Motion Reinforces Appearance: RGB-Skeleton Gated Residual Fusion for Micro-Gesture Online Recognition
Pith reviewed 2026-06-27 10:53 UTC · model grok-4.3
The pith
A gated residual module adaptively injects skeleton motion cues into RGB features to improve micro-gesture localization and classification in untrimmed videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
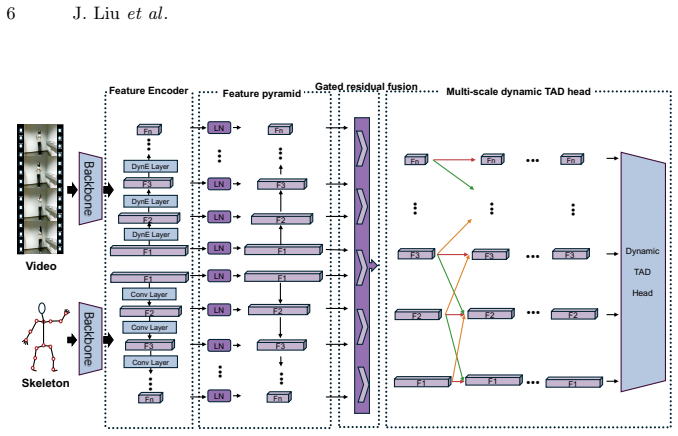
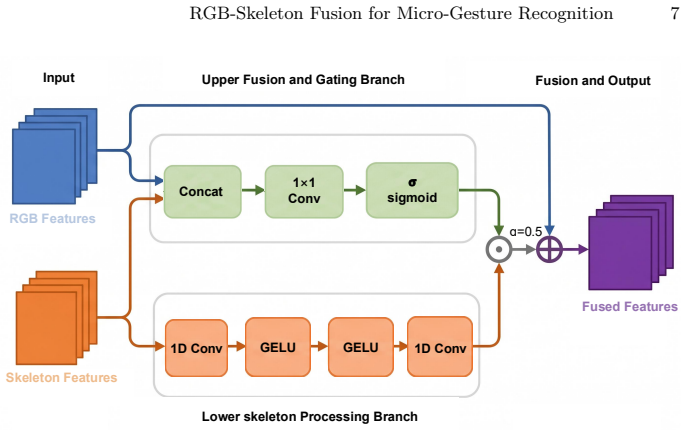
DyFADet+ extends the original DyFADet into a dual-stream RGB-skeleton framework in which both modalities are projected into shared multi-scale temporal embeddings and fused through a gated residual module that adaptively injects skeleton motion into the RGB representation; the fused features are decoded by a Dynamic TAD head for online classification and boundary regression, producing an F1 score of 40.88 on the SMG dataset.
What carries the argument
The gated residual module that adaptively injects skeleton motion into the RGB representation rather than using naive concatenation.
If this is right
- The dual-stream model with shared temporal embeddings produces more accurate start-time, end-time, and category outputs for each micro-gesture instance than single-modality baselines.
- Adaptive rather than fixed fusion allows the network to emphasize motion information only where it reinforces appearance cues.
- The resulting features support real-time online processing on untrimmed video without requiring trimmed clips.
- The same fused representation feeds directly into an existing Dynamic TAD decoding head for boundary regression.
Where Pith is reading between the lines
- The gated injection pattern could be tested on other paired modalities such as depth or optical flow for the same task.
- If the gate learns to suppress skeleton input on certain gesture classes, that pattern might reveal which micro-gestures are primarily appearance-driven.
- Extending the shared embedding space to include audio could address cases where visual motion alone remains ambiguous.
Load-bearing premise
Skeleton motion supplies complementary cues that the gated residual module can usefully inject into RGB features, rather than performance gains arising mainly from architecture scale, training schedule, or dataset properties.
What would settle it
A controlled ablation in which the gated residual module is replaced by simple feature concatenation or by an RGB-only stream while keeping all other components identical and observing whether the F1 score remains at or above 40.88.
