Gerrymandering the Warp: Non-Control-Data Attacks on CUDA Collective Decision
Pith reviewed 2026-06-27 09:04 UTC · model grok-4.3
The pith
Corrupted participation metadata lets CUDA collectives authorize decisions over the wrong set even when executing the intended primitive.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
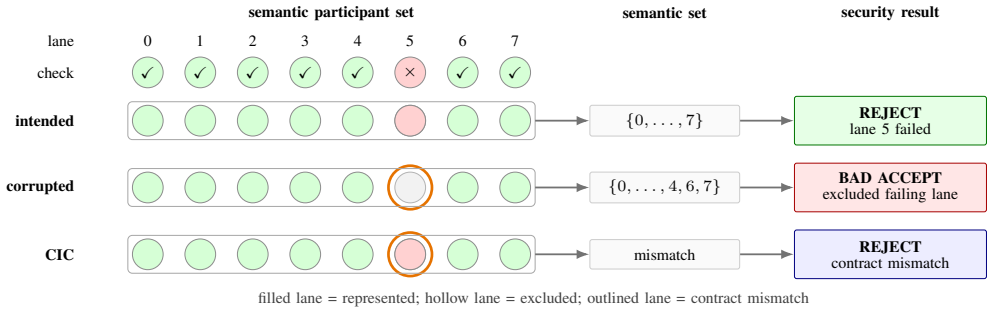
Collective Semantic Corruption (CSC) is a non-control-data attack in which range-valid masks, predicates, source lanes, descriptors, group labels, or epochs cause a CUDA-conforming collective to authorize a decision over the wrong membership, contribution, role, or validation-to-use state. The kernel reaches the intended collective site and executes the expected primitive, yet the primitive represents the wrong authority set.
What carries the argument
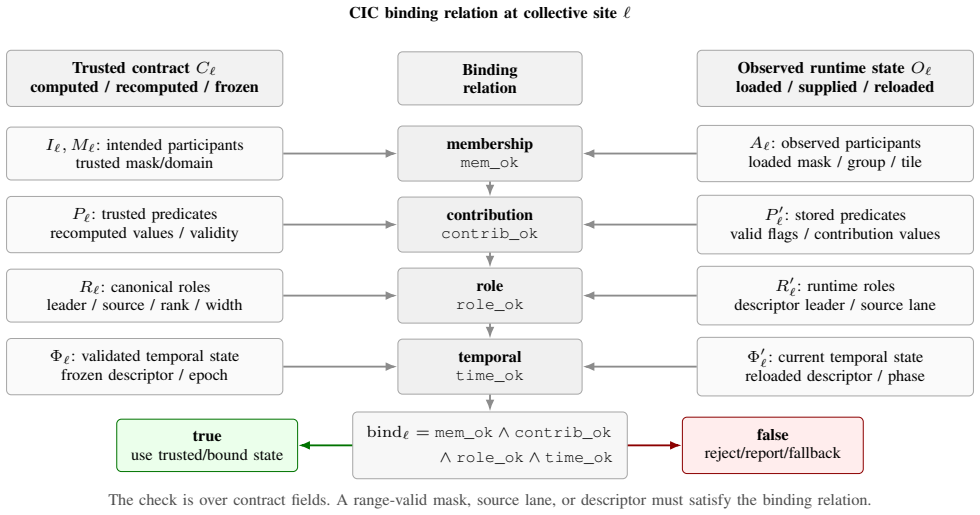
The site-local participation-authority contract, which derives, recomputes, checks, or freezes membership, contribution, role, and temporal state before authorization in protected collectives.
If this is right
- Corrupted participation metadata causes a trusted-reference mismatch in 102 out of 102 instances in the contract-conformance suite.
- Hardened variants preserve the trusted reference in 102 out of 102 instances.
- CIC wrappers bind participation metadata before collective use to prevent such corruption.
- Security of CUDA collective decisions depends on both computed values and represented participants.
Where Pith is reading between the lines
- Similar non-control data attacks may exist in other parallel programming models that use collectives for decisions.
- The CIC discipline could be tested for performance impact in production CUDA workloads.
Load-bearing premise
The site-local participation-authority contract accurately models how CUDA collectives participate in security decision paths, and the evaluation suite represents real usage.
What would settle it
Finding even one instance in the contract-conformance suite where corrupted participation metadata does not produce a trusted-reference mismatch would falsify the attack effectiveness claim.
