The Long Tail, Not the Front Page: Cold-Start Prediction of Crowd Highlight Salience
Pith reviewed 2026-06-27 08:28 UTC · model grok-4.3
The pith
A trained logistic ranker predicts crowd highlight locations from text better than the lead baseline before any marks accumulate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
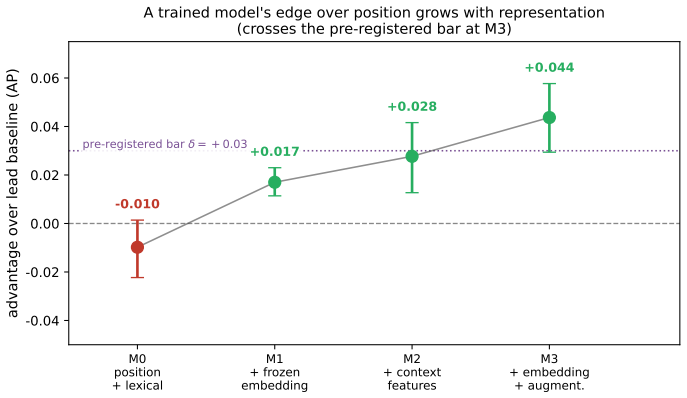
The authors establish that a logistic ranker over sentence embeddings and positional/contextual features, trained on a highlight corpus, beats the lead baseline by 0.044 average precision in a retrospective simulation of cold-start prediction, with the edge attributable to the embeddings and training, and stronger on lower-popularity content.
What carries the argument
Logistic ranker combining sentence embeddings with positional and contextual features to score sentences for highlight likelihood.
If this is right
- Precision at 3 rises from 0.25 to 0.39.
- The model outperforms the lead baseline on 69 percent of documents.
- The performance edge derives mainly from the raw sentence embeddings and training augmentation.
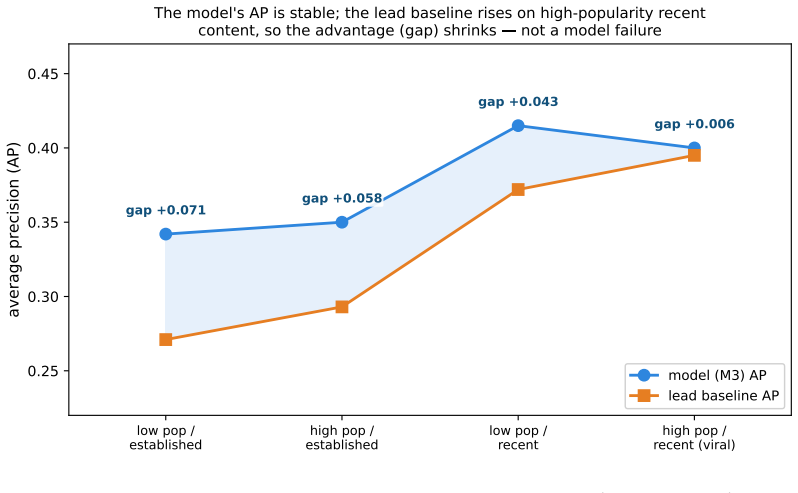
- The advantage is governed by document popularity, nearly vanishing only on the most popular content.
- Two unsupervised extractive baselines lose to the lead baseline.
Where Pith is reading between the lines
- Highlight prediction models could be deployed at publication time to guide initial reader attention.
- Patterns in reader marks reflect learnable textual properties beyond simple position.
- Similar approaches might predict other crowd behaviors like comments or shares from text.
- Further tests on documents that never accumulate marks would strengthen the cold-start claim.
Load-bearing premise
That evaluating on documents which later receive readers accurately simulates prediction for documents with no marks yet.
What would settle it
A prospective evaluation on newly published documents before any marks appear, checking if the model's advantage persists.
