IAPO: Input Attribution-Aware Policy Optimization for Tool Use in Small Multimodal Agents
Pith reviewed 2026-06-27 10:55 UTC · model grok-4.3
The pith
Aligning a small multimodal model's input attributions with a teacher's lets it learn effective tool use from sparse rewards where exact-match signals fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
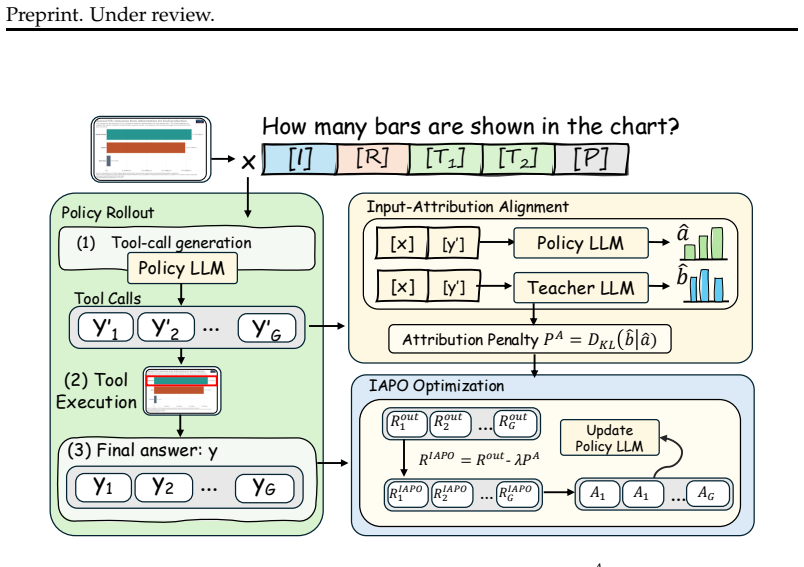
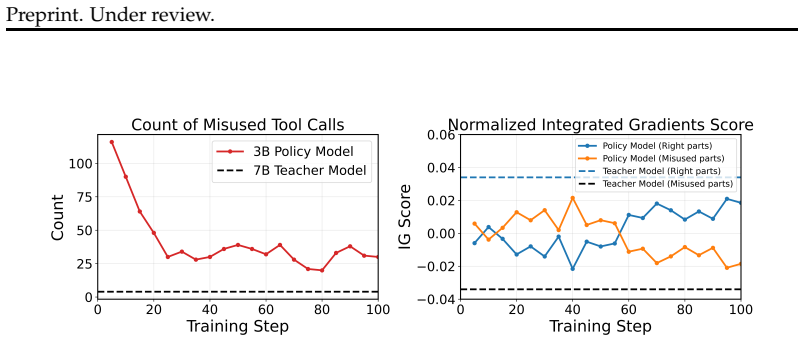
Input Attribution-Aware Policy Optimization improves tool-calling performance in small multimodal models by replacing brittle binary rewards with an objective that aligns the model's attribution scores over input tokens and image patches to those of a larger teacher, thereby directing the agent's attention toward the most relevant evidence even when ground-truth trajectories are absent and multiple valid tool paths exist.
What carries the argument
Input Attribution-Aware Policy Optimization (IAPO), the mechanism that adds an attribution-alignment term to the policy gradient so the student model's importance weights over multimodal inputs match a teacher's.
If this is right
- The method removes the need for annotated tool trajectories when training multimodal agents.
- Small models can improve decision quality by learning to focus on relevant input regions rather than relying solely on final-answer correctness.
- The approach scales to any multimodal task where a stronger model can supply attribution maps.
- Training becomes more stable because the reward signal is dense across input components instead of sparse at the trajectory level.
Where Pith is reading between the lines
- The same alignment idea could be tested on non-tool tasks such as multimodal reasoning chains where credit assignment is difficult.
- If teacher attributions are noisy, the student might inherit systematic biases in what it attends to.
- Combining attribution alignment with other dense signals such as process supervision might compound gains when both are available.
Load-bearing premise
Matching the student's attribution pattern to a teacher's pattern will produce useful learning signals for the underlying tool-selection decisions when multiple paths are valid.
What would settle it
A controlled experiment in which attribution alignment is added to the training objective but the resulting accuracy on the six visual QA test sets shows no gain or a loss relative to the same base model trained with standard sparse rewards.
