Next Forcing: Causal World Modeling with Multi-Chunk Prediction
Pith reviewed 2026-06-27 13:29 UTC · model grok-4.3
The pith
Next Forcing uses multi-chunk prediction modules to speed up training and inference in autoregressive video world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
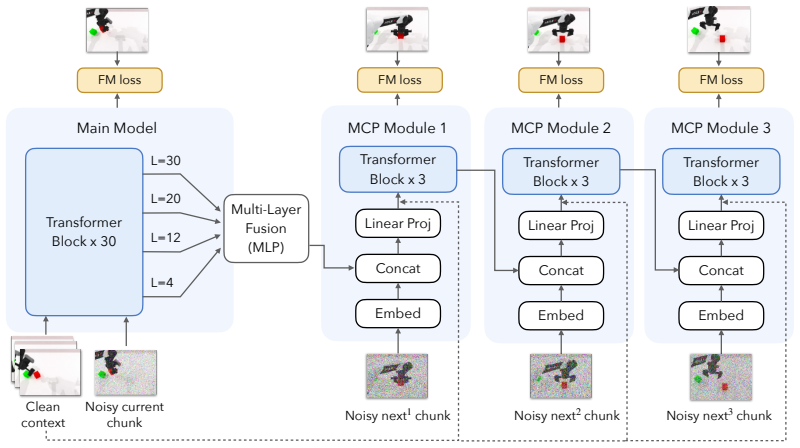
Next Forcing augments the main autoregressive video model with lightweight auxiliary MCP modules to simultaneously denoise video chunks at multiple future temporal horizons, forming a causal chain across prediction depths where intermediate features are fused to predict future dynamics and provide dense multi-scale temporal supervision back to the main model.
What carries the argument
Multi-chunk prediction (MCP) modules that denoise multiple future video chunks in a causal chain by fusing features from the main model to supply multi-scale temporal supervision.
If this is right
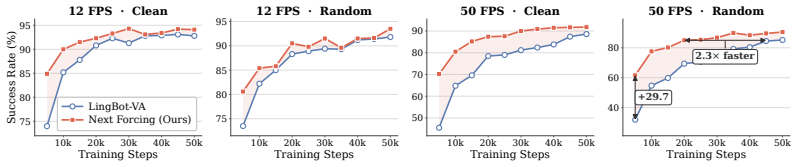
- At 50 fps, Next Forcing achieves a 93.1% relative improvement over LingBot-VA at 5k training steps.
- It demonstrates 2.3x faster convergence.
- It establishes new state-of-the-art results on the RoboTwin benchmark with 94.1% on Clean and 93.5% on Random.
- It achieves 2x inference acceleration by retaining the MCP modules.
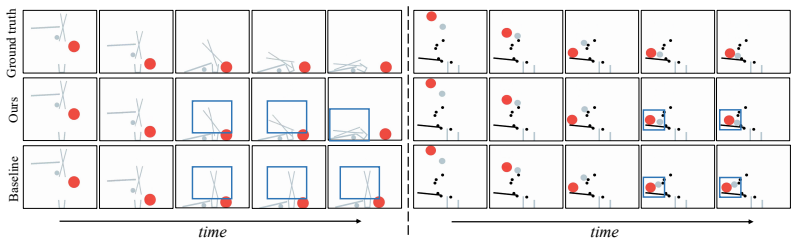
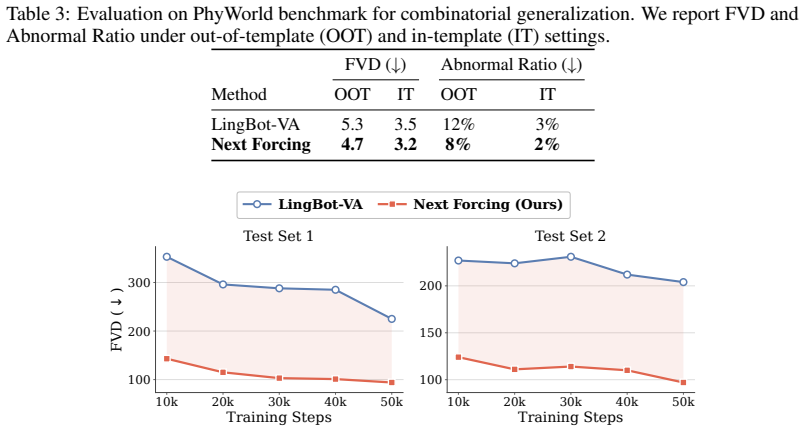
- It shows significant improvements on PhyWorld and over 50% FVD reduction on general video pretraining.
