TaskFusion: Continual Anomaly Detection for Heterogeneous Tabular Data
Pith reviewed 2026-06-27 10:39 UTC · model grok-4.3
The pith
Task-specific features can be mapped to a shared space to support continual anomaly detection on heterogeneous tabular data without catastrophic forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
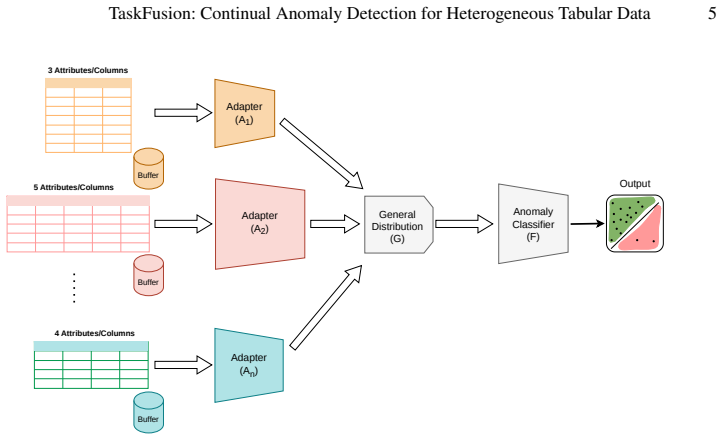
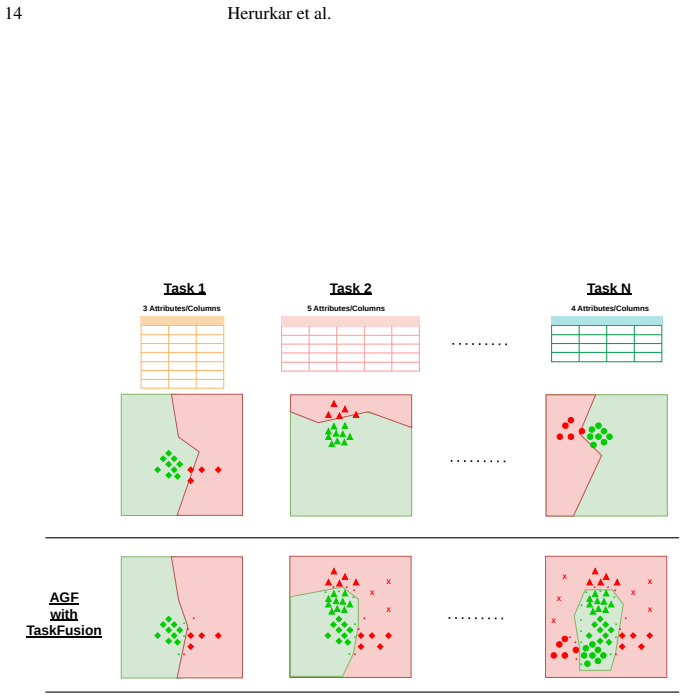
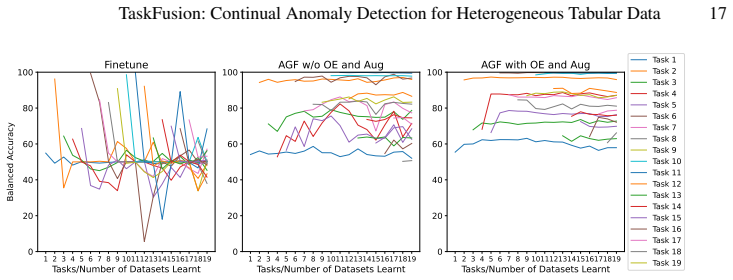
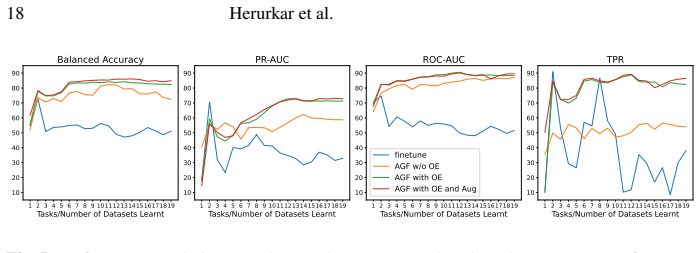
The TaskFusion method uses an AGF model to map task-specific features into a shared space, align their distributions to reduce drift, and learn anomaly decision boundaries there. Taskfusion augmentation refines boundaries via within-task interpolation and transfers structure via cross-task mixing. Tabular dataset distillation creates compact replay samples for outlier exposure to handle imbalance and memory limits. This enables substantial improvements in continual anomaly detection over sequential fine-tuning and other baselines on 21 heterogeneous datasets, with reduced forgetting and stable performance.
