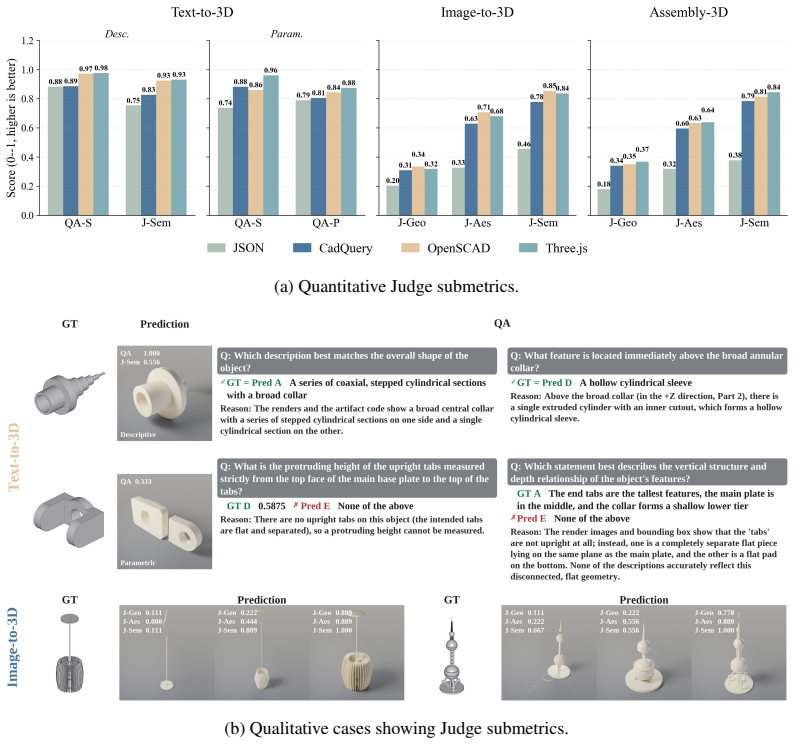
P3D-Bench demonstrates that current MLLMs and text-only LLMs can often recover the global shape and semantic identity of target objects yet fail to reproduce the precise parametric geometry and part relations specified by the input, with part-level modeling especially weak on assemblies where neither individual part geometry nor the right number of parts is recovered.
What carries the argument
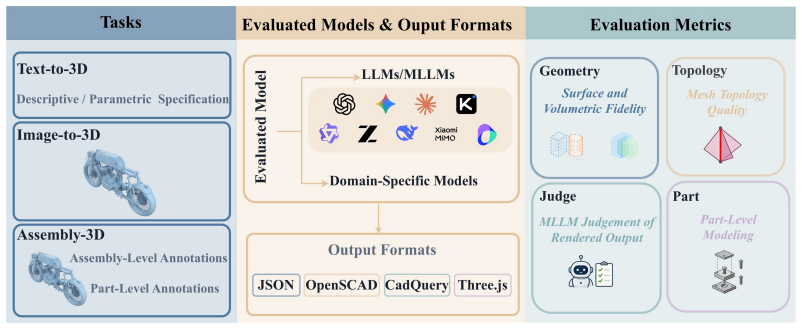
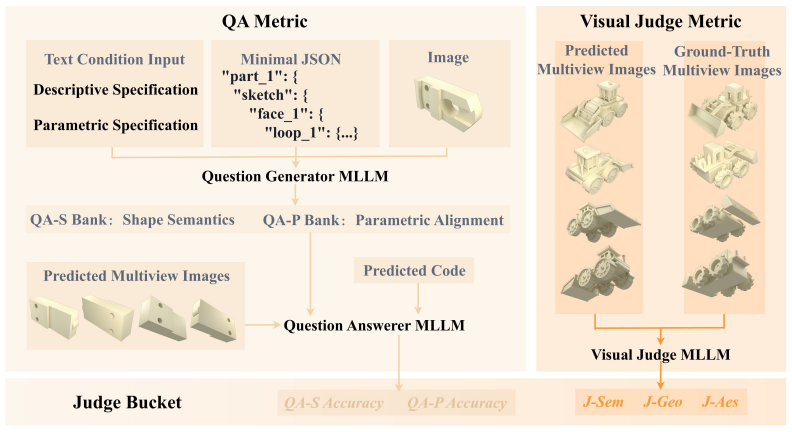
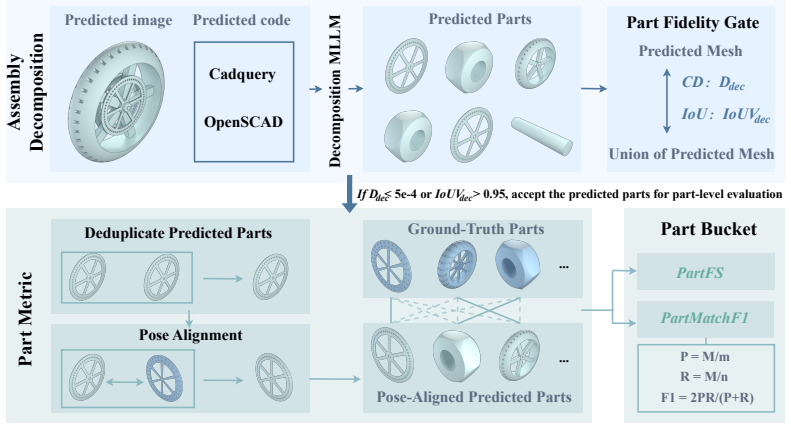
P3D-Bench benchmark protocol that scores parametric 3D program outputs for executability, geometric fidelity, topology, text-grounded constraints, multiview semantic alignment, and part-level structure across three task families.
If this is right
- Assembly tasks expose the greatest gap in compositional structure modeling.
- Global semantic recovery does not imply recovery of specified parametric values.
- Part-level accuracy, including correct part counts and individual geometries, requires targeted improvement.
Where Pith is reading between the lines