Where Pith is reading between the lines
- The causal chain structure could allow scaling to predict even more distant chunks for longer-term video forecasting.
- Parallel prediction during inference may enable deployment in real-time robotic planning systems.
- Improved physical adherence on PhyWorld suggests the method could be tested on other physics-based simulation benchmarks.
Load-bearing premise
The lightweight auxiliary MCP modules can be trained to extract and fuse useful intermediate features from the main model across multiple prediction depths without introducing training instability or degrading the quality of the primary single-chunk predictions.
What would settle it
Running the training at 50 fps and observing that the multi-chunk prediction modules do not accelerate convergence or improve accuracy compared to the baseline single-chunk approach would falsify the main benefit.
Figures
read the original abstract
Autoregressive video generation has emerged as a powerful paradigm for World Action Models (WAMs). However, existing approaches suffer from slow training convergence and limited converged accuracy, particularly at high frame rates, as the training supervision is confined to the current chunk without explicit signals about future dynamics; they also suffer from slow inference due to iterative video denoising. In this paper, we present Next Forcing, a multi-chunk prediction (MCP) framework for causal world modeling that enables faster training, higher accuracy, and accelerated inference. Inspired by multi-token prediction in large language models, Next Forcing introduces an MCP training objective that augments the main model with lightweight auxiliary MCP modules to simultaneously denoise video chunks at multiple future temporal horizons (next$^1$, next$^2$, next$^3$ chunks). These MCP modules form a causal chain across prediction depths, where intermediate features fused from multiple layers of the main model are leveraged to predict future dynamics, allowing near-future predictions to inform farther-future ones and providing dense multi-scale temporal supervision back to the main model. During training, the MCP modules significantly accelerate convergence and improve converged accuracy, especially at high frame rates: at 50 fps, Next Forcing achieves a 93.1% relative improvement over LingBot-VA at 5k training steps and 2.3x faster convergence, and establishes new state-of-the-art results on the RoboTwin benchmark (94.1/93.5% on Clean/Random). At inference, the MCP modules can be retained to predict the next video chunk in parallel with the current one, achieving 2x inference acceleration. Next Forcing also demonstrates significant improvements on PhyWorld, a benchmark evaluating adherence to physical laws in video generation, and over 50% FVD reduction on general video pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Next Forcing, a multi-chunk prediction (MCP) framework for autoregressive video generation in World Action Models. It augments the main model with lightweight auxiliary MCP modules that predict multiple future video chunks at different temporal horizons in a causal chain, using fused features from multiple layers of the main model to provide dense multi-scale temporal supervision. This is claimed to accelerate training convergence, improve accuracy at high frame rates (e.g., 93.1% relative improvement over LingBot-VA at 50 fps after 5k steps, 2.3x faster convergence), achieve new SOTA on RoboTwin (94.1/93.5% Clean/Random), improve on PhyWorld, reduce FVD by over 50% in general video pretraining, and enable 2x faster inference by retaining MCP modules for parallel chunk prediction.
Significance. If validated, this work could have substantial impact on the development of efficient causal world models for video. The extension of multi-token prediction to video chunks addresses a clear limitation in current autoregressive approaches regarding future dynamics supervision. The inference acceleration is a notable practical benefit. The empirical claims, if supported by rigorous experiments, would represent a meaningful advance in the field. However, the current presentation lacks the detailed experimental validation needed to fully gauge the significance.
major comments (2)
- [Abstract] Abstract: The central empirical claims, such as the 93.1% relative improvement and new SOTA results on RoboTwin, are presented without reference to specific experimental sections, tables, or figures detailing the setup, baselines, or variance, which is load-bearing for assessing the validity of the reported gains.
