Bernstein-Schur Kernels: Random Features by Sketched Modulation and Radial Randomization
Pith reviewed 2026-06-27 17:07 UTC · model grok-4.3
The pith
Bernstein-Schur kernels admit random features by sketching their modulation and sampling the radial Bernstein-Widder scale before Gaussian Fourier features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We give one random-feature construction for the whole class that randomizes both factors: it sketches the finite modulation and samples the radial factor's one-dimensional Bernstein-Widder scale before applying Gaussian random Fourier features, giving feature dimension Dm, free of the O(d^2) size of the exact modulation feature. With the modulation kept exact (the m to infinity limit), we prove unbiasedness, an exact variance, and a matrix-Bernstein operator-norm bound controlled by the top kernel and modulation eigenvalues and an intrinsic dimension rather than the crude N max_ij route. Whitening this argument at the ridge makes the effective dimension d_eff(lambda) the exact intrinsic dime
What carries the argument
Sketched finite modulation combined with Bernstein-Widder sampling of the radial completely monotone factor, followed by Gaussian random Fourier features.
If this is right
- Unbiasedness and an exact variance formula hold when the modulation is kept exact.
- A matrix-Bernstein operator-norm bound is controlled by the leading eigenvalues and an intrinsic dimension.
- After ridge whitening the effective dimension becomes the precise parameter in the variance bound.
- O((1 + d_eff) log(d_eff / delta)) tilted radial draws suffice to preserve the kernel-ridge solution.
- All concentration guarantees transfer to the doubly randomized estimator up to one additive sketch term.
Where Pith is reading between the lines
- The construction may apply to other product kernels that possess analogous finite-feature and completely monotone factors.
