CS-YODAS: A Mined Dataset of In-the-Wild Code-Switched Speech
Pith reviewed 2026-06-27 11:25 UTC · model grok-4.3
The pith
A 313-hour dataset of spontaneous code-switched speech is mined from multilingual YouTube videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
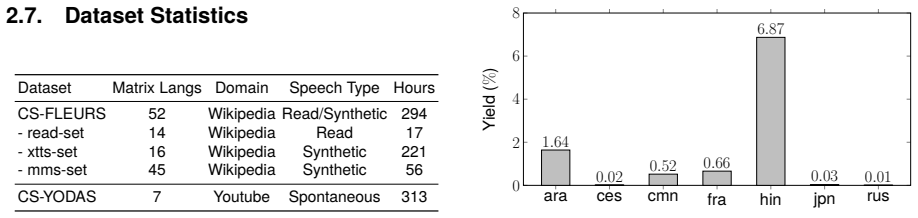
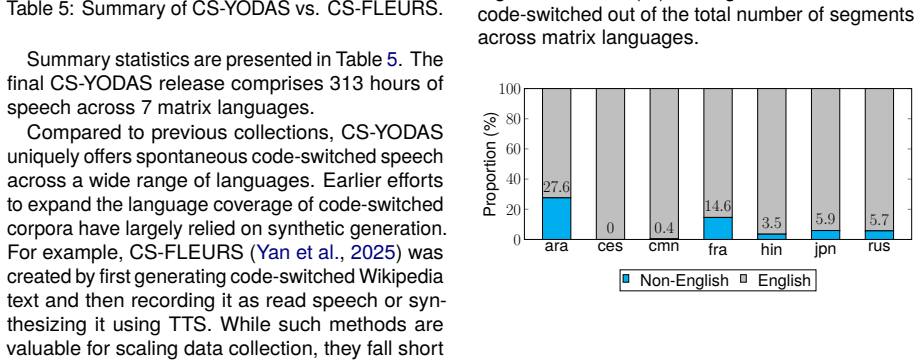
The authors create CS-YODAS by applying a human-in-the-loop pipeline to the YODAS corpus to identify and validate naturally occurring code-switching from YouTube. The resulting Creative Commons dataset totals 313 hours and spans seven matrix languages, supplying diverse spontaneous examples along with statistics on language-pair frequencies and switching patterns plus baseline results for spoken language identification.
What carries the argument
The scalable human-in-the-loop pipeline that identifies and validates naturally occurring code-switching instances from the YODAS corpus.
If this is right
- Models trained on the dataset can better handle spontaneous language alternation in multilingual settings.
- The reported language-pair frequencies and switching patterns become reference statistics for code-switching research.
- Baseline spoken language identification results serve as a starting point for new systems evaluated on in-the-wild data.
- The Creative Commons license allows direct reuse and extension by other researchers.
Where Pith is reading between the lines
- The same pipeline could be rerun on newer YouTube data to grow the dataset over time.
- Performance gaps between this data and studio-recorded code-switching sets would highlight the value of in-the-wild examples for real applications.
- The dataset may expose switching patterns tied to specific social contexts that controlled corpora miss.
Load-bearing premise
The mining pipeline accurately detects genuine code-switching instances from YouTube audio without introducing major errors or biases.
What would settle it
A manual review of several hundred randomly sampled segments from the released dataset showing that a large fraction lack actual code-switching or were mislabeled by the pipeline.
Figures


read the original abstract
We present CS-YODAS, a Creative Commons-licensed dataset of in-the-wild code-switched speech mined from multilingual YouTube data. Code-switching (CS), or the alternation between languages within an utterance or conversation, is common in multilingual settings but remains underrepresented in existing CS speech resources, which are typically small, domain-specific, or artificially constructed. Building on the YODAS corpus, we develop a scalable, human-in-the-loop pipeline for identifying and validating naturally occurring code-switching. The resulting dataset, which totals 313 hours and spans 7 matrix languages, provides diverse, real-world examples of spontaneous code-switched speech. We further analyze the distribution and characteristics of code-switching in the wild, examining language-pair frequencies and switching patterns, and report baseline results for spoken language identification. We hope that CS-YODAS will encourage broader and more comprehensive research on code-switched speech. Dataset link: https://huggingface.co/datasets/byan/cs-yodas.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CS-YODAS, a Creative Commons-licensed 313-hour dataset of spontaneous code-switched speech mined from multilingual YouTube data via a scalable human-in-the-loop pipeline. It covers 7 matrix languages, includes analysis of language-pair frequencies and switching patterns, reports baseline spoken language identification results, and releases the data on Hugging Face to support research on underrepresented code-switching phenomena.
Significance. If the pipeline reliably extracts natural code-switching instances, the dataset would be a valuable addition to the field by providing a large-scale, in-the-wild resource that contrasts with existing small, domain-specific, or artificial CS corpora, potentially enabling more robust modeling of real-world multilingual speech.
major comments (2)
- [Abstract / pipeline description] Abstract and pipeline description: the central claim that the human-in-the-loop pipeline produces a high-quality dataset of naturally occurring code-switching rests on unquantified validation; no precision, recall, error rates, or inter-annotator agreement figures are reported for the identification or validation stages, making it impossible to assess whether the 313 hours contain substantial noise or bias.
