3D-CBM: A Framework for Concept-Based Interpretability in Generative 3D Modeling
Pith reviewed 2026-06-27 13:08 UTC · model grok-4.3
The pith
A 3D concept bottleneck maps raw geometry to human concepts and permits test-time fixes to generated shapes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
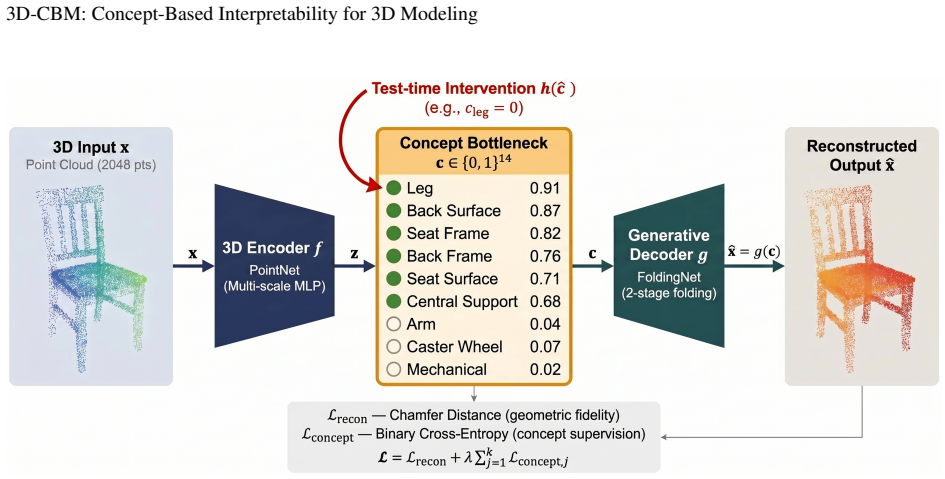
The 3D-CBM architecture maps unstructured geometric inputs into a multi-tiered taxonomy of interpretable primitives and attributes, thereby enabling precise test-time intervention that corrects structural errors while preserving low reconstruction error.
What carries the argument
The concept bottleneck layer inserted between the encoder and decoder that constrains the latent space to align with the predefined concept taxonomy.
If this is right
- Generated 3D parts become editable by changing the value of an individual concept at inference time.
- The same architecture can be trained on PartNet and ShapeNet without requiring new supervision schemes.
- Human operators gain a direct channel to steer output geometry without modifying the underlying generative weights.
Where Pith is reading between the lines
- The same bottleneck idea could be tested on generative models for other unstructured data such as voxel grids or implicit surfaces.
- If the taxonomy proves stable, downstream tasks like part retrieval or functional analysis might inherit the same intervention capability.
- Real-world deployment would require checking whether the learned concepts transfer to noisy sensor data rather than clean synthetic meshes.
Load-bearing premise
Raw point clouds and meshes can be reliably mapped to a fixed hierarchy of human concepts that remains consistent across different object datasets.
What would settle it
A controlled test in which an intervention on a predicted concept fails to reduce the structural error of the output shape or drops concept accuracy below 80 percent on held-out shapes.