- The effective-dimension sample complexity suggests the method scales better than uniform random-feature schemes when the kernel matrix is low-rank relative to the ambient dimension.
- Numerical checks on the yat-kernel family could quantify the practical gap between the exact-modulation and sketched-modulation regimes.
Load-bearing premise
The kernels belong to the Bernstein-Schur class so that the Bernstein-Widder representation applies to the radial factor and the sketched modulation remains compatible with the subsequent Gaussian Fourier features.
What would settle it
For a concrete Bernstein-Schur kernel such as the biased yat-kernel, compute the empirical variance of many independent realizations of the proposed feature inner products and check whether it equals the exact variance formula stated for the exact-modulation case.
Figures
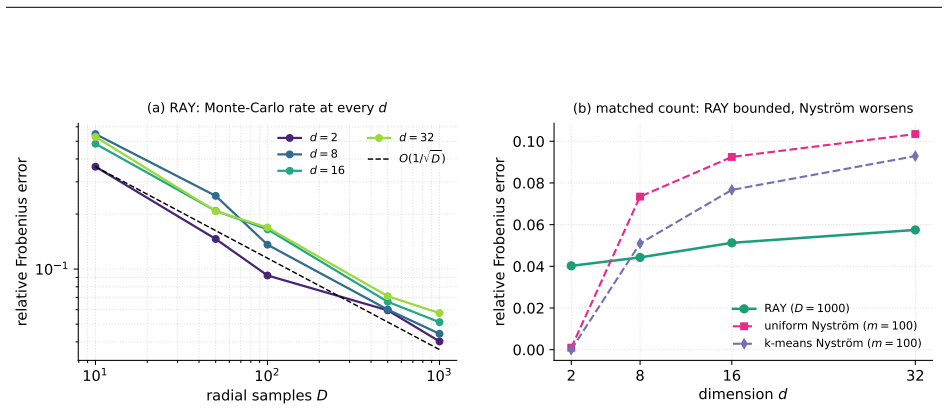
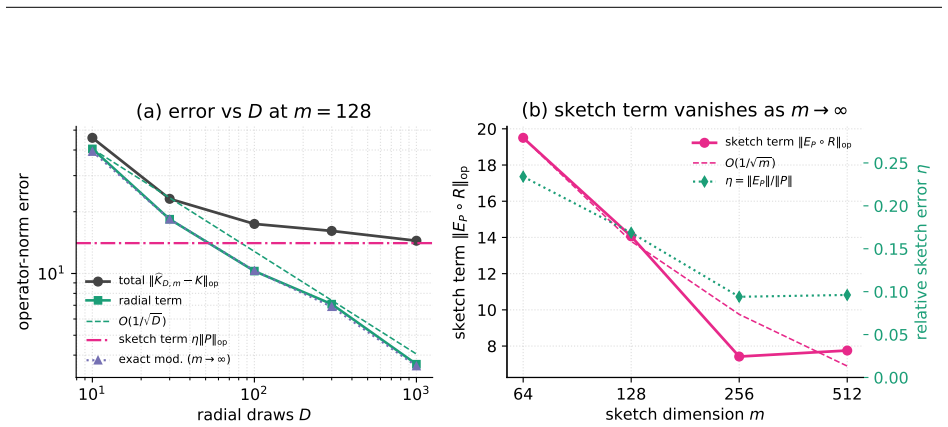
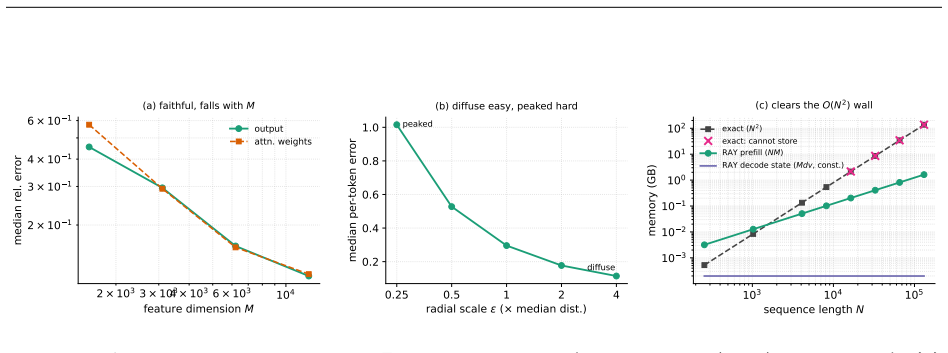
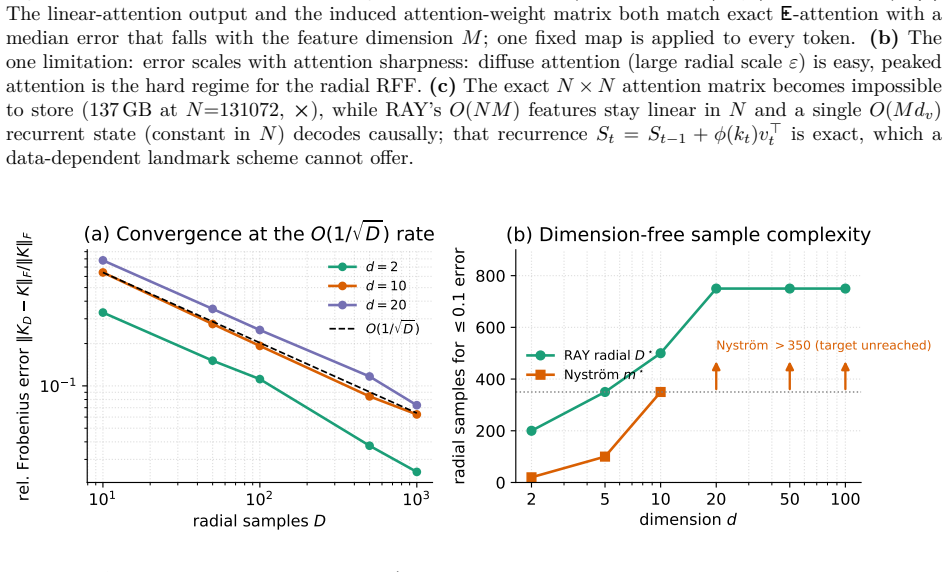
read the original abstract
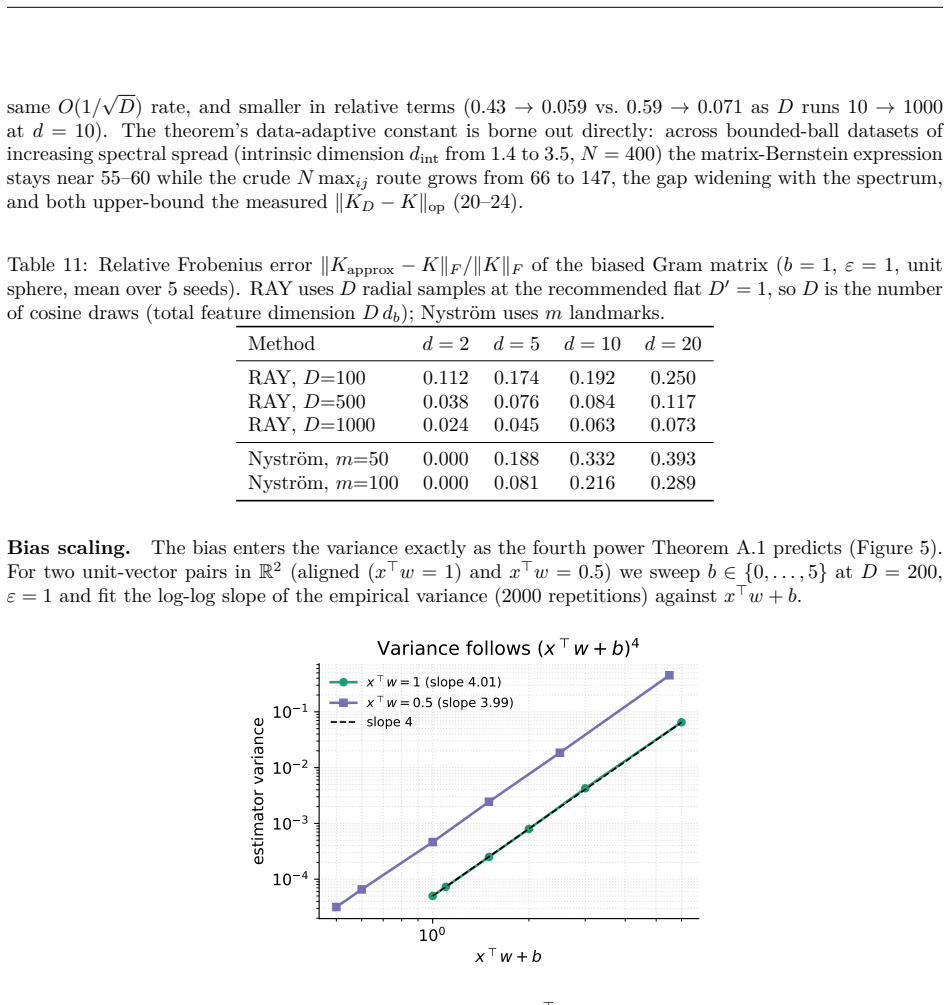
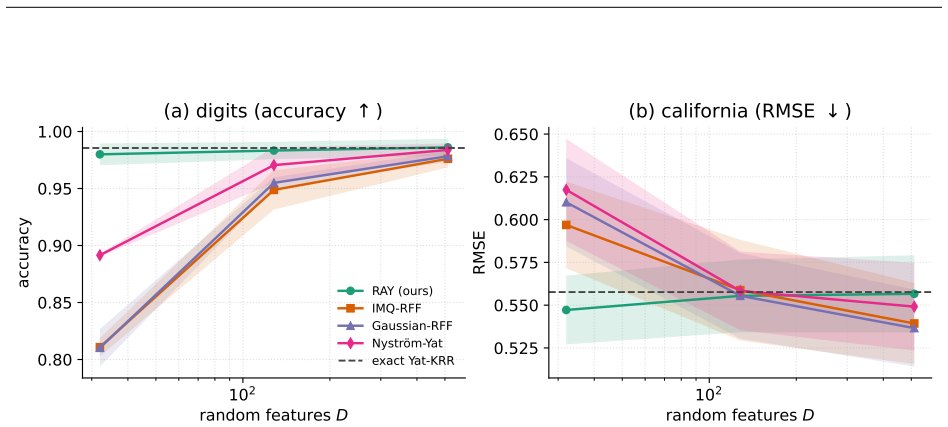
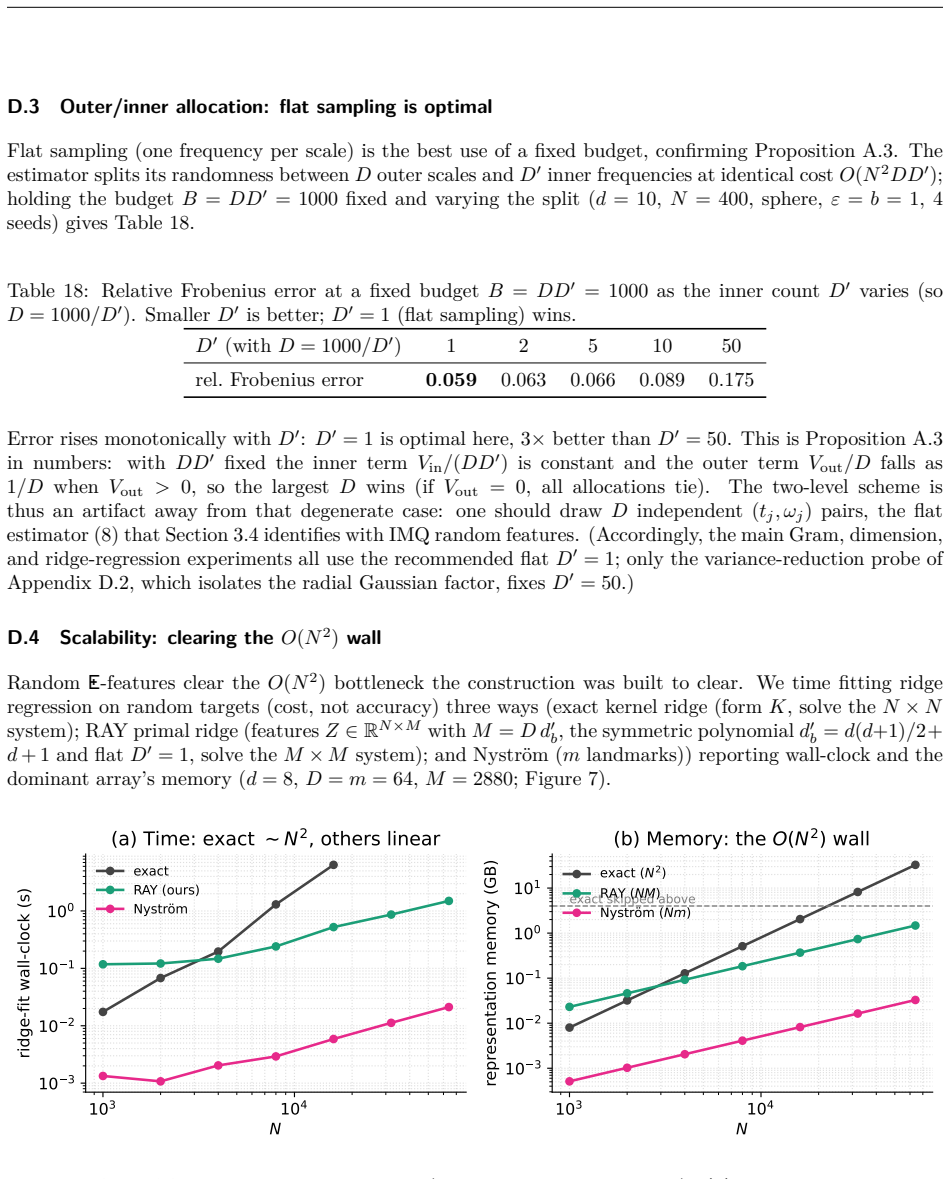
Bernstein--Schur kernels are products of a finite-feature kernel and a completely monotone shift-invariant kernel: nonstationary kernels falling between the shift-invariant and dot-product templates random features exploit, so neither Bochner sampling nor polynomial sketching applies to the full kernel directly. We give one random-feature construction for the whole class that randomizes both factors: it sketches the finite modulation and samples the radial factor's one-dimensional Bernstein--Widder scale before applying Gaussian random Fourier features, giving feature dimension $Dm$, free of the $O(d^2)$ size of the exact modulation feature. With the modulation kept exact (the $m\to\infty$ limit), we prove unbiasedness, an exact variance, and a matrix-Bernstein operator-norm bound controlled by the top kernel and