Space-sampled Value Decay: Forgetting Mechanisms for Non-stationary Deep Reinforcement Learning
Pith reviewed 2026-06-27 10:54 UTC · model grok-4.3
The pith
Space-sampled Value Decay supplies an explicit forgetting rule that lets value-based deep RL adapt to drifting environments without any change signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Space-sampled Value Decay is presented as an explicit forgetting mechanism for value-based deep RL architectures. When added to DQN and SAC, the method produces positive effects on handling non-stationary environments while also revealing limitations in the returns that can be achieved.
What carries the argument
Space-sampled Value Decay, a mechanism that samples values across state space and applies decay to older estimates so that agents can drop outdated information without external change cues.
If this is right
- Value-based agents can adapt to environmental drift using only the uncertainty already present in their value estimates.
- Simple decay rules can be inserted into existing DQN and SAC implementations without requiring task IDs or context variables.
- Forgetting through space sampling reduces the impact of outdated rewards or transitions on current policy performance.
- The same decay principle may apply to other value-based architectures beyond the two tested here.
Where Pith is reading between the lines
- Extending the decay rule to policy-gradient methods could test whether the forgetting benefit is specific to value functions.
- Environments with abrupt rather than gradual drift would provide a sharper test of whether sampling alone suffices.
- If the decay rate can be learned from data, the method might reduce the need for manual tuning in new tasks.
Load-bearing premise
The tested non-stationary environments have drift patterns that value decay alone can offset even when the agent receives no information about when or how the environment changes.
What would settle it
A controlled run on one of the paper's non-stationary benchmarks in which the Space-sampled Value Decay versions of DQN or SAC produce equal or lower returns than the unmodified baselines across multiple random seeds.
Figures
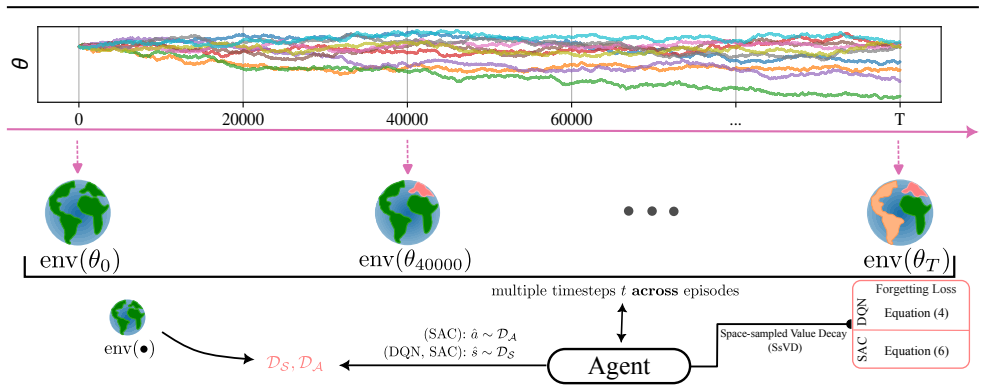
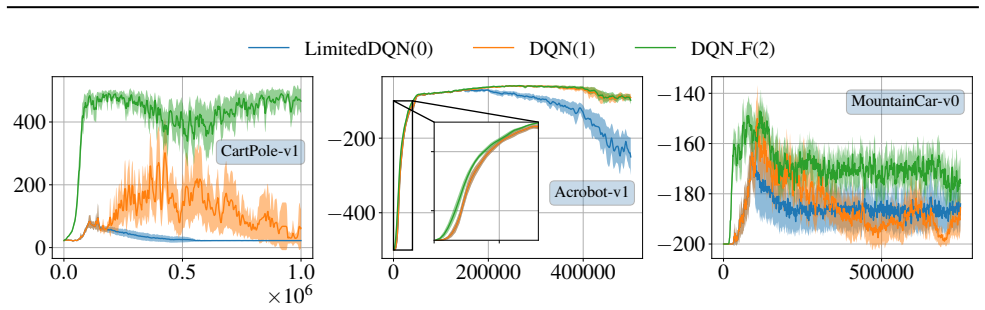
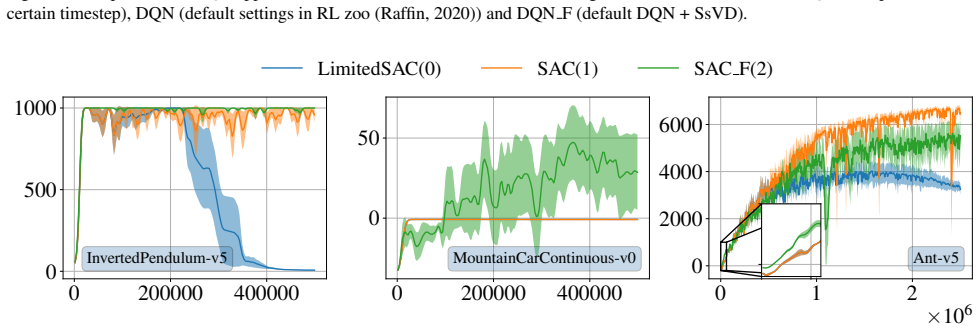
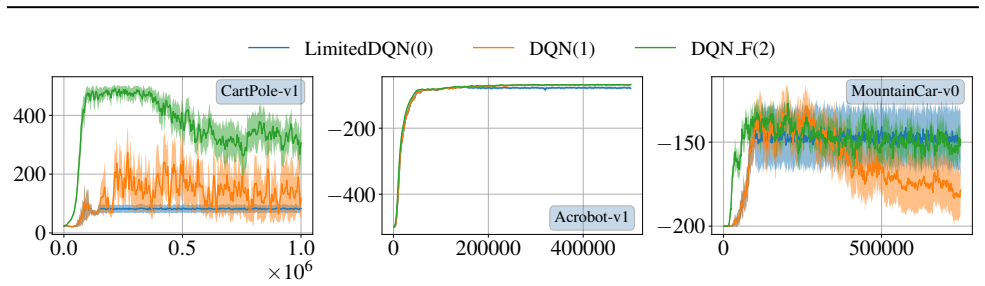
read the original abstract
