Accurate and Resource-Efficient Federated Continual Learning
Pith reviewed 2026-06-27 13:38 UTC · model grok-4.3
The pith
FedRAN replaces gradient updates in federated continual learning with truncated-SVD summaries of Gram matrices to cut communication by up to 121x while raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
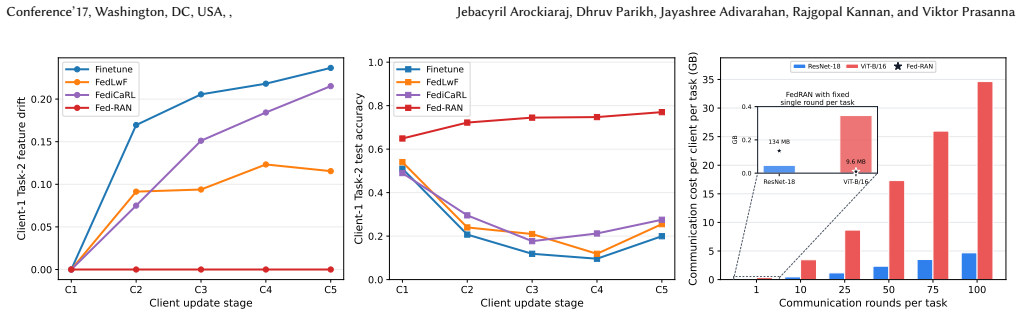
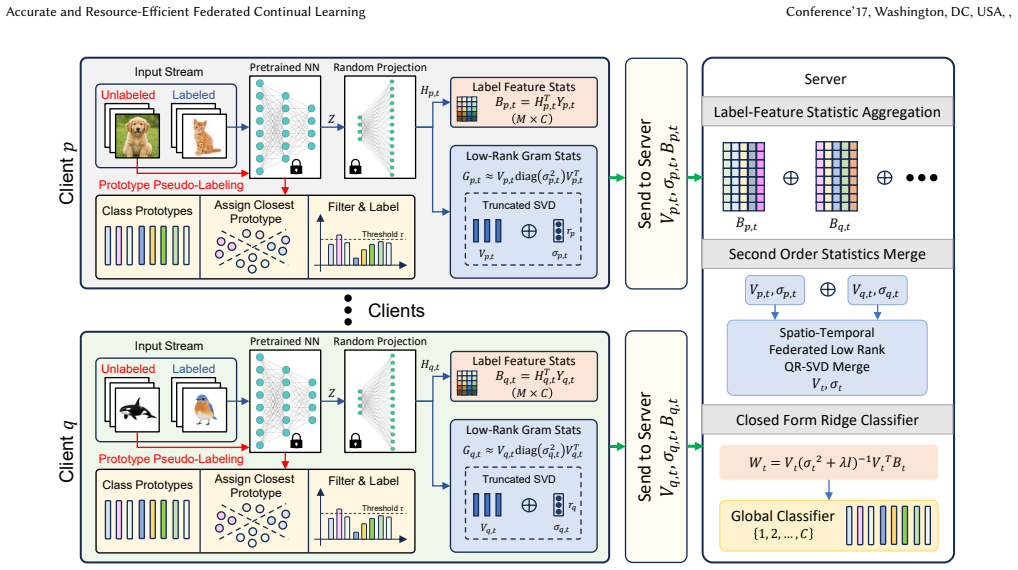
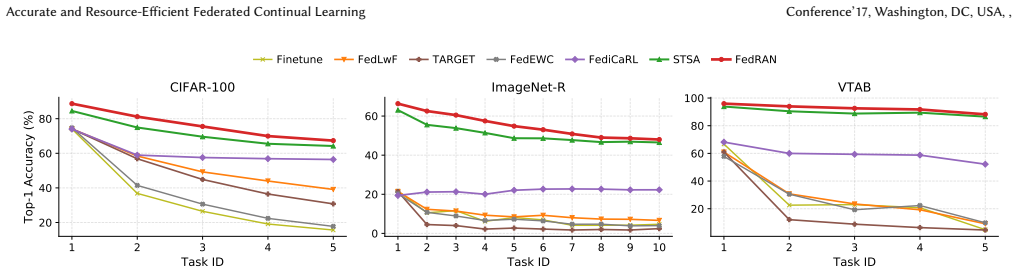
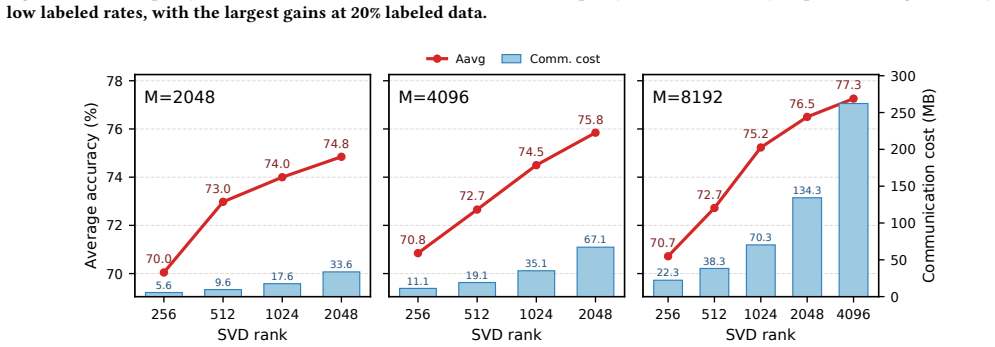
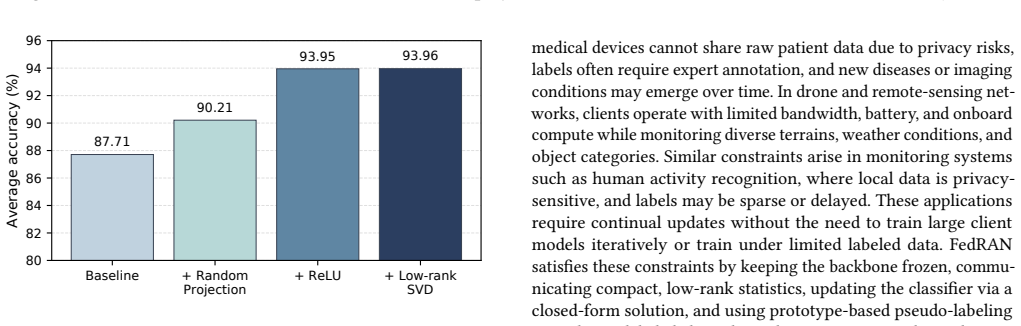
FedRAN transmits a truncated-SVD summary of each client's Gram matrix instead of gradients or full statistics, reducing the dominant communication cost from quadratic to linear in the random feature dimension for fixed rank; the server then applies a two-level QR-SVD merge first across clients and then across tasks before computing a ridge-regression solution in closed form, yielding up to 4.8 percentage points higher average accuracy than the strongest baseline on CIFAR-100, ImageNet-R, and VTAB while using 30.6-121.8 times less per-client communication and running 190.3 times faster on average than gradient baselines.
What carries the argument
The truncated-SVD summary of the Gram matrix, which compresses the second-order random-feature statistic for linear communication cost, together with the server's two-level QR-SVD subspace merge that combines information spatially across clients and temporally across tasks before closed-form ridge regression.
If this is right
- Average accuracy rises by as much as 4.8 points over the strongest prior FCL method across the tested image datasets.
- Per-client communication drops by factors between 30.6 and 121.8 compared with optimization-based approaches.
- Training runs 190.3 times faster on average than gradient-based baselines.