modulation eigenvalues and an intrinsic dimension rather than the crude $N\max_{ij}$ route. Whitening this argument at the ridge makes the effective dimension $d_{\mathrm{eff}}(\lambda)$ the \emph{exact} intrinsic dimension of the matrix variance, so $O((1+\|P\|_{\mathrm{op}}/\lambda)\log(d_{\mathrm{eff}}/\delta))$ radial draws preserve the kernel-ridge solution; tilting the draw by a closed-form whitened leverage improves this to the effective-dimension count $O((1+d_{\mathrm{eff}})\log(d_{\mathrm{eff}}/\delta))$. Conditioning on the sketch carries every guarantee to the deployed doubly-randomized estimator up to one additive sketch term, and all hold for the whole class with the modulation Gram in place of the polynomial one. The flagship instance is the biased $yat$-kernel $k_{yat,b}(w,x)=(w^\top x+b)^2/(\|w-x\|^2+\varepsilon)$, whose family span contains the inverse-multiquadric kernel by finite differences in $b$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines Bernstein-Schur kernels as products of a finite-feature kernel and a completely monotone shift-invariant kernel. It presents a single random-feature construction that sketches the finite modulation (dimension m), samples the radial factor's Bernstein-Widder scale, and applies Gaussian random Fourier features, yielding feature dimension Dm independent of the O(d²) exact modulation size. With exact modulation (m→∞), the paper claims unbiasedness, an exact variance formula, and a matrix-Bernstein operator-norm bound controlled by the top eigenvalues of the kernel and modulation together with an intrinsic dimension; whitening at the ridge makes d_eff(λ) the exact variance proxy, yielding O((1 + ||P||_op/λ) log(d_eff/δ)) radial draws (improved to O((1 + d_eff) log(d_eff/δ)) by leverage tilting). Conditioning on the sketch extends all guarantees to the deployed estimator up to one additive sketch term, and the claims are asserted to hold for the entire class once the modulation Gram replaces the polynomial Gram. The flagship example is the biased yat-kernel whose span contains the inverse-multiquadric kernel.