- [Results / dataset statistics] Results section on dataset statistics: the reported 313 hours and 7 matrix languages are presented without a breakdown of hours per language pair, per-matrix-language distribution after filtering, or details on how post-validation duration was computed, which weakens the claim of diversity and scale.
minor comments (2)
- [Baseline results] The baseline spoken language identification results are mentioned but lack details on the model used, evaluation splits, or comparison to prior CS LID work.
- [Dataset release] Dataset link is provided, but the manuscript should include a brief description of the exact Hugging Face repository structure and any accompanying metadata files.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the CS-YODAS paper. The comments highlight important areas for improving the presentation of the pipeline validation and dataset statistics. We address each point below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract / pipeline description] Abstract and pipeline description: the central claim that the human-in-the-loop pipeline produces a high-quality dataset of naturally occurring code-switching rests on unquantified validation; no precision, recall, error rates, or inter-annotator agreement figures are reported for the identification or validation stages, making it impossible to assess whether the 313 hours contain substantial noise or bias.
Authors: We agree that the absence of quantitative metrics limits the ability to evaluate the pipeline's reliability. The current manuscript describes the human-in-the-loop stages at a high level but does not report precision, recall, error rates, or agreement figures. In the revised version, we will add a dedicated subsection on validation methodology, including inter-annotator agreement computed on a sampled subset of segments and estimated precision from the human validation stage. This will allow readers to better assess potential noise or bias. revision: yes
-
Referee: [Results / dataset statistics] Results section on dataset statistics: the reported 313 hours and 7 matrix languages are presented without a breakdown of hours per language pair, per-matrix-language distribution after filtering, or details on how post-validation duration was computed, which weakens the claim of diversity and scale.
Authors: We acknowledge that the reported aggregate figures (313 hours across 7 matrix languages) lack granular breakdowns, which would better support claims of diversity. The revised manuscript will include a table with hours per language pair and per matrix language after filtering, as well as a clear description of how post-validation durations were calculated (accounting for segment trimming and removal of non-CS content). These details are derivable from the released dataset and will be added to the results section. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a data-mining and dataset-release effort describing a human-in-the-loop pipeline to extract code-switched speech from YouTube. No equations, parameter fitting, predictions, uniqueness theorems, or derivations are present; the central claim (existence of the 313-hour CS-YODAS corpus with stated language coverage) is supported directly by the pipeline description and does not reduce to any self-referential input by construction. This is the expected non-finding for a purely descriptive resource paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Inthecurrenteraoflarge-scalemultilingualspeech processing, models such as Whisper (Radford etal.,2023),MMS(Pratapetal.,2024),andOWSM (Peng et al., 2025) enable automatic speech recog- nition (ASR) and language identification (LID) across hundreds of languages. These advances are supported by massive collections of speech, providingbroadcovera...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Dataset Construction 2.1. Source Corpus and Motivation CS-YODAS is derived from the YODAS corpus (Li et al., 2023b), a large-scale multilingual speech resource collected from publicly available YouTube content – by implication, CS-YODAS is under the Creative Commons license. Specifically, we use the cleaned YODAS from the OWSM v4 project (Peng et al., 202...
2025
-
[4]
Does the segment contain <lang1>? 1https://huggingface.co/Qwen/Qwen3-14B Set Samples Evaluated Precision mine_iter0 700 18.0% mine_iter1 120 70.0% Table 2: Precision of samples selected from mine_iter0vsmine_iter1, measured via agreement with human evaluations
-
[5]
Is <lang1> the matrix language?
-
[6]
Does the segment contain <lang2>?
-
[7]
Yes”, “No
Are all <lang2> words proper nouns? Each of these must be answered with “Yes”, “No”, or “I can’t tell”. Additionally, we solicit comments for each segment where any of Q1-4 were not an- swered with "Yes". This human feedback is then utilized via in- context learning when prompting the LLM to gen- erate responses to the same 5 questions for all candidate s...
2025
-
[8]
yeah”, “like
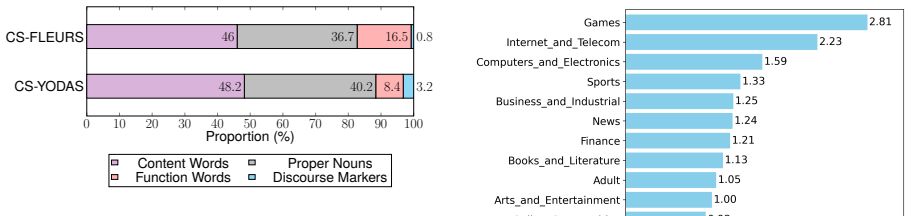
Dataset Analyses 3.1. Overview The primary motivation of our dataset analysis is to augment the dataset with additional metadata, such as language roles, parts-of-speech, and text or audio domains. In this section, we describe our methodology for generating metadata and summa- rize the metadata distributions. Please be aware that the following analyses ar...