Figures
read the original abstract
Micro-gesture analysis attracts increasing attention for inferring spontaneous emotion from subtle body movements. Micro-gesture online recognition, which localizes and classifies each gesture instance in untrimmed videos, is a core task in the 4th EI-MiGA-IJCAI Challenge. Compared with typical temporal action detection, MGR emphasizes the localization and classification of actions, requiring the model to output the start time, end time, and category of each micro-gesture. Moreover, since micro-gestures are highly spontaneous, relying solely on a single modality makes it difficult to capture the complete and accurate multi-modal cues. In this work, we propose DyFADet+, which extends DyFADet into a dual-stream RGB-skeleton framework. In our model, both modalities are projected into shared multi-scale temporal embeddings and fused through a gated residual module, which adaptively injects skeleton motion into the RGB representation rather than using naive concatenation. Finally, these fused features are decoded by a Dynamic TAD head for online classification and boundary regression. On the SMG dataset, our method achieves an F1 score of 40.88, ranking 2nd in the Micro-gesture Online Recognition track.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DyFADet+, a dual-stream RGB-skeleton extension of DyFADet for micro-gesture online recognition. Both modalities are projected into shared multi-scale temporal embeddings and fused by a gated residual module that adaptively injects skeleton motion cues into the RGB stream (rather than naive concatenation); the fused representation is decoded by a Dynamic TAD head to produce online start/end times and class labels. On the SMG dataset the method reports an F1 score of 40.88 and second place in the Micro-gesture Online Recognition track of the 4th EI-MiGA-IJCAI Challenge.
Significance. If the gated residual fusion can be shown to be the operative factor, the work would supply a concrete, learnable mechanism for injecting complementary motion information into appearance features for subtle, spontaneous actions. The competitive ranking on an external challenge dataset indicates potential practical value for multi-modal micro-gesture analysis, but the absence of controlled ablations prevents assessment of whether the reported gain exceeds what would be obtained by simply increasing model capacity or altering the training schedule.
major comments (2)
- [Abstract] Abstract (paragraph on DyFADet+): the central claim that the gated residual module 'adaptively injects skeleton motion into the RGB representation rather than using naive concatenation' is load-bearing for the attribution of the 40.88 F1 score, yet the manuscript supplies no quantitative delta, ablation table, or controlled experiment that isolates the gated module while holding the dual-stream architecture, shared embeddings, and Dynamic TAD head fixed.
- [Abstract] Abstract: the reported F1 score of 40.88 is presented without baselines, ablation tables, error bars, or any description of how the gated module was trained or validated, so the performance claim cannot be checked against the DyFADet baseline or against alternative fusion strategies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that the manuscript does not currently provide ablations or baselines to isolate the contribution of the gated residual fusion. We address each point below and commit to adding the requested experiments in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on DyFADet+): the central claim that the gated residual module 'adaptively injects skeleton motion into the RGB representation rather than using naive concatenation' is load-bearing for the attribution of the 40.88 F1 score, yet the manuscript supplies no quantitative delta, ablation table, or controlled experiment that isolates the gated module while holding the dual-stream architecture, shared embeddings, and Dynamic TAD head fixed.
Authors: We agree that the manuscript lacks a controlled ablation isolating the gated residual module. In the revised version we will add experiments that hold the dual-stream architecture, shared multi-scale embeddings, and Dynamic TAD head fixed while comparing gated residual fusion against naive concatenation and alternative fusion strategies, thereby supplying the requested quantitative deltas. revision: yes
-
Referee: [Abstract] Abstract: the reported F1 score of 40.88 is presented without baselines, ablation tables, error bars, or any description of how the gated module was trained or validated, so the performance claim cannot be checked against the DyFADet baseline or against alternative fusion strategies.