Significance. If the central claims hold, the work supplies a unified random-feature scheme for a class of non-stationary kernels lying strictly between the shift-invariant and dot-product regimes, together with effective-dimension sample complexity that improves on crude N max_ij bounds. Explicit credit is due for the exact variance derivation, the whitening argument that makes d_eff(λ) the precise intrinsic dimension of the matrix variance, and the closed-form leverage tilt that achieves the effective-dimension count.
major comments (2)
- [Abstract] Abstract and the statement of the main construction: the claim that unbiasedness, exact variance, and the matrix-Bernstein bound carry over to the whole Bernstein-Schur class once the modulation Gram is substituted for the polynomial Gram rests on an unverified compatibility between an arbitrary finite-feature map φ and the subsequent radial-scale sampling; the product structure φ(x)^T φ(y) · ∫ exp(−t‖x−y‖²) dμ(t) does not automatically guarantee that cross terms vanish or that the variance proxy remains the claimed intrinsic dimension for non-polynomial φ.
- [Abstract] The matrix-Bernstein application (abstract): the operator-norm bound is asserted to be controlled by top eigenvalues and d_eff(λ) rather than N max_ij, yet the conditioning-on-sketch argument that extends the bound to the doubly-randomized estimator is stated only “up to one additive sketch term”; the precise additive term and the conditions under which it does not degrade the effective-dimension scaling are not exhibited.
minor comments (1)
