Elucidating the Size of Chemical Space with Assembly Theory
Pith reviewed 2026-06-27 11:02 UTC · model grok-4.3
The pith
Assembly theory estimates that drug-like chemical space reaches about 10^117 molecules at assembly index 25 under mass and structural constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
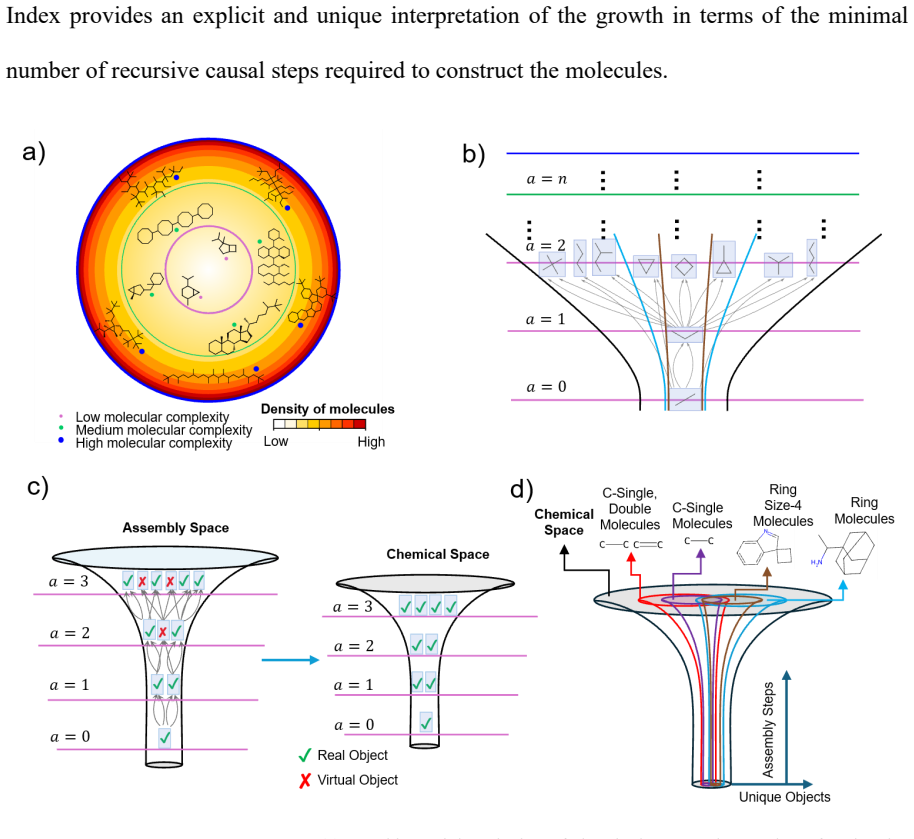
Chemical space grows at least super-exponentially and at most double-exponentially with assembly index. Fitting this growth to the GDB-13 database and contracting the space by atom and bond types, ring counts, ring sizes, and chemical motifs produces an estimate of approximately 10^117 molecules at assembly index 25 when the molecular mass is kept below 500 Da. The same partitioning further allows the space to be restricted by biologically relevant motifs to locate molecules near the accessible boundaries.
What carries the argument
The assembly index: the minimum number of recursive bond-joining operations required to construct a molecular graph.
If this is right
- Chemical space can be divided into discrete levels according to assembly index.
- The total number of molecules grows at least super-exponentially and at most double-exponentially with rising assembly index.
- Under drug-like constraints of mass below 500 Da together with atom, bond, and ring limits, the space at assembly index 25 contains roughly 10^117 molecules.
- Additional filtering by biologically relevant motifs further reduces the accessible portion of the space near its boundaries.
Where Pith is reading between the lines
- Higher assembly indices would therefore correspond to molecules that are exponentially harder to reach by synthesis, narrowing practical exploration to lower indices.
- The model supplies a quantitative way to rank how much additional synthetic effort is required to access new regions of chemical space.
- Extending the same growth fit to databases that sample higher masses could test whether the double-exponential ceiling remains valid at larger scales.
Load-bearing premise
The growth rate of molecule count versus assembly index observed in GDB-13 continues to apply once further structural constraints are added and the index is extrapolated past the database's mass limit.
What would settle it
An exhaustive enumeration or sampling of molecules at assembly index near 25 that yields a count differing by many orders of magnitude from 10^117 under the stated mass and motif constraints would falsify the extrapolated growth model.