What carries the argument
The AGF model that maps task-specific features into a shared space then aligns distributions and learns anomaly decision boundaries in the aligned space.
If this is right
- Substantially improves continual anomaly detection performance over sequential fine-tuning and other CL baselines.
- Reduces catastrophic forgetting.
- Maintains stable detection across heterogeneous datasets.
- Handles class imbalance and memory constraints using distilled replay samples.
Where Pith is reading between the lines
- The shared space approach could extend to other machine learning tasks involving heterogeneous data streams, such as classification or regression in changing environments.
- If the alignment preserves boundaries well, it might reduce the need for task-specific models in deployed anomaly detection systems.
- Further work could test whether the method scales to very high-dimensional or extremely imbalanced tabular data beyond the 21 datasets evaluated.
Load-bearing premise
The AGF model can map task-specific features into a shared space and align distributions in a way that preserves anomaly decision boundaries without requiring task-specific labels or suffering from severe information loss due to heterogeneity.
What would settle it
A new experiment on additional heterogeneous tabular datasets where the method shows no improvement over baselines or exhibits significant catastrophic forgetting would falsify the central claim.
Figures
read the original abstract
Continual anomaly detection in tabular data is challenging and remains largely underexplored, particularly in settings with heterogeneous feature schemas, distribution shifts, and severe class imbalance. In many real-world applications, data arrive sequentially from diverse domains, rendering conventional continual learning methods ineffective due to their reliance on a fixed input space. We propose a continual learning (CL) method, which can overcome these challenges and continually learn from different tasks. Our method consists of three main parts: our AGF model, Taskfusion augmentation, and outlier exposure. The AGF-model maps task-specific features into a shared space, then aligns distributions to reduce representation drift, and learns anomaly decision boundaries in the aligned space. To improve stability, we introduce Taskfusion augmentation, combining boundary-aware interpolation within tasks to refine the model anomaly boundaries and cross-task mixing to transfer anomaly structure across datasets. To handle class imbalance and memory constraints, we employ tabular dataset distillation to store compact synthetic replay samples, which are jointly used with augmented data in an outlier exposure objective for robust anomaly detection. We evaluate the approach on 21 heterogeneous datasets across multiple domains. Results show that our approach substantially improves continual anomaly detection performance over sequential fine-tuning and other CL baselines while reducing catastrophic forgetting and maintaining stable detection across heterogeneous datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TaskFusion for continual anomaly detection on heterogeneous tabular data. The method comprises an AGF model that maps task-specific features into a shared space and performs distribution alignment to reduce drift while learning anomaly boundaries; Taskfusion augmentation that combines boundary-aware intra-task interpolation with cross-task mixing; and tabular dataset distillation to generate compact replay samples used jointly with augmented data in an outlier exposure objective. The approach is evaluated on 21 heterogeneous datasets and is claimed to substantially outperform sequential fine-tuning and other continual learning baselines while mitigating catastrophic forgetting.