Figures
read the original abstract
CUDA collective operations often sit on security decision paths: votes accept batches, reductions aggregate evidence, shuffles select representatives, and barriers order checked state before use. Such decisions depend not only on computed values, but also on which lanes are represented, what evidence they contribute, which lane speaks for the group, and which checked state reaches commit. We identify this participation metadata as decision-making non-control data. We define Collective Semantic Corruption (CSC), a non-control-data attack family in which range-valid masks, predicates, source lanes, descriptors, group labels, or epochs cause a CUDA-conforming collective to authorize a decision over the wrong membership, contribution, role, or validation-to-use state. The kernel reaches the intended collective site and executes the expected primitive; the primitive represents the wrong authority set. We model CSC with a site-local participation-authority contract. A protected collective derives, recomputes, checks, or freezes membership, contribution, role, and temporal state before authorization. We evaluate CSC across NVIDIA CUDA collective primitives, trigger channels, compact workload-style kernels, reduced idiom bridges, and admission-guard harnesses. In a CUDA-defined contract-conformance suite spanning the four authority dimensions, corrupted participation metadata causes a trusted-reference mismatch in 102/102 instances, while hardened variants preserve that reference in 102/102. We report 13 synchronization-sensitive instances separately. We then introduce Collective Integrity Contracts (CIC), a wrapper discipline that binds participation metadata before collective use. For CUDA collective decisions, security depends on both the values computed and the participants represented.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that CUDA collective operations (votes, reductions, shuffles, barriers) depend on participation metadata as non-control data. It defines Collective Semantic Corruption (CSC) attacks that corrupt masks, predicates, lanes, or epochs to authorize decisions over the wrong membership/contribution/role/temporal state while still executing a conforming primitive. The attack is modeled via a site-local four-dimensional participation-authority contract. In a custom CUDA-defined contract-conformance suite using compact kernels, idiom bridges, and harnesses, corrupted metadata produces trusted-reference mismatch in 102/102 instances while CIC-hardened variants preserve the reference in 102/102; 13 synchronization-sensitive cases are noted separately. The paper concludes that security of CUDA collective decisions requires binding both computed values and represented participants.
Significance. If the central empirical result holds under a validated contract, the work identifies a previously unexamined non-control-data attack surface on GPU collectives that sit on security decision paths. The systematic four-dimensional model and the constructive CIC wrapper discipline are positive contributions. The consistent 102/102 count across the authors' suite demonstrates internal reproducibility of the modeled attack. However, because the evaluation uses only synthetic conformance artifacts rather than production security kernels, the assessed external impact remains limited even if the internal result is sound.
major comments (2)
- [Abstract] Abstract: the headline 102/102 trusted-reference mismatch result is obtained exclusively inside a custom 'CUDA-defined contract-conformance suite' built around the authors' four-dimensional participation-authority contract; no details are supplied on the concrete test cases, trigger channels, error-handling, or how the suite maps to real authority sets used in production collective security decisions (votes on batches, reductions on evidence).
- [Abstract] Abstract: the evaluation therefore demonstrates only internal consistency of the site-local contract rather than external security impact; the weakest assumption (that the membership/contribution/role/temporal dimensions accurately model authority sets fed into actual CUDA security paths) is unvalidated and load-bearing for the claim that CSC affects real decisions.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recognition of the internal reproducibility of our results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline 102/102 trusted-reference mismatch result is obtained exclusively inside a custom 'CUDA-defined contract-conformance suite' built around the authors' four-dimensional participation-authority contract; no details are supplied on the concrete test cases, trigger channels, error-handling, or how the suite maps to real authority sets used in production collective security decisions (votes on batches, reductions on evidence).
Authors: The abstract summarizes the result at a high level. The full manuscript describes the contract-conformance suite, the compact kernels, idiom bridges, harnesses, and the systematic coverage of the four authority dimensions with explicit trigger channels. We will revise the abstract to briefly note the evaluation methodology and direct readers to the detailed test cases in the evaluation section. revision: yes
-
Referee: [Abstract] Abstract: the evaluation therefore demonstrates only internal consistency of the site-local contract rather than external security impact; the weakest assumption (that the membership/contribution/role/temporal dimensions accurately model authority sets fed into actual CUDA security paths) is unvalidated and load-bearing for the claim that CSC affects real decisions.
