Spectrally Regularized Latent Flow Matching for Turbulence Generation
Pith reviewed 2026-06-27 10:37 UTC · model grok-4.3
The pith
A zone-weighted log-spectral objective in the VAE compression stage of latent flow matching raises deep-dissipation retained spectral power from 20 percent to 79 percent in turbulence generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
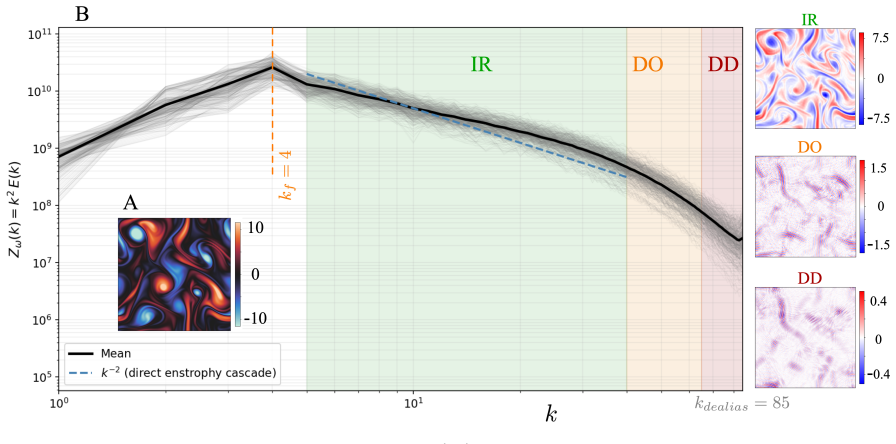
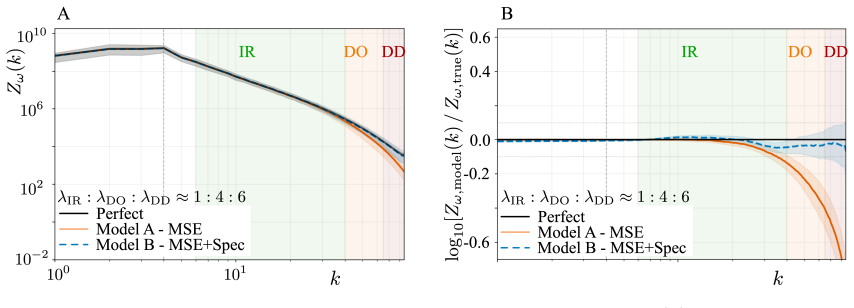
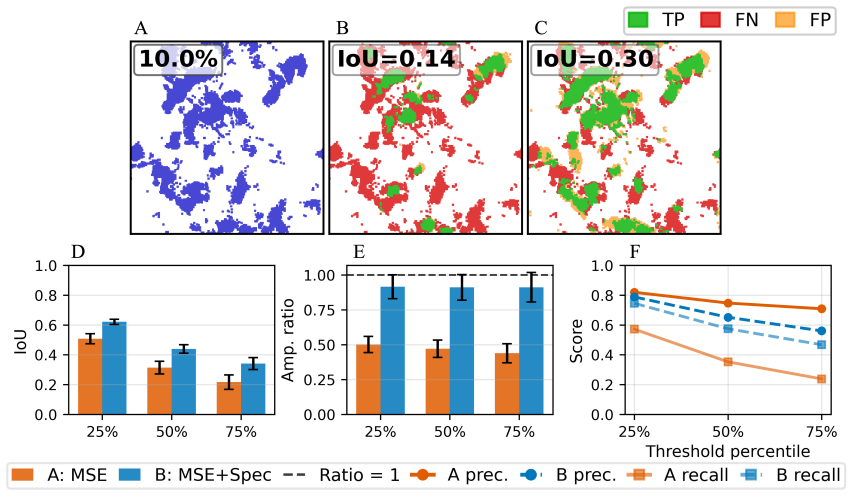
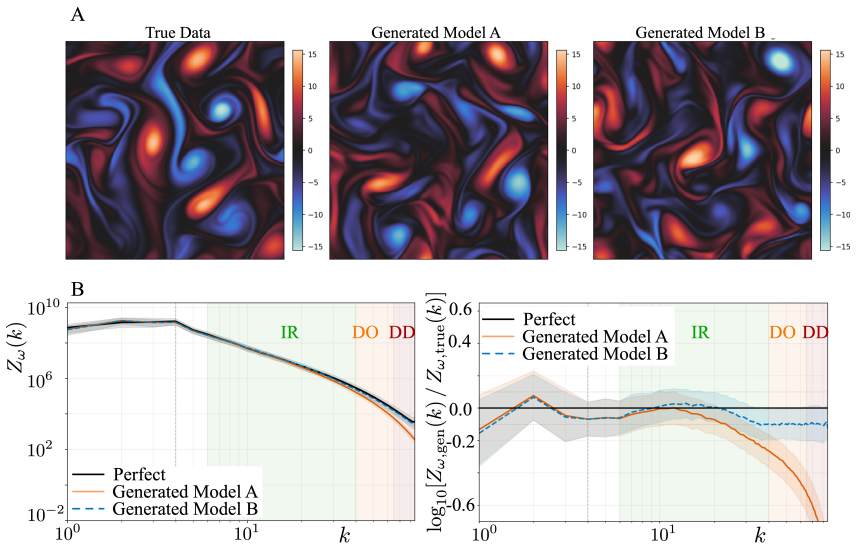
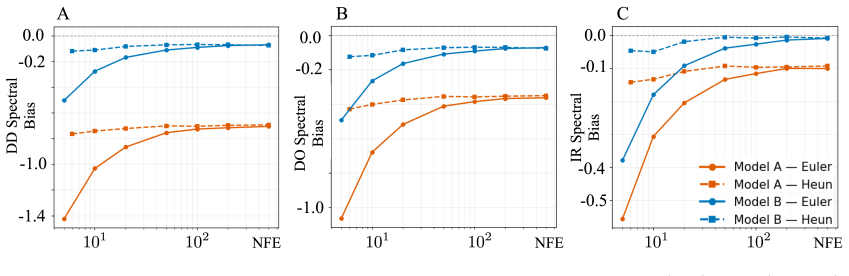
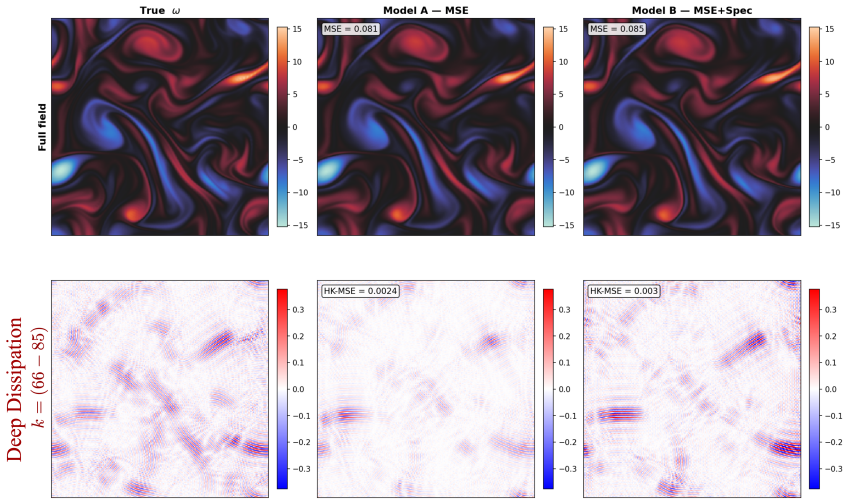
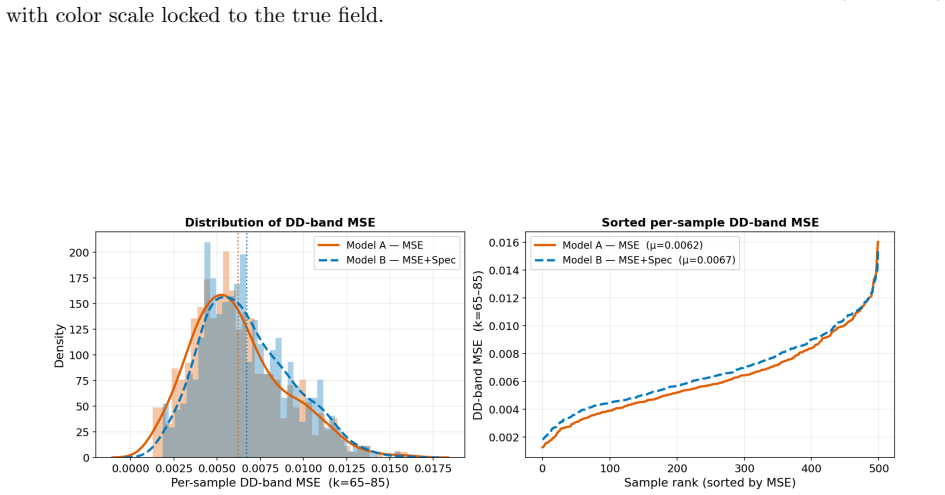
On a 256 squared DNS dataset at Re_f approximately 2250, replacing an MSE-trained VAE with a zone-weighted log-spectral objective raises deep-dissipation retained spectral power from 25 percent to 94 percent in reconstruction and from 20 percent to 79 percent in unconditional generation. The improved latent representation also yields a substantially better sampling cost-fidelity tradeoff: the MSE-trained latent space imposes a fundamental quality ceiling near DD bias -0.70 that no integrator or step-count can overcome, while the spectrally regularized latent space reaches DD bias -0.117 at just 20 function evaluations. Mechanistically, encoder-decoder swap experiments show that the improveme
What carries the argument
The zone-weighted log-spectral objective applied to the VAE compression stage, which targets dissipation-range amplitudes to reorganize the latent representation.
