Real-Time Language Model Jamming: A Case Study for Live Music Accompaniment Generation
Pith reviewed 2026-06-27 08:20 UTC · model grok-4.3
The pith
StreamMUSE lets language models generate live music accompaniment that stays synchronized to an external performance signal through a client-server setup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present StreamMUSE, an inference system that performs LM generation in response to an external signal stream within a client-server architecture. The client continuously sends high-frequency inference requests based on the most recent inputs and receives outputs synchronized to the external clock, while the server executes model inference. We demonstrate the framework through a live music accompaniment task, showing how real-time synchronization can be achieved across different deployment environments with varying round-trip latencies. We further model the relationship between system hyperparameters and round-trip latency, and evaluate how different environments affect optimal configurati
What carries the argument
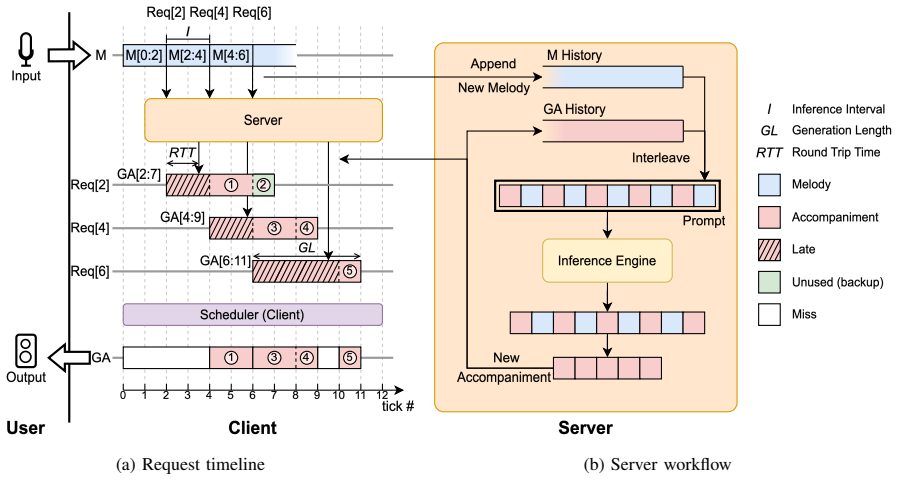
StreamMUSE client-server architecture, where the client issues high-frequency requests tied to the latest external signal and the server returns outputs locked to that external clock.
If this is right
- Real-time performance in the client-server loop produces measurably higher quality music accompaniment.
- Hyperparameters can be tuned against measured round-trip latency to reach workable real-time operation in different environments.
- The same synchronization approach applies to other tasks that need generation to match an external timing signal.
- Music quality tracks directly with how well the system meets its real-time constraints.
Where Pith is reading between the lines
- The method could support synchronized voice synthesis or translation if the external signal is speech rather than music.
- Deployment on edge devices versus cloud servers would likely require different hyperparameter mappings to the same latency target.
- If the correspondence between timing accuracy and output quality holds beyond music, it points to latency control as a general lever for streaming generative models.
Load-bearing premise
Continuous high-frequency client requests and server inference can keep precise frame-level timing with an external clock even when round-trip latencies fluctuate in real networks.
What would settle it
Measure generated accompaniment against the input signal in a live setup where network latency varies by more than a few frames; if the outputs drift out of time and music quality drops sharply, the synchronization claim fails.
Figures

read the original abstract
Language models (LMs) have become one of the most prominent paradigms in modern generative modeling. While making them faster has been the main focus of real-time deployment, speed alone is not enough. Many real-world applications, such as synchronized translation and voice synthesis, also require precise alignment between generation and external signals, both in terms of generation content and timing. We refer to this problem as \textit{frame-synchronous streaming inference}. To address it, we present StreamMUSE, an inference system that performs LM generation in response to an external signal stream within a client-server architecture. The client continuously sends high-frequency inference requests based on the most recent inputs and receives outputs synchronized to the external clock, while the server executes model inference. We demonstrate the framework through a live music accompaniment task, showing how real-time synchronization can be achieved across different deployment environments with varying round-trip latencies. We further model the relationship between system hyperparameters and round-trip latency, and evaluate how different environments affect optimal configurations to achieve real-time performance. Experimental results show a consistent correspondence between system real-time performance and music quality, demonstrating the effectiveness of the proposed framework. The project is open source. Relevant code and the latest updates are available at https://stream-muse-webpage.vercel.app/#audio-library.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents StreamMUSE, an inference system for performing language model generation in response to an external signal stream using a client-server architecture to achieve frame-synchronous streaming inference. Demonstrated on live music accompaniment generation, the client sends high-frequency requests based on recent inputs and receives outputs synchronized to an external clock, while the server handles model inference. The authors model the hyperparameter-round-trip latency relationship and evaluate optimal configurations across environments with varying latencies. They report a consistent correspondence between real-time performance and music quality, with the project being open source.