- The results point to a separation between semantic priors and the ability to enforce explicit geometric constraints in generated code.
- The benchmark could be used to test whether fine-tuning on parametric constraint examples closes the observed gaps.
- Similar evaluation protocols might apply to other domains where code must produce exact physical outputs rather than approximate appearances.
Load-bearing premise
The chosen metrics for executability, geometric fidelity, topology, text-grounded constraints, multiview semantic alignment and part-level structure are sufficient to measure whether a generated program recovers a design's structure.
What would settle it
A model that scores high on all P3D-Bench metrics but whose executed 3D output deviates in exact dimensions, topology, or part count from the input specification would show the metrics do not capture structural recovery.
Figures

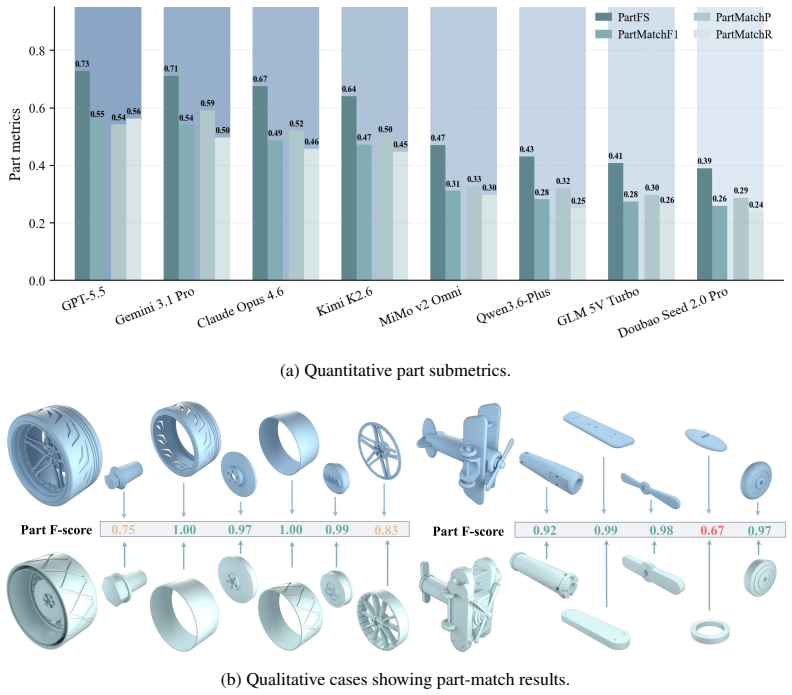
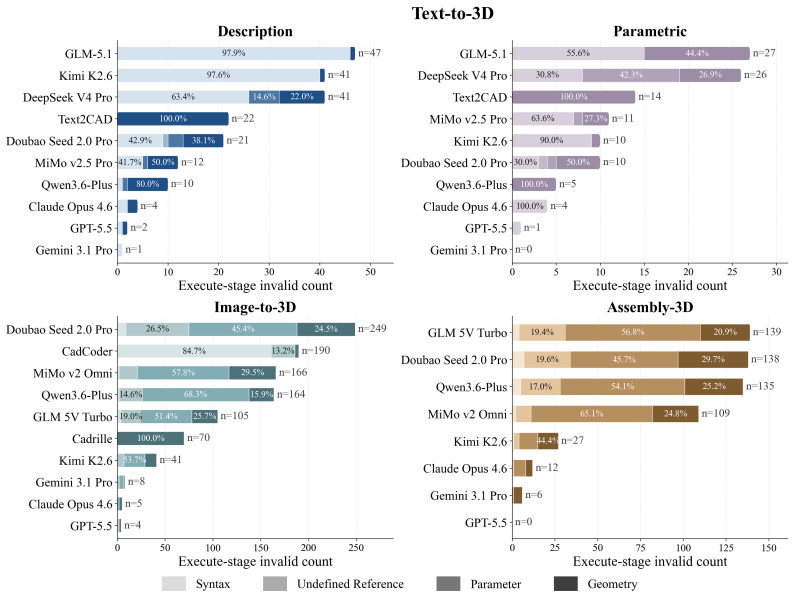
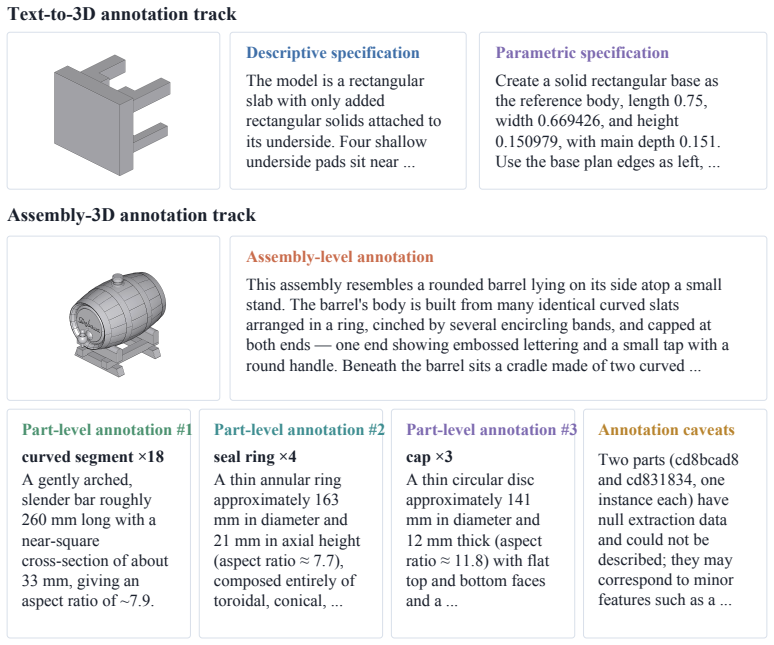
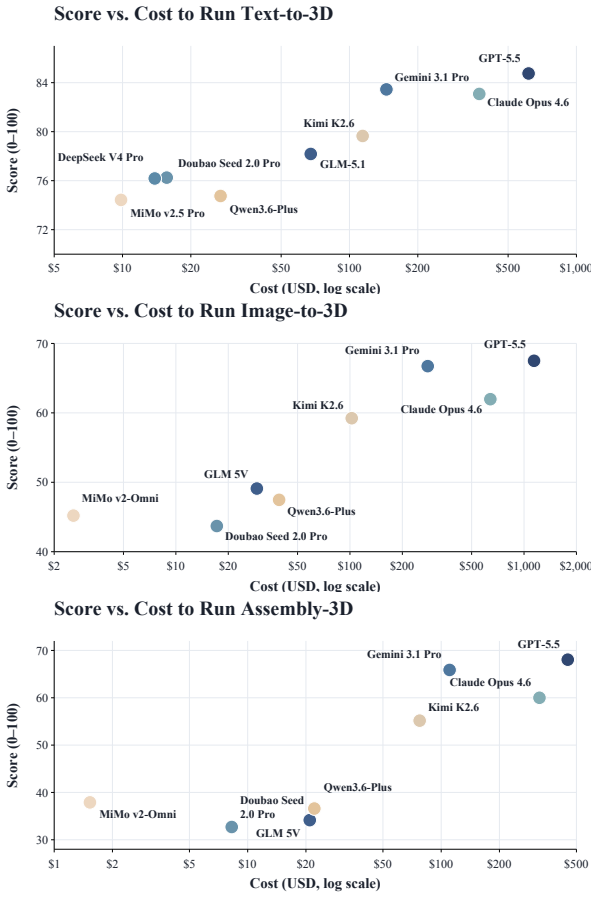












read the original abstract
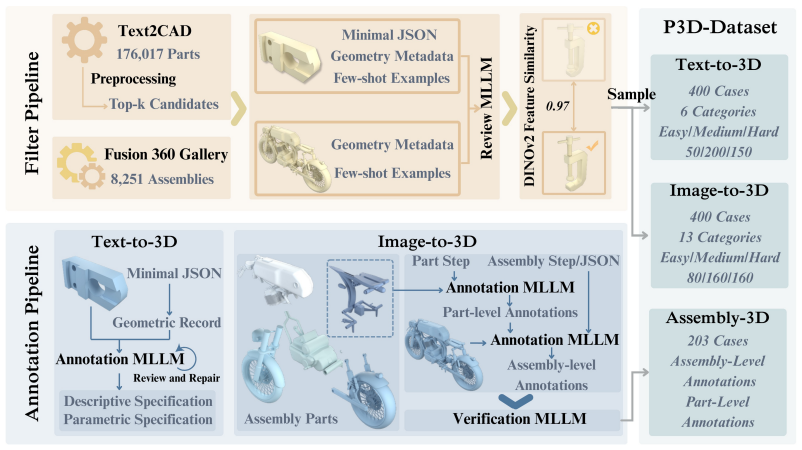