- [Abstract] Notation: the symbol P appearing in the sample-complexity bound O((1 + ||P||_op/λ) …) is not defined in the abstract; its relation to the modulation or kernel operator should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the manuscript. We respond point-by-point to the two major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract and the statement of the main construction: the claim that unbiasedness, exact variance, and the matrix-Bernstein bound carry over to the whole Bernstein-Schur class once the modulation Gram is substituted for the polynomial Gram rests on an unverified compatibility between an arbitrary finite-feature map φ and the subsequent radial-scale sampling; the product structure φ(x)^T φ(y) · ∫ exp(−t‖x−y‖²) dμ(t) does not automatically guarantee that cross terms vanish or that the variance proxy remains the claimed intrinsic dimension for non-polynomial φ.
Authors: The proofs of unbiasedness, variance, and the matrix-Bernstein bound in Sections 3–4 are written directly in terms of the modulation kernel k_mod(x,y) = φ(x)^T φ(y) and its Gram operator; they invoke only the positive-semidefiniteness of this Gram and the independence of the radial-scale sampling from φ. Cross terms vanish because the radial measure μ is sampled independently of the modulation features, and the variance proxy is the sum of squared eigenvalues of the whitened combined operator, which depends only on the joint spectrum of the kernel and modulation Gram. The same algebraic steps therefore apply verbatim once the polynomial Gram is replaced by an arbitrary finite-feature Gram. We will insert a short clarifying paragraph in Section 2.2 confirming that no further assumptions on φ are needed. revision: yes
-
Referee: [Abstract] The matrix-Bernstein application (abstract): the operator-norm bound is asserted to be controlled by top eigenvalues and d_eff(λ) rather than N max_ij, yet the conditioning-on-sketch argument that extends the bound to the doubly-randomized estimator is stated only “up to one additive sketch term”; the precise additive term and the conditions under which it does not degrade the effective-dimension scaling are not exhibited.