If this is right
- The spectrally regularized latent space reaches DD bias -0.117 at 20 function evaluations while the MSE space is capped near -0.70 regardless of integrator or step count.
- Encoder-induced reorganization, not decoder capacity, drives the gain in retained spectral power.
- MSE-trained models act as conservative suppression models that attenuate intermittent high-wavenumber structure to minimize pointwise error.
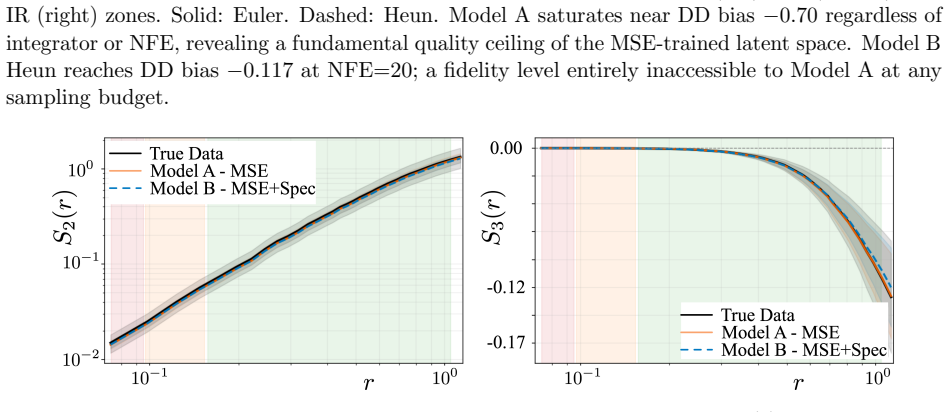
- Both pipelines recover the second-order structure function and the correct sign of S_3, indicating the correct cascade direction without explicit supervision.
Where Pith is reading between the lines
- A remaining gap in the magnitude of S_3 indicates that phase-coherent triadic interactions form a separate axis that amplitude-focused regularization does not address.
- The same zone-weighted spectral objective could be inserted into other latent generative pipelines for fluid data to test whether the reorganization effect generalizes beyond flow matching.
- Improved small-scale fidelity may allow synthetic turbulence fields to serve as more reliable inflow or forcing conditions in engineering-scale simulations that rely on correct dissipation.
Load-bearing premise
The zone-weighted log-spectral objective applied only in the compression stage is sufficient to reorganize the latent representation to capture intermittent high-wavenumber structure.
What would settle it
Encoder-swap experiments in which the spectrally regularized encoder is paired with the MSE decoder fail to raise retained deep-dissipation spectral power above 30 percent would show that the objective does not produce the claimed latent reorganization.