Figures

read the original abstract
Chemical space is unimaginably vast with common heuristic estimates suggesting that there are ca. 10^60 'drug-like' molecules possible below a molecular mass of 500 Da. However, these estimates largely ignore the structural and synthetic complexity of the molecules enumerated. Here we present a first-principles estimate of the size of chemical space using the Assembly Theory, which quantifies the amount of causation required to form a molecule, captured in the assembly Index. This is a measurable molecular complexity measure derived from the minimum number of recursive bond-joining operations required to construct a molecular graph. Assembly Theory partitions chemical space into levels defined by Assembly Index, allowing bounds to be placed on its growth as molecular complexity increases. We show that chemical space (the accumulated Assembly Index level sets) grows at least super-exponentially, and at most, double-exponentially with respect to the Assembly Index. Using the GDB-13 database as a reference for growth-rate estimation, we model how chemical space expands under increasing complexity and contracts under structural constraints, including atom and bond types, number of rings, ring size, and chemical motifs. Under constraints comparable to standard drug-like estimates, including molecular mass below 500 Da, our analysis yields a chemical space of approximately 10117 molecules at Assembly Index 25. Finally, we constrain chemical space by biologically relevant motifs and identify structurally relevant molecules near the accessible boundaries of these assembly-defined spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper uses Assembly Theory to partition chemical space by Assembly Index (AI), a measure of minimum recursive bond-joining steps needed to build a molecular graph. It derives that the cumulative number of molecules grows at least super-exponentially and at most double-exponentially with AI. A growth-rate parameter is fitted to molecule counts per AI in the GDB-13 database; reduction factors for atom types, bonds, rings, motifs, and mass <500 Da are then applied multiplicatively to produce an estimate of ~10^117 drug-like molecules at AI=25.
Significance. If the central modeling assumptions hold, the work supplies the first explicit bounds on chemical-space growth that incorporate a measurable complexity metric rather than mass or atom-count heuristics alone. This could sharpen enumeration strategies in drug discovery and synthetic chemistry by identifying accessible complexity regimes. The approach also demonstrates how Assembly Theory can be used to impose biologically relevant motif filters near the boundaries of the estimated space.
major comments (3)
- [Abstract] Abstract and growth-model section: the headline 10^117 figure is obtained by fitting a growth function to GDB-13 counts and then multiplying by post-hoc reduction factors for additional constraints; no derivation or numerical test is supplied showing that the fitted functional form (super- to double-exponential) remains unchanged once the new filters are imposed.
- [Growth model] Growth-rate estimation procedure: the single free parameter (growth-rate) is calibrated inside the GDB-13 mass window and then extrapolated to AI=25 under mass <500 Da and motif constraints; the manuscript provides neither held-out validation nor an argument that the constraints act multiplicatively on the assembly steps rather than coupling to them.
- [Results] Central numerical claim: because the reported size at AI=25 depends on the same database used for calibration, the estimate is not an independent first-principles bound but a model-dependent extrapolation whose uncertainty is not quantified (no error bars or sensitivity analysis).
minor comments (2)
- [Theory] Clarify whether the reported bounds on growth (super- vs. double-exponential) are proven for the unrestricted graph ensemble or only observed numerically in GDB-13.
- [Abstract] The abstract states 'first-principles estimate' yet the method relies on a fitted parameter; adjust wording to reflect the hybrid empirical-modeling nature of the result.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our use of Assembly Theory to bound chemical space. We address each major point below, agreeing where additional analysis is needed and outlining revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and growth-model section: the headline 10^117 figure is obtained by fitting a growth function to GDB-13 counts and then multiplying by post-hoc reduction factors for additional constraints; no derivation or numerical test is supplied showing that the fitted functional form (super- to double-exponential) remains unchanged once the new filters are imposed.
Authors: The super- to double-exponential bounds follow directly from the recursive definition of assembly steps in Assembly Theory and are independent of downstream filters on atom types, bonds, or motifs. The reduction factors are applied as a first-order approximation to the reduced number of valid assembly pathways. We acknowledge that no explicit numerical test under the full set of constraints was provided and will revise the growth-model section to include a sensitivity check on a motif-filtered subset of GDB-13 to verify that the effective growth rate remains within the super- to double-exponential regime. revision: partial
-
Referee: [Growth model] Growth-rate estimation procedure: the single free parameter (growth-rate) is calibrated inside the GDB-13 mass window and then extrapolated to AI=25 under mass <500 Da and motif constraints; the manuscript provides neither held-out validation nor an argument that the constraints act multiplicatively on the assembly steps rather than coupling to them.