1993
-
[9]
Baseline Experiments 4.1. Overview Modern multilingual speech recognition and trans- lation systems rely on accurate spoken LID both for curating large-scale training datasets (Valk and Alumäe, 2021; Peng et al., 2025) and for routing input to the language-specific modules (Radford et al., 2023; Pratap et al., 2024). However, current spoken LID systems (J...
2021
-
[10]
are almost exclusively trained under the as- sumption that utterances are purely monolingual, ignoring the possibility that a single utterance may contain multiple languages. Prior work has shown thatthismonolingualbiasgreatlylimitsthequalityof downstream speech processing for code-switched Train Set FLEURS CS-FLEURS XTTS1 MMS READ ara-eng cmn-eng fra-eng...
2023
-
[11]
w/o CS-YODAS
training set with the XTTS-generated train- ing data from CS-FLEURS and (2) further includ- ing CS-YODAS data.3 Both configurations contain 102 monolingual languages and 16 code-switched language pairs. The 16 pairs originate from CS- FLEURS, with 6 of them further supplemented by datafromCS-YODAS.Werefertothesesettingsas “w/o CS-YODAS” and “w/ CS-YODAS” ...
2024
-
[12]
Using CS-YODAS along with the existing CS-FLEURS, we are able to show that synthetically generated code-switching has yet to thoroughly mimic the patterns observed in the wild
Conclusion In summary, our work introduces CS-YODAS, a large-scale dataset of spontaneous, naturally oc- curring code-switched speech. Using CS-YODAS along with the existing CS-FLEURS, we are able to show that synthetically generated code-switching has yet to thoroughly mimic the patterns observed in the wild. Further, we show that synthetic code- switche...
-
[13]
Limitations While CS-YODAS represents a significant step to- wardlarge-scale,naturallyoccurringcode-switched speech resources, several limitations remain. First, the underlying source corpus, YODAS, is based on Creative Commons YouTube content, which inherently biases the dataset toward pub- licly available and broadcast-style material, such as news, educ...
-
[14]
Annotators were recruited for this project on a volunteer basis and were made aware of our data mining approach and thus agreed to the use of their feedback to refine the dataset
Ethics Statement This dataset is a mined subset from an already publicly released dataset, so we do not foresee any harm arising from its content. Annotators were recruited for this project on a volunteer basis and were made aware of our data mining approach and thus agreed to the use of their feedback to refine the dataset
-
[15]
languages
Example LLM Prompts 8.1. Overview Thissectionprovidesexamplesofthepromptsused for text-based LID and human-in-the-loop Valida- tion, supplementing the main description of the LLM-based data mining pipeline in §2. 8.2. Text-based LID (System) You are performing text-based language iden- tification. We are trying to identify code-mixed or code- switched utt...
-
[16]
Is the transcript correct?
-
[17]
Does the speech contain Chinese?
-
[18]
Is Chinese the matrix language?
-
[19]
Does the speech contain English?
-
[20]
Q1": "Yes
Are all English words proper nouns? (Assistant) {"Q1": "Yes", "Q2": "Yes", "Q3": "Yes", "Q4": "Yes", "Q5": "No", "Comments": ""} ...100 in-context examples are provided in total... (User) <Prompt with target segment> (Assistant) <Human-in-the-loop Validation output> Table 8: Example prompt used for human-in-the- loop validation. In-context examples are de...
-
[21]
References Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis Ty- ers, and Gregor Weber. 2020. Common Voice: A massively-multilingual speech corpus. InProc. LREC, pages 4218–4222. Laurie Burchell, Alexandra Birch, Robert P Thomp- son,andKennethHeafield.2024. Code-switched langu...
-
[22]
Building bilingual corpora.Advances in the Study of Bilingualism, pages 93–111. Anuj Diwan, Rakesh Vaideeswaran, Sanket Shah, Ankita Singh, Srinivasa Raghavan, Shreya Khare,VinitUnni,SaurabhVyas,AkashRajpuria, Chiranjeevi Yarra, Ashish Mittal, Prasanta Ku- mar Ghosh, Preethi Jyothi, Kalika Bali, Vivek Seshadri, Sunayana Sitaram, Samarth Bharad- waj, Jai N...
-
[23]
Robust speech recognition via large-scale weak supervision. InProc. ICML, pages 28492– 28518. Pradeep Rangan, Sundeep Teki, and Hemant Misra. 2020. Exploiting spectral augmentation forcode-switchedspokenlanguageidentification. arXiv preprint arXiv:2010.07130. Jörgen Valk and Tanel Alumäe. 2021. VoxLin- gua107: a dataset for spoken language recogni- tion. ...
-
[24]
A first south African corpus of multilin- gual code-switched soap opera speech. InProc. LREC. Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, and Emmanuel Dupoux
-
[25]
VoxPopuli: A large-scale multilingual speech corpus for representation learning, semi- supervised learning and interpretation. InProc. ACL -IJCNLP. Qingzheng Wang, Hye-jin Shim, Jiancheng Sun, and Shinji Watanabe. 2025. Geolocation-aware robust spoken language identification. InProc. IEEE ASRU. Brian Yan, Injy Hamed, Shuichiro Shimizu, Vasista Sai Lodagal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.