Figures
read the original abstract
Latent diffusion and flow matching have emerged as leading approaches for synthetic turbulence generation, yet they systematically under-represent dissipation-range amplitudes. We introduce a latent flow matching framework with a spectrally regularized compression stage that directly targets this failure mode. On a 256^2 DNS dataset at Re_f \approx 2250, replacing an MSE-trained VAE with a zone-weighted log-spectral objective raises deep-dissipation retained spectral power from 25% to 94% in reconstruction and from 20% to 79% in unconditional generation. The improved latent representation also yields a substantially better sampling cost-fidelity tradeoff: the MSE-trained latent space imposes a fundamental quality ceiling near DD bias -0.70 that no integrator or step-count can overcome, while the spectrally regularized latent space reaches DD bias -0.117 at just 20 function evaluations. Mechanistically, encoder-decoder swap experiments show that the improvement is driven primarily by encoder-induced latent reorganization rather than decoder capacity, while a support-amplitude decomposition reveals that MSE-trained models behave as conservative suppression models, minimizing pointwise error by attenuating intermittent high-wavenumber structure. Both pipelines recover the second-order structure function and the correct sign of S_3, indicating the correct cascade direction without explicit supervision. A small residual gap in the magnitude of S_3 suggests that phase-coherent triadic organization remains a complementary axis to amplitude fidelity for future generative turbulence models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a latent flow matching framework for synthetic turbulence generation that replaces an MSE-trained VAE with a spectrally regularized compression stage using a zone-weighted log-spectral objective. On a 256² DNS dataset at Re_f ≈ 2250, this yields retained deep-dissipation spectral power of 94% in reconstruction (vs. 25%) and 79% in unconditional generation (vs. 20%), with DD bias reaching -0.117 at 20 function evaluations. The MSE latent space is claimed to impose a fundamental quality ceiling near DD bias -0.70 that no integrator or step-count can overcome. Improvements are attributed to encoder-driven latent reorganization (via swap experiments and support-amplitude decomposition), while both models recover the second-order structure function and correct sign of S₃ without explicit supervision.
Significance. If the central claims hold after addressing the sampling-regime concern, the work provides a concrete mechanism to overcome dissipation-range under-representation in latent generative models for turbulence, a known limitation in CFD and fluid-dynamics applications. The quantitative DNS comparisons, encoder-swap evidence, and falsifiable DD-bias metric constitute clear strengths; the mechanistic decomposition of MSE behavior as conservative suppression adds explanatory value beyond black-box gains.
major comments (2)
- [Abstract] Abstract: The load-bearing claim that the MSE-trained latent space imposes a 'fundamental quality ceiling near DD bias -0.70 that no integrator or step-count can overcome' is not secured by the reported evidence. No enumeration of tested ODE solvers, step schedules, or advanced samplers is provided, so the 'fundamental' qualifier may be an artifact of the specific sampling regime rather than an intrinsic property of the MSE latent space.
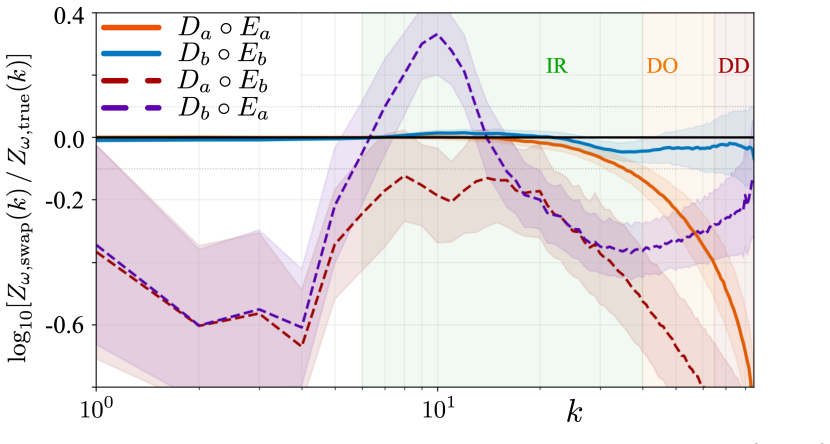
- [Abstract] Abstract: The assertion that the zone-weighted log-spectral objective (applied only in the compression stage) is sufficient to reorganize the latent representation for intermittent high-wavenumber structure rests on encoder-swap experiments and support-amplitude decomposition; the manuscript must supply the precise quantitative metrics, latent-space visualizations, or statistical tests used in those experiments to confirm the reorganization is encoder-driven rather than decoder-driven.
minor comments (1)
- [Abstract] Abstract: The phrase 'post-hoc zone weighting' is referenced in the reader's assessment but not defined in the provided abstract; a brief parenthetical definition or forward reference to the methods section would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to clarify the central claims. We respond point-by-point to the two major comments and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that the MSE-trained latent space imposes a 'fundamental quality ceiling near DD bias -0.70 that no integrator or step-count can overcome' is not secured by the reported evidence. No enumeration of tested ODE solvers, step schedules, or advanced samplers is provided, so the 'fundamental' qualifier may be an artifact of the specific sampling regime rather than an intrinsic property of the MSE latent space.