Authors: We acknowledge that the current manuscript does not include explicit baselines, ablation tables, error bars, or expanded training details for the gated module. The revision will incorporate comparisons to the original DyFADet, alternative fusion approaches, and a description of the training/validation protocol; error bars from repeated runs will be added if compute permits. revision: yes
Circularity Check
No circularity: empirical result on external benchmark with independent evaluation
full rationale
The paper proposes DyFADet+ as an architectural extension (dual-stream RGB-skeleton with shared embeddings and gated residual fusion) and reports an F1 score of 40.88 on the SMG dataset from the EI-MiGA-IJCAI Challenge. No equations, predictions, or derivations are present that reduce by construction to fitted inputs or self-referential quantities. The central claim is an externally measured performance number on a held-out challenge dataset, which is falsifiable and does not rely on self-citation chains or ansatzes for its validity. Minor self-citation of the base DyFADet model (if by overlapping authors) is not load-bearing for the reported result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Caba Heilbron, F., Escorcia, V., Ghanem, B., Carlos Niebles, J.: ActivityNet: A large-scale video benchmark for human activity understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 961–970 (2015)
2015
-
[2]
Calvo, R.A., D’Mello, S.: Affect detection: An interdisciplinary review of models, methods, and their applications. IEEE Transactions on Affective Computing1(1), 18–37 (2010).https://doi.org/10.1109/T-AFFC.2010.1 RGB-Skeleton Fusion for Micro-Gesture Recognition 11
-
[3]
arXiv preprint arXiv:2408.03097 (2024)
Chen, G., Wang, F., Li, K., Wu, Z., Fan, H., Yang, Y., Wang, M., Guo, D.: Prototype learning for micro-gesture classification. arXiv preprint arXiv:2408.03097 (2024)
arXiv 2024
-
[4]
In: Proceedings of the IJCAI 2024 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2024)
Chen, H., Schuller, B.W., Adeli, E., Zhao, G.: The 2nd challenge on micro-gesture analysis for hidden emotion understanding (MiGA) 2024: Dataset and results. In: Proceedings of the IJCAI 2024 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2024). CEUR Workshop Proceedings, vol. 3848 (2024)
2024
-
[5]
International Journal of Computer Vision131(5), 1346–1366 (2023).https://doi.org/10.1007/ s11263-023-01761-6
Chen, H., Shi, H., Liu, X., Li, X., Zhao, G.: SMG: A micro-gesture dataset to- wards spontaneous body gestures for emotional stress state analysis. International Journal of Computer Vision131(5), 1346–1366 (2023).https://doi.org/10.1007/ s11263-023-01761-6
2023
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Y., Zhang, Z., Yuan, C., Li, B., Deng, Y., Hu, W.: Channel-wise topology refinement graph convolution for skeleton-based action recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13359–13368 (2021)
2021
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Duan, H., Zhao, Y., Chen, K., Lin, D., Dai, B.: Revisiting skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2969–2978 (2022)
2022
-
[8]
PsycEXTRA Dataset (1969).https://doi.org/10.1037/e525532009-012
Ekman, P., Friesen, W.V.: Nonverbal leakage and clues to deception. PsycEXTRA Dataset (1969).https://doi.org/10.1037/e525532009-012
-
[9]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Gu, J., Li, K., Wang, F., Wei, Y., Wu, Z., Fan, H., Wang, M.: Motion matters: Motion-guided modulation network for skeleton-based micro-action recognition. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 5461–5470 (2025)
2025
-
[10]
arXiv preprint arXiv:2507.08344 (2025)
Gu, J., Wang, F., Li, K., Wei, Y., Wu, Z., Guo, D.: MM-Gesture: Towards precise micro-gesture recognition through multimodal fusion. arXiv preprint arXiv:2507.08344 (2025)
arXiv 2025
-
[11]
IEEE Transactions on Circuits and Systems for Video Technology (2024), arXiv:2403.05234
Guo, D., Li, K., Hu, B., Zhang, Y., Wang, M.: Benchmarking micro-action recog- nition: Dataset, methods, and applications. IEEE Transactions on Circuits and Systems for Video Technology (2024), arXiv:2403.05234
arXiv 2024
-
[12]
In: Proceed- ings of the IJCAI 2023 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2023)
