Distortion-Resilient Robotic Imitation Learning for Autonomous Cable Routing
Pith reviewed 2026-06-27 10:06 UTC · model grok-4.3
The pith
A framework combining image quality assessment and confidence-based learning enables distortion-resilient imitation learning for robotic cable routing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
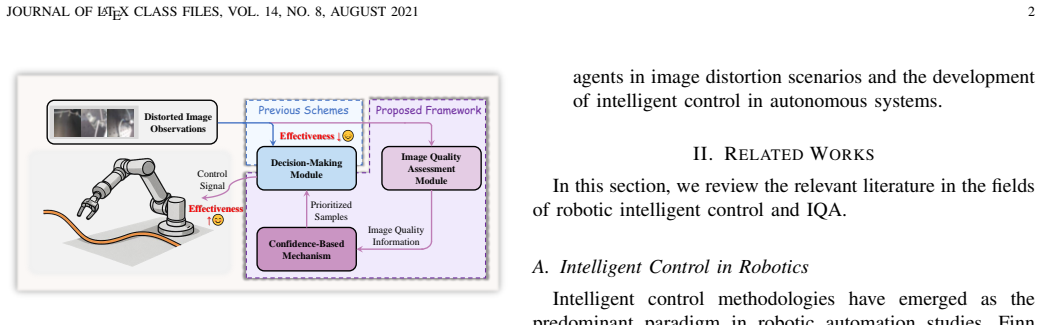
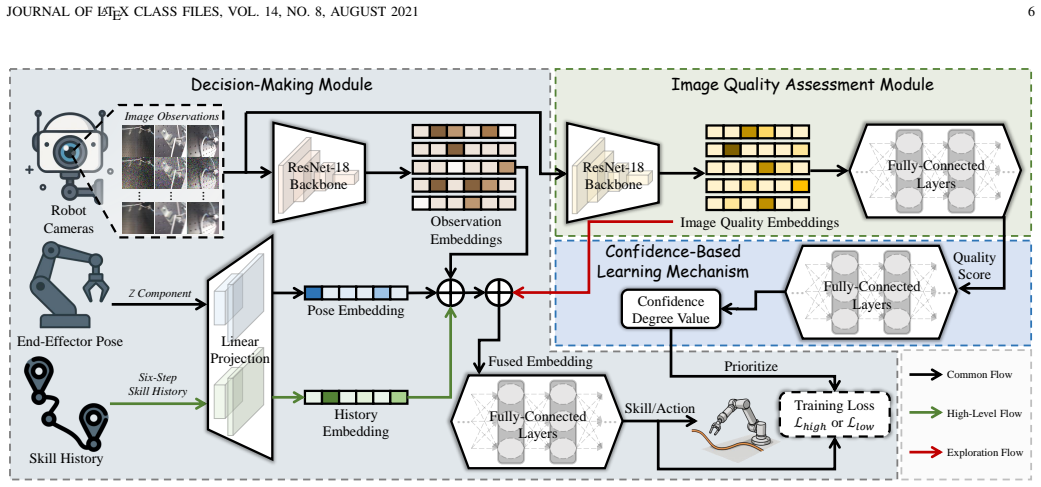
The central claim is that the formulated framework, consisting of an image quality assessment module, a confidence-based learning mechanism, and a decision-making module, enhances the overall performance of the decision-making module even under distorted image observations by synergizing quality extraction with adaptive prioritization of challenging samples.
What carries the argument
The synergy between the image quality assessment module, which extracts quality information from observations, and the confidence-based learning mechanism, which adaptively prioritizes challenging samples to improve the decision-making module.
If this is right
- The decision-making module determines appropriate discrete skills or continuous actions more effectively under distortion.
- The overall system maintains high performance in practical scenarios where image distortion frequently occurs.
- Image quality information is exploited to enhance the performance of intelligent control methodologies.