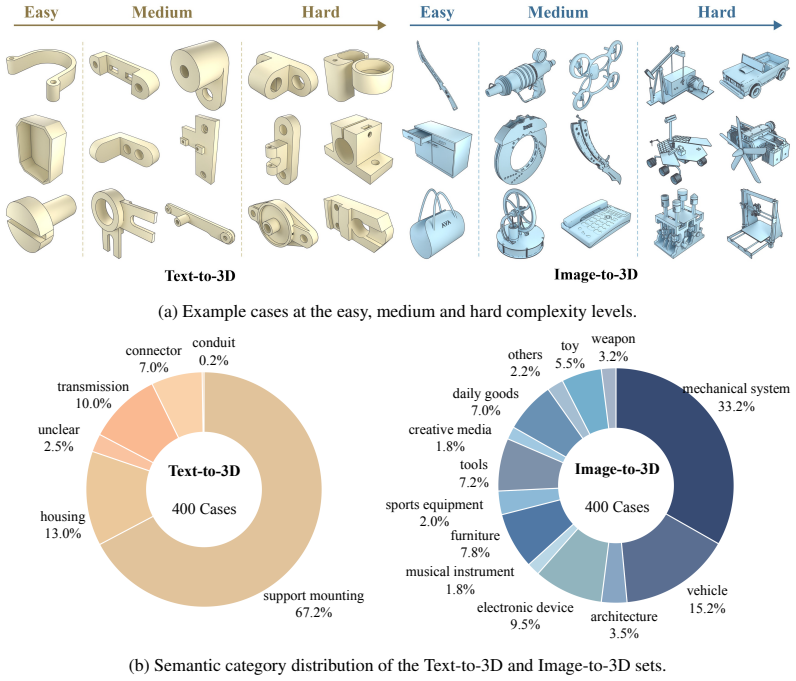
Multimodal large language models can write code to produce complex programs as well as use programs to do 3D modeling, which opens up a new avenue for 3D generation powered by their priors, world knowledge and reasoning. Yet existing benchmarks rarely evaluate 3D modeling through code. Such modeling demands more than runnable code: from a text or visual specification, a model must generate a parametric 3D program that is geometrically precise, semantically aligned and assembly-consistent. We introduce P3D-Bench, a benchmark for parametric 3D generation. Unlike a 3D mesh, a parametric 3D program exposes explicit dimensions, construction operations and part relations, revealing whether a model recovers a design's structure, not just its appearance. Under a unified protocol, P3D-Bench covers three task families (Text-to-3D, Image-to-3D and Assembly-3D) and scores each output for executability, geometric fidelity, topology, text-grounded constraints, multiview semantic alignment and part-level structure. We evaluate frontier MLLMs and text-only LLMs on 400 text cases, 400 image cases