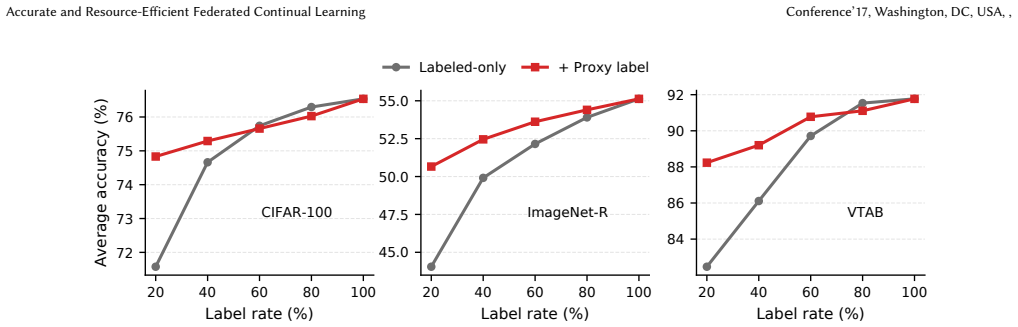
- When only 20 percent of labels are present, prototype pseudo-labeling adds up to 6.61 accuracy points.
Where Pith is reading between the lines
- The same truncated-summary approach could be tested on non-image modalities such as text or sensor streams to check whether the rank needed for good accuracy scales similarly.
- Because the server never sees raw gradients or full models, the method may reduce certain privacy leakage vectors that iterative methods expose.
- If the random-feature dimension must grow with task complexity, the linear communication saving might shrink, suggesting a need to adapt the truncation rank dynamically.
Load-bearing premise
The low-rank SVD truncation of each client's Gram matrix keeps enough information that the server's merged ridge classifier remains competitive with iterative optimization across sequential tasks.
What would settle it
Run FedRAN and a standard optimization-based FCL baseline on a new streaming dataset with the same communication budget; if FedRAN accuracy falls more than 2 points below the baseline while still reporting the claimed communication reduction, the central claim is falsified.
Figures

read the original abstract
Federated continual learning (FCL) must learn from distributed task streams under limited resources, such as communication, computation, memory, and label availability. Existing FCL methods often rely on repeated local optimization, replay, and full supervision. Analytic alternatives avoid iterative training and replay, but using high-dimensional random features to improve accuracy requires a second-order feature statistic, the Gram matrix, which has a quadratic communication cost in the random feature size $M$. We propose FedRAN, a resource-aware analytic FCL framework that replaces gradient-based updates with compact random feature statistics. Each client transmits a truncated-SVD summary of its Gram matrix, reducing the dominant second-order upload from quadratic to linear in $M$ for fixed rank. The server performs a two-level QR-SVD subspace merge, spatially across clients and temporally across tasks, and solves a ridge classifier in closed form. FedRAN further supports label scarcity through prototype-based pseudo-labeling. Across CIFAR-100, ImageNet-R, and VTAB datasets, FedRAN improves average accuracy by up to 4.8 percentage points over the strongest baseline, uses 30.6-121.8$\times$ less per-client communication than optimization-based FCL, and is 190.3$\times$ faster on average than gradient-based baselines; with only 20% labels, pseudo-labeling improves average accuracy by up to 6.61 points. These results show that FedRAN enables accurate and resource-efficient FCL under communication, computation, and label constraints. The source code is available at https://github.com/JebacyrilArockiaraj/Fed-RAN-SSL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedRAN, an analytic federated continual learning method that uses random features with truncated-SVD summaries of per-client Gram matrices to reduce communication from quadratic to linear in feature dimension M. The server performs a two-level QR-SVD merge (spatial across clients, temporal across tasks) followed by closed-form ridge regression; prototype-based pseudo-labeling handles label scarcity. On CIFAR-100, ImageNet-R and VTAB it reports up to 4.8 pp higher average accuracy than the strongest baseline, 30.6–121.8× lower per-client communication than optimization-based FCL, and 190.3× faster training than gradient-based methods; with 20 % labels the pseudo-labeling variant gains up to 6.61 pp.