Significance. If the empirical claims hold under rigorous scrutiny, the work would address a genuinely underexplored setting—continual anomaly detection under non-overlapping feature schemas and severe imbalance—where standard CL methods fail due to input-space mismatch. The combination of explicit alignment, augmentation, and distillation offers a concrete technical path that could be adopted in domains with streaming heterogeneous tabular streams.
major comments (2)
- [AGF model and alignment procedure] The central claim that the AGF mapping plus alignment step produces a shared representation whose anomaly decision boundaries remain faithful to each task’s original data is load-bearing, yet the manuscript provides no direct measurement (e.g., AUROC or precision-recall on held-out anomalies computed before versus after the mapping/alignment). Without this comparison it is impossible to separate the contribution of the shared-space component from the augmentation and replay mechanisms.
- [Abstract and experimental claims] The abstract asserts “substantial improvements … on 21 heterogeneous datasets” and “stable detection across heterogeneous datasets,” but the provided summary contains no quantitative tables, error bars, ablation results, or experimental protocol details. The data-to-claim link therefore cannot be assessed from the material supplied.
minor comments (2)
- Clarify whether the AGF alignment objective is supervised or unsupervised and how task-specific anomaly labels (if any) are used during alignment.
- Specify the exact memory budget and number of replay samples per task so that comparisons with other replay-based CL baselines are reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, providing clarifications based on the manuscript content and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [AGF model and alignment procedure] The central claim that the AGF mapping plus alignment step produces a shared representation whose anomaly decision boundaries remain faithful to each task’s original data is load-bearing, yet the manuscript provides no direct measurement (e.g., AUROC or precision-recall on held-out anomalies computed before versus after the mapping/alignment). Without this comparison it is impossible to separate the contribution of the shared-space component from the augmentation and replay mechanisms.
Authors: We agree that isolating the AGF mapping and alignment contribution via direct before-versus-after AUROC or precision-recall measurements on held-out anomalies would strengthen the analysis. The manuscript reports end-to-end continual anomaly detection results across 21 datasets that demonstrate gains over sequential fine-tuning and other baselines, which supports the overall pipeline including alignment. To better separate components, we will add the requested before/after comparisons in the revised manuscript. revision: yes
-
Referee: [Abstract and experimental claims] The abstract asserts “substantial improvements … on 21 heterogeneous datasets” and “stable detection across heterogeneous datasets,” but the provided summary contains no quantitative tables, error bars, ablation results, or experimental protocol details. The data-to-claim link therefore cannot be assessed from the material supplied.
Authors: The abstract is a concise summary of the key results. The full manuscript contains the supporting quantitative tables, error bars, ablation studies, and detailed experimental protocols for the 21 heterogeneous datasets. These establish the performance gains and stability claims. We can expand quantitative highlights in the abstract if requested. revision: partial
Circularity Check
No derivation chain or self-referential steps present
full rationale
The paper describes an empirical continual learning method (AGF model for shared-space mapping, Taskfusion augmentation, outlier exposure, and dataset distillation) evaluated on 21 heterogeneous tabular datasets. No equations, first-principles derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. Claims rest on experimental comparisons to baselines rather than any reduction of outputs to inputs by construction. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bahri, D., Jiang, H., Tay, Y ., Metzler, D.: Scarf: Self-supervised contrastive learning using random feature corruption (2022),https://arxiv.org/abs/2106.15147