Figures

read the original abstract
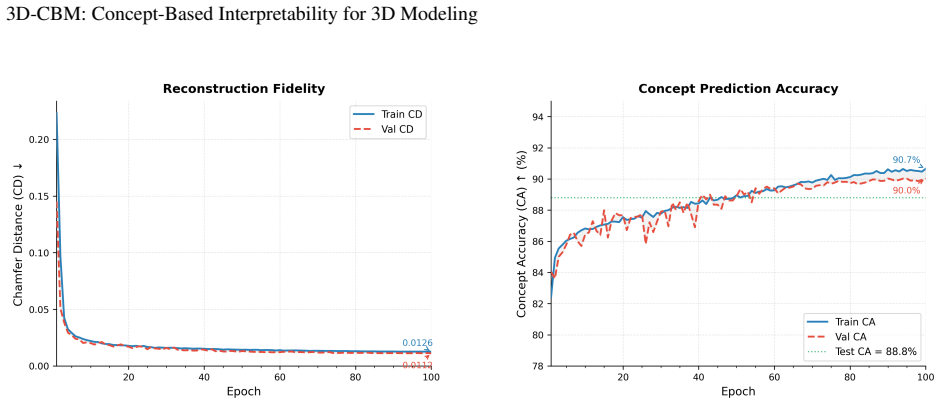
This research introduces a framework for incorporating Concept Bottleneck Models (CBMs) into 3D generative architectures to address the inherent 'semantic gap' in deep geometric learning. As deep models become central to 3D content creation, explainability shifts from a peripheral feature to a fundamental requirement for trust and accountability in safety-critical domains such as healthcare and manufacturing. CBMs provide an intrinsic interpretability solution by constraining latent representations to align with human-defined concepts, yet their application to unstructured 3D data remains largely unexplored. We design, implement, and validate a formal 3D-CBM architecture that maps raw geometric inputs, including point clouds and meshes, into a multi-tiered taxonomy of interpretable primitives and functional attributes. The framework further identifies strategic datasets, such as PartNet and ShapeNet, specialized for concept-based supervision. Experimental results from a 3D part-manipulation proof-of-concept experiment demonstrate the framework's efficacy, achieving a concept prediction accuracy of 88.8\% and a Chamfer Distance of 0.0115. Critically, the model enables precise test-time intervention, allowing for the interactive correction of structural errors. This work establishes a foundation for semantically-steerable 3D generation and invites further exploration into collaborative human-in-the-loop design systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the 3D-CBM framework to integrate Concept Bottleneck Models into 3D generative architectures, mapping raw geometric inputs (point clouds, meshes) to a multi-tiered taxonomy of human-defined concepts and functional attributes. It identifies PartNet and ShapeNet as suitable datasets and reports results from a 3D part-manipulation proof-of-concept experiment: 88.8% concept prediction accuracy, Chamfer Distance of 0.0115, and the ability to perform precise test-time intervention for correcting structural errors.
Significance. If the experimental claims hold under proper validation, the work could establish a foundation for semantically steerable 3D generation and human-in-the-loop systems, addressing the semantic gap in deep geometric learning for safety-critical domains. The reported test-time intervention capability is a potentially useful strength if supported by reproducible code or detailed intervention protocols.
major comments (2)
- [Abstract] Abstract: The headline results (88.8% concept prediction accuracy and Chamfer Distance 0.0115) are stated without any description of the model architecture, training procedure, concept taxonomy definition, baselines, ablation studies, or error analysis. This absence makes it impossible to evaluate whether the numbers support the central claim of effective concept-based interpretability and test-time intervention.
- [Abstract] Abstract: No details are provided on how raw geometric inputs are mapped to the multi-tiered taxonomy or how the taxonomy is constructed and supervised, leaving the weakest assumption (reliable generalization across PartNet and ShapeNet) unexamined and untested in the presented text.
minor comments (1)
- [Abstract] The abstract uses informal phrasing such as 'semantic gap' in quotes and 'invites further exploration' without specifying concrete open questions or limitations.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract. We agree that the abstract as currently written is too concise and lacks key contextual details needed to evaluate the claims. We will revise the abstract in the next version to address these points directly while keeping it within length limits. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline results (88.8% concept prediction accuracy and Chamfer Distance 0.0115) are stated without any description of the model architecture, training procedure, concept taxonomy definition, baselines, ablation studies, or error analysis. This absence makes it impossible to evaluate whether the numbers support the central claim of effective concept-based interpretability and test-time intervention.
Authors: We agree that the abstract does not include these details. The full manuscript provides the 3D-CBM architecture in Section 3, training procedure and supervision in Section 4, and the proof-of-concept results (including the reported metrics) in Section 5. No baselines or ablations are claimed in the abstract because the work is presented as a framework introduction with a targeted intervention experiment rather than a comparative benchmark study. To resolve the concern, we will expand the abstract with one or two sentences summarizing the architecture, the multi-tiered taxonomy, and the intervention protocol. revision: yes
-
Referee: [Abstract] Abstract: No details are provided on how raw geometric inputs are mapped to the multi-tiered taxonomy or how the taxonomy is constructed and supervised, leaving the weakest assumption (reliable generalization across PartNet and ShapeNet) unexamined and untested in the presented text.