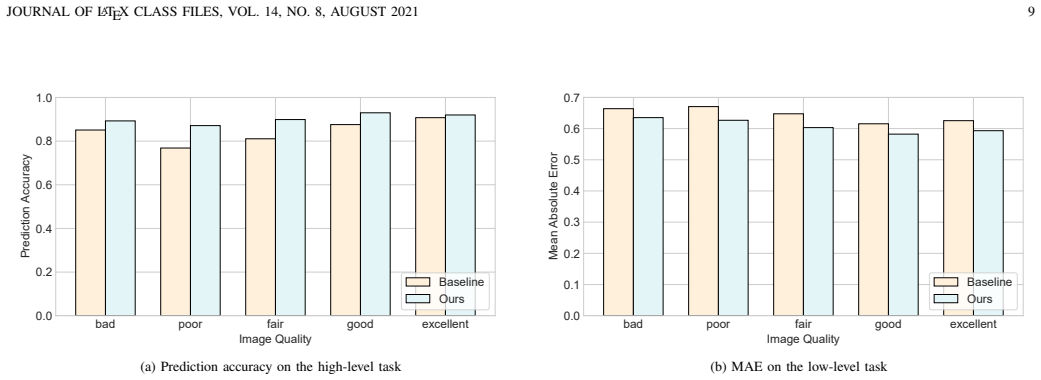
- Experimental results demonstrate enhancement of the decision-making module's performance.
Where Pith is reading between the lines
- The same modules could extend to other robotic manipulation tasks that depend on visual feedback in variable lighting or sensor conditions.
- Industrial deployments might tolerate lower-cost cameras or less controlled environments without sacrificing autonomy.
- The framework could be tested on physical robot hardware to check transfer from any simulation-based experiments.
- Integration with additional sensor types might further reduce reliance on pristine image data.
Load-bearing premise
The image quality assessment module and confidence-based learning mechanism can be combined in a way that reliably improves policy learning from distorted observations rather than introducing new failure modes.
What would settle it
Apply the full framework and a standard imitation learning baseline to the same cable routing task under controlled image distortions; if the framework shows no performance gain or lower performance on the decision-making module, the central claim does not hold.
Figures



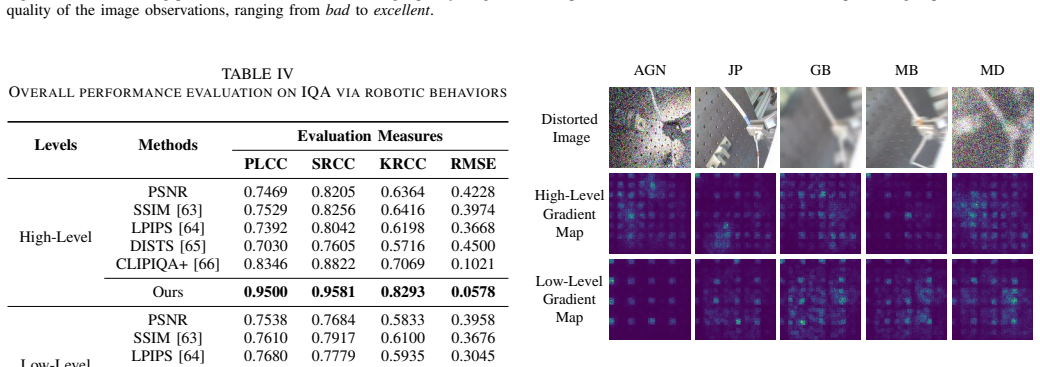
read the original abstract
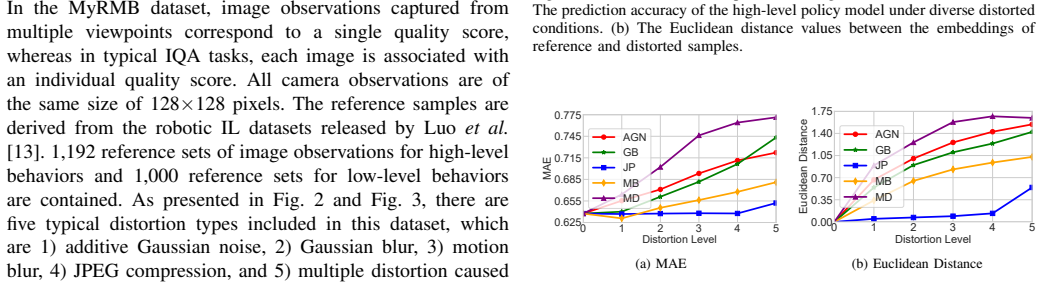
The rapid development of intelligent control methodologies has endowed robots with powerful autonomous intelligence. Cable routing, a ubiquitous foundational task in industry, provides a rigorous benchmark for robotic dexterity and sequential decision-making. In these practical scenarios, image observation distortion frequently occurs. Samples characterized by low-quality image observations often hinder accurate model training, posing challenges to the reliability and accuracy of intelligent control systems. Nevertheless, no dedicated intelligent control solution has been proposed for scenarios of image signal distortion. Meanwhile, image quality information has not been sufficiently exploited to further enhance the performance of intelligent control methodologies. To this end, we propose a novel robotic imitation learning framework that comprises an image quality assessment module, a confidence-based learning mechanism, and a decision-making module, which is designed to maintain high performance even under distorted image observations. In the proposed framework, the image quality assessment module synergizes with the confidence-based learning mechanism to enhance the efficacy of the decision-making module. Specifically, the image quality assessment module is incorporated to extract image quality information from image observations, while the confidence-based learning mechanism adaptively prioritizes challenging samples to improve learning effectiveness. The decision-making module determines appropriate discrete skills or continuous actions. Experimental results demonstrate that our formulated framework enhances the overall performance of the decision-making module.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a three-module robotic imitation learning framework for autonomous cable routing under image distortion, consisting of an image quality assessment module to extract quality information, a confidence-based learning mechanism to prioritize challenging samples, and a decision-making module for discrete skills or continuous actions. The central claim is that the first two modules synergize to enhance the decision-making module's performance, as demonstrated by experimental results.