Guo, X.P., Peng, W., Huang, H., Xia, Z.: Micro-gesture online recognition with graph-convolution and multiscale transformers for long sequence. In: Proceed- ings of the IJCAI 2023 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2023). CEUR Workshop Proceedings, vol. 3522 (2023)
2023
-
[13]
IEEE Transactions on Circuits and Systems for Video Technology32(10), 7120–7132 (2022)
Hao, Y., Wang, S., Cao, P., Gao, X., Xu, T., Wu, J., He, X.: Attention in attention: Modeling context correlation for efficient video classification. IEEE Transactions on Circuits and Systems for Video Technology32(10), 7120–7132 (2022)
2022
-
[14]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
Hao, Y., Zhang, H., Ngo, C.W., He, X.: Group contextualization for video recog- nition. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 928–938 (2022)
2022
-
[15]
In: ECCV Workshop on Action Recognition with a Large Number of Classes (2014)
Idrees, H., Zamir, A.R., Jiang, Y.G., Gorban, A., Laptev, I., Sukthankar, R., Shah, M.: THUMOS challenge: Action recognition with a large number of classes. In: ECCV Workshop on Action Recognition with a Large Number of Classes (2014)
2014
-
[16]
arXiv preprint arXiv:2603.26586 (2026)
Li, K., Gu, J., Wang, F., Wu, Z., Fan, H., Guo, D.: MA-Bench: Towards fine-grained micro-action understanding. arXiv preprint arXiv:2603.26586 (2026)
arXiv 2026
-
[17]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, K., Guo, D., Chen, G., Fan, C., Xu, J., Wu, Z., Fan, H., Wang, M.: Prototypical calibrating ambiguous samples for micro-action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4815–4823 (2025)
2025
-
[18]
In: Proceedings of the 31st ACM International Conference on Multimedia
Li, K., Guo, D., Chen, G., Liu, F., Wang, M.: Data augmentation for human behavior analysis in multi-person conversations. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 9516–9520 (2023) 12 J. Liuet al
2023
-
[19]
arXiv preprint arXiv:2307.10624 (2023)
Li, K., Guo, D., Chen, G., Peng, X., Wang, M.: Joint skeletal and semantic embedding loss for micro-gesture classification. arXiv preprint arXiv:2307.10624 (2023)
arXiv 2023
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Li, K., Liu, P., Guo, D., Wang, F., Wu, Z., Fan, H., Wang, M.: MMAD: Multi-label micro-action detection in videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lin, C., Li, J., Wang, Y., Tai, Y., Luo, D., Cui, Z., Wang, C., Li, J., Huang, F., Ji, R.: Learning salient boundary feature for anchor-free temporal action localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3320–3329 (2021)
2021
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lin, T., Liu, X., Li, X., Ding, E., Wen, S.: Bmn: Boundary-matching network for tem- poral action proposal generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3889–3898 (2019)
2019
-
[23]
In: Proceedings of the IEEE International Conference on Computer Vision
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2980–2988 (2017)
2017
-
[24]
arXiv preprint arXiv:2503.15978 (2025)
Liu, P., Dong, G., Guo, D., Li, K., Li, F., Yang, X., Wang, M., Ying, X.: A survey on fmri-based brain decoding for reconstructing multimodal stimuli. arXiv preprint arXiv:2503.15978 (2025)
arXiv 2025
-
[25]
arXiv preprint arXiv:2507.09512 (2025)
Liu, P., Li, K., Wang, F., Wei, Y., She, J., Guo, D.: Online micro-gesture recog- nition using data augmentation and spatial-temporal attention. arXiv preprint arXiv:2507.09512 (2025)
arXiv 2025
-
[26]
In: Proceedings of the IJCAI 2024 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2024)
Liu, P., Wang, F., Li, K., Chen, G., Wei, Y., Tang, S., Wu, Z., Guo, D.: Micro-gesture online recognition using learnable query points. In: Proceedings of the IJCAI 2024 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2024). CEUR Workshop Proceedings, vol. 3848 (2024)
2024
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops
Liu, S., Zhao, C., Zohra, F., Soldan, M., Pardo, A., Xu, M., Alssum, L., Ra- mazanova, M., Alcázar, J.L., Cioppa, A., Giancola, S., Hinojosa, C., Ghanem, B.: OpenTAD: A unified framework and comprehensive study of temporal action detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp. 2650–2660 (2025)
2025
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, X., Shi, H., Chen, H., Yu, Z., Li, X., Zhao, G.: iMiGUE: An identity-free video dataset for micro-gesture understanding and emotion analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10631–10642 (2021)