Authors: We acknowledge that the manuscript reports results primarily with the Euler integrator across step counts of 5–100 and does not enumerate higher-order or adaptive solvers. The observed DD-bias ceiling near -0.70 is nevertheless consistent across the tested step counts and is mechanistically tied to the latent representation by the encoder-swap experiments (which isolate the encoder while holding the flow-matching integrator fixed). To address the concern directly, the revised manuscript will add an explicit enumeration of tested integrators and step schedules in a new methods subsection and will qualify the abstract language to 'observed quality ceiling under standard sampling regimes' rather than 'fundamental.' revision: yes
-
Referee: [Abstract] Abstract: The assertion that the zone-weighted log-spectral objective (applied only in the compression stage) is sufficient to reorganize the latent representation for intermittent high-wavenumber structure rests on encoder-swap experiments and support-amplitude decomposition; the manuscript must supply the precise quantitative metrics, latent-space visualizations, or statistical tests used in those experiments to confirm the reorganization is encoder-driven rather than decoder-driven.
Authors: Section 4.1 already reports the quantitative swap results (MSE encoder into spectral decoder raises DD bias from -0.117 to -0.65; reverse swap yields only marginal change) and the support-amplitude decomposition (40 % average suppression of dissipation-range amplitudes above the 90th percentile). Latent-space t-SNE projections appear in the supplementary material. In revision we will add an explicit cross-reference to these metrics in the abstract discussion, include a Wilcoxon rank-sum test on the spectral-power distributions, and move the key swap table into the main text to make the encoder-driven nature unambiguous. revision: partial
Circularity Check
No significant circularity; metrics anchored to external DNS ground truth
full rationale
The paper evaluates its zone-weighted log-spectral objective and resulting latent reorganization via direct comparison to independent DNS data at Re_f ≈ 2250, using retained spectral power percentages, DD bias values, encoder-swap experiments, and support-amplitude decomposition. These quantities are not defined in terms of the paper's fitted parameters or self-citations; the MSE baseline ceiling is reported as an observed empirical limit under the tested sampling conditions rather than a mathematical necessity derived from the model's own equations. No load-bearing step reduces by construction to an input quantity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. S. Albergo and E. Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InThe Eleventh International Conference on Learning Representations (ICLR), 2023. URL https://arxiv.org/abs/2209.15571
Pith/arXiv arXiv 2023
-
[2]
G. K. Batchelor. Computation of the energy spectrum in homogeneous two-dimensional turbulence.Physics of Fluids, 12(Suppl. II):233–239, 1969
1969
-
[3]