and 203 annotated assemblies, with domain-specific models as reference points. Our extensive evaluation yields three findings. First, assemblies are the hardest setting, where models still fail to compose multiple parts into a coherent structure. Second, models can often recover the global shape and semantic identity of the target object, yet fail to reproduce the precise parametric geometry specified by the input. Third, part-level modeling remains weak on assemblies, where models recover neither the geometry of each part nor the right number of parts. These results position P3D-Bench as a benchmark for evaluating precise parametric geometry and part-level structure in parametric 3D generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces P3D-Bench, a benchmark for evaluating MLLMs on parametric 3D program generation from text, image, or assembly inputs across three task families. It scores model outputs using metrics for executability, geometric fidelity, topology, text-grounded constraints, multiview semantic alignment, and part-level structure on 400 text cases, 400 image cases, and 203 assemblies. The evaluation of frontier MLLMs and LLMs (with domain-specific references) yields three findings: assemblies are the hardest setting, models recover global shape and semantic identity but fail precise parametric geometry, and part-level modeling remains weak on assemblies.
Significance. If the metrics and case validations hold, P3D-Bench would provide a useful addition to 3D generation evaluation by focusing on parametric structure and part relations rather than appearance alone. The unified protocol across modalities and the scale of the evaluation (over 1000 cases) are positive aspects that could help identify specific gaps in current models' structural reasoning.
major comments (2)
- [Abstract] Abstract: the second finding claims models recover global shape/semantic identity yet fail to reproduce precise parametric geometry. However, the abstract lists the six metrics without definitions, formulas, or validation showing they isolate exact parameter mismatches independently of rendered mesh or global shape similarity (e.g., whether geometric fidelity compares program parameters directly). This is load-bearing for the finding.