Authors: Calibration on GDB-13 supplies the effective growth-rate parameter within the enumerated range; extrapolation assumes this rate persists at higher AI. We will add a short derivation showing that motif and mass constraints act primarily by pruning the branching factor at each assembly step, preserving the multiplicative structure. For validation, GDB-13 is the only large-scale enumerated set available; we will include a split-sample check (training on lower-AI molecules, testing on higher-AI) in the revised supplementary material. revision: partial
-
Referee: [Results] Central numerical claim: because the reported size at AI=25 depends on the same database used for calibration, the estimate is not an independent first-principles bound but a model-dependent extrapolation whose uncertainty is not quantified (no error bars or sensitivity analysis).
Authors: The theoretical bounds on growth are first-principles results from Assembly Theory; the numerical value at AI=25 combines these bounds with an empirically fitted rate from GDB-13. We agree that uncertainty was not quantified. In revision we will report the fitted growth-rate interval from the GDB-13 regression and propagate it to produce error bars on the final 10^117 estimate, together with a one-parameter sensitivity plot. revision: yes
Circularity Check
Chemical space size at AI=25 obtained by fitting growth rate to GDB-13 then extrapolating under constraints
specific steps
-
fitted input called prediction
[Abstract (growth-rate estimation paragraph)]
"Using the GDB-13 database as a reference for growth-rate estimation, we model how chemical space expands under increasing complexity and contracts under structural constraints, including atom and bond types, number of rings, ring size, and chemical motifs. Under constraints comparable to standard drug-like estimates, including molecular mass below 500 Da, our analysis yields a chemical space of approximately 10^117 molecules at Assembly Index 25."
The 10^117 value is produced by (1) empirical counts per AI in GDB-13, (2) fitting the growth-rate parameters to those counts, (3) scaling by constraint reduction factors, and (4) evaluating the same fitted function at AI=25. The numerical result is therefore determined by the fitted parameters and the assumption that the functional form is unchanged under the added filters, rather than by an independent derivation from assembly operations.
full rationale
The paper partitions space by Assembly Index (a first-principles construct) but obtains its headline quantitative bound by counting molecules per AI bin inside GDB-13, fitting a super- to double-exponential growth function to those counts, multiplying by ad-hoc reduction factors for atom types/rings/motifs/mass, and evaluating the fitted model at AI=25. No independent derivation shows the functional form or parameters remain valid once the new constraints are imposed or outside the GDB-13 mass window; the reported 10^117 figure is therefore fixed by the calibration data and the extrapolation assumption rather than by assembly theory alone.
Axiom & Free-Parameter Ledger
free parameters (1)
- growth-rate parameter
axioms (1)
- domain assumption Assembly Index equals the minimum number of recursive bond-joining operations needed to construct a molecular graph.
Forward citations
Cited by 1 Pith paper
-
Zombie Compositions in Assembly Algebras and an Upper Bound on the Size of Chemical Space
Construction systems and valence-bounded composition polytopes classify zombie compositions and tighten the molecular graph growth exponent from 0.73 to exactly log 2.