Significance. If the truncated-SVD approximation is shown to be sufficient, the work supplies a genuinely resource-efficient, non-iterative alternative to existing FCL methods, with concrete communication and wall-clock gains that are directly tied to the analytic formulation. The public code release and the explicit handling of label scarcity are additional strengths that would make the result immediately usable by the community.
major comments (2)
- [Method description (around the FedRAN algorithm and QR-SVD merge)] The central accuracy claim rests on the assumption that a fixed-rank truncated SVD of each client’s Gram matrix supplies a subspace whose subsequent two-level QR-SVD merge yields a ridge classifier competitive with iterative optimization. No approximation bounds on the discarded singular components are supplied, nor is it shown that the retained rank-r summary remains sufficient when later tasks introduce discriminative directions orthogonal to those retained from earlier tasks (see the skeptic note on the temporal merge).
- [Experiments section] The SVD truncation rank is listed as the sole free parameter, yet no ablation or sensitivity analysis on its value is reported; the communication–accuracy trade-off therefore cannot be assessed from the given experiments.
minor comments (2)
- [Abstract] The abstract states empirical gains but does not mention the truncation rank or any assumption on the retained subspace; adding a brief qualifier would improve clarity.
- [Tables and figures] Table captions and axis labels should explicitly state the random-feature dimension M and the chosen truncation rank so that the reported communication numbers can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on FedRAN. Below we respond point-by-point to the major comments, clarifying the empirical grounding of the truncated-SVD approach and committing to additional experiments where appropriate.
read point-by-point responses
-
Referee: [Method description (around the FedRAN algorithm and QR-SVD merge)] The central accuracy claim rests on the assumption that a fixed-rank truncated SVD of each client’s Gram matrix supplies a subspace whose subsequent two-level QR-SVD merge yields a ridge classifier competitive with iterative optimization. No approximation bounds on the discarded singular components are supplied, nor is it shown that the retained rank-r summary remains sufficient when later tasks introduce discriminative directions orthogonal to those retained from earlier tasks (see the skeptic note on the temporal merge).
Authors: We acknowledge the absence of theoretical approximation bounds. FedRAN is motivated by the practical observation that low-rank Gram-matrix summaries retain the dominant directions needed for accurate ridge regression in the random-feature space; this is supported by the consistent gains (up to 4.8 pp) across CIFAR-100, ImageNet-R and VTAB. The two-level QR-SVD merge is explicitly designed to accommodate new discriminative directions: the spatial merge aggregates client subspaces and the temporal merge recomputes an updated orthonormal basis from the concatenated summaries of all tasks seen so far, so directions orthogonal to earlier subspaces are incorporated when they appear in later Gram matrices. While formal bounds would be desirable, the analytic closed-form solution and the reported communication and wall-clock advantages are tied directly to the low-rank representation, and the empirical results across three benchmarks indicate that the retained rank is sufficient for the evaluated continual-learning regimes. revision: no
-
Referee: [Experiments section] The SVD truncation rank is listed as the sole free parameter, yet no ablation or sensitivity analysis on its value is reported; the communication–accuracy trade-off therefore cannot be assessed from the given experiments.
Authors: We agree that an explicit sensitivity study on the truncation rank would strengthen the presentation of the communication–accuracy trade-off. In the revised manuscript we will add an ablation that varies the retained rank r on the primary datasets, reporting both average accuracy and per-client communication volume for each setting. revision: yes
Circularity Check
No significant circularity; derivation uses standard linear-algebra primitives
full rationale
The paper constructs FedRAN from random-feature Gram matrices, truncated SVD compression, two-level QR-SVD merging, and closed-form ridge regression. These operations are standard, externally defined linear-algebra steps whose outputs are not redefined in terms of the target accuracy metric. No equation reduces a claimed performance quantity to a fitted parameter by construction, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled via prior work. Empirical accuracy, communication, and speed numbers are reported from experiments rather than derived tautologically from the method equations themselves. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- SVD truncation rank
axioms (1)
- domain assumption Random Fourier features yield a sufficiently accurate finite-dimensional approximation to the kernel for the downstream ridge classifier.