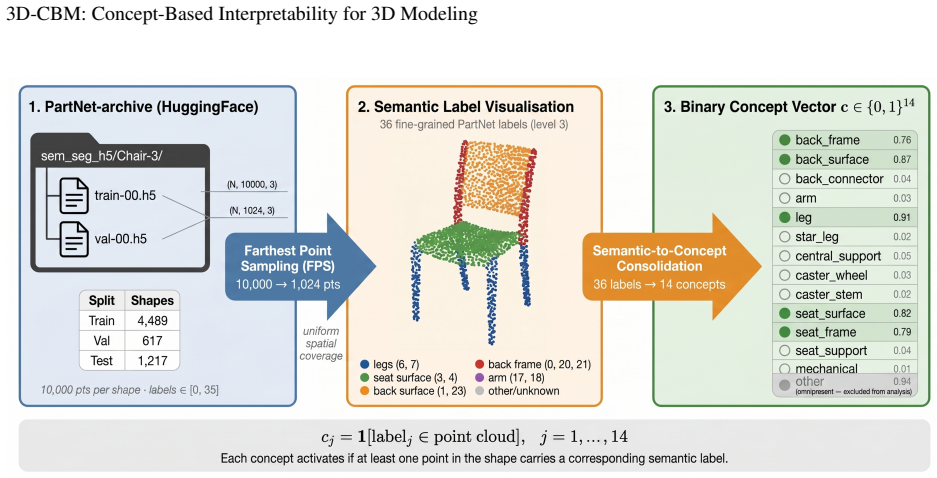
Authors: We acknowledge the observation. The abstract omits the mapping mechanism and taxonomy construction details, which are described in Section 3 (the formal 3D-CBM architecture that maps point clouds and meshes to the taxonomy) and Section 4 (dataset-specific supervision on PartNet and ShapeNet). The taxonomy is human-defined and organized into primitive and functional tiers; supervision uses the part annotations available in those datasets. Generalization is demonstrated by reporting results on both datasets in the experiments, but the abstract does not explicitly state this. We will add a brief clause to the abstract describing the input-to-concept mapping and the use of PartNet/ShapeNet for supervision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description introduce an architectural framework for 3D-CBM without any equations, fitted parameters, derivations, or self-citations that reduce claims to inputs by construction. Reported metrics (88.8% accuracy, Chamfer 0.0115) are presented as experimental outcomes from a proof-of-concept, not as predictions forced by prior fits or definitions. No load-bearing steps match the enumerated circularity patterns; the work is self-contained as a proposal for concept-based interpretability in 3D models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-defined concepts can be aligned with latent representations of unstructured 3D geometric data.
Reference graph
Works this paper leans on
-
[1]
Compositional 3d scene generation using locally conditioned diffusion
Ryan Po and Gordon Wetzstein. Compositional 3d scene generation using locally conditioned diffusion. In2024 International Conference on 3D Vision (3DV), pages 651–663. IEEE, 2024
2024
-
[2]
State of the art on diffusion models for visual computing
Ryan Po, Wang Yifan, Vladislav Golyanik, Kfir Aberman, Jonathan T Barron, Amit Bermano, Eric Chan, Tali Dekel, Aleksander Holynski, Angjoo Kanazawa, et al. State of the art on diffusion models for visual computing. InComputer graphics forum, volume 43, page e15063. Wiley Online Library, 2024
2024
-
[3]
Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480, 2022
Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480, 2022
-
[4]
Seyed Mohammad Ahmadi, Koorosh Aslansefat, Ruben Valcarce-Dineiro, and Joshua Barnfather. Explainability of point cloud neural networks using smile: Statistical model-agnostic interpretability with local explanations. arXiv preprint arXiv:2410.15374, 2024
-
[5]
Label-free concept bottleneck models
Tuomas Oikarinen, Subhro Das, Lam M Nguyen, and Tsui-Wei Weng. Label-free concept bottleneck models. arXiv preprint arXiv:2304.06129, 2023
-
[6]
Toqa Khaled and Ahmad Al-Kabbany. Interpretable aneurysm classification via 3d concept bottleneck models: Integrating morphological and hemodynamic clinical features.arXiv preprint arXiv:2603.07399, 2026
-
[7]
Language in a bottle: Language model guided concept bottlenecks for interpretable image classification
Yue Yang, Artemis Panagopoulou, Shenghao Zhou, Daniel Jin, Chris Callison-Burch, and Mark Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19187–19197, 2023
2023
-
[8]
Explainable and interpretable multimodal large language models: A comprehensive survey
Yunkai Dang, Kaichen Huang, Jiahao Huo, Yibo Yan, Sirui Huang, Dongrui Liu, Mengxi Gao, Jie Zhang, Chen Qian, Kun Wang, et al. Explainable and interpretable multimodal large language models: A comprehensive survey. arXiv preprint arXiv:2412.02104, 2024
-
[9]
Generative ai meets 3d: A survey on text-to-3d in aigc era.arXiv preprint arXiv:2305.06131, 2023