Figures

read the original abstract
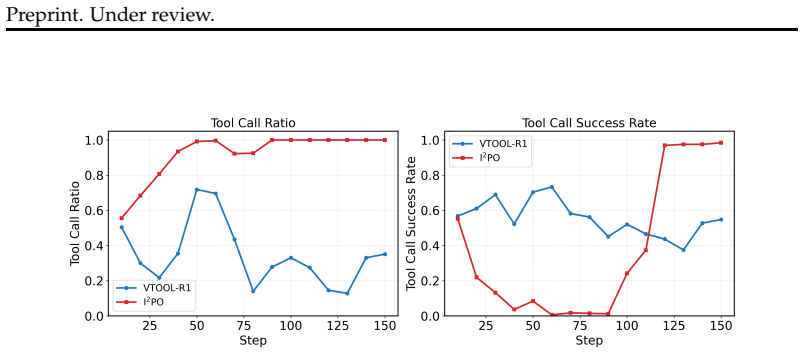
This paper investigates reinforcement learning (RL) methods for improving tool-calling capabilities in multimodal small language model (SLM) agents. While existing works have explored various reward designs to improve agentic tool-calling ability, these approaches face inherent limitations for SLM training, especially under multimodal scenarios. First, many existing methods evaluate tool use correctness through exact matching against certain ground-truth or predefined formats. However, this assumption is often unsuitable for multimodal tasks, where multiple tool use paths may be valid and annotated tool trajectories are typically unavailable. Second, such sparse and brittle binary rewards provide little guidance on how to improve the underlying decision process, making them particularly difficult for multimodal SLM to learn from. To address these issues, we propose Input Attribution-Aware Policy Optimization (IAPO), an RL algorithm for improving tool use in multimodal SLM by aligning the model's attribution across input components with that of a stronger teacher. Experiments on Qwen2.5-VL-3B show that the proposed method improves visual question answering accuracy by an average of 3% across six test sets compared with existing visual tool use work, by helping the model attend to the most relevant input evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Input Attribution-Aware Policy Optimization (IAPO), an RL algorithm for tool use in small multimodal SLM agents. It addresses limitations of sparse binary rewards and unavailable ground-truth trajectories in multimodal tasks by aligning the model's input attributions with those of a stronger teacher model, thereby providing denser signals for the decision process. Experiments on Qwen2.5-VL-3B report an average 3% VQA accuracy gain across six test sets relative to prior visual tool-use methods.
Significance. If the empirical gains are robust and the attribution alignment supplies effective learning signals under multiple valid tool-use paths, the method could meaningfully advance RL-based training of small multimodal agents without requiring dense annotations or exact-match rewards. The approach is a reasonable extension of attribution techniques to the RL setting for tool calling.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the central empirical claim of a 3% average accuracy improvement supplies no information on the baselines, number of runs, statistical significance tests, variance, or ablation studies isolating the attribution-alignment component; without these the contribution cannot be evaluated.
- [Method] Method section: the description of how input attributions are computed (e.g., gradient-based, attention rollout, or integrated gradients) and how the alignment objective is combined with the RL policy gradient is absent, leaving the precise training signal undefined.
- [Introduction / Experiments] The weakest assumption—that teacher attribution alignment supplies effective dense signals when multiple valid tool trajectories exist—is stated but not tested via controlled comparisons (e.g., random attribution targets or weaker teachers); this is load-bearing for the claimed advantage over sparse-reward baselines.
minor comments (1)
- [Method] Notation for the attribution alignment loss and the teacher model is introduced without a clear equation or pseudocode block.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below with clarifications and plans for revision where the feedback identifies gaps in the current presentation.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central empirical claim of a 3% average accuracy improvement supplies no information on the baselines, number of runs, statistical significance tests, variance, or ablation studies isolating the attribution-alignment component; without these the contribution cannot be evaluated.
Authors: We agree that the abstract and experiments section would benefit from greater transparency on the experimental protocol. The manuscript compares against prior visual tool-use methods as baselines, but does not report run counts, variance, or statistical tests. In the revised manuscript we will expand both the abstract and experiments section to include the number of runs, standard deviations, significance testing where appropriate, and an ablation isolating the attribution-alignment term. revision: yes
-
Referee: [Method] Method section: the description of how input attributions are computed (e.g., gradient-based, attention rollout, or integrated gradients) and how the alignment objective is combined with the RL policy gradient is absent, leaving the precise training signal undefined.