Figures
read the original abstract
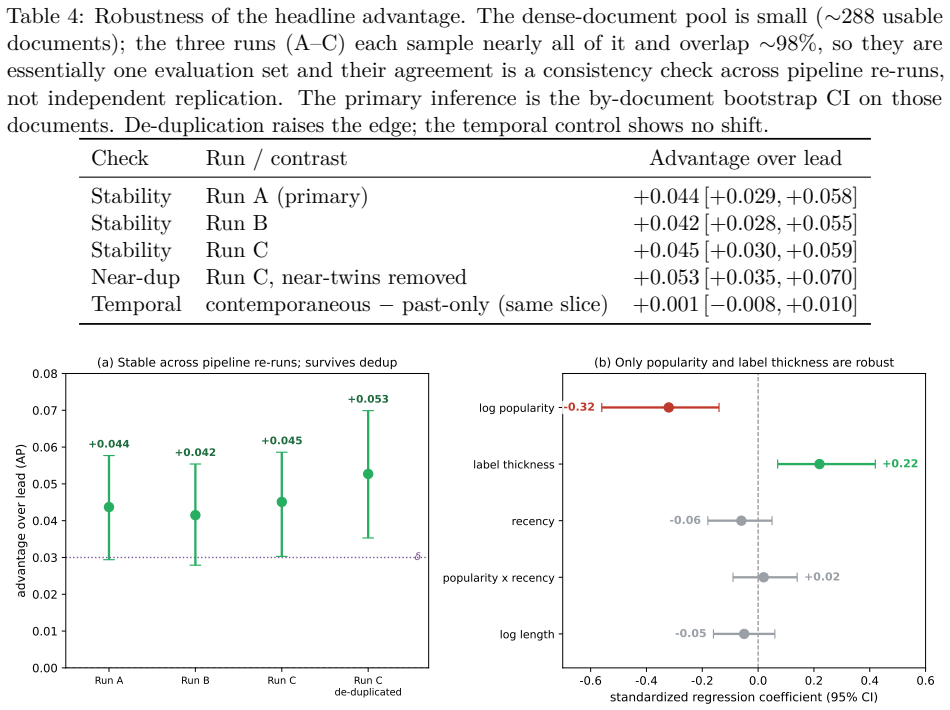
A social highlighter's most useful signal -- which passages a crowd of readers marks -- exists only for documents people have already read. Can the aggregate crowd salience of a document be predicted from its text before its marks accumulate? Prior work on this data found that zero-shot language models recover highlight locations worse than a trivial lead (position) baseline, so we ask whether a model trained on the highlight corpus can beat that baseline. Using a pre-registered ladder of models and a by-document cluster bootstrap, we find a small but robust edge: a logistic ranker over sentence embeddings and positional/contextual features beats the lead baseline by +0.044 average precision (95% CI [+0.029, +0.058]; clears a pre-registered margin delta=0.03 in 97% of resamples, and stable across pipeline re-runs). Two unsupervised extractive baselines (centroid, LexRank-style centrality) lose to lead, and the trained model beats them by +0.108, so the edge is not recovered by generic unsupervised proxies -- it reflects learning from real reader marks. In product terms, precision@3 rises from 0.25 to 0.39 (+55% relative) and the model beats lead on 69% of documents. An ablation attributes the edge to the raw embedding (+0.014) and training augmentation (+0.010), each with a positive CI. The edge is not a temporal-generalization failure, and we find no evidence that content drift or near-duplicate leakage explains it. A standardized regression shows the advantage is governed mainly by document popularity (lower popularity, larger edge) and by label reliability. It nearly vanishes only on the most popular content; there it is the lead baseline that strengthens, not the model that weakens. Because our evaluation conditions on documents that eventually accumulated readers, these results are a retrospective cold-start simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a logistic ranker trained on sentence embeddings plus positional and contextual features outperforms a lead (position) baseline by +0.044 average precision (95% CI [+0.029, +0.058]) when predicting crowd-sourced highlight locations on held-out documents. The evaluation uses a pre-registered ladder of models, by-document cluster bootstrap, ablations, leakage/drift checks, and reports that the edge clears a pre-registered delta=0.03 margin in 97% of resamples, is stable across re-runs, and is larger on lower-popularity documents. Unsupervised extractive baselines (centroid, LexRank) underperform the lead baseline, and the trained model beats them by +0.108. The setup is explicitly described as a retrospective cold-start simulation conditioned on documents that eventually accumulate marks.
Significance. If the reported edge holds under the stated conditions, the result shows that supervised learning from past highlight data can extract non-trivial, non-positional signals for salience prediction that generic unsupervised methods do not recover. The pre-registered design, bootstrap CIs, ablation attribution (+0.014 from embeddings, +0.010 from augmentation), and explicit stability/leakage checks are strengths that increase credibility of the modest effect size. Practical gains (P@3 from 0.25 to 0.39) are noted. The retrospective conditioning, however, restricts direct claims about true cold-start regimes for documents that never receive marks.