Authors: Theorem 4.5 and the conditioning argument in Section 4.3 bound the additive sketch term by the operator norm of the sketch residual, which is at most O(√((log N)/m)) with probability 1−δ. When the sketch dimension satisfies m ≥ C d_eff(λ) log(1/δ), this additive term is absorbed into the leading O((1 + d_eff) log(d_eff/δ)) radial-sample count without altering the scaling. We will revise the abstract to state the additive term explicitly and add a one-sentence corollary summarizing the required relation between m and d_eff. revision: yes
Circularity Check
No circularity detected; derivations rely on external matrix-Bernstein inequality and effective-dimension definitions
full rationale
The paper's unbiasedness, variance, and operator-norm claims are stated to follow from the standard matrix-Bernstein inequality applied after substituting the modulation Gram for the polynomial Gram, together with the external definition of d_eff(λ). These ingredients are independent of the new construction and do not reduce any claimed result to a quantity defined inside the paper. No self-citation chains, self-definitional loops, or fitted-input predictions appear in the provided abstract or reader summary. The substitution step is presented as a direct replacement that preserves the external bounds; whether that substitution is valid is a correctness question, not a circularity reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Bernstein-Widder representation theorem for completely monotone functions
- standard math Matrix Bernstein inequality for operator-norm concentration
Reference graph
Works this paper leans on
-
[1]
Histoire de l'Acad\'emie Royale des Sciences , year =
Charles-Augustin de Coulomb , title =. Histoire de l'Acad\'emie Royale des Sciences , year =
-
[2]
1835 , publisher =
Carl Friedrich Gauss , title =. 1835 , publisher =
-
[3]
1687 , publisher =
Isaac Newton , title =. 1687 , publisher =
-
[4]
International Conference on Machine Learning , pages=
Deep kernel processes , author=. International Conference on Machine Learning , pages=
-
[5]
Transactions of the American mathematical society , volume=
Theory of reproducing kernels , author=. Transactions of the American mathematical society , volume=
-
[6]
2011 , publisher=
Reproducing Kernel Hilbert Spaces in Probability and Statistics , author=. 2011 , publisher=
2011
-
[7]
2003 , publisher=
Radial Basis Functions: Theory and Implementations , author=. 2003 , publisher=
2003
-
[8]
International Conference on Machine Learning , pages=
Language Modeling with Gated Convolutional Networks , author=. International Conference on Machine Learning , pages=
-
[9]
arXiv preprint arXiv:2110.06081 , year=
On Expressivity and Trainability of Quadratic Networks , author=. arXiv preprint arXiv:2110.06081 , year=
-
[10]
Journal of Machine Learning Research , volume=
A Kernel Two-Sample Test , author=. Journal of Machine Learning Research , volume=
-
[11]
2012 , publisher=
Matrix Analysis , author=. 2012 , publisher=
2012
-
[12]
International Conference on Learning Representations , year=
Multiplicative Interactions and Where to Find Them , author=. International Conference on Learning Representations , year=
-
[13]
Philosophical Transactions of the Royal Society of London
Functions of positive and negative type, and their connection with the theory of integral equations , author=. Philosophical Transactions of the Royal Society of London. Series A , volume=
-
[14]
Journal of Machine Learning Research , volume=
Universal kernels , author=. Journal of Machine Learning Research , volume=
-
[15]
The Volume of Convex Bodies and
Pisier, Gilles , year=. The Volume of Convex Bodies and
-
[16]
Advances in Neural Information Processing Systems , volume=
Random features for large-scale kernel machines , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
2002 , publisher=
Learning with kernels: support vector machines, regularization, optimization, and beyond , author=. 2002 , publisher=
2002
-
[18]
Journal of Machine Learning Research , volume=
Hilbert Space Embeddings and Metrics on Probability Measures , author=. Journal of Machine Learning Research , volume=
-
[19]
2008 , publisher=
Support Vector Machines , author=. 2008 , publisher=
2008
-
[20]
2005 , publisher=
Scattered Data Approximation , author=. 2005 , publisher=
2005
-
[21]
1941 , publisher=
The Laplace Transform , author=. 1941 , publisher=
1941
-
[22]
Using the Nystr