Reference graph
Works this paper leans on
-
[1]
Zahir Alsulaimawi. 2026. One-Shot Federated Ridge Regression: Exact Recovery via Sufficient Statistic Aggregation.arXiv preprint arXiv:2601.08216(2026)
arXiv 2026
-
[2]
Gaurav Bagwe, Xiaoyong Yuan, Miao Pan, and Lan Zhang. 2023. Fed-cprompt: Contrastive prompt for rehearsal-free federated continual learning.arXiv preprint arXiv:2307.04869(2023)
arXiv 2023
-
[3]
Yavuz Faruk Bakman, Duygu Nur Yaldiz, Yahya H Ezzeldin, and Salman Aves- timehr. 2023. Federated orthogonal training: Mitigating global catastrophic forgetting in continual federated learning.arXiv preprint arXiv:2309.01289(2023)
arXiv 2023
-
[4]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. 2021. A continual learning survey: Defying forgetting in classification tasks.IEEE transactions on pattern analysis and machine intelligence44, 7 (2021), 3366–3385
2021
-
[5]
Yongheng Deng, Sheng Yue, Tuowei Wang, Guanbo Wang, Ju Ren, and Yaoxue Zhang. 2023. Fedinc: An exemplar-free continual federated learning framework with small labeled data. InProceedings of the 21st ACM Conference on Embedded Networked Sensor Systems. 56–69. Accurate and Resource-Efficient Federated Continual Learning Conference’17, Washington, DC, USA, ,
2023
-
[6]
Jiahua Dong, Hongliu Li, Yang Cong, Gan Sun, Yulun Zhang, and Luc Van Gool
-
[7]
No one left behind: Real-world federated class-incremental learning.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 4 (2023), 2054–2070
2023
-
[8]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
Pith/arXiv arXiv 2020
-
[9]
Armin Eftekhari, Raphael A Hauser, and Andreas Grammenos. 2019. MOSES: A streaming algorithm for linear dimensionality reduction.IEEE transactions on pattern analysis and machine intelligence42, 11 (2019), 2901–2911
2019
-
[10]
Jianqing Fan, Dong Wang, Kaizheng Wang, and Ziwei Zhu. 2019. Distributed estimation of principal eigenspaces.Annals of statistics47, 6 (2019), 3009
2019
-
[11]
Kejia Fan, Jianheng Tang, Zhirui Yang, Feijiang Han, Jiaxu Li, Run He, Yajiang Huang, Anfeng Liu, Houbing Herbert Song, Yunhuai Liu, et al . 2025. Apfl: Analytic personalized federated learning via dual-stream least squares.arXiv preprint arXiv:2508.10732(2025)
arXiv 2025
-
[13]
Eros Fanì, Raffaello Camoriano, Barbara Caputo, and Marco Ciccone. 2024. Ac- celerating heterogeneous federated learning with closed-form classifiers.arXiv preprint arXiv:2406.01116(2024)
arXiv 2024
-
[14]
Mina Ghashami, Edo Liberty, Jeff M Phillips, and David P Woodruff. 2016. Fre- quent directions: Simple and deterministic matrix sketching.SIAM J. Comput.45, 5 (2016), 1762–1792
2016
-
[15]
Masoume Gholizade, Fabrizio Ruffini, Pietro Ducange, and Francesco Marcelloni
-
[16]
Federated continual learning: A comprehensive survey on lifelong and privacy-preserving learning over distributed and non-stationary data.Neuro- computing(2026), 133929
2026
-
[17]
Dipam Goswami, Simone Magistri, Kai Wang, Bartłomiej Twardowski, Andrew Bagdanov, and Joost van de Weijer. 2026. Covariances for free: Exploiting mean distributions for training-free federated learning.Advances in Neural Information Processing Systems38 (2026), 65081–65115
2026
-
[18]
Andreas Grammenos, Rodrigo Mendoza Smith, Jon Crowcroft, and Cecilia Mas- colo. 2020. Federated principal component analysis.Advances in neural informa- tion processing systems33 (2020), 6453–6464
2020
-
[19]
Zenghao Guan, Guojun Zhu, Yucan Zhou, Wu Liu, Weiping Wang, Jiebo Luo, and Xiaoyan Gu. 2026. Enhancing Federated Class-Incremental Learning via Spatial- Temporal Statistics Aggregation. InProceedings of the ACM Web Conference 2026. 5356–5367