Studies on rodents such as mice have shown the capabilities to adapt their behavior when dealing with changing parameters (``drift'') of the environment even if no information about change is provided (uncertainty) -- a behavior that can be modeled by forgetting mechanisms. Non-stationary Reinforcement Learning (NSRL) deals with adapting state-of-the-art RL methods to deal with changing environments: these however usually require (partially) perfect information about the drift such as ``task IDs'' or ``context''. To mitigate the effects of drift, this work develops \emph{Space-sampled Value Decay} as an explicit forgetting mechanism for value-based deep RL architectures as a simple yet effective approach. In particular we demonstrate and discuss positive effects but also limitations in achieved returns for modifications of Deep Q-networks (DQN) and Soft Actor-Critic (SAC) when evaluated on non-stationary environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Space-sampled Value Decay as an explicit forgetting mechanism for value-based deep RL architectures (modifications of DQN and SAC) to handle non-stationary environments with environmental drift but no information about the change. Drawing inspiration from rodent studies on adaptation under uncertainty, the work claims to demonstrate positive effects alongside limitations in achieved returns when evaluated on non-stationary environments.
Significance. If the mechanism and results hold under scrutiny, the contribution would lie in offering a simple, context-free forgetting strategy for NSRL that does not rely on task IDs or explicit drift detection. This could broaden applicability of value-based methods in drifting settings and provide a biologically motivated baseline for comparison with more complex adaptation techniques.
major comments (1)
- Abstract: The abstract provides no equations, experimental details, data, or results to verify whether the proposed mechanism actually supports the stated positive effects; assessment impossible from available text.
Simulated Author's Rebuttal
We thank the referee for their comments on our manuscript. We address the single major comment below and are prepared to revise the abstract accordingly.
read point-by-point responses
-
Referee: Abstract: The abstract provides no equations, experimental details, data, or results to verify whether the proposed mechanism actually supports the stated positive effects; assessment impossible from available text.