- [MCP framework] MCP framework: The assumption that the auxiliary MCP modules can be trained to extract and fuse useful intermediate features without introducing training instability or degrading primary predictions is central to the method but lacks supporting analysis or ablations in the manuscript.
minor comments (1)
- [Abstract] Clarify the exact meaning of 'next$^1$, next$^2$, next$^3$ chunks' with a brief definition or reference to a figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of Next Forcing's potential impact on causal world models. We address each major comment below and commit to revisions that strengthen the experimental presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims, such as the 93.1% relative improvement and new SOTA results on RoboTwin, are presented without reference to specific experimental sections, tables, or figures detailing the setup, baselines, or variance, which is load-bearing for assessing the validity of the reported gains.
Authors: We agree that explicit cross-references would improve traceability. In the revised manuscript we will insert concise pointers (e.g., “see Section 4.2 and Table 2”) into the abstract for the 93.1 % relative improvement, RoboTwin SOTA numbers, and convergence claims. We will also add a short reproducibility paragraph in Section 4 noting that all reported numbers are from single runs with fixed seeds; multi-seed variance will be reported if additional compute is obtained before camera-ready. revision: yes
-
Referee: [MCP framework] MCP framework: The assumption that the auxiliary MCP modules can be trained to extract and fuse useful intermediate features without introducing training instability or degrading primary predictions is central to the method but lacks supporting analysis or ablations in the manuscript.
Authors: The manuscript currently demonstrates the net benefit through end-to-end metrics, but dedicated stability and fusion ablations are indeed absent. We will add a new subsection (4.4) containing: (i) training-loss curves with and without MCP modules, (ii) an ablation on feature-fusion depth and layer selection, and (iii) a direct comparison of primary-prediction quality (FVD, accuracy) when MCP modules are present versus removed. These additions will be included in the revised submission. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces an MCP framework with auxiliary modules for multi-horizon video chunk prediction, drawing inspiration from multi-token prediction in LLMs. All reported gains (e.g., 93.1% relative improvement, 2.3x faster convergence, SOTA on RoboTwin, >50% FVD reduction) are presented as empirical outcomes on external benchmarks (RoboTwin, PhyWorld) rather than quantities defined by fitted parameters or self-citations. No equations appear that equate a claimed prediction to its own training objective by construction, and no load-bearing self-citations or uniqueness theorems are invoked. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffusion for world modeling: Visual details matter in atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[2]
Video PreTraining (VPT): Learning to act by watching unlabeled online videos
Bowen Baker, Ilge Akkaya, Peter Zhokhov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampedro, and Jeff Clune. Video PreTraining (VPT): Learning to act by watching unlabeled online videos. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[3]
Being-h0.7: A latent world-action model from egocentric videos.arXiv preprint arXiv:2605.00078, 2026
BeingBeyond Team. Being-h0.7: A latent world-action model from egocentric videos.arXiv preprint arXiv:2605.00078, 2026
Pith/arXiv arXiv 2026
-
[4]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[5]
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doer- sch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024
Pith/arXiv arXiv 2024
-
[6]
Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, and Jun Zhu. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[7]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
Pith/arXiv arXiv 2024
-
[8]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnik...
2023
-
[9]
Jake Bruce, Michael D. Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder...
2024
-
[10]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. In International Conference on Machine Learning (ICML), 2024
2024
-
[11]
Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025. 11
Pith/arXiv arXiv 2025
-
[12]
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, Hanbo Zhang, and Minzhao Zhu. GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
Pith/arXiv arXiv 2024
-
[13]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[14]
Kaijin Chen, Dingkang Liang, Xin Zhou, Yikang Ding, Xiaoqiang Liu, Pengfei Wan, and Xiang Bai. Out of sight but not out of mind: Hybrid memory for dynamic video world models.arXiv preprint arXiv:2603.25716, 2026
arXiv 2026
-
[15]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[16]
Moto: Latent motion token as the bridging language for robot manipulation
Yi Chen, Yuying Ge, Yizhuo Li, Yixiao Ge, Mingyu Ding, Ying Shan, and Xihui Liu. Moto: Latent motion token as the bridging language for robot manipulation. InProceedings of the IEEE/CVF international conference on computer vision, 2025
2025
-
[17]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[18]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
DeepSeek-AI. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[19]
Tenenbaum, Dale Schuurmans, and Pieter Abbeel
Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[20]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InInternational Conference on Machin...