Significance. This work tackles the important problem of precise timing alignment in real-time LM applications, which is crucial for interactive scenarios like live music. The client-server design and latency modeling could provide valuable insights for deploying generative models in latency-sensitive environments. The open-source code enhances the potential impact by allowing community validation and extension.
major comments (2)
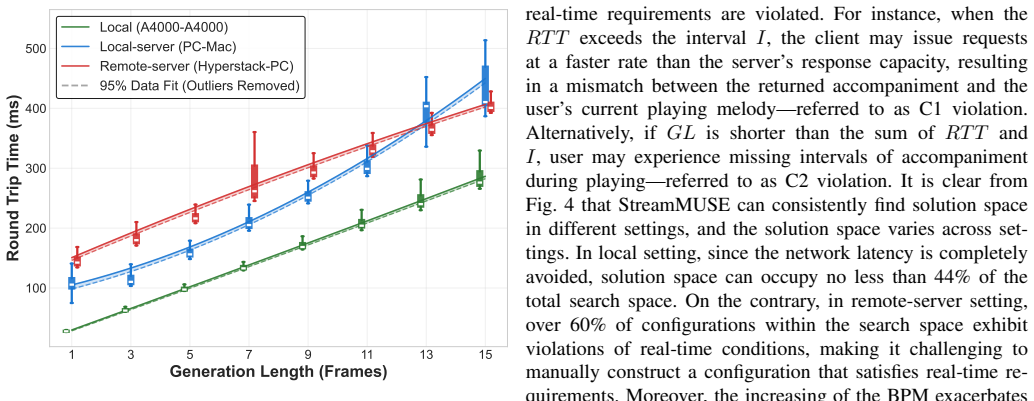
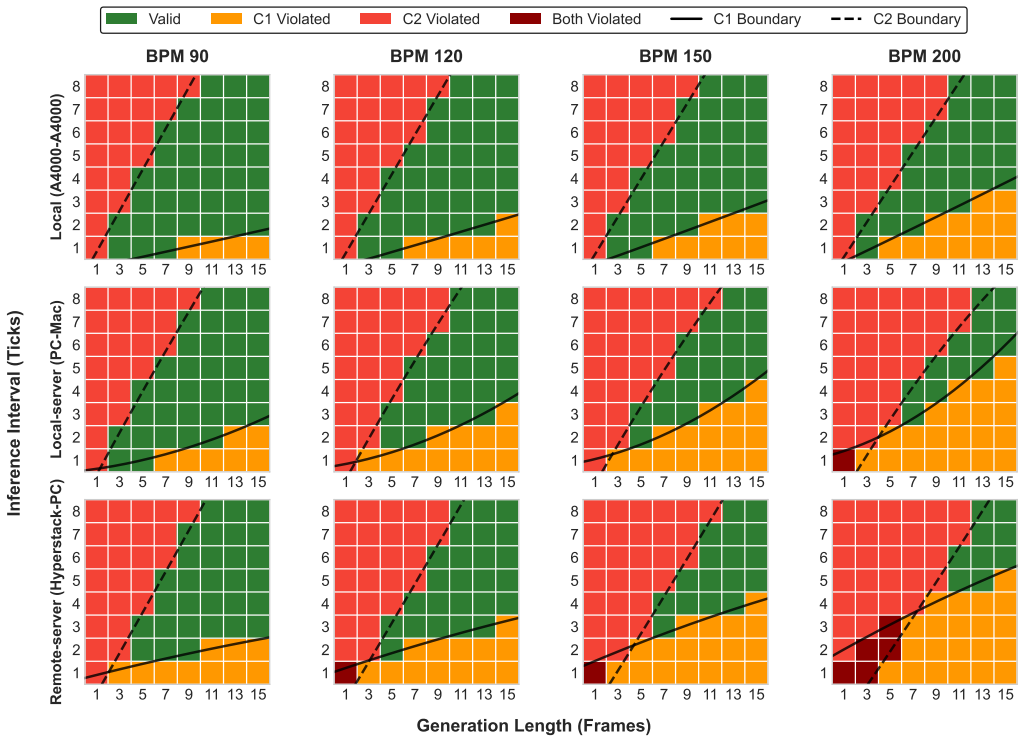
- [Experimental evaluation (referenced in abstract)] The central claim that 'experimental results show a consistent correspondence between system real-time performance and music quality' lacks any quantitative support (specific latency values, music quality metrics, correlation measures, error bars, or statistical tests). This prevents assessment of the effectiveness assertion and is load-bearing for the main contribution.
- [System architecture and client-server loop] The description of maintaining precise frame-level synchronization to an external clock despite varying RTT is high-level; the buffering, prediction logic, or compensation mechanisms are not detailed with equations, pseudocode, or timing diagrams. This is load-bearing for the frame-synchronous claim.
minor comments (2)
- [Abstract] The abstract states that the relationship between hyperparameters and latency is modeled but provides no equation, functional form, or key fitted parameters; adding a brief summary would improve clarity.
- Ensure the open-source link remains stable and that any accompanying audio examples are clearly linked to specific experimental conditions.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and outline revisions that will strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Experimental evaluation (referenced in abstract)] The central claim that 'experimental results show a consistent correspondence between system real-time performance and music quality' lacks any quantitative support (specific latency values, music quality metrics, correlation measures, error bars, or statistical tests). This prevents assessment of the effectiveness assertion and is load-bearing for the main contribution.