Authors: The referee correctly notes that the precise implementation details are not fully specified. The current text describes the high-level idea of attribution alignment but omits the exact attribution method and the combined loss. We will revise the Method section to state that attributions are obtained via integrated gradients and to provide the explicit objective that adds the attribution-alignment term to the policy-gradient loss. revision: yes
-
Referee: [Introduction / Experiments] The weakest assumption—that teacher attribution alignment supplies effective dense signals when multiple valid tool trajectories exist—is stated but not tested via controlled comparisons (e.g., random attribution targets or weaker teachers); this is load-bearing for the claimed advantage over sparse-reward baselines.
Authors: We acknowledge that direct controlled comparisons (e.g., random attribution targets) are absent and would strengthen the argument. Our existing results show gains relative to sparse-reward baselines, which indirectly supports the value of teacher-derived attributions. In revision we will add a dedicated discussion paragraph addressing the assumption and, space permitting, a limited ablation with weaker or randomized targets. Full new experiments are not feasible within the current revision cycle. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes IAPO as an RL algorithm that aligns the model's input attributions with those of an external stronger teacher model to supply dense learning signals for tool use when ground-truth trajectories are unavailable. This approach relies on an independent external teacher rather than any self-referential derivation, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or steps in the provided abstract reduce the central claim to its own inputs by construction; the reported 3% accuracy gain is framed as an experimental result on Qwen2.5-VL-3B across six test sets. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Aligning attribution with a stronger teacher supplies effective guidance for the decision process when exact-match rewards are unsuitable.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.01441 , year=
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2505.01441 , year=
-
[2]
arXiv preprint arXiv:2504.13958 , year=
ToolRL: Reward is All Tool Learning Needs , author=. arXiv preprint arXiv:2504.13958 , year=
-
[5]
arXiv preprint arXiv:2505.17612 , year=
Distilling LLM Agent into Small Models with Retrieval and Code Tools , author=. arXiv preprint arXiv:2505.17612 , year=
-
[6]
arXiv preprint arXiv:2505.13820 , year=
Structured Agent Distillation for Large Language Models , author=. arXiv preprint arXiv:2505.13820 , year=
-
[7]
arXiv preprint arXiv:2602.03955 , year=
AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent , author=. arXiv preprint arXiv:2602.03955 , year=
-
[8]
arXiv preprint arXiv:2504.14870 , year=
OTC: Optimal Tool Calls via Reinforcement Learning , author=. arXiv preprint arXiv:2504.14870 , year=
-
[9]
arXiv preprint arXiv:2504.11536 , year=
ReTool: Reinforcement Learning for Strategic Tool Use in Large Language Models , author=. arXiv preprint arXiv:2504.11536 , year=
-
[10]
arXiv preprint arXiv:2025.xxxxx , year=
ReCall: Learning to Reason with Tool Calls via Reinforcement Learning , author=. arXiv preprint arXiv:2025.xxxxx , year=
2025
-
[11]
arXiv preprint arXiv:2509.11963 , year=
ToolRM: Outcome Reward Models for Tool-Calling Large Language Models , author=. arXiv preprint arXiv:2509.11963 , year=
-
[12]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[13]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[14]
arXiv preprint arXiv:2502.14768 , year=
Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2502.14768 , year=
-
[15]
arXiv preprint arXiv:2509.08827 , year=
A survey of reinforcement learning for large reasoning models , author=. arXiv preprint arXiv:2509.08827 , year=
-
[16]
The Landscape of Agentic Reinforcement Learning for
Guibin Zhang and Hejia Geng and Xiaohang Yu and Zhenfei Yin and Zaibin Zhang and Zelin Tan and Heng Zhou and Zhong-Zhi Li and Xiangyuan Xue and Yijiang Li and Yifan Zhou and Yang Chen and Chen Zhang and Yutao Fan and Zihu Wang and Songtao Huang and Francisco Piedrahita Velez and Yue Liao and Hongru WANG and Mengyue Yang and Heng Ji and Jun Wang and Shuich...