major comments (1)
- [Abstract] Abstract: The evaluation conditions on documents that eventually accumulated readers and treats this as a 'retrospective cold-start simulation.' This selection criterion is load-bearing for the cold-start claim because documents that never receive marks could differ systematically in content, style, or salience distribution; the model could therefore be capturing popularity-correlated signals rather than pure text-based highlight prediction. No direct test on a zero-mark hold-out set is reported, and the paper notes the edge grows on lower-popularity documents but provides no external validation of the proxy.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the scope of the cold-start claim. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The evaluation conditions on documents that eventually accumulated readers and treats this as a 'retrospective cold-start simulation.' This selection criterion is load-bearing for the cold-start claim because documents that never receive marks could differ systematically in content, style, or salience distribution; the model could therefore be capturing popularity-correlated signals rather than pure text-based highlight prediction. No direct test on a zero-mark hold-out set is reported, and the paper notes the edge grows on lower-popularity documents but provides no external validation of the proxy.
Authors: We agree that conditioning on documents that eventually receive marks is a substantive limitation for any claim of true prospective cold-start prediction on never-highlighted documents. The manuscript already states this explicitly in the abstract and in Section 4, labeling the setup a 'retrospective cold-start simulation' precisely to avoid overclaiming. A direct evaluation on a zero-mark hold-out set is not feasible because no crowd-sourced highlight labels exist for such documents, so no ground-truth salience signal is available. The reported regression (Section 5) does show that the model's advantage increases as document popularity decreases, which supplies internal evidence that the learned signal is not driven solely by high-popularity content; however, we acknowledge that this remains an internal proxy and that external validation on an independent corpus of never-marked documents would be a valuable extension. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper trains a logistic ranker on historical crowd highlights to predict highlight salience on held-out documents, then compares performance to an independent position-based lead baseline and unsupervised extractive methods. The reported +0.044 AP edge is obtained via standard cross-document evaluation and bootstrap statistics; it does not reduce by the paper's own equations to any fitted parameter or self-referential quantity. The setup is explicitly labeled a retrospective simulation conditioned on documents that eventually received marks, with no self-citation load-bearing the central claim and no ansatz or uniqueness theorem imported from prior author work. The derivation chain is therefore self-contained against the external lead baseline.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Trait, Not State: The Durability of Reading Identity in Social Highlighting
Readers' highlighting patterns on a social web platform remain stable over 24 months as a durable trait, with personal profiles from early documents predicting future selections at roughly 3x the average precision of ...
Reference graph
Works this paper leans on
-
[1]
K. Nakayashiki and K. Watanabe. Personal Salience: Highlighting Is Social, but Individuality Lives in Selection. arXiv:2606.09024, 2026
Pith/arXiv arXiv 2026
-
[2]
K. Nakayashiki and K. Watanabe. Selection, Not Salience: The Shape and Limits of Personalization in Social Highlighting. arXiv:2606.10398, 2026
Pith/arXiv arXiv 2026
-
[3]
K. Nakayashiki and K. Watanabe. Factions Within, Uncertain Across: Within-Document Reader Sub-Groups in Social Highlighting. arXiv:2606.11613, 2026
Pith/arXiv arXiv 2026
-
[4]
K. Watanabe and K. Nakayashiki. Disentangling Answer Engine Optimization from Platform Growth. arXiv:2606.04362, 2026
Pith/arXiv arXiv 2026
-
[5]
J. S. Park et al. Generative Agent Simulations of 1,000 People. arXiv:2411.10109, 2024
Pith/arXiv arXiv 2024
-
[6]
Schoenegger et al
P. Schoenegger et al. Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy. Science Advances, 2024. 9
2024
-
[7]
Trienes et al
J. Trienes et al. Behavioral Analysis of Information Salience in Large Language Models. Findings of ACL, 2025
2025
-
[8]
Krichene and S
W. Krichene and S. Rendle. On Sampled Metrics for Item Recommendation. KDD, 2020
2020
-
[9]
Y. Ji, A. Sun, J. Zhang, and C. Li. A Re-visit of the Popularity Baseline in Recommender Systems. SIGIR, 2020
2020
-
[10]
Winchell et al
A. Winchell et al. Highlights as an Early Predictor of Student Comprehension and Interests. Cognitive Science, 2020
2020
-
[11]
Danescu-Niculescu-Mizil, J
C. Danescu-Niculescu-Mizil, J. Cheng, J. Kleinberg, and L. Lee. You Had Me at Hello: How Phrasing Affects Memorability. ACL, 2012
2012
-
[12]
Bohn and C
T. Bohn and C. X. Ling. Catching Attention with Automatic Pull Quote Selection. COLING, 2020. 10
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.