2021
-
[29]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[30]
In: Proceedings of the IJCAI 2025 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2025) (2025)
Meng, C., Ma, F., Zhang, C., Miao, J., Yang, Y., Zhuang, Y.: Online micro-gesture recognition in long videos via spatiotemporal feature encoding and query-based temporal detection. In: Proceedings of the IJCAI 2025 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2025) (2025)
2025
-
[31]
MiGA Organizers: Miga: Micro-gesture analysis for hidden emotion understanding challenge.https://cv-ac.github.io/MiGA2/(2024), accessed: 2026-05-10
2024
-
[32]
Noroozi, F., Corneanu, C.A., Kaminska, D., Sapinski, T., Escalera, S., Anbarjafari, G.: Survey on emotional body gesture recognition. IEEE Transactions on Affective Computing12, 505–523 (2021).https://doi.org/10.1109/taffc.2018.2874986
-
[33]
Journal of Nonverbal Behavior48, 137–159 (2024)
Poppe, R., van der Zee, S., Taylor, P.J., Anderson, R.J., Veltkamp, R.C.: Mining bodily cues to deception. Journal of Nonverbal Behavior48, 137–159 (2024). https://doi.org/10.1007/s10919-023-00450-9 RGB-Skeleton Fusion for Micro-Gesture Recognition 13
-
[34]
In: Chinese Conference on Pattern Recognition and Computer Vision (PRCV)
Shang, T., Hao, Y., Pei, M., Li, K., Ben, H., Wang, S.: Cross-modal feature enhancement and contrastive alignment for micro-gesture recognition. In: Chinese Conference on Pattern Recognition and Computer Vision (PRCV). pp. 203–217. Springer (2025)
2025
-
[35]
arXiv preprint arXiv:2606.07355 (2026)
Shen, X., Li, K., Wang, F., Qian, W., Jiang, J., Guo, D.: Spatial-temporal decoupled adapter for micro-gesture online recognition. arXiv preprint arXiv:2606.07355 (2026)
Pith/arXiv arXiv 2026
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shi, D., Zhong, Y., Cao, Q., Ma, L., Li, J., Tao, D.: Tridet: Temporal action detection with relative boundary modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18857–18866 (2023)
2023
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shi, L., Zhang, Y., Cheng, J., Lu, H.: Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12026–12035 (2019)
2019
-
[38]
In: Advances in Neural Information Processing Systems
Tan, J., Zhao, X., Shi, X., Kang, B., Wang, L.: PointTAD: Multi-label temporal action detection with learnable query points. In: Advances in Neural Information Processing Systems. vol. 35 (2022)
2022
-
[39]
In: Advances in Neural Information Processing Systems
Tong, Z., Song, Y., Wang, J., Wang, L.: VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In: Advances in Neural Information Processing Systems. vol. 35, pp. 10078–10093 (2022)
2022
-
[40]
In: Proceedings of the IJCAI 2024 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2024)
Wang, Y., Linghu, K., Huang, H., Xia, Z.: Micro-gesture online recognition with dual-stream multi-scale transformer in long videos. In: Proceedings of the IJCAI 2024 Workshop on Micro-gesture Analysis for Hidden Emotion Understanding (MiGA 2024). CEUR Workshop Proceedings, vol. 3848 (2024)
2024
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, M., Zhao, C., Rojas, D.S., Thabet, A., Ghanem, B.: G-tad: Sub-graph localiza- tion for temporal action detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10156–10165 (2020)
2020
-
[42]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 32 (2018)
2018
-
[43]
In: Proceedings of the European Conference on Computer Vision (2024)
Yang, L., Zheng, Z., Han, Y., Cheng, H., Song, S., Huang, G., Li, F.: DyFADet: Dynamic feature aggregation for temporal action detection. In: Proceedings of the European Conference on Computer Vision (2024)
2024
-
[44]
In: Proceedings of the European Conference on Computer Vision
Zhang, C.L., Wu, J., Li, Y.: Actionformer: Localizing moments of actions with transformers. In: Proceedings of the European Conference on Computer Vision. pp. 492–510. Springer (2022)
2022
-
[45]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zheng, Z., Wang, P., Liu, W., Li, J., Ye, R., Ren, D.: Distance-IoU loss: Faster and better learning for bounding box regression. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 34, pp. 12993–13000 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.