2026
-
[20]
Haiyang Guo, Fei Zhu, Wenzhuo Liu, Xu-Yao Zhang, and Cheng-Lin Liu. 2024. Pilora: Prototype guided incremental lora for federated class-incremental learning. InEuropean Conference on Computer Vision. Springer, 141–159
2024
-
[21]
Nathan Halko, Per-Gunnar Martinsson, and Joel A Tropp. 2011. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM review53, 2 (2011), 217–288
2011
-
[22]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[23]
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. 2021. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision. 8340– 8349
2021
-
[24]
Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. 2019. Measuring the effects of non-identical data distribution for federated visual classification.arXiv preprint arXiv:1909.06335(2019)
Pith/arXiv arXiv 2019
-
[25]
Mark A Iwen and Benjamin W Ong. 2016. A distributed and incremental SVD algorithm for agglomerative data analysis on large networks.SIAM J. Matrix Anal. Appl.37, 4 (2016), 1699–1718
2016
-
[26]
Wonyong Jeong, Jaehong Yoon, Eunho Yang, and Sung Ju Hwang. 2020. Federated semi-supervised learning with inter-client consistency & disjoint learning.arXiv preprint arXiv:2006.12097(2020)
arXiv 2020
-
[27]
Ellango Jothimurugesan, Kevin Hsieh, Jianyu Wang, Gauri Joshi, and Phillip B Gibbons. 2023. Federated learning under distributed concept drift. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 5834–5853
2023
-
[28]
Peter Kairouz and H Brendan McMahan. 2021. Advances and open problems in federated learning.Foundations and trends in machine learning14, 1-2 (2021), 1–210
2021
-
[30]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences114, 13 (2017), 3521– 3526
2017
-
[31]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[32]
Gwen Legate, Nicolas Bernier, Lucas Page-Caccia, Edouard Oyallon, and Eugene Belilovsky. 2023. Guiding the last layer in federated learning with pre-trained models.Advances in Neural Information Processing Systems36 (2023), 69832– 69848
2023
-
[33]
Haolin Li and Hoda Bidkhori. 2025. FedGTEA: Federated Class-Incremental Learning with Gaussian Task Embedding and Alignment.arXiv preprint arXiv:2510.12927(2025)
arXiv 2025
-
[34]
Yichen Li, Yuying Wang, Jiahua Dong, Haozhao Wang, Yining Qi, Rui Zhang, and Ruixuan Li. 2026. Resource-constrained federated continual learning: What does matter?Advances in Neural Information Processing Systems38 (2026), 79493– 79518
2026
-
[35]
Zhizhong Li and Derek Hoiem. 2017. Learning without forgetting.IEEE transac- tions on pattern analysis and machine intelligence40, 12 (2017), 2935–2947
2017
-
[36]
Mark D McDonnell, Dong Gong, Amin Parvaneh, Ehsan Abbasnejad, and Anton Van den Hengel. 2023. Ranpac: Random projections and pre-trained models for continual learning.Advances in Neural Information Processing Systems36 (2023), 12022–12053
2023
-
[38]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics. Pmlr, 1273–1282
2017
-
[39]
Chuiyang Meng, Ming Tang, and Vincent WS Wong. 2026. FLoRG: Federated Fine-tuning with Low-rank Gram Matrices and Procrustes Alignment.arXiv preprint arXiv:2602.17095(2026)
arXiv 2026
-
[40]
Saleh Momeni, Changnan Xiao, and Bing Liu. 2026. Anacp: Toward upper- bound continual learning via analytic contrastive projection.Advances in Neural Information Processing Systems38 (2026), 72923–72944
2026
-
[41]
Byoungjun Park, Pedro Porto Buarque de GusmÃG, o, Dongjin Ji, and Minhoe Kim
-
[42]
CATCHFed: Efficient Unlabeled Data Utilization for Semi-Supervised Fed- erated Learning in Limited Labels Environments.arXiv preprint arXiv:2511.11778 (2025)