Significance. If the empirical claims hold with rigorous validation, the work could address a practical gap in robust imitation learning for industrial tasks where sensor distortions occur. It attempts to integrate image quality assessment with adaptive learning in a way that may improve reliability for sequential decision-making, though the absence of supporting details limits assessment of novelty or impact.
major comments (3)
- [Abstract] Abstract: The assertion that 'Experimental results demonstrate that our formulated framework enhances the overall performance of the decision-making module' is unsupported by any metrics, baselines, ablation studies, task descriptions, distortion models, or quantitative comparisons, which are load-bearing for the central empirical claim.
- [§4 (Experiments)] §4 (Experiments): No details are provided on evaluation metrics, baseline methods, dataset characteristics, cable-routing task setup, or how quality scores are fused into the confidence mechanism, preventing verification of the claimed synergy and performance gains.
- [§3 (Method)] §3 (Method): The description of module integration remains qualitative with no equations, algorithms, or pseudocode specifying fusion of image quality information into the learning mechanism or decision-making policy, undermining reproducibility and the claim of reliable improvement without new failure modes.
minor comments (1)
- [Abstract/Introduction] The abstract and introduction contain repetitive phrasing about the challenges of image distortion without adding new information.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the current manuscript requires substantial expansion to substantiate the central claims with explicit metrics, implementation details, and reproducibility elements. We will prepare a major revision that incorporates all requested information while preserving the core framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Experimental results demonstrate that our formulated framework enhances the overall performance of the decision-making module' is unsupported by any metrics, baselines, ablation studies, task descriptions, distortion models, or quantitative comparisons, which are load-bearing for the central empirical claim.
Authors: We acknowledge that the abstract claim is stated at too high a level. In the revised manuscript we will replace the generic statement with a concise summary of the key quantitative findings (success-rate improvements under specific distortion models, comparison to baselines, and ablation outcomes) drawn from the expanded Section 4, ensuring the abstract is directly supported by the reported evidence. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): No details are provided on evaluation metrics, baseline methods, dataset characteristics, cable-routing task setup, or how quality scores are fused into the confidence mechanism, preventing verification of the claimed synergy and performance gains.