arXiv 2022
-
[2]
Dong, H., Frusque, G., Zhao, Y ., Chatzi, E., Fink, O.: Nng-mix: Improving semi-supervised anomaly detection with pseudo-anomaly generation. IEEE Transactions on Neural Networks and Learning Systems36(6), 10635–10647 (2025).https://doi.org/10.1109/ TNNLS.2024.3497801
arXiv 2025
-
[3]
In: Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security
Du, M., Chen, Z., Liu, C., Oak, R., Song, D.: Lifelong anomaly detection through unlearning. In: Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. p. 1283–1297. CCS ’19, Association for Computing Machinery, New York, NY , USA (2019).https://doi.org/10.1145/3319535.3363226,https://doi. org/10.1145/3319535.3363226
-
[4]
IEEE Access12, 41364– 41380 (2024).https://doi.org/10.1109/ACCESS.2024.3377690
Faber, K., Corizzo, R., Sniezynski, B., Japkowicz, N.: Lifelong continual learning for anomaly detection: New challenges, perspectives, and insights. IEEE Access12, 41364– 41380 (2024).https://doi.org/10.1109/ACCESS.2024.3377690
-
[5]
In: 2022 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR)
Fini, E., Da Costa, V .G.T., Alameda-Pineda, X., Ricci, E., Alahari, K., Mairal, J.: Self- supervised models are continual learners. In: 2022 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR). pp. 9611–9620 (2022).https://doi.org/10. 1109/CVPR52688.2022.00940
arXiv 2022
-
[6]
Frikha, A., Krompass, D., Tresp, V .: ARCADe: A Rapid Continual Anomaly De- tector . In: 2020 25th International Conference on Pattern Recognition (ICPR). pp. 10449–10456. IEEE Computer Society, Los Alamitos, CA, USA (Jan 2021). https://doi.org/10.1109/ICPR48806.2021.9412627,https: //doi.ieeecomputersociety.org/10.1109/ICPR48806.2021.9412627
-
[7]
Advances in Neural Information Processing Systems35, 32142–32159 (2022) 12 Herurkar et al
Han, S., Hu, X., Huang, H., Jiang, M., Zhao, Y .: Adbench: Anomaly detection benchmark. Advances in Neural Information Processing Systems35, 32142–32159 (2022) 12 Herurkar et al
2022
-
[8]
Hendrycks, D., Mazeika, M., Dietterich, T.: Deep anomaly detection with outlier exposure (2019),https://arxiv.org/abs/1812.04606
Pith/arXiv arXiv 2019
-
[9]
IEEE Access14, 25691–25705 (2026)
Herurkar, D., Hees, J., Tzvetkov, V ., Dengel, A.: Tabular data adapters: Pseudo-labeling un- labeled private tabular data for outlier detection. IEEE Access14, 25691–25705 (2026). https://doi.org/10.1109/ACCESS.2026.3663975
-
[10]
Herurkar, D., Meier, M., Hees, J.: Recol: Reconstruction error columns for outlier detection. In: KI 2023: Advances in Artificial Intelligence: 46th German Conference on AI, Berlin, Germany, September 26–29, 2023, Proceedings. p. 60–74. Springer-Verlag, Berlin, Hei- delberg (2023).https://doi.org/10.1007/978-3-031-42608-7_6,https: //doi.org/10.1007/978-3-...
-
[11]
ArXivabs/2404.14933(2024),https://api
Herurkar, D., Palacio, S.M., Anwar, A., Hees, J., Dengel, A.: Fin-fed-od: Federated out- lier detection on financial tabular data. ArXivabs/2404.14933(2024),https://api. semanticscholar.org/CorpusID:269303016
arXiv 2024
-
[12]
In: Proceedings of the 5th ACM International Conference on AI in Finance
Herurkar, D., Raue, F., Dengel, A.: Tab-distillation: Impacts of dataset distillation on tabular data for outlier detection. In: Proceedings of the 5th ACM International Conference on AI in Finance. p. 804–812. ICAIF ’24, Association for Computing Machinery, New York, NY , USA (2024).https://doi.org/10.1145/3677052.3698660,https://doi. org/10.1145/3677052.3698660
-
[13]
Herurkar, D., Sattarov, T., Hees, J., Palacio, S., Raue, F., Dengel, A.: Cross-domain transfor- mation for outlier detection on tabular datasets. In: International Joint Conference on Neural Networks, IJCNN 2023, Gold Coast, Australia, June 18-23, 2023. pp. 1–8. IEEE (2023). https://doi.org/10.1109/IJCNN54540.2023.10191326,https://doi. org/10.1109/IJCNN54...