arXiv 2025
-
[43]
Liangzu Peng, Juan Elenter, Joshua Agterberg, Alejandro Ribeiro, and René Vidal
-
[44]
Loranpac: Low-rank random features and pre-trained models for bridging theory and practice in continual learning.arXiv preprint arXiv:2410.00645(2024)
arXiv 2024
-
[45]
Ameya Prabhu, Shiven Sinha, Ponnurangam Kumaraguru, Philip H Torr, Ozan Sener, and Puneet K Dokania. 2024. RanDumb: Random representations outper- form online continually learned representations.Advances in Neural Information Processing Systems37 (2024), 37988–38006
2024
-
[46]
Daiqing Qi, Handong Zhao, and Sheng Li. 2023. Better generative replay for continual federated learning.arXiv preprint arXiv:2302.13001(2023)
arXiv 2023
-
[47]
Yijun Quan, Wentai Wu, and Giovanni Montana. 2026. Exact Federated Contin- ual Unlearning for Ridge Heads on Frozen Foundation Models.arXiv preprint arXiv:2603.12977(2026)
arXiv 2026
-
[48]
Ali Rahimi and Benjamin Recht. 2007. Random features for large-scale kernel machines.Advances in neural information processing systems20 (2007)
2007
-
[49]
Ali Rahimi and Benjamin Recht. 2008. Weighted sums of random kitchen sinks: Replacing minimization with randomization in learning.Advances in neural information processing systems21 (2008)
2008
-
[50]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. 2017. icarl: Incremental classifier and representation learning. InPro- ceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2001– 2010
2017
-
[51]
Jonathan Schwarz, Wojciech Czarnecki, Jelena Luketina, Agnieszka Grabska- Barwinska, Yee Whye Teh, Razvan Pascanu, and Raia Hadsell. 2018. Progress & compress: A scalable framework for continual learning. InInternational conference on machine learning. PMLR, 4528–4537
2018
-
[52]
Maksym Shamrai. 2026. Concatenated Matrix SVD: Compression Bounds, In- cremental Approximation, and Error-Constrained Clustering.arXiv preprint arXiv:2601.11626(2026)
arXiv 2026
-
[53]
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira
-
[54]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11909–11919
-
[55]
Yue Tan, Guodong Long, Lu Liu, Tianyi Zhou, Qinghua Lu, Jing Jiang, and Chengqi Zhang. 2022. Fedproto: Federated prototype learning across hetero- geneous clients. InProceedings of the AAAI conference on artificial intelligence, Vol. 36. 8432–8440
2022
-
[56]
Jianheng Tang, Yajiang Huang, Kejia Fan, Feijiang Han, Jiaxu Li, Jinfeng Xu, Run He, Anfeng Liu, Houbing Herbert Song, Huiping Zhuang, et al. 2026. DeepAFL: Deep analytic federated learning.arXiv preprint arXiv:2603.00579(2026). Conference’17, Washington, DC, USA, , Jebacyril Arockiaraj, Dhruv Parikh, Jayashree Adivarahan, Rajgopal Kannan, and Viktor Prasanna
arXiv 2026
-
[57]
Jianheng Tang, Zhirui Yang, Jingchao Wang, Kejia Fan, Jinfeng Xu, Huiping Zhuang, Anfeng Liu, Houbing Herbert Song, Leye Wang, and Yunhuai Liu
-
[58]
FedHiP: Heterogeneity-Invariant Personalized Federated Learning Through Closed-Form Solutions.arXiv preprint arXiv:2508.04470(2025)
arXiv 2025
-
[59]
Jianheng Tang, Huiping Zhuang, Jingyu He, Run He, Jingchao Wang, Kejia Fan, Anfeng Liu, Tian Wang, Leye Wang, Zhanxing Zhu, et al. 2025. Afcl: Analytic federated continual learning for spatio-temporal invariance of non-iid data.arXiv preprint arXiv:2505.12245(2025)
arXiv 2025
-
[60]
Fabio Turazza, Marco Picone, and Marco Mamei. 2026. The Gaussian-Head OFL Family: One-Shot Federated Learning from Client Global Statistics.arXiv preprint arXiv:2602.01186(2026)
Pith/arXiv arXiv 2026
-
[61]