Authors: We agree that Section 4 currently lacks the necessary experimental specification. The revision will add: (i) explicit metrics (task success rate, average completion time, failure-mode breakdown), (ii) baseline descriptions (behavioral cloning, standard imitation learning variants, and distortion-robust alternatives), (iii) dataset statistics (number of demonstrations, distortion types and severity levels), (iv) full task setup (robot platform, cable types, workspace), and (v) the precise fusion rule (quality score mapped to per-sample loss weight via a monotonic function, with the resulting weighted objective written explicitly). revision: yes
-
Referee: [§3 (Method)] §3 (Method): The description of module integration remains qualitative with no equations, algorithms, or pseudocode specifying fusion of image quality information into the learning mechanism or decision-making policy, undermining reproducibility and the claim of reliable improvement without new failure modes.
Authors: We accept that the integration description must be made formal. The revised Section 3 will include: (i) the mathematical definition of the quality-to-weight mapping, (ii) the modified imitation-learning objective that incorporates the weight, (iii) the overall training algorithm in pseudocode, and (iv) a short discussion of potential failure modes introduced by the weighting together with mitigation steps. These additions will allow exact reproduction of the training procedure. revision: yes
Circularity Check
No derivation chain present; performance claim is purely empirical
full rationale
The manuscript describes a three-module framework (image quality assessment, confidence-based learning, decision-making) for imitation learning under distorted observations and states that 'Experimental results demonstrate that our formulated framework enhances the overall performance of the decision-making module.' No equations, first-principles derivations, fitted parameters, or uniqueness theorems appear in the text. The central claim is an empirical assertion whose grounding would require the (unprovided) experimental section, but the absence of any mathematical reduction means no step can be shown to equal its inputs by construction. Self-citations, if present elsewhere, are not load-bearing for any derivation here. This is the normal case of an empirical robotics paper with no circularity risk in its (non-existent) derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Integrating image and textual information in human–robot interactions for children with autism spectrum disorder,
X. Yang, M.-L. Shyu, H.-Q. Yu, S.-M. Sun, N.-S. Yin, and W. Chen, “Integrating image and textual information in human–robot interactions for children with autism spectrum disorder,”IEEE transactions on multimedia, vol. 21, no. 3, pp. 746–759, 2019
2019
-
[2]
Task intelligence of robots: Neural model-based mechanism of thought and online motion planning,
I.-B. Jeong, W.-R. Ko, G.-M. Park, D.-H. Kim, Y .-H. Yoo, and J.-H. Kim, “Task intelligence of robots: Neural model-based mechanism of thought and online motion planning,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 1, no. 1, pp. 41–50, 2017
2017
-
[3]
Scene recognition mechanism for service robot adapting various families: A cnn-based approach using multi-type cameras,
S. Liu, G. Tian, Y . Zhang, and P. Duan, “Scene recognition mechanism for service robot adapting various families: A cnn-based approach using multi-type cameras,”IEEE Transactions on Multimedia, vol. 24, pp. 2392–2406, 2021
2021
-
[4]
A topological approach to gait generation for biped robots,
N. Rosa and K. M. Lynch, “A topological approach to gait generation for biped robots,”IEEE Transactions on Robotics, vol. 38, no. 2, pp. 699–718, 2022
2022
-
[5]
Motion planning and cooperative manipulation for mobile robots with dual arms,
F. Sun, Y . Chen, Y . Wu, L. Li, and X. Ren, “Motion planning and cooperative manipulation for mobile robots with dual arms,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 6, no. 6, pp. 1345–1356, 2022
2022
-
[6]
Design and human- robot coupling performance analysis of flexible ankle rehabilitation robot,