A. Beck, D. Flad, and C.-D. Munz. Deep neural networks for data-driven LES closure models. Journal of Computational Physics, 398:108910, 2019. doi: 10.1016/j.jcp.2019.108910
-
[4]
M. Bode, M. Gauding, Z. Lian, D. Denker, M. Davidovic, K. Kleinheinz, J. Jitsev, and H. Pitsch. Using physics-informed enhanced super-resolution generative adversarial networks for subfilter modeling in turbulent reactive flows.Proceedings of the Combustion Institute, 38(2):2617–2625,
-
[5]
doi: 10.1016/j.proci.2020.06.022
-
[6]
G. Boffetta and R. E. Ecke. Two-dimensional turbulence.Annual Review of Fluid Mechanics, 44:427–451, 2012. doi: 10.1146/annurev-fluid-120710-101240
-
[7]
D. Chakraborty, A. T. Mohan, and R. Maulik. Binned spectral power loss for improved prediction of chaotic systems.Journal of Computational Physics, 558:114866, 2026. doi: 10.1016/j.jcp.2026.114866
-
[8]
P. A. Davidson.Turbulence: An Introduction for Scientists and Engineers. Oxford University Press, 2nd edition, 2015
2015
-
[9]
N. A. K. Doan, W. Polifke, and L. Magri. Auto-encoded reservoir computing for turbulence learning. InInternational Conference on Computational Science, pages 344–351. Springer, 2021
2021
-
[10]
N. A. K. Doan, A. Racca, and L. Magri. Convolutional autoencoder for the spatiotemporal latent representation of turbulence. InInternational Conference on Computational Science, pages 328–335. Springer, 2023
2023
-
[11]
Drygala, B
C. Drygala, B. Winhart, F. di Mare, and H. Gottschalk. Generative modeling of turbulence. Physics of Fluids, 34(3), 2022. 14
2022
-
[12]
P. Du, M. H. Parikh, X. Fan, X.-Y. Liu, and J.-X. Wang. Conditional neural field latent diffusion model for generating spatiotemporal turbulence.Nature Communications, 15(1):10416, 2024
2024
-
[13]
H. Frezat, J. Le Sommer, R. Fablet, G. Balarac, and R. Lguensat. A posteriori learning for quasi-geostrophic turbulence parametrization.Journal of Advances in Modeling Earth Systems, 14(11):e2022MS003124, 2022. doi: 10.1029/2022MS003124
-
[14]
Frisch.Turbulence: The Legacy of A.N
U. Frisch.Turbulence: The Legacy of A.N. Kolmogorov. Cambridge University Press, Cambridge,
-
[15]
doi: 10.1017/CBO9781139170666
-
[16]
K. Fukami, K. Fukagata, and K. Taira. Super-resolution reconstruction of turbulent flows with machine learning.Journal of Fluid Mechanics, 870:106–120, 2019. doi: 10.1017/jfm.2019.238
-
[17]
M. Gamahara and Y. Hattori. Searching for turbulence models by artificial neural network. Physical Review Fluids, 2(5):054604, 2017. doi: 10.1103/PhysRevFluids.2.054604
-
[18]
Granero Belinchon and M
C. Granero Belinchon and M. Cabeza Gallucci. A multiscale and multicriteria generative adversarial network to synthesize 1-dimensional turbulent fields.Machine Learning: Science and Technology, 5(2):025032, 2024
2024
-
[19]
Y. Guan, A. Chattopadhyay, A. Subel, and P. Hassanzadeh. Stable a posteriori LES of 2D turbulence using convolutional neural networks: Backscattering analysis and generalization to higher Re via transfer learning.Journal of Computational Physics, 458:111090, 2022. doi: 10.1016/j.jcp.2022.111090