Authors: We agree that the reported evaluation establishes internal consistency of the modeled contract rather than direct measurement on production security kernels. The four-dimensional model is derived from the documented semantics of CUDA collective primitives. We will revise the abstract and add a scope statement in the introduction to clarify that the work identifies a new attack surface and mitigation discipline, with external impact depending on the use of collectives in security decision paths. revision: partial
Circularity Check
No significant circularity; empirical evaluation is self-contained but not reductive
full rationale
The paper defines CSC via a site-local participation-authority contract and reports an empirical count (102/102 mismatch) inside a custom CUDA-defined contract-conformance suite. No derivation chain, equations, or first-principles predictions are present that reduce to inputs by construction. The result demonstrates behavior within the authors' model but is not claimed as a mathematical derivation or fitted prediction; it is presented as an evaluation outcome. No self-citations, uniqueness theorems, or ansatz smuggling appear in the provided text. The evaluation is synthetic and internal by design, yet this does not meet the criteria for circularity under the enumerated patterns since no specific reduction (e.g., Eq. X equivalent to input by definition) is exhibited.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CUDA collective operations often sit on security decision paths
invented entities (2)
-
Collective Semantic Corruption (CSC)
no independent evidence
-
Collective Integrity Contracts (CIC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Non-control-data attacks are realistic threats,
S. Chen, J. Xu, and E. C. Sezer, “Non-control-data attacks are realistic threats,” inProceedings of the 14th USENIX Security Symposium. USENIX Association, 2005. [Online]. Available: https://www.usenix.org/conference/14th-usenix-security-symposium/ non-control-data-attacks-are-realistic-threats
2005
-
[2]
Modular protections against non-control data attacks,
C. Schlesinger, K. Pattabiraman, N. Swamy, D. Walker, and B. G. Zorn, “Modular protections against non-control data attacks,”Journal of Computer Security, vol. 22, no. 5, pp. 699–742, 2014
2014
-
[3]
Data-oriented programming: On the expressiveness of non-control data attacks,
H. Hu, S. Shinde, S. Adrian, Z. L. Chua, P. Saxena, and Z. Liang, “Data-oriented programming: On the expressiveness of non-control data attacks,” inProceedings of the 37th IEEE Symposium on Security and Privacy. IEEE, 2016, pp. 969–986
2016
-
[4]
Control-flow integrity,
M. Abadi, M. Budiu, Ú. Erlingsson, and J. Ligatti, “Control-flow integrity,” inProceedings of the 12th ACM Conference on Computer and Communications Security (CCS ’05). ACM, 2005, pp. 340–353
2005
-
[5]
Code-Pointer integrity,
V . Kuznetsov, L. Szekeres, M. Payer, G. Candea, R. Sekar, and D. Song, “Code-Pointer integrity,” inProceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’14). Broomfield, CO: USENIX Association, Oct. 2014, pp. 147–
2014
-
[6]
Available: https://www.usenix.org/conference/osdi14/ technical-sessions/presentation/kuznetsov
[Online]. Available: https://www.usenix.org/conference/osdi14/ technical-sessions/presentation/kuznetsov
-
[7]
Securing software by enforcing data-flow integrity,
M. Castro, M. Costa, and T. Harris, “Securing software by enforcing data-flow integrity,” inProceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’06). USENIX Association, 2006, pp. 147–
2006
-
[8]
Available: https://www.usenix.org/conference/osdi-06/ securing-software-enforcing-data-flow-integrity
[Online]. Available: https://www.usenix.org/conference/osdi-06/ securing-software-enforcing-data-flow-integrity
-
[9]
[Online]
NVIDIA,CUDA Programming Guide, 2026, accessed 2026-06-09. [Online]. Available: https://docs.nvidia.com/cuda/ cuda-programming-guide/
2026
-
[10]
[Online]
——,PTX ISA, 2026, accessed 2026-06-09. [Online]. Available: https://docs.nvidia.com/cuda/parallel-thread-execution/
2026
-