Chenghao Li, Chaoning Zhang, Joseph Cho, Atish Waghwase, Lik-Hang Lee, Francois Rameau, Yang Yang, Sung-Ho Bae, and Choong Seon Hong. Generative ai meets 3d: A survey on text-to-3d in aigc era.arXiv preprint arXiv:2305.06131, 2023
-
[10]
A survey on text-to-3d contents generation in the wild.arXiv preprint arXiv:2405.09431, 2024
Chenhan Jiang. A survey on text-to-3d contents generation in the wild.arXiv preprint arXiv:2405.09431, 2024
-
[11]
Diffusion probabilistic models for 3d point cloud generation
Shitong Luo and Wei Hu. Diffusion probabilistic models for 3d point cloud generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2837–2845, 2021
2021
-
[12]
Sp-gan: Sphere-guided 3d shape generation and manipula- tion.ACM Transactions on Graphics (TOG), 40(4):1–12, 2021
Ruihui Li, Xianzhi Li, Ka-Hei Hui, and Chi-Wing Fu. Sp-gan: Sphere-guided 3d shape generation and manipula- tion.ACM Transactions on Graphics (TOG), 40(4):1–12, 2021. 1https://paper-banana.org/ 12 3D-CBM: Concept-Based Interpretability for 3D Modeling
2021
-
[13]
Lion: Latent point diffusion models for 3d shape generation.Advances in Neural Information Processing Systems, 35:10021–10039, 2022
Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, Karsten Kreis, et al. Lion: Latent point diffusion models for 3d shape generation.Advances in Neural Information Processing Systems, 35:10021–10039, 2022
2022
-
[14]
Concept bottleneck models for explainable decision making: A survey of progress, taxonomy, and future directions.Preprint at ResearchGate, 2022
Chunjiang Wang, Fan Li, Wenbo Hu, Rui Yan, Kun Zhang, and Shaohua Kevin Zhou. Concept bottleneck models for explainable decision making: A survey of progress, taxonomy, and future directions.Preprint at ResearchGate, 2022
2022
-
[15]
Explainable generative ai: A two-stage review of existing techniques and future research directions.AI, 7(1):31, 2026
Prabha M Kumarage and Mirka Saarela. Explainable generative ai: A two-stage review of existing techniques and future research directions.AI, 7(1):31, 2026
2026
-
[16]
Interpretable 3d neural object volumes for robust conceptual reasoning
Nhi Pham, Artur Jesslen, Bernt Schiele, Adam Kortylewski, and Jonas Fischer. Interpretable 3d neural object volumes for robust conceptual reasoning. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[17]
Ahmed R Sadik and Mariusz Bujny. Human-in-the-loop: Quantitative evaluation of 3d models generation by large language models.arXiv preprint arXiv:2509.07010, 2025
-
[18]
Simon and Schuster, 2021
Robert Munro Monarch.Human-in-the-Loop Machine Learning: Active learning and annotation for human- centered AI. Simon and Schuster, 2021
2021
-
[19]
Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding
Kaichun Mo, Shilin Zhu, Angel X Chang, Li Yi, Subarna Tripathi, Leonidas J Guibas, and Hao Su. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 909–918, 2019
2019
-
[20]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 652–660, 2017
2017
-
[21]
Foldingnet: Point cloud auto-encoder via deep grid deformation
Yaoqing Yang, Chen Feng, Yiru Shen, and Dong Tian. Foldingnet: Point cloud auto-encoder via deep grid deformation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 206–215, 2018
2018
-
[22]
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCA V)
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and Rory Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCA V). In Proceedings of the 35th International Conference on Machine Learning (ICML), pages 2668–2677, 2018. 13
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.