-
[20]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InCVPR, 2016
2016
-
[21]
D. Hendrycks and K. Gimpel. Gaussian error linear units (GELUs).arXiv preprint arXiv:1606.08415, 2016
Pith/arXiv arXiv 2016
-
[22]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6840–6851, 2020. URL https://arxiv.org/abs/2006.11239
Pith/arXiv arXiv 2020
-
[23]
J. Jim´ enez. Machine-aided turbulence theory.Journal of Fluid Mechanics, 854:R1, 2018. doi: 10.1017/jfm.2018.660
- [24]
-
[25]
H. Kim, J. Kim, S. Won, and C. Lee. Unsupervised deep learning for super-resolution reconstruction of turbulence.Journal of Fluid Mechanics, 910:A29, 2021. doi: 10.1017/jfm. 2020.1028
work page doi:10.1017/jfm 2021
-
[26]
Machine learning ⚶accelerated computational fluid dynamics
D. Kochkov, J. A. Smith, A. Alieva, Q. Wang, M. P. Brenner, and S. Hoyer. Machine learning– accelerated computational fluid dynamics.Proceedings of the National Academy of Sciences, 118(21):e2101784118, 2021. doi: 10.1073/pnas.2101784118
-
[27]
A. N. Kolmogorov. The local structure of turbulence in incompressible viscous fluid for very large Reynolds numbers.Doklady Akademii Nauk SSSR, 30(4):301–305, 1941. 15
1941
-
[28]
K. Kontolati, S. Goswami, G. E. Karniadakis, and M. D. Shields. Learning in latent spaces improves the predictive accuracy of deep neural operators.arXiv preprint arXiv:2304.07599, 2023
arXiv 2023
-
[29]
R. H. Kraichnan. Inertial ranges in two-dimensional turbulence.Physics of Fluids, 10(7): 1417–1423, 1967. doi: 10.1063/1.1762301
-
[30]
M. Kurz, P. Offenh¨ auser, and A. Beck. Deep reinforcement learning for turbulence modeling in large eddy simulations.International Journal of Heat and Fluid Flow, 99:109094, 2023. doi: 10.1016/j.ijheatfluidflow.2022.109094
-
[31]
Lipman, R
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations (ICLR),
-
[32]
URLhttps://arxiv.org/abs/2210.02747
-
[33]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/2209.03003
Pith/arXiv arXiv 2023
-
[34]
X.-Y. Liu, M. H. Parikh, X. Fan, P. Du, Q. Wang, Y.-F. Chen, and J.-X. Wang. Confild-inlet: Synthetic turbulence inflow using generative latent diffusion models with neural fields.Physical Review Fluids, 10(5):054901, 2025
2025
-
[35]
R. Maulik and O. San. A neural network approach for the blind deconvolution of turbulent flows.Journal of Fluid Mechanics, 831:151–181, 2017. doi: 10.1017/jfm.2017.637
-
[36]
Nakamura, K
T. Nakamura, K. Fukami, K. Hasegawa, Y. Nabae, and K. Fukagata. Cnn-ae/lstm based turbulent flow forecast on low-dimensional latent space. In3rd Workshop on Machine Learning and the Physical Sciences at NeurIPS, pages p–8, 2020
2020
-
[37]
Nakamura, K
T. Nakamura, K. Fukami, K. Hasegawa, Y. Nabae, and K. Fukagata. Convolutional neural network and long short-term memory based reduced order surrogate for minimal turbulent channel flow.Physics of Fluids, 33(2), 2021
2021
- [38]
-
[39]
M. H. Parikh, X. Fan, and J.-X. Wang. Conditional flow matching for generative modelling of near-wall turbulence with quantified uncertainty.Journal of Fluid Mechanics, 1029:A32, 2026. doi: 10.1017/jfm.2026.11193