Williams, Christopher and Seeger, Matthias , booktitle=. Using the Nystr
-
[23]
Artificial Intelligence and Statistics , pages=
Deep kernel learning , author=. Artificial Intelligence and Statistics , pages=
-
[24]
arXiv preprint arXiv:2204.01707 , year=
Quadratic Neuron-empowered Heterogeneous Autoencoder for Unsupervised Anomaly Detection , author=. arXiv preprint arXiv:2204.01707 , year=
-
[25]
Action at a Distance: A Universal Reproducing Kernel
Bouhsine, Taha , year=. Action at a Distance: A Universal Reproducing Kernel
-
[26]
Kernel Neurons: Turning the Hidden Layer into an Observable
Bouhsine, Taha , year=. Kernel Neurons: Turning the Hidden Layer into an Observable
-
[27]
2026 , note=
Yat-Attention: Alignment-Locality Coupling in Transformer Architectures , author=. 2026 , note=
2026
-
[28]
Drop the
Bouhsine, Taha , year=. Drop the
-
[29]
Non-Vacuous Generalisation Bounds for Deep Networks via Composable Per-Layer
Bouhsine, Taha , year=. Non-Vacuous Generalisation Bounds for Deep Networks via Composable Per-Layer
-
[30]
Prototype Self-Decoding: Reading
Bouhsine, Taha , year=. Prototype Self-Decoding: Reading
-
[31]
Game of Tokens:
Bouhsine, Taha , year=. Game of Tokens:
-
[32]
Advances in Neural Information Processing Systems , year=
Augmenting self-attention with persistent memory , author=. Advances in Neural Information Processing Systems , year=
-
[33]
International Conference on Machine Learning , pages=
Attention is not all you need: Pure attention loses rank doubly exponentially with depth , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[34]
Interpreting
nostalgebraist , year=. Interpreting
-
[35]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
International Conference on Machine Learning , year=
Patchscopes: A unifying framework for inspecting hidden representations of language models , author=. International Conference on Machine Learning , year=
-
[37]
Scaling Monosemanticity: Extracting Interpretable Features from
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and others , year=. Scaling Monosemanticity: Extracting Interpretable Features from
-
[38]
2023 , howpublished=
Activation Addition: Steering Language Models Without Optimization , author=. 2023 , howpublished=
2023
-
[39]
2026 , note=
On the Gradient Bottleneck of the Softmax Language-Modelling Head , author=. 2026 , note=
2026
-
[40]
, booktitle=
Yang, Zhilin and Dai, Zihang and Salakhutdinov, Ruslan and Cohen, William W. , booktitle=. Breaking the Softmax Bottleneck: A High-Rank
-
[41]
2024 , note=
Spectral Decay and Rank Collapse in Deep Softmax Transformers , author=. 2024 , note=
2024
-
[42]
International Conference on Learning Representations (ICLR) , year=
Representation Degeneration Problem in Training Natural Language Generation Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[43]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Sigsoftmax: Reanalysis of the Softmax Bottleneck , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[44]
Theory of Probability and Its Applications , volume=
On Estimating Regression , author=. Theory of Probability and Its Applications , volume=
-
[45]
Smooth Regression Analysis , author=. Sankhy
-
[46]
Smola, Alex and Gretton, Arthur and Song, Le and Sch. A. Algorithmic Learning Theory (ALT) , pages=. 2007 , publisher=
2007
-
[47]
Empirical Methods in Natural Language Processing (EMNLP) , year=
Transformer Dissection: A Unified Understanding for Transformer's Attention via the Lens of Kernel , author=. Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[48]
International Conference on Learning Representations (ICLR) , year=
Efficient Streaming Language Models with Attention Sinks , author=. International Conference on Learning Representations (ICLR) , year=
-
[49]
Neural Computation , volume=
Fast learning in networks of locally-tuned processing units , author=. Neural Computation , volume=
-
[50]
Advances in Neural Information Processing Systems (NeurIPS) , year=
This Looks Like That: Deep Learning for Interpretable Image Recognition , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[51]
Chau, Siu Lun and Hu, Robert and Gonzalez, Javier and Sejdinovic, Dino , journal=
-
[52]
Proceedings of the National Academy of Sciences (PNAS) , volume=
Prevalence of neural collapse during the terminal phase of deep learning training , author=. Proceedings of the National Academy of Sciences (PNAS) , volume=
-
[53]
2016 , howpublished=