[11]
[Online]
——,CUDA C++ Best Practices Guide, 2026, accessed 2026-05-21. [Online]. Available: https://docs.nvidia.com/cuda/ cuda-c-best-practices-guide/
2026
-
[12]
On the correctness of the SIMT execution model of GPUs,
A. Habermaier and A. Knapp, “On the correctness of the SIMT execution model of GPUs,” inProgramming Languages and Systems, ser. Lecture Notes in Computer Science, vol
-
[13]
Springer, 2012, pp. 316–335. [Online]. Available: https: //doi.org/10.1007/978-3-642-28869-2_16
-
[14]
Using CUDA warp-level primitives,
Y . Lin and V . Grover, “Using CUDA warp-level primitives,” NVIDIA Technical Blog, 2018, accessed 2026-06-09. [Online]. Available: https://developer.nvidia.com/blog/using-cuda-warp-level-primitives/
2018
-
[15]
[Online]
NVIDIA,Cooperative Groups, 2026, accessed 2026-05-21. [Online]. Available: https://docs.nvidia.com/cuda/cuda-programming-guide/ 04-special-topics/cooperative-groups.html
2026
-
[16]
Prefix sums and their applications,
G. E. Blelloch, “Prefix sums and their applications,” School of Computer Science, Carnegie Mellon University, Tech. Rep. CMU- CS-90-190, Nov. 1990. [Online]. Available: https://www.cs.cmu.edu/ afs/cs.cmu.edu/project/scandal/public/papers/CMU-CS-90-190.html
1990
-
[17]
Scan prim- itives for GPU computing,
S. Sengupta, M. J. Harris, Y . Zhang, and J. D. Owens, “Scan prim- itives for GPU computing,” inProceedings of the SIGGRAPH/Eu- rographics Workshop on Graphics Hardware. The Eurographics Association, 2007, pp. 97–106
2007
-
[18]
Efficient parallel scan algorithms for GPUs,
S. Sengupta, M. Harris, and M. Garland, “Efficient parallel scan algorithms for GPUs,” NVIDIA, Tech. Rep. NVR-2008-003, Dec
2008
-
[19]
Available: https://research.nvidia.com/publication/ 2008-12_efficient-parallel-scan-algorithms-gpus
[Online]. Available: https://research.nvidia.com/publication/ 2008-12_efficient-parallel-scan-algorithms-gpus
2008
-
[20]
[Online]
NVIDIA,CUB: Cooperative Primitives for CUDA C++, 2026, accessed 2026-06-09. [Online]. Available: https://nvidia.github.io/ cccl/unstable/cub/index.html
2026
-
[21]
——,Thrust: Parallel Algorithms Library, 2026, accessed 2026-05-
2026
-
[22]
Available: https://developer.nvidia.com/thrust
[Online]. Available: https://developer.nvidia.com/thrust
-
[23]
CUDPP: CUDA data parallel primitives library,
CUDPP Project, “CUDPP: CUDA data parallel primitives library,” 2016, version 2.3, accessed 2026-05-25. [Online]. Available: https://cudpp.github.io/
2016
-
[24]
Baxter,ModernGPU Library, 2016, accessed 2026-05-25
S. Baxter,ModernGPU Library, 2016, accessed 2026-05-25. [Online]. Available: https://moderngpu.github.io/library.html
2016
-
[25]
Single-pass parallel prefix scan with decoupled look-back,
D. Merrill and M. Garland, “Single-pass parallel prefix scan with decoupled look-back,” NVIDIA, Tech. Rep. NVR-2016-002, Mar
2016
-
[26]
Available: https://www.mgarland.org/papers/2016/ scan/
[Online]. Available: https://www.mgarland.org/papers/2016/ scan/
2016
-
[27]
CUTLASS: Fast linear algebra in CUDA C++,
A. Kerr, D. Merrill, J. Demouth, and J. Tran, “CUTLASS: Fast linear algebra in CUDA C++,” NVIDIA Technical Blog, 2017, accessed 2026-05-21. [Online]. Available: https://developer.nvidia. com/blog/cutlass-linear-algebra-cuda/
2017
-
[28]
cuDNN: Efficient primitives for deep learning,
S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro, and E. Shelhamer, “cuDNN: Efficient primitives for deep learning,” 2014. [Online]. Available: https://arxiv.org/abs/1410. 0759
2014
-
[29]
Gunrock: a high-performance graph processing library on the GPU,
Y . Wang, A. A. Davidson, Y . Pan, Y . Wu, A. Riffel, and J. D. Owens, “Gunrock: a high-performance graph processing library on the GPU,” inProceedings of the 21st ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP ’16). ACM, 2016, pp. 11:1–11:12
2016
-
[30]
Billion-scale similarity search with GPUs,
J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with GPUs,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535– 547, 2021
2021
-
[31]
Rodinia: a benchmark suite for heterogeneous comput- ing,