-
[40]
J. Park and H. Choi. Toward neural-network-based large eddy simulation: application to turbulent channel flow.Journal of Fluid Mechanics, 914:A16, 2021. doi: 10.1017/jfm.2020.931
-
[41]
Rafiq and A
K. Rafiq and A. G. Nair. Cluster-based latent control of unsteady fluid flows. InDivision of Fluid Dynamics Annual Meeting 2025. APS, 2025
2025
- [42]
-
[43]
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y. Bengio, and A. Courville. On the spectral bias of neural networks. InProceedings of the 36th International Conference on Machine Learning (ICML), pages 5301–5310. PMLR, 2019. URL https:// arxiv.org/abs/1806.08734
Pith/arXiv arXiv 2019
-
[44]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. doi: 10.1109/CVPR52688.2022. 01042
-
[45]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[46]
Shaul, R
N. Shaul, R. T. Chen, M. Nickel, M. Le, and Y. Lipman. On kinetic optimal probability paths for generative models. InInternational Conference on Machine Learning, pages 30883–30907. PMLR, 2023
2023
-
[47]
D. Shu, Z. Li, and A. B. Farimani. A physics-informed diffusion model for high-fidelity flow field reconstruction.Journal of Computational Physics, 478:111972, 2023. doi: 10.1016/j.jcp. 2023.111972
-
[48]
J. Sirignano, J. F. MacArt, and J. B. Freund. DPM: A deep learning PDE augmentation method with application to large-eddy simulation.Journal of Computational Physics, 423: 109811, 2020. doi: 10.1016/j.jcp.2020.109811
-
[49]
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[50]
T. Whittaker, R. A. Janik, and Y. Oz. Turbulence scaling from deep learning diffusion generative models.Journal of Computational Physics, 514:113239, 2024. doi: 10.1016/j.jcp.2024.113239
-
[51]
S. Wiewel, M. Becher, and N. Thuerey. Latent space physics: Towards learning the temporal evolution of fluid flow.Computer Graphics Forum, 38(2):71–82, 2019. doi: 10.1111/cgf.13620
-
[52]
Y. Wu and K. He. Group normalization. InProceedings of the European Conference on Computer Vision (ECCV), pages 3–19, 2018. doi: 10.1007/978-3-030-01261-8 1
-
[53]
C.-A. Yeh, M. Gopalakrishnan Meena, and K. Taira. Network broadcast analysis and control of turbulent flows.Journal of Fluid Mechanics, 910:A15, 2021. doi: 10.1017/jfm.2020.965
-
[54]
M. Z. Yousif, L. Yu, S. Hoyas, R. Vinuesa, and H. Lim. A deep-learning approach for reconstructing 3D turbulent flows from 2D observation data.Scientific Reports, 13(1):2529,
-
[55]
Yousif, Linqi Yu, Sergio Hoyas, Ricardo Vinuesa, and HeeChang Lim
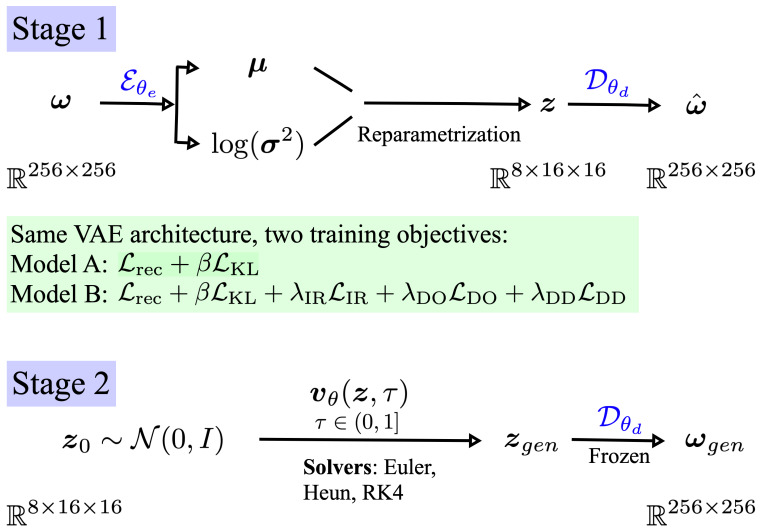
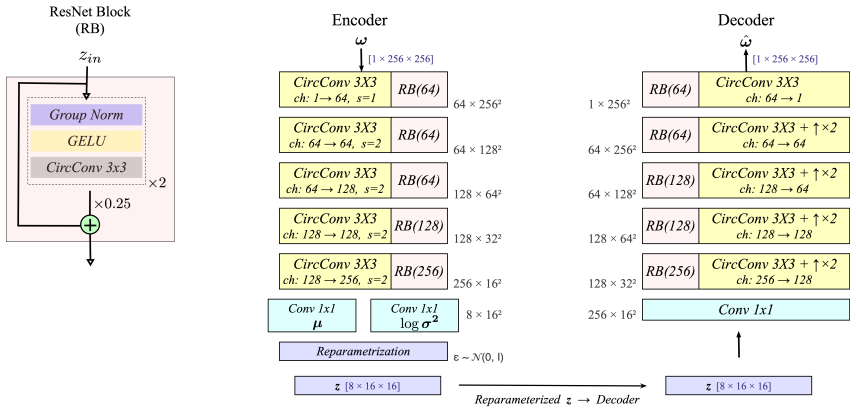
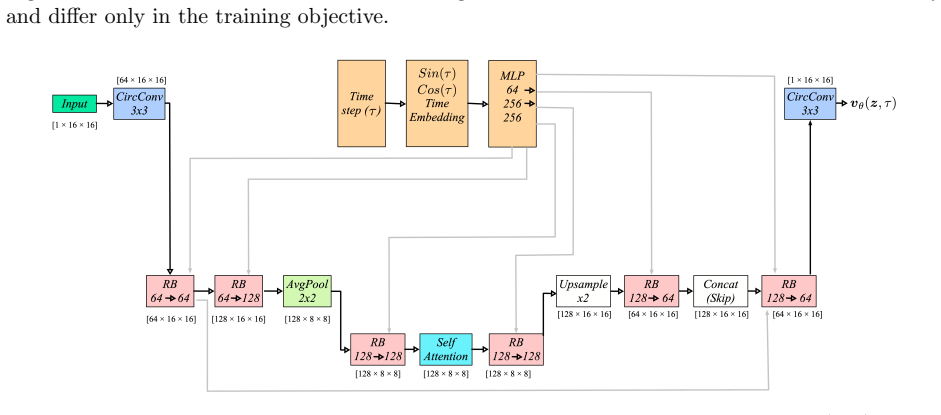
doi: 10.1038/s41598-023-29525-9. A Architecture Details The Stage 1 VAE architecture is shown in Figure 9. The Stage 2 latent flow matching U-Net is shown in Figure 10. A larger latent of size 8 × 32 × 32 (a weaker 16× compression) was also tested; several latent channels exhibited near-zero empirical variance after training, indicating representational r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.