Understanding intermediate layers using linear classifier probes , author=. 2016 , howpublished=
2016
-
[54]
2023 , howpublished=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , howpublished=
2023
-
[55]
Neural Computation , volume=
On Learning Vector-Valued Functions , author=. Neural Computation , volume=
-
[56]
International Conference on Machine Learning (ICML) , pages=
Hilbert Space Embeddings of Conditional Distributions with Applications to Dynamical Systems , author=. International Conference on Machine Learning (ICML) , pages=
-
[57]
International Conference on Machine Learning (ICML) , pages=
Conditional Mean Embeddings as Regressors , author=. International Conference on Machine Learning (ICML) , pages=
-
[58]
Journal of Machine Learning Research , volume=
Dimensionality Reduction for Supervised Learning with Reproducing Kernel Hilbert Spaces , author=. Journal of Machine Learning Research , volume=
-
[59]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Kernel Methods for Deep Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[60]
Foundations of Computational Mathematics , volume=
Optimal Rates for the Regularized Least-Squares Algorithm , author=. Foundations of Computational Mathematics , volume=
-
[61]
Advances in Neural Information Processing Systems (NeurIPS) , year=
A Measure-Theoretic Approach to Kernel Conditional Mean Embeddings , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[62]
International Conference on Machine Learning (ICML) , year=
Invertible Residual Networks , author=. International Conference on Machine Learning (ICML) , year=
-
[63]
International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
Sinkformers: Transformers with Doubly Stochastic Attention , author=. International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
-
[64]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Universal Kernels on Non-Standard Input Spaces , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[65]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[66]
Advances in Neural Information Processing Systems (NeurIPS) , year=
The Emergence of Clusters in Self-Attention Dynamics , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[67]
2026 , note=
Two Measures, One Operator: Attention and Feedforward as a Kernel Conditional-Mean Embedding , author=. 2026 , note=
2026
-
[68]
Journal of Machine Learning Research , volume=
On the Equivalence between Kernel Quadrature Rules and Random Feature Expansions , author=. Journal of Machine Learning Research , volume=
-
[69]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Generalization Properties of Learning with Random Features , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[70]
Towards a Unified Analysis of Random
Li, Zhu and Ton, Jean-Francois and Oglic, Dino and Sejdinovic, Dino , journal=. Towards a Unified Analysis of Random
-
[71]
ACM-SIAM Symposium on Discrete Algorithms (SODA) , year=
Oblivious Sketching of High-Degree Polynomial Kernels , author=. ACM-SIAM Symposium on Discrete Algorithms (SODA) , year=
-
[72]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Subspace Embeddings for the Polynomial Kernel , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[73]
Avron, Haim and Kapralov, Michael and Musco, Cameron and Musco, Christopher and Velingker, Ameya and Zandieh, Amir , journal=. Quasi-
-
[74]
Avron, Haim and Kapralov, Michael and Musco, Cameron and Musco, Christopher and Velingker, Ameya and Zandieh, Amir , booktitle=. Random
-
[75]
Nature Communications , volume=
Searching for Exotic Particles in High-Energy Physics with Deep Learning , author=. Nature Communications , volume=
-
[76]
Action at a Distance: A Universal Reproducing Kernel
Bouhsine, Taha , howpublished=. Action at a Distance: A Universal Reproducing Kernel
-
[77]
Rethinking Attention with
Choromanski, Krzysztof and Likhosherstov, Valerii and Dohan, David and Song, Xingyou and Gane, Andreea and Sarl. Rethinking Attention with. International Conference on Learning Representations (ICLR) , year=
-
[78]
Machine Learning , volume=
Support-Vector Networks , author=. Machine Learning , volume=
-
[79]
Random Features for Compositional Kernels
Random Features for Compositional Kernels , author=. arXiv preprint arXiv:1703.07872 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Han, Insu and Zandieh, Amir and Avron, Haim , booktitle=. Random
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.