D. Zeng, Y . Liu, C. Qu, J. Cong, Y . Hou, and W. Lu, “Design and human- robot coupling performance analysis of flexible ankle rehabilitation robot,”IEEE Robotics and Automation Letters, vol. 9, no. 1, pp. 579– 586, 2024
2024
-
[7]
Promoting trust in industrial human-robot collaboration through preference-based optimization,
G. Campagna, M. Lagomarsino, M. Lorenzini, D. Chrysostomou, M. Rehm, and A. Ajoudani, “Promoting trust in industrial human-robot collaboration through preference-based optimization,”IEEE Robotics and Automation Letters, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
2024
-
[8]
Toward safe distributed multi-robot navigation coupled with variational bayesian model,
L. Chen, Y . Wang, Z. Miao, M. Feng, Z. Zhou, H. Wang, and D. Wang, “Toward safe distributed multi-robot navigation coupled with variational bayesian model,”IEEE Transactions on Automation Science and Engi- neering, vol. 21, no. 4, pp. 7583–7598, 2024
2024
-
[9]
Neuronsgym: A hybrid framework and benchmark for robot navigation with sim2real policy learning,
H. Li, G. Hu, S. Liu, M. Ma, Y . Chen, and D. Zhao, “Neuronsgym: A hybrid framework and benchmark for robot navigation with sim2real policy learning,”IEEE Transactions on Emerging Topics in Computa- tional Intelligence, 2024
2024
-
[10]
Efficient online planning and robust optimal control for nonholonomic mobile robot in unstructured environments,
Y . Hu, W. Zhou, Y . Liu, M. Zeng, W. Ding, S. Li, G. Li, Z. Li, and A. Knoll, “Efficient online planning and robust optimal control for nonholonomic mobile robot in unstructured environments,”IEEE Transactions on Emerging Topics in Computational Intelligence, 2024
2024
-
[11]
Toward efficient self-motion- based memory representation for visuomotor navigation of embodied robot,
Q. Liu, H. Xin, Z. Liu, and H. Wang, “Toward efficient self-motion- based memory representation for visuomotor navigation of embodied robot,”IEEE Transactions on Emerging Topics in Computational Intel- ligence, 2025
2025
-
[12]
Do you want to make your robot warmer? make it more reactive!
A. B. Gim ´enez, E. Fern ´andez-Rodicio, ´A. Castro-Gonz ´alez, and M. A. Salichs, “Do you want to make your robot warmer? make it more reactive!”IEEE Transactions on Cognitive and Developmental Systems, vol. 15, no. 4, pp. 1971–1980, 2023
1971
-
[13]
Multi-stage cable routing through hierarchical imitation learning,
J. Luo, C. Xu, X. Geng, G. Feng, K. Fang, L. Tan, S. Schaal, and S. Levine, “Multi-stage cable routing through hierarchical imitation learning,”IEEE Transactions on Robotics, 2024
2024
-
[14]
One-shot domain-adaptive imitation learning via progressive learning applied to robotic pouring,
D. Zhang, W. Fan, J. Lloyd, C. Yang, and N. F. Lepora, “One-shot domain-adaptive imitation learning via progressive learning applied to robotic pouring,”IEEE Transactions on Automation Science and Engineering, vol. 21, no. 1, pp. 541–554, 2024
2024
-
[15]
Ranking- based generative adversarial imitation learning,
Z. Shi, X. Zhang, Y . Fang, C. Li, G. Liu, and J. Zhao, “Ranking- based generative adversarial imitation learning,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8967–8974, 2024
2024
-
[16]
Learning from demonstrations: A computationally efficient inverse reinforcement learning approach with simplified implementation,
Y . Lin, Z. Ni, and X. Zhong, “Learning from demonstrations: A computationally efficient inverse reinforcement learning approach with simplified implementation,”IEEE Transactions on Emerging Topics in Computational Intelligence, 2025
2025
-
[17]
A survey of imitation learning: Algorithms, recent developments, and challenges,
M. Zare, P. M. Kebria, A. Khosravi, and S. Nahavandi, “A survey of imitation learning: Algorithms, recent developments, and challenges,” IEEE Transactions on Cybernetics, vol. 54, no. 12, pp. 7173–7186, 2024
2024
-
[18]
Efficient training of artificial neural networks for autonomous navigation,
D. A. Pomerleau, “Efficient training of artificial neural networks for autonomous navigation,”Neural computation, vol. 3, no. 1, pp. 88–97, 1991
1991
-
[19]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 627–635
2011
-
[20]
Is imitation learning the route to humanoid robots?