- [Evaluation] Evaluation section: no details are supplied on metric definitions, how the 400+400+203 cases were validated or annotated (especially the 203 assemblies), or how scores were aggregated across metrics. Without this, support for all three findings cannot be verified.
minor comments (1)
- [Figures and Tables] Figure captions and tables should explicitly note the number of cases per task family and any aggregation method used for the reported scores.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that the current manuscript provides insufficient detail on metric definitions and case validation to fully substantiate the reported findings. We will revise the manuscript to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the second finding claims models recover global shape/semantic identity yet fail to reproduce precise parametric geometry. However, the abstract lists the six metrics without definitions, formulas, or validation showing they isolate exact parameter mismatches independently of rendered mesh or global shape similarity (e.g., whether geometric fidelity compares program parameters directly). This is load-bearing for the finding.
Authors: We agree that the abstract is too concise and does not supply the requested definitions or validation. The geometric fidelity metric is intended to operate directly on program parameters (e.g., dimension values and construction operations) rather than on rendered meshes or global shape descriptors; the other five metrics address orthogonal aspects. To make this explicit and support the second finding, we will revise the abstract to include brief characterizations of the metrics and a pointer to their formal definitions and independence checks in the main text. revision: yes
-
Referee: [Evaluation] Evaluation section: no details are supplied on metric definitions, how the 400+400+203 cases were validated or annotated (especially the 203 assemblies), or how scores were aggregated across metrics. Without this, support for all three findings cannot be verified.
Authors: We concur that the Evaluation section currently lacks the necessary transparency. In the revised version we will expand it to provide: (i) complete definitions and formulas for all six metrics, including explicit demonstration that geometric fidelity measures parameter-level differences independently of mesh or semantic similarity; (ii) a description of the annotation and validation protocol used for the 400 text, 400 image, and 203 assembly cases (including how assemblies were constructed and cross-checked); and (iii) the precise aggregation procedure across metrics. These additions will enable verification of the three findings. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or fitted predictions
full rationale
The paper introduces P3D-Bench as an evaluation protocol for MLLMs on parametric 3D tasks, reporting empirical findings from model evaluations on fixed test cases. No mathematical derivations, parameter fitting, predictions from first principles, or self-citation chains appear in the abstract or described structure. The three findings are direct observations from scoring outputs on executability, fidelity, topology, and structure metrics; they do not reduce to inputs by construction. This matches the default case of a self-contained empirical benchmark with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parametric 3D programs can be meaningfully scored for geometric fidelity, topology, and part-level structure from text or image specifications.
invented entities (1)
-
P3D-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[2]
Advances in Neural Information Processing Systems , volume=
Text2cad: Generating sequential cad designs from beginner-to-expert level text prompts , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
ACM Transactions on Graphics (TOG) , volume=
Fusion 360 gallery: A dataset and environment for programmatic cad construction from human design sequences , author=. ACM Transactions on Graphics (TOG) , volume=. 2021 , publisher=
2021
-
[4]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Deepcad: A deep generative network for computer-aided design models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[5]
2026 , howpublished =
2026
-
[6]
2025 , eprint=
CAD-Coder: An Open-Source Vision-Language Model for Computer-Aided Design Code Generation , author=. 2025 , eprint=
2025
-
[7]
2026 , url=
Prashant Govindarajan and Davide Baldelli and Jay Pathak and Quentin Fournier and Sarath Chandar , journal=. 2026 , url=
2026
-
[8]
2026 , eprint=