-
[14]
Hilal, W., Gadsden, S.A., Yawney, J.: Financial fraud: A review of anomaly detection tech- niques and recent advances. Expert Systems with Applications193, 116429 (2022).https: //doi.org/https://doi.org/10.1016/j.eswa.2021.116429,https:// www.sciencedirect.com/science/article/pii/S0957417421017164
-
[15]
King, S., Zhang, Z., Yu, R., Coskun, B., Ding, W., Cui, Q.: Contextual learning for anomaly detection in tabular data (2025),https://arxiv.org/abs/2509.09030
arXiv 2025
-
[16]
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Mi- lan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Ku- maran, D., Hadsell, R.: Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences114(13), 3521–3526 (2017).https://doi.org/ 10.1073/pnas...
-
[17]
Li, Z., Hoiem, D.: Learning without forgetting (2017),https://arxiv.org/abs/ 1606.09282
Pith/arXiv arXiv 2017
-
[18]
In: 2024 IEEE 40th International Conference on Data Engi- neering (ICDE)
LIU, H., DI, S., LI, H., LI, S., CHEN, L., ZHOU, X.: Effective data selection and replay for unsupervised continual learning. In: 2024 IEEE 40th International Conference on Data Engi- neering (ICDE). pp. 1449–1463 (2024).https://doi.org/10.1109/ICDE60146. 2024.00119
-
[19]
Rebuffi, S.A., Kolesnikov, A., Sperl, G., Lampert, C.H.: icarl: Incremental classifier and rep- resentation learning. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5533–5542 (2017).https://doi.org/10.1109/CVPR.2017.587
-
[20]
In: Proceedings of the 33rd ACM International Conference on Infor- mation and Knowledge Management
Thimonier, H., Popineau, F., Rimmel, A., Doan, B.L.: Retrieval augmented deep anomaly de- tection for tabular data. In: Proceedings of the 33rd ACM International Conference on Infor- mation and Knowledge Management. p. 2250–2259. CIKM ’24, Association for Computing Machinery, New York, NY , USA (2024).https://doi.org/10.1145/3627673. 3679559,https://doi.o...
-
[21]
2022 International Joint Conference on Neu- ral Networks (IJCNN) pp