2024
-
[21]
Wichmann
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
2020
-
[22]
Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
Gemini Robotics Team. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
Pith/arXiv arXiv 2025
-
[23]
Better & faster large language models via multi-token prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Synnaeve. Better & faster large language models via multi-token prediction. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[24]
Recurrent world models facilitate policy evolution
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution. In Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[25]
Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Pith/arXiv arXiv 2023
-
[26]
GAIA-1: A generative world model for autonomous driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. GAIA-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
Pith/arXiv arXiv 2023
-
[27]
Video prediction policy: A generalist robot policy with predictive visual representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. InInternational Conference on Machine Learning (ICML), 2025. 12
2025
-
[28]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[29]
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models.arXiv preprint arXiv:2505.12705, 2025
Pith/arXiv arXiv 2025
-
[30]
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954, 2024
arXiv 2024
-
[31]
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective.arXiv preprint arXiv:2411.02385, 2024
Pith/arXiv arXiv 2024
-
[32]
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[33]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. InConference on Robot Learning (C...
2024
-
[34]
Tenenbaum
Po-Chen Ko, Jiayuan Mao, Yilun Du, Shao-Hua Sun, and Joshua B. Tenenbaum. Learning to act from actionless videos through dense correspondences. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[35]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[36]
Causal world modeling for robot control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control. arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[37]
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, and Carl V ondrick. Dreamitate: Real-world visuomotor policy learning via video generation.arXiv preprint arXiv:2406.16862, 2024
arXiv 2024
-
[38]
Weixin Liang, Lili Yu, Liang Luo, Srinivasan Iyer, Ning Dong, Chunting Zhou, Gargi Ghosh, Mike Lewis, Wen-tau Yih, Luke Zettlemoyer, and Xi Victoria Lin. Mixture-of- transformers: A sparse and scalable architecture for multi-modal foundation models.arXiv preprint arXiv:2411.04996, 2024
Pith/arXiv arXiv 2024
-
[39]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[40]
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
Pith/arXiv arXiv 2025
-
[41]
RDT-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1b: a diffusion foundation model for bimanual manipulation. In International Conference on Learning Representations (ICLR), 2025
2025
-
[42]
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being-h0: Vision-language-action pretraining from large-scale human videos.arXiv preprint arXiv:2507.15597, 2025. 13
arXiv 2025
-
[43]
NVIDIA, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang ...
Pith/arXiv arXiv 2025
-
[44]
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic-video: Video-action models for generalizable robot control beyond VLAs.arXiv preprint arXiv:2512.15692, 2025
Pith/arXiv arXiv 2025
-
[45]
Physical Intelligence. π0.7: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[46]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
Pith/arXiv arXiv 2025
-
[47]
SpatialVLA: Exploring spatial representations for visual-language-action model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. SpatialVLA: Exploring spatial representations for visual-language-action model. InRobotics: Science and Systems (RSS), 2025
2025
-
[48]
Sequence level training with recurrent neural networks
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence level training with recurrent neural networks. InInternational Conference on Learning Representa- tions (ICLR), 2016
2016