S. Schaal, “Is imitation learning the route to humanoid robots?”Trends in cognitive sciences, vol. 3, no. 6, pp. 233–242, 1999
1999
-
[21]
An algorithmic perspective on imitation learning,
T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, J. Peters et al., “An algorithmic perspective on imitation learning,”Foundations and Trends® in Robotics, vol. 7, no. 1-2, pp. 1–179, 2018
2018
-
[22]
On robustness of robotic and autonomous systems perception: An assessment of image distortion on state-of-the-art robotic vision model,
C. R. Steffens, L. R. V . Messias, P. J. L. Drews-Jr, and S. S. d. C. Botelho, “On robustness of robotic and autonomous systems perception: An assessment of image distortion on state-of-the-art robotic vision model,”Journal of Intelligent & Robotic Systems, vol. 101, pp. 1–17, 2021
2021
-
[23]
A motion distortion resistant vslam system for quadruped robots based on deep learning,
Z. Li, F. Fang, B. Zhou, W. Sun, D. Shen, and K. Liu, “A motion distortion resistant vslam system for quadruped robots based on deep learning,” in2024 43rd Chinese Control Conference (CCC). IEEE, 2024, pp. 4278–4283
2024
-
[24]
Image quality assessment in visual reinforcement learning for fast-moving targets,
S. Ryoo, J. Jeong, and S. Han, “Image quality assessment in visual reinforcement learning for fast-moving targets,”International Journal of Control, Automation and Systems, vol. 22, no. 11, pp. 3303–3313, 2024
2024
-
[25]
Leveraging imitation learning in agricultural robotics: a comprehensive survey and comparative analysis,
S. Mahmoudi, A. Davar, P. Sohrabipour, R. B. Bist, Y . Tao, and D. Wang, “Leveraging imitation learning in agricultural robotics: a comprehensive survey and comparative analysis,”Frontiers in Robotics and AI, vol. 11, p. 1441312, 2024
2024
-
[26]
Embod- ied image quality assessment for robotic intelligence,
J. Zhang, C. Li, L. Yuan, G. Zheng, J. Hao, and G. Zhai, “Embod- ied image quality assessment for robotic intelligence,”arXiv preprint arXiv:2412.18774, 2024
-
[27]
Blind image quality measurement by exploiting high-order statistics with deep dictionary encoding network,
Q. Jiang, W. Gao, S. Wang, G. Yue, F. Shao, Y .-S. Ho, and S. Kwong, “Blind image quality measurement by exploiting high-order statistics with deep dictionary encoding network,”IEEE Transactions on Instru- mentation and Measurement, vol. 69, no. 10, pp. 7398–7410, 2020
2020
-
[28]
A novel rank learning based no-reference image quality assessment method,
F.-Z. Ou, Y .-G. Wang, J. Li, G. Zhu, and S. Kwong, “A novel rank learning based no-reference image quality assessment method,”IEEE Transactions on Multimedia, vol. 24, pp. 4197–4211, 2021
2021
-
[29]
Medical ultrasound image quality assessment for autonomous robotic screening,
Y . Song, Z. Zhong, B. Zhao, P. Zhang, Q. Wang, Z. Wang, L. Yao, F. Lv, and Y . Hu, “Medical ultrasound image quality assessment for autonomous robotic screening,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6290–6296, 2022
2022
-
[30]
Troubleshooting ethnic quality bias with curriculum domain adaptation for face image quality assessment,
F.-Z. Ou, B. Chen, C. Li, S. Wang, and S. Kwong, “Troubleshooting ethnic quality bias with curriculum domain adaptation for face image quality assessment,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 20 718–20 729
2023
-
[31]
Blind image quality assessment: A fuzzy neural network for opinion score distribution prediction,
Y . Gao, X. Min, Y . Zhu, X.-P. Zhang, and G. Zhai, “Blind image quality assessment: A fuzzy neural network for opinion score distribution prediction,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 3, pp. 1641–1655, 2024
2024
-
[32]
Refining uncertain features with self-distillation for face recognition and person re-identification,
F.-Z. Ou, X. Chen, K. Zhao, S. Wang, Y .-G. Wang, and S. Kwong, “Refining uncertain features with self-distillation for face recognition and person re-identification,”IEEE Transactions on Multimedia, vol. 26, pp. 6981–6995, 2024
2024
-
[33]