Thimonier, H., Popineau, F., Rimmel, A., Doan, B.L., Daniel, F.: Tracinad: Mea- suring influence for anomaly detection. 2022 International Joint Conference on Neu- ral Networks (IJCNN) pp. 1–6 (2022),https://api.semanticscholar.org/ CorpusID:248505883
2022
-
[22]
In: International Conference on Machine Learning (2018),https://api.semanticscholar.org/ CorpusID:59604501
Verma, V ., Lamb, A., Beckham, C., Najafi, A., Mitliagkas, I., Lopez-Paz, D., Bengio, Y .: Manifold mixup: Better representations by interpolating hidden states. In: International Conference on Machine Learning (2018),https://api.semanticscholar.org/ CorpusID:59604501
2018
-
[23]
Xu, H., Pang, G., Wang, Y ., Wang, Y .: Deep isolation forest for anomaly detection. IEEE Transactions on Knowledge and Data Engineering35(12), 12591–12604 (2023).https: //doi.org/10.1109/TKDE.2023.3270293
-
[24]
In: The Twelfth International Conference on Learning Representa- tions (2024),https://openreview.net/forum?id=lNZJyEDxy4
Yin, J., Qiao, Y ., Zhou, Z., Wang, X., Yang, J.: MCM: Masked cell modeling for anomaly detection in tabular data. In: The Twelfth International Conference on Learning Representa- tions (2024),https://openreview.net/forum?id=lNZJyEDxy4
2024
-
[25]
In: 6th International Conference on Learning Representations, ICLR 2018, Van- couver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings
Zhang, H., Cissé, M., Dauphin, Y .N., Lopez-Paz, D.: mixup: Beyond empirical risk mini- mization. In: 6th International Conference on Learning Representations, ICLR 2018, Van- couver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenRe- view.net (2018),https://openreview.net/forum?id=r1Ddp1-Rb
2018
-
[26]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
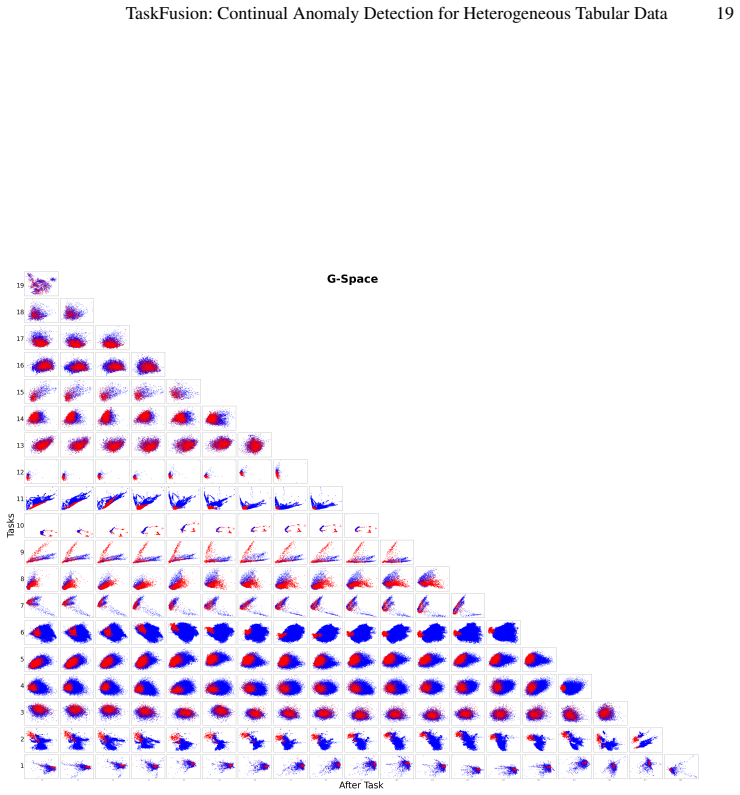
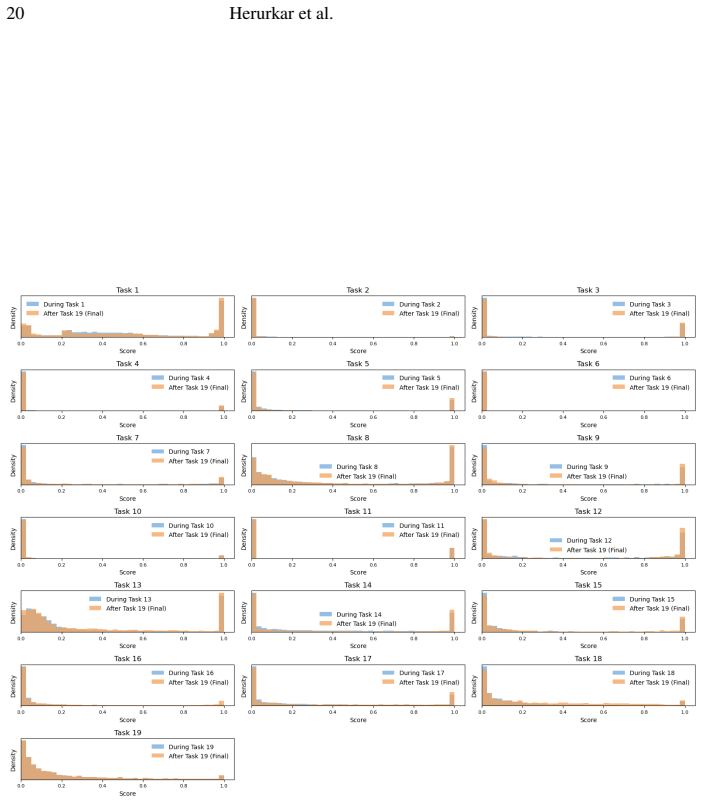
Zhao, B., Bilen, H.: Dataset condensation with distribution matching. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6514–6523 (2023) A Appendix: To further understand the behavior of the proposed framework under long continual learning sequences, we provide additional qualitative and distributional analyses of t...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.