Authors: We acknowledge that the provided abstract is concise and omits specific equations, experimental details, and quantitative results. This is standard for abstracts in the field to remain brief, with all technical details (including the SSVD formulation, DQN/SAC modifications, non-stationary environment setups, and results on returns) reserved for the main text. We agree this can make standalone assessment of the abstract difficult and will revise it in the next version to include a brief mention of the mechanism and the nature of the observed positive but limited effects. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, or first-principles claims that could reduce to inputs by construction. The work introduces Space-sampled Value Decay as an explicit mechanism and reports empirical effects on modified DQN/SAC without any fitted-parameter predictions presented as independent results or self-citation chains supporting uniqueness. The central contribution is therefore self-contained as a proposed architectural modification evaluated on non-stationary environments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Policy and Value Transfer in Lifelong Reinforcement Learning , booktitle =
Abel, David and Jinnai, Yuu and Guo, Sophie Yue and Konidaris, George and Littman, Michael , editor =. Policy and Value Transfer in Lifelong Reinforcement Learning , booktitle =
-
[2]
International Conference on Learning Representations , author =
Prevalence of Negative Transfer in Continual Reinforcement Learning:. International Conference on Learning Representations , author =
-
[3]
Proceedings of the National Academy of Sciences , volume =
Mice Exhibit Stochastic and Efficient Action Switching during Probabilistic Decision Making , author =. Proceedings of the National Academy of Sciences , volume =
-
[4]
, year = 2020, month = sep, number =
Chandak, Yash and Theocharous, Georgios and Shankar, Shiv and White, Martha and Mahadevan, Sridhar and Thomas, Philip S. , year = 2020, month = sep, number =. Optimizing for the. arXiv , langid =:2005.08158 , primaryclass =
- [5]
-
[6]
Haarnoja, Tuomas and Zhou, Aurick and Abbeel, Pieter and Levine, Sergey , year = 2018, month = aug, number =. Soft. arXiv , langid =:1801.01290 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Proceedings of the 35th International Conference on Machine Learning , author =
Soft Actor-Critic:. Proceedings of the 35th International Conference on Machine Learning , author =
-
[8]
Haarnoja, Tuomas and Zhou, Aurick and Hartikainen, Kristian and Tucker, George and Ha, Sehoon and Tan, Jie and Kumar, Vikash and Zhu, Henry and Gupta, Abhishek and Abbeel, Pieter and Levine, Sergey , year = 2019, month = jan, number =. Soft. arXiv , langid =:1812.05905 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[9]
Double Q-Learning , booktitle =
Hasselt, Hado , editor =. Double Q-Learning , booktitle =
-
[10]
Validation of
Ito, Makoto and Doya, Kenji , year = 2009, month = aug, journal =. Validation of
2009
-
[11]
Forgetting in
Kato, Ayaka and Morita, Kenji , year = 2016, month = oct, journal =. Forgetting in
2016
-
[12]
Keplinger, Nathaniel S. and Luo, Baiting and Bektas, Iliyas and Zhang, Yunuo and Wray, Kyle Hollins and Laszka, Aron and Dubey, Abhishek and Mukhopadhyay, Ayan , year = 2025, month = jan, number =. arXiv , langid =:2501.09646 , primaryclass =
-
[13]
Proceedings of the National Academy of Sciences , volume =
Overcoming Catastrophic Forgetting in Neural Networks , author =. Proceedings of the National Academy of Sciences , volume =
- [14]
-
[15]
Nature , volume =
Human-Level Control through Deep Reinforcement Learning , author =. Nature , volume =
-
[16]
Raffin, Antonin , year = 2020, publisher =
2020
-
[17]
Smooth Exploration for Robotic Reinforcement Learning , booktitle =
Raffin, Antonin and Kober, Jens and Stulp, Freek , editor =. Smooth Exploration for Robotic Reinforcement Learning , booktitle =
-
[18]
Stable-Baselines3:
Raffin, Antonin and Hill, Ashley and Gleave, Adam and Kanervisto, Anssi and Ernestus, Maximilian and Dormann, Noah , year = 2021, journal =. Stable-Baselines3:
2021
-
[19]
Experience Replay for Continual Learning , booktitle =
Rolnick, David and Ahuja, Arun and Schwarz, Jonathan and Lillicrap, Timothy and Wayne, Gregory , editor =. Experience Replay for Continual Learning , booktitle =
-
[20]
Proximal Policy Optimization Algorithms
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , year = 2017, month = aug, number =. Proximal. arXiv , keywords =:1707.06347 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Welcome to the
Silver, David and Sutton, Richard S , year = 2025, abstract =. Welcome to the
2025
-
[22]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Gymnasium: A Standard Interface for Reinforcement Learning Environments , author =. arXiv preprint arXiv:2407.17032 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
and LaValle, S.M
Yershova, A. and LaValle, S.M. , year = 2004, volume =. Deterministic Sampling Methods for Spheres and
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.