cadrille: Multi-modal CAD Reconstruction with Reinforcement Learning , author=. 2026 , eprint=
2026
-
[9]
arXiv preprint arXiv:2604.10992 , year=
ArtiCAD: Articulated CAD Assembly Design via Multi-Agent Code Generation , author=. arXiv preprint arXiv:2604.10992 , year=
-
[10]
arXiv preprint arXiv:2605.15187 , year=
Articraft: An Agentic System for Scalable Articulated 3D Asset Generation , author=. arXiv preprint arXiv:2605.15187 , year=
-
[11]
arXiv preprint arXiv:2508.08228 , year=
Ll3m: Large language 3d modelers , author=. arXiv preprint arXiv:2508.08228 , year=
-
[12]
arXiv preprint arXiv:2601.11109 , year=
Vision-as-inverse-graphics agent via interleaved multimodal reasoning , author=. arXiv preprint arXiv:2601.11109 , year=
-
[13]
arXiv preprint arXiv:2207.04632 , year=
Skexgen: Autoregressive generation of cad construction sequences with disentangled codebooks , author=. arXiv preprint arXiv:2207.04632 , year=
-
[14]
and Furukawa, Yasutaka , booktitle =
Xu, Xiang and Jayaraman, Pradeep Kumar and Lambourne, Joseph George and Willis, Karl D.D. and Furukawa, Yasutaka , booktitle =. Hierarchical Neural Coding for Controllable. 2023 , editor =
2023
-
[15]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[16]
International Conference on Learning Representations , volume=
Swe-bench: Can language models resolve real-world github issues? , author=. International Conference on Learning Representations , volume=
-
[17]
The Eleventh International Conference on Learning Representations , year=
DreamFusion: Text-to-3D using 2D Diffusion , author=. The Eleventh International Conference on Learning Representations , year=
-
[18]
Communications of the ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deepsdf: Learning continuous signed distance functions for shape representation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
Advances in Neural Information Processing Systems , volume=
Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
International Conference on Learning Representations , volume=
Lrm: Large reconstruction model for single image to 3d , author=. International Conference on Learning Representations , volume=
-
[23]
arXiv preprint arXiv:2310.02977 , year=
T ^3 Bench: Benchmarking Current Progress in Text-to-3D Generation , author=. arXiv preprint arXiv:2310.02977 , year=
-
[24]
arXiv preprint arXiv:2503.21745 , year=
3dgen-bench: comprehensive benchmark suite for 3d generative models , author=. arXiv preprint arXiv:2503.21745 , year=
-
[25]
arXiv preprint arXiv:2505.06507 , year=
Text-to-cadquery: A new paradigm for cad generation with scalable large model capabilities , author=. arXiv preprint arXiv:2505.06507 , year=
-
[26]
arXiv preprint arXiv:2603.26512 , year=
Cadsmith: Multi-agent cad generation with programmatic geometric validation , author=. arXiv preprint arXiv:2603.26512 , year=
-
[27]
arXiv preprint arXiv:2602.03045 , year=
Clarify Before You Draw: Proactive Agents for Robust Text-to-CAD Generation , author=. arXiv preprint arXiv:2602.03045 , year=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Infinibench: Infinite benchmarking for visual spatial reasoning with customizable scene complexity , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
The Fourteenth International Conference on Learning Representations , year=
Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration? , author=. The Fourteenth International Conference on Learning Representations , year=
-
[30]
arXiv preprint arXiv:2604.02580 , year=
VoxelCodeBench: Benchmarking 3D World Modeling Through Code Generation , author=. arXiv preprint arXiv:2604.02580 , year=
-
[31]
2026 , eprint=
3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code , author=. 2026 , eprint=
2026
-
[32]
arXiv preprint arXiv:2605.18430 , year=
Text2CAD-Bench: A Benchmark for LLM-based Text-to-Parametric CAD Generation , author=. arXiv preprint arXiv:2605.18430 , year=
-
[33]
arXiv preprint arXiv:2605.10865 , year=
BenchCAD: A Comprehensive, Industry-Standard Benchmark for Programmatic CAD , author=. arXiv preprint arXiv:2605.10865 , year=
-
[34]
arXiv preprint arXiv:2605.28579 , year=
MUSE: Benchmarking Manufacturable, Functional, and Assemblable Text-to-CAD Generation , author=. arXiv preprint arXiv:2605.28579 , year=
-
[35]
2026 , eprint=
UniCAD: A Unified Benchmark and Universal Model for Multi-Modal Multi-Task CAD , author=. 2026 , eprint=
2026
-
[36]
2021 , howpublished =
2021
-
[37]
Transactions on Machine Learning Research , issn=
Maxime Oquab and Timoth. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.