S. Che, M. Boyer, J. Meng, D. Tarjan, J. W. Sheaffer, S.-H. Lee, and K. Skadron, “Rodinia: a benchmark suite for heterogeneous comput- ing,” inProceedings of the 2009 IEEE International Symposium on Workload Characterization (IISWC ’09). IEEE, 2009, pp. 44–54
2009
-
[32]
GPU memory exploitation for fun and profit,
Y . Guo, Z. Zhang, and J. Yang, “GPU memory exploitation for fun and profit,” in33rd USENIX Security Symposium (USENIX Security 24). Philadelphia, PA: USENIX Association, Aug. 2024, pp. 4033–4050. [Online]. Available: https://www.usenix.org/conference/ usenixsecurity24/presentation/guo-yanan
2024
-
[33]
CUDA, woulda, shoulda: Returning exploits in a SASS-y world,
J. Roels, A. Jacobs, and S. V olckaert, “CUDA, woulda, shoulda: Returning exploits in a SASS-y world,” inProceedings of the 18th European Workshop on Systems Security (EuroSec ’25). New York, NY , USA: Association for Computing Machinery, 2025, pp. 40–48. [Online]. Available: https://doi.org/10.1145/3722041.3723099
-
[34]
AddressSanitizer: A fast address sanity checker,
K. Serebryany, D. Bruening, A. Potapenko, and D. Vyukov, “AddressSanitizer: A fast address sanity checker,” in2012 USENIX Annual Technical Conference (USENIX ATC ’12). Boston, MA: USENIX Association, Jun. 2012, pp. 309–
2012
-
[35]
Available: https://www.usenix.org/conference/atc12/ addresssanitizer-fast-address-sanity-checker
[Online]. Available: https://www.usenix.org/conference/atc12/ addresssanitizer-fast-address-sanity-checker
-
[36]
Baggy bounds checking: An efficient and backwards-compatible defense against Out-of-Bounds errors,
P. Akritidis, M. Costa, M. Castro, and S. Hand, “Baggy bounds checking: An efficient and backwards-compatible defense against Out-of-Bounds errors,” in18th USENIX Security Symposium (USENIX Security ’09). Montreal, QC, Canada: USENIX Association, Aug. 2009, pp. 51–66. [On- line]. Available: https://www.usenix.org/conference/usenixsecurity09/ technical-ses...
2009
-
[37]
SoftBound: Highly compatible and complete spatial memory safety for C,
S. Nagarakatte, J. Zhao, M. M. K. Martin, and S. Zdancewic, “SoftBound: Highly compatible and complete spatial memory safety for C,” inProceedings of the 30th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI ’09). ACM, 2009, pp. 245–258
2009
-
[38]
CETS: Compiler-enforced temporal safety for C,
——, “CETS: Compiler-enforced temporal safety for C,” inProceed- ings of the 9th International Symposium on Memory Management (ISMM ’10). ACM, 2010, pp. 31–40
2010
-
[39]
Securing GPU via region-based bounds checking,
J. Lee, Y . Kim, J. Cao, E. Kim, J. Lee, and H. Kim, “Securing GPU via region-based bounds checking,” inProceedings of the 49th Annual International Symposium on Computer Architecture (ISCA ’22). ACM, 2022, pp. 27–41
2022
-
[40]
CuSafe: Capturing memory corruption on NVIDIA GPUs,
H. Lu, F. Zhang, Z. Zhang, S. Wang, and Y . Guo, “CuSafe: Capturing memory corruption on NVIDIA GPUs,” inProceedings of the 35th USENIX Security Symposium (USENIX Security 2026). USENIX Association, 2026, to appear
2026
-
[41]
Rendered insecure: GPU side channel attacks are practical,
H. Naghibijouybari, A. Neupane, Z. Qian, and N. B. Abu-Ghazaleh, “Rendered insecure: GPU side channel attacks are practical,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS ’18). ACM, 2018, pp. 2139–2153
2018
-
[42]
GPU.zip: On the side-channel implications of hardware-based graphical data compression,
Y . Wang, R. Paccagnella, Zhao Gang, W. R. Vasquez, D. Kohlbrenner, H. Shacham, and C. W. Fletcher, “GPU.zip: On the side-channel implications of hardware-based graphical data compression,” inPro- ceedings of the 45th IEEE Symposium on Security and Privacy. IEEE, 2024, pp. 3716–3734
2024
-
[43]
Owl: Differential-based side-channel leakage detection for CUDA appli- cations,
Y . Zhao, W. Xue, W. Chen, W. Qiang, D. Zou, and H. Jin, “Owl: Differential-based side-channel leakage detection for CUDA appli- cations,” inProceedings of the 54th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN ’24). IEEE, 2024, pp. 362–376
2024
-
[44]
[Online]