Vinita Vasudevan and M Ramakrishna. 2017. A hierarchical singular value decomposition algorithm for low rank matrices.arXiv preprint arXiv:1710.02812 (2017)
Pith/arXiv arXiv 2017
-
[62]
Yeshwanth Venkatesha, Youngeun Kim, Hyoungseob Park, Yuhang Li, and Priyadarshini Panda. 2022. Addressing client drift in federated continual learning with adaptive optimization.A vailable at SSRN 4188586(2022)
2022
-
[63]
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, et al. 2022. Dualprompt: Complementary prompting for rehearsal-free continual learning. InEuropean conference on computer vision. Springer, 631–648
2022
-
[64]
Kunlun Xu, Yibo Feng, Jiangmeng Li, Yongsheng Qi, and Jiahuan Zhou. 2026. C2 Prompt: Class-aware Client Knowledge Interaction for Federated Continual Learning.Advances in Neural Information Processing Systems38 (2026), 44109– 44139
2026
-
[65]
Jaehong Yoon, Wonyong Jeong, Giwoong Lee, Eunho Yang, and Sung Ju Hwang
-
[66]
InInter- national conference on machine learning
Federated continual learning with weighted inter-client transfer. InInter- national conference on machine learning. PMLR, 12073–12086
-
[67]
Hao Yu, Xin Yang, Le Zhang, Hanlin Gu, Tianrui Li, Lixin Fan, and Qiang Yang
-
[68]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Handling spatial-temporal data heterogeneity for federated continual learning via tail anchor. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4874–4883
-
[69]
Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, et al. 2019. A large-scale study of representation learning with the visual task adaptation benchmark.arXiv preprint arXiv:1910.04867 (2019)
Pith/arXiv arXiv 2019
-
[71]
Jie Zhang, Chen Chen, Weiming Zhuang, and Lingjuan Lyu. 2023. Target: Feder- ated class-continual learning via exemplar-free distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 4782–4793
2023
-
[72]
Zhengyi Zhong, Weidong Bao, Ji Wang, Jianguo Chen, Lingjuan Lyu, and Wei Yang Bryan Lim. 2025. Sacfl: Self-adaptive federated continual learning for resource-constrained end devices.IEEE Transactions on Neural Networks and Learning Systems(2025)
2025
-
[73]
Huiping Zhuang, Yizhu Chen, Di Fang, Run He, Kai Tong, Hongxin Wei, Ziqian Zeng, and Cen Chen. 2024. GACL: Exemplar-free generalized analytic continual learning.Advances in neural information processing systems37 (2024), 83024– 83047
2024
-
[74]
Huiping Zhuang, Run He, Kai Tong, Ziqian Zeng, Cen Chen, and Zhiping Lin
-
[75]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
DS-AL: A dual-stream analytic learning for exemplar-free class-incremental learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17237–17244
-
[76]
Huiping Zhuang, Yuchen Liu, Run He, Kai Tong, Ziqian Zeng, Cen Chen, Yi Wang, and Lap-Pui Chau. 2024. F-oal: Forward-only online analytic learning with fast training and low memory footprint in class incremental learning.Advances in Neural Information Processing Systems37 (2024), 41517–41538
2024
-
[77]
Huiping Zhuang, Zhenyu Weng, Hongxin Wei, Renchunzi Xie, Kar-Ann Toh, and Zhiping Lin. 2022. ACIL: Analytic class-incremental learning with absolute memorization and privacy protection.Advances in Neural Information Processing Systems35 (2022), 11602–11614
2022
-
[78]
Radim Řehřek. 2011. Subspace tracking for latent semantic analysis. InEuropean Conference on Information Retrieval. Springer, 289–300. Accurate and Resource-Efficient Federated Continual Learning Conference’17, Washington, DC, USA, , A Additional FedRAN Algorithms and Proofs This appendix provides helper algorithms and proofs for the state- ments in Secti...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.