Clib-fiqa: Face image quality assessment with confidence calibration,
F.-Z. Ou, C. Li, S. Wang, and S. Kwong, “Clib-fiqa: Face image quality assessment with confidence calibration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1694–1704
2024
-
[34]
Spatio-temporal feature integration for quality assessment of stitched omnidirectional images,
H. Hu, F. Shao, H. Wang, B. Mu, H. Chen, Q. Jiang, and W. Chen, “Spatio-temporal feature integration for quality assessment of stitched omnidirectional images,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 8, no. 2, pp. 1484–1499, 2024
2024
-
[35]
Unsupervised learning for physical interaction through video prediction,
C. Finn, I. Goodfellow, and S. Levine, “Unsupervised learning for physical interaction through video prediction,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[36]
Learning hand-eye coordination for robotic grasping with deep learning and large- scale data collection,
S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen, “Learning hand-eye coordination for robotic grasping with deep learning and large- scale data collection,”The International journal of robotics research, vol. 37, no. 4-5, pp. 421–436, 2018
2018
-
[37]
Geneworker: An end-to-end robotic reinforcement learning approach with collaborative generator and worker networks,
H. Wang, H. Man, W. Cui, R. Lu, C. Cai, and X. Fan, “Geneworker: An end-to-end robotic reinforcement learning approach with collaborative generator and worker networks,”Neural Networks, p. 106472, 2024
2024
-
[38]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausmanet al., “Do as i can, not as i say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choroman- ski, T. Ding, D. Driess, A. Dubey, C. Finnet al., “Rt-2: Vision-language- action models transfer web knowledge to robotic control,”arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
A. Padalkar, A. Pooley, A. Jain, A. Bewley, A. Herzog, A. Ir- pan, A. Khazatsky, A. Rai, A. Singh, A. Brohanet al., “Open x- embodiment: Robotic learning datasets and rt-x models,”arXiv preprint arXiv:2310.08864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Metaiqa: Deep meta- learning for no-reference image quality assessment,
H. Zhu, L. Li, J. Wu, W. Dong, and G. Shi, “Metaiqa: Deep meta- learning for no-reference image quality assessment,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 14 143–14 152
2020
-
[43]
J. Vanschoren, “Meta-learning: A survey,”arXiv preprint arXiv:1810.03548, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
Blindly assess image quality in the wild guided by a self-adaptive hyper network,
S. Su, Q. Yan, Y . Zhu, C. Zhang, X. Ge, J. Sun, and Y . Zhang, “Blindly assess image quality in the wild guided by a self-adaptive hyper network,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3667–3676
2020
-
[45]
Forgetting to remember: A scalable incremental learning framework for cross-task blind image quality assessment,
R. Ma, Q. Wu, K. N. Ngan, H. Li, F. Meng, and L. Xu, “Forgetting to remember: A scalable incremental learning framework for cross-task blind image quality assessment,”IEEE Transactions on Multimedia, vol. 25, pp. 8817–8827, 2023
2023
-
[46]
No-reference stereoscopic image quality assessment based on image distortion and stereo perceptual information,
L. Shen, R. Fang, Y . Yao, X. Geng, and D. Wu, “No-reference stereoscopic image quality assessment based on image distortion and stereo perceptual information,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 3, no. 1, pp. 59–72, 2019
2019
-
[47]
Vsoiqe: A novel viewport-based stitched 360° omnidirectional image quality evaluator,
C. Tian, X. Chai, G. Chen, F. Shao, Q. Jiang, X. Meng, L. Xu, and Y .- S. Ho, “Vsoiqe: A novel viewport-based stitched 360° omnidirectional image quality evaluator,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 10, pp. 6557–6572, 2022
2022
-
[48]
Blind image quality assessment via cross-view consistency,
Y . Zhu, Y . Li, W. Sun, X. Min, G. Zhai, and X. Yang, “Blind image quality assessment via cross-view consistency,”IEEE Transactions on Multimedia, vol. 25, pp. 7607–7620, 2023. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