2026
-
[17]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[18]
Agentic Reasoning and Tool Integration for
Joykirat Singh and Yash Pandya and Pranav Vajreshwari and Raghav Magazine and Akshay Nambi , booktitle=. Agentic Reasoning and Tool Integration for. 2025 , url=
2025
-
[19]
Cheng Qian and Emre Can Acikgoz and Qi He and Hongru WANG and Xiusi Chen and Dilek Hakkani-T. Tool. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[20]
2026 , url=
Mingyuan Wu and Jingcheng Yang and Jize Jiang and Meitang Li and Kaizhuo Yan and Hanchao Yu and Minjia Zhang and ChengXiang Zhai and Klara Nahrstedt , booktitle=. 2026 , url=
2026
-
[21]
arXiv preprint arXiv:2505.08617 , year=
Openthinkimg: Learning to think with images via visual tool reinforcement learning , author=. arXiv preprint arXiv:2505.08617 , year=
-
[22]
Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
StepTool: Enhancing Multi-Step Tool Usage in LLMs via Step-Grained Reinforcement Learning , author=. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
-
[23]
arXiv preprint arXiv:2505.11821 , year=
Reinforcing multi-turn reasoning in llm agents via turn-level reward design , author=. arXiv preprint arXiv:2505.11821 , year=
-
[24]
Deepeyes: Incentivizing" thinking with images" via reinforcement learning , author=. arXiv preprint arXiv:2505.14362 , year=
-
[25]
International conference on machine learning , pages=
Axiomatic attribution for deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[26]
NIPS Workshop on Interpreting, Explaining and Visualizing Deep Learning-Now What?(NIPS 2017) , year=
A unified view of gradient-based attribution methods for Deep Neural Networks , author=. NIPS Workshop on Interpreting, Explaining and Visualizing Deep Learning-Now What?(NIPS 2017) , year=
2017
-
[27]
The Fourteenth International Conference on Learning Representations , year=
Empowering LLM Tool Invocation with Tool-call Reward Model , author=. The Fourteenth International Conference on Learning Representations , year=
-
[28]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[29]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[30]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[31]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
ReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[32]
Advances in Neural Information Processing Systems , volume =
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs , author =. Advances in Neural Information Processing Systems , volume =
-
[33]
Findings of the Association for Computational Linguistics: ACL 2022 , pages =
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning , author =. Findings of the Association for Computational Linguistics: ACL 2022 , pages =
2022
-
[34]
arXiv preprint arXiv:2404.19205 , year =
TableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains , author =. arXiv preprint arXiv:2404.19205 , year =
-
[35]
Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Compositional Semantic Parsing on Semi-Structured Tables , author =. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[36]
International Conference on Learning Representations (ICLR) , year =
TabFact: A Large-scale Dataset for Table-based Fact Verification , author =. International Conference on Learning Representations (ICLR) , year =
-
[37]
International Conference on Learning Representations (ICLR) , year =
VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use , author =. International Conference on Learning Representations (ICLR) , year =
-
[38]
arXiv preprint arXiv:2503.23383 , year =
ToRL: Scaling Tool-Integrated RL , author =. arXiv preprint arXiv:2503.23383 , year =
-
[39]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[40]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[41]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Attribution explanations for deep neural networks: A theoretical perspective , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[42]
arXiv preprint arXiv:2506.02153 , year=
Small language models are the future of agentic ai , author=. arXiv preprint arXiv:2506.02153 , year=
-
[43]
arXiv preprint arXiv:2601.22511 , year=
Mock Worlds, Real Skills: Building Small Agentic Language Models with Synthetic Tasks, Simulated Environments, and Rubric-Based Rewards , author=. arXiv preprint arXiv:2601.22511 , year=
-
[44]
International journal of computer vision , volume=
Knowledge distillation: A survey , author=. International journal of computer vision , volume=. 2021 , publisher=
2021
-
[45]
Advances in Neural Information Processing Systems , volume=
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
arXiv preprint arXiv:2505.07773 , year=
Agent rl scaling law: Agent rl with spontaneous code execution for mathematical problem solving , author=. arXiv preprint arXiv:2505.07773 , year=
-
[47]
arXiv preprint arXiv:2504.07615 , year=
Vlm-r1: A stable and generalizable r1-style large vision-language model , author=. arXiv preprint arXiv:2504.07615 , year=
-
[48]
arXiv preprint arXiv:2503.06749 , year=
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.