-
[49]
Shuhuai Ren, Shuming Ma, Xu Sun, and Furu Wei. Next block prediction: Video generation via semi-autoregressive modeling.arXiv preprint arXiv:2502.07737, 2025
arXiv 2025
-
[50]
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. GAIA-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523, 2025
Pith/arXiv arXiv 2025
-
[51]
Learning to act without actions
Dominik Schmidt and Minqi Jiang. Learning to act without actions. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[52]
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, and Baining Guo. Videovla: Video generators can be generalizable robot manipulators.arXiv preprint arXiv:2512.06963, 2025
arXiv 2025
-
[53]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[54]
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation.arXiv preprint arXiv:2412.15109, 2024
Pith/arXiv arXiv 2024
-
[55]
Towards accurate generative models of video: A new metric & challenges
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
Pith/arXiv arXiv 2018
-
[56]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[57]
Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers
Lirui Wang, Xinlei Chen, Jialiang Zhao, and Kaiming He. Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 14
2024
-
[58]
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, and Jian Tang. TinyVLA: Towards fast, data-efficient vision-language-action models for robotic manipulation.arXiv preprint arXiv:2409.12514, 2024
Pith/arXiv arXiv 2024
-
[59]
John Won, Kyungmin Lee, Huiwon Jang, Dongyoung Kim, and Jinwoo Shin. Dual- stream diffusion for world-model augmented vision-language-action model.arXiv preprint arXiv:2510.27607, 2025
Pith/arXiv arXiv 2025
-
[60]
Unleashing large-scale video generative pre-training for visual robot manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[61]
Magma: A foundation model for multimodal AI agents
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, Yuquan Deng, Lars Liden, and Jianfeng Gao. Magma: A foundation model for multimodal AI agents. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[62]
World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
Pith/arXiv arXiv 2026
-
[63]
Latent action pretraining from videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, and Minjoon Seo. Latent action pretraining from videos. In International Conference on Learning Representations (ICLR), 2025
2025
-
[64]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025
2025
-
[65]
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-W AM: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[66]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Tsung-Yi Lin, Gordon Wetzstein, Ming-Yu Liu, and Donglai Xiang. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[67]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems (RSS), 2023
2023
-
[68]
3D-VLA: A 3D vision-language-action generative world model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3D-VLA: A 3D vision-language-action generative world model. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[69]
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, and Xianyuan Zhan. X-VLA: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[70]
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies.arXiv preprint arXiv:2412.10345, 2024
Pith/arXiv arXiv 2024
-
[71]
Exploring the limits of vision-language-action manipulation in cross-task generalization.Advances in Neural Information Processing Systems (NeurIPS), 38:139899– 139927, 2026
Jiaming Zhou, Ke Ye, Jiayi Liu, Teli Ma, Zifan Wang, Ronghe Qiu, Kun-Yu Lin, Zhilin Zhao, and Junwei Liang. Exploring the limits of vision-language-action manipulation in cross-task generalization.Advances in Neural Information Processing Systems (NeurIPS), 38:139899– 139927, 2026. 15
2026
-
[72]
cX# nX!nX
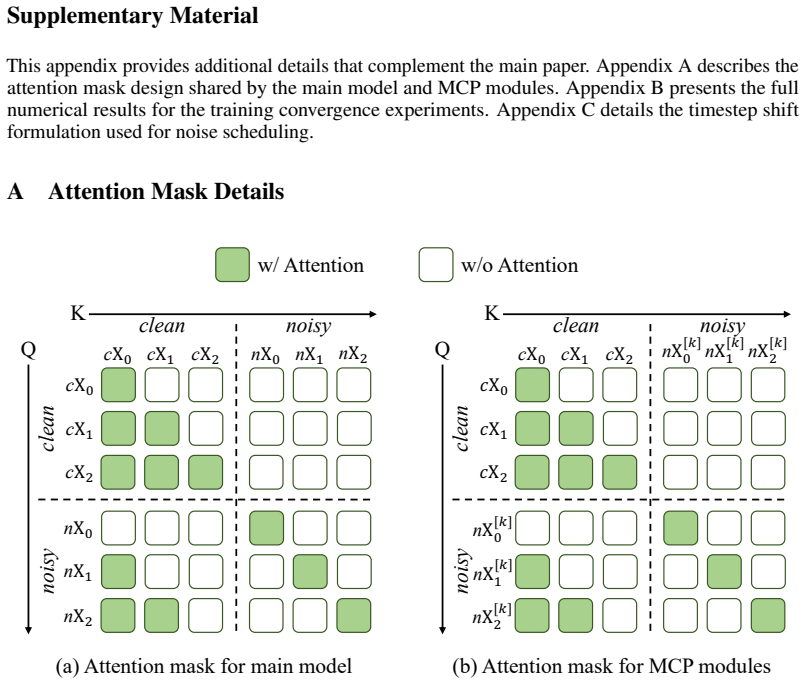
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. InRobotics: Science and Systems (RSS), 2025. 16 Supplementary Material This appendix provides additional details that complement the main paper. Appendix A describes...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.