Reference graph
Works this paper leans on
-
[1]
S., McMartin, C
Bohacek, R. S., McMartin, C. & Guida, W. C. The art and practice of structure-based drug design: A molecular modeling perspective. Med. Res. Rev. 16, 3–50 (1996)
1996
-
[2]
Davies, D. W. et al. Computational Screening of All Stoichiometric Inorganic Materials. Chem 1, 617–627 (2016)
2016
-
[3]
The quest for new functionality
Walsh, A. The quest for new functionality. Nat. Chem. 7, 274–275 (2015)
2015
-
[4]
Coley, C. W. Defining and Exploring Chemical Spaces. Trends Chem. 3, 133–145 (2021)
2021
-
[5]
Kim, S. et al. PubChem 2025 update. Nucleic Acids Res. 53, D1516–D1525 (2025)
2025
-
[6]
The Chemical Space Project
Reymond, J.-L. The Chemical Space Project. Acc. Chem. Res. 48, 722–730 (2015)
2015
-
[7]
S., Rasmussen, M
Henault, E. S., Rasmussen, M. H. & Jensen, J. H. Chemical space exploration: how genetic algorithms find the needle in the haystack. PeerJ Phys. Chem. 2, e11 (2020)
2020
-
[8]
& Van Den Abeele, J
Verhellen, J. & Van Den Abeele, J. Illuminating elite patches of chemical space. Chem. Sci. 11, 11485–11491 (2020)
2020
-
[9]
Jensen, J. H. A graph-based genetic algorithm and generative model/Monte Carlo tree search for the exploration of chemical space. Chem. Sci. 10, 3567–3572 (2019)
2019
-
[10]
A., Stacey, R
Skinnider, M. A., Stacey, R. G., Wishart, D. S. & Foster, L. J. Chemical language models enable navigation in sparsely populated chemical space. Nat. Mach. Intell. 3, 759–770 (2021)
2021
-
[11]
Zhang, K. et al. Artificial intelligence in drug development. Nat. Med. 31, 45–59 (2025). 25
2025
-
[12]
& Jensen, K
Bilodeau, C., Jin, W., Jaakkola, T., Barzilay, R. & Jensen, K. F. Generative models for molecular discovery: Recent advances and challenges. WIREs Comput. Mol. Sci. 12, e1608 (2022)
2022
-
[13]
Drew, K. L. M., Baiman, H., Khwaounjoo, P ., Yu, B. & Reynisson, J. Size estimation of chemical space: how big is it? J. Pharm. Pharmacol. 64, 490–495 (2012)
2012
-
[14]
Blum, L. C. & Reymond, J.-L. 970 Million Druglike Small Molecules for Virtual Screening in the Chemical Universe Database GDB-13. J. Am. Chem. Soc. 131, 8732– 8733 (2009)
2009
-
[15]
Ruddigkeit, L., Van Deursen, R., Blum, L. C. & Reymond, J.-L. Enumeration of 166 Billion Organic Small Molecules in the Chemical Universe Database GDB-17. J. Chem. Inf. Model. 52, 2864–2875 (2012)
2012
-
[16]
G., Madzhidov, T
Polishchuk, P. G., Madzhidov, T. I. & Varnek, A. Estimation of the size of drug-like chemical space based on GDB-17 data. J. Comput. Aided Mol. Des. 27, 675–679 (2013)
2013
-
[17]
& Reymond, J.-L
Buehler, Y . & Reymond, J.-L. A View on Molecular Complexity from the GDB Chemical Space. J. Chem. Inf. Model. 65, 8405–8410 (2025)
2025
-
[18]
Sharma, A. et al. Assembly theory explains and quantifies selection and evolution. Nature 622, 321–328 (2023)
2023
-
[19]
Liu, Y . et al. Exploring and mapping chemical space with molecular assembly trees. Sci. Adv. 7, eabj2465 (2021)
2021
-
[22]
Seet, I., Patarroyo, K. Y ., Siebert, G., Walker, S. I. & Cronin, L. Rapid Exploration of the Assembly Chemical Space of Molecular Graphs. J. Chem. Inf. Model. acs.jcim.5c01964 (2025) doi:10.1021/acs.jcim.5c01964
-
[24]
Kempes, C. P. et al. Assembly theory and its relationship with computational complexity. Npj Complex. 2, 27 (2025)
2025
-
[25]
M., Moore, D
Marshall, S. M., Moore, D. G., Murray, A. R. G., Walker, S. I. & Cronin, L. Formalising the Pathways to Life Using Assembly Spaces. Entropy 24, 884 (2022)
2022
-
[26]
Łukaszyk, S. & Bieniawski, W. Assembly Theory of Binary Messages. Mathematics 12, 1600 (2024). 27.Cronin, L., Parra, J. C. M. & Patarroyo, K. Y . Assembly Addition Chains. Preprint at https://doi.org/10.48550/ARXIV .2512.18030 (2025)
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[27]
The On-Line Encyclopedia of Integer Sequences
OEIS Foundation Inc. The On-Line Encyclopedia of Integer Sequences. Published electronically at https://oeis.org/A002905
-
[28]
McKay, B. D. & Piperno, A. Practical graph isomorphism, II. J. Symb. Comput. 60, 94– 112 (2014)
2014
-
[29]
Sorokina, M., Merseburger, P., Rajan, K., Yirik, M. A. & Steinbeck, C. COCONUT online: Collection of Open Natural Products database. J. Cheminformatics 13, 2 (2021)
2021
-
[30]
Marshall, S. M. et al. Identifying molecules as biosignatures with assembly theory and mass spectrometry. Nat. Commun. 12, 3033 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.