NVIDIA,Compute Sanitizer, 2026, accessed 2026-06-09. [Online]. Available: https://docs.nvidia.com/compute-sanitizer/index.html
2026
-
[45]
The geometry of innocent flesh on the bone: Return- into-libc without function calls (on the x86),
H. Shacham, “The geometry of innocent flesh on the bone: Return- into-libc without function calls (on the x86),” inProceedings of the 14th ACM Conference on Computer and Communications Security (CCS ’07). ACM, 2007, pp. 552–561
2007
-
[46]
Jump-oriented programming: A new class of code-reuse attack,
T. K. Bletsch, X. Jiang, V . W. Freeh, and Z. Liang, “Jump-oriented programming: A new class of code-reuse attack,” inProceedings of the 6th ACM Symposium on Information, Computer and Communi- cations Security (AsiaCCS ’11). ACM, 2011, pp. 30–40
2011
-
[47]
SoK: Eternal war in memory,
L. Szekeres, M. Payer, T. Wei, and D. Song, “SoK: Eternal war in memory,” inProceedings of the 34th IEEE Symposium on Security and Privacy. IEEE, 2013, pp. 48–62
2013
-
[48]
GPUVerify: a verifier for GPU kernels,
A. Betts, N. Chong, A. F. Donaldson, S. Qadeer, and P. Thomson, “GPUVerify: a verifier for GPU kernels,” inProceedings of the 27th Annual ACM SIGPLAN Conference on Object-Oriented Program- ming, Systems, Languages, and Applications (OOPSLA ’12). ACM, 2012, pp. 113–132
2012
-
[49]
GKLEE: concolic verification and test generation for GPUs,
G. Li, P. Li, G. Sawaya, G. Gopalakrishnan, I. Ghosh, and S. P. Rajan, “GKLEE: concolic verification and test generation for GPUs,” inProceedings of the 17th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP ’12). ACM, 2012, pp. 215–224
2012
-
[50]
Practical symbolic race check- ing of GPU programs,
P. Li, G. Li, and G. Gopalakrishnan, “Practical symbolic race check- ing of GPU programs,” inProceedings of the International Con- ference for High Performance Computing, Networking, Storage and Analysis (SC ’14). IEEE, 2014, pp. 179–190
2014
-
[51]
GMRace: Detecting data races in GPU programs via a low-overhead scheme,
M. Zheng, V . T. Ravi, F. Qin, and G. Agrawal, “GMRace: Detecting data races in GPU programs via a low-overhead scheme,”IEEE Transactions on Parallel and Distributed Systems, vol. 25, no. 1, pp. 104–115, 2014
2014
-
[52]
BAR- RACUDA: binary-level analysis of runtime RAces in CUDA pro- grams,
A. Eizenberg, Y . Peng, T. Pigli, W. Mansky, and J. Devietti, “BAR- RACUDA: binary-level analysis of runtime RAces in CUDA pro- grams,” inProceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI ’17). ACM, 2017, pp. 126–140
2017
-
[53]
Oclgrind: an extensible OpenCL device simulator,
J. Price and S. McIntosh-Smith, “Oclgrind: an extensible OpenCL device simulator,” inProceedings of the 3rd International Workshop on OpenCL (IWOCL ’15). ACM, 2015, pp. 12:1–12:7
2015
-
[54]
Characterizing and Detecting CUDA Program Bugs
M. Wu, H. Zhou, L. Zhang, C. Liu, and Y . Zhang, “Characterizing and detecting CUDA program bugs,” 2019. [Online]. Available: https://arxiv.org/abs/1905.01833
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[55]
Automating CUDA synchronization via program transformation,
M. Wu, L. Zhang, C. Liu, S. H. Tan, and Y . Zhang, “Automating CUDA synchronization via program transformation,” inProceedings of the 34th IEEE/ACM International Conference on Automated Soft- ware Engineering (ASE ’19). IEEE, 2019, pp. 748–759
2019
-
[56]
Simulee: detecting CUDA synchronization bugs via memory-access modeling,
M. Wu, Y . Ouyang, H. Zhou, L. Zhang, C. Liu, and Y . Zhang, “Simulee: detecting CUDA synchronization bugs via memory-access modeling,” inProceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE ’20). ACM, 2020, pp. 937–948
2020
-
[57]
GPURepair: Automated repair of GPU kernels,
S. Joshi and G. Muduganti, “GPURepair: Automated repair of GPU kernels,” inProceedings of the 22nd International Conference on Verification, Model Checking, and Abstract Interpretation (VMCAI ’21). Springer, 2021, pp. 401–414. Appendix A. Reproducibility and Scope An anonymized Docker-first artifact is available at https://anonymous. 4open.science/r/warp-...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.