2023
-
[49]
Perceptual quality assessment of retouched face images,
G. Yue, H. Wu, Q. Jiang, T. Zhou, W. Yan, and T. Wang, “Perceptual quality assessment of retouched face images,”IEEE Transactions on Multimedia, vol. 26, pp. 5741–5752, 2024
2024
-
[50]
Robonet: Large-scale multi-robot learning,
S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, and C. Finn, “Robonet: Large-scale multi-robot learning,” inConference on Robot Learning. PMLR, 2020, pp. 885– 897
2020
-
[51]
Bridgedata v2: A dataset for robot learning at scale,
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen- Estruch, A. W. He, V . Myers, M. J. Kim, M. Duet al., “Bridgedata v2: A dataset for robot learning at scale,” inConference on Robot Learning. PMLR, 2023, pp. 1723–1736
2023
-
[52]
Interactive language: Talking to robots in real time,
C. Lynch, A. Wahid, J. Tompson, T. Ding, J. Betker, R. Baruch, T. Armstrong, and P. Florence, “Interactive language: Talking to robots in real time,”IEEE Robotics and Automation Letters, 2023
2023
-
[53]
Objective quality assessment of multiply distorted images,
D. Jayaraman, A. Mittal, A. K. Moorthy, and A. C. Bovik, “Objective quality assessment of multiply distorted images,” in2012 Conference record of the forty sixth asilomar conference on signals, systems and computers (ASILOMAR). IEEE, 2012, pp. 1693–1697
2012
-
[54]
Hybrid no-reference quality metric for singly and multiply distorted images,
K. Gu, G. Zhai, X. Yang, and W. Zhang, “Hybrid no-reference quality metric for singly and multiply distorted images,”IEEE Transactions on Broadcasting, vol. 60, no. 3, pp. 555–567, 2014
2014
-
[55]
Image database tid2013: Peculiarities, results and perspectives,
N. Ponomarenko, L. Jin, O. Ieremeiev, V . Lukin, K. Egiazarian, J. Astola, B. V ozel, K. Chehdi, M. Carli, F. Battistiet al., “Image database tid2013: Peculiarities, results and perspectives,”Signal processing: Image com- munication, vol. 30, pp. 57–77, 2015
2015
-
[56]
Kadid-10k: A large-scale artificially distorted iqa database,
H. Lin, V . Hosu, and D. Saupe, “Kadid-10k: A large-scale artificially distorted iqa database,” in2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX). IEEE, 2019, pp. 1–3
2019
-
[57]
Degraded reference image quality assessment,
S. Athar and Z. Wang, “Degraded reference image quality assessment,” IEEE Transactions on Image Processing, vol. 32, pp. 822–837, 2023
2023
-
[58]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[59]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,”Machine learning, vol. 8, pp. 229–256, 1992
1992
-
[60]
Policy gradient methods for reinforcement learning with function approximation,
R. S. Sutton, D. McAllester, S. Singh, and Y . Mansour, “Policy gradient methods for reinforcement learning with function approximation,” in Proceedings of the 12th International Conference on Neural Information Processing Systems, 1999, pp. 1057–1063
1999
-
[61]
Group normalization,
Y . Wu and K. He, “Group normalization,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 3–19
2018
-
[62]
Distributed representations of words and phrases and their composi- tionality,
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their composi- tionality,”Advances in neural information processing systems, vol. 26, 2013
2013
-
[63]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[64]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[65]
Image quality assessment: Unifying structure and texture similarity,
K. Ding, K. Ma, S. Wang, and E. P. Simoncelli, “Image quality assessment: Unifying structure and texture similarity,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 5, pp. 2567– 2581, 2020
2020
-
[66]
Exploring clip for assessing the look and feel of images,
J. Wang, K. C. Chan, and C. C. Loy, “Exploring clip for assessing the look and feel of images,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 2, 2023, pp. 2555–2563
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.