Authors: We acknowledge that the current manuscript presents the correspondence primarily through qualitative descriptions and example configurations rather than formal quantitative metrics. In the revision we will add tables reporting measured round-trip latencies across environments, quantitative music quality metrics (e.g., frame alignment error and mean opinion scores from listening tests), Pearson correlations between latency and quality, error bars, and appropriate statistical tests to substantiate the claim. revision: yes
-
Referee: [System architecture and client-server loop] The description of maintaining precise frame-level synchronization to an external clock despite varying RTT is high-level; the buffering, prediction logic, or compensation mechanisms are not detailed with equations, pseudocode, or timing diagrams. This is load-bearing for the frame-synchronous claim.
Authors: We agree that the synchronization mechanism requires more explicit technical detail. The revised manuscript will include a timing diagram of the client-server loop, pseudocode for the request-response and buffering logic, and equations formalizing the prediction horizon, clock alignment, and latency compensation strategy that together enable frame-synchronous output. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an inference system (StreamMUSE) for frame-synchronous LM generation in a client-server architecture, along with modeling of hyperparameter-latency relationships and experimental results showing correspondence between real-time metrics and music quality. No equations, derivations, fitted parameters presented as independent predictions, or load-bearing self-citations appear in the abstract or described claims. The central claims rest on architectural description and external experimental validation rather than any step that reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient and adaptive simultaneous speech translation with fully unidirectional architecture,
B. Fu, D. Yu, M. Liao, C. Li, X. Chen, Y . Chen, K. Fan, and X. Shi, “Efficient and adaptive simultaneous speech translation with fully unidirectional architecture,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 36, 2026, pp. 30 735–30 743
2026
-
[2]
Deep encoder, shallow decoder: Reevaluating non-autoregressive machine translation,
J. Kasai, N. Pappas, H. Peng, J. Cross, and N. A. Smith, “Deep encoder, shallow decoder: Reevaluating non-autoregressive machine translation,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[3]
Fastspeech 2: Fast and high-quality end-to-end text to speech,
Y . Ren, C. Hu, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y . Liu, “Fastspeech 2: Fast and high-quality end-to-end text to speech,” in International Conference on Learning Representations (ICLR), 2021
2021
-
[4]
Jukebox: A Generative Model for Music
P. Dhariwal, H. Jun, C. Payne, J. W. Kim, A. Radford, and I. Sutskever, “Jukebox: A generative model for music,” 2020. [Online]. Available: https://arxiv.org/abs/2005.00341
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
LaMDA: Language Models for Dialog Applications
R. Thoppilan, D. D. Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.-T. Cheng, A. Jin, T. Bos, L. Baker, Y . Du, Y . Li, H. Lee, H. S. Zheng, A. Ghafouri, M. Menegali, Y . Huang, M. Krikun, D. Lepikhin, J. Qin, D. Chen, Y . Xu, Z. Chen, A. Roberts, M. Bosma, V . Zhao, Y . Zhou, C.-C. Chang, I. Krivokon, W. Rusch, M. Pickett, P. Srinivasan, L. Man, K. Mei...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Blenderbot 3: a deployed conversational agent that continually learns to responsibly engage,
K. Shuster, J. Xu, M. Komeili, D. Ju, E. M. Smith, S. Roller, M. Ung, M. Chen, K. Arora, J. Lane, M. Behrooz, W. Ngan, S. Poff, N. Goyal, A. Szlam, Y .-L. Boureau, M. Kambadur, and J. Weston, “Blenderbot 3: a deployed conversational agent that continually learns to responsibly engage,” 2022. [Online]. Available: https://arxiv.org/abs/2208.03188
-
[7]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V . Le, G. E. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inInternational Conference on Learning Representations (ICLR), 2017. [Online]. Available: https://openreview.net/forum?id=B1ckMDqlg
2017
-
[8]
Efficient Memory Management for Large Language Model Serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23. New York, NY , USA: Association for Computing Machinery, 2023, pp. 611–626. [Online]. Availab...
-
[9]
Sglang: Efficient execution of structured language model programs,
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, C. Barrett, and Y . Sheng, “Sglang: Efficient execution of structured language model programs,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran ...
2024
-
[10]
Enhancing real- time inference performance for time-critical software-defined vehicles,
Sumaiya, R. Jafarpourmarzouni, S. Lu, and Z. Dong, “Enhancing real- time inference performance for time-critical software-defined vehicles,” in2024 IEEE International Conference on Mobility, Operations, Ser- vices and Technologies (MOST), 2024, pp. 101–113
2024
-
[11]
An on-line algorithm for real-time accompani- ment,
R. B. Dannenberg, “An on-line algorithm for real-time accompani- ment,” inProceedings of the International Computer Music Conference (ICMC), 1984, pp. 193–198
1984
-
[12]
Score following: State of the art and new developments,
N. Orio, S. Lemouton, and D. Schwarz, “Score following: State of the art and new developments,” inProceedings of the International Conference on New Interfaces for Musical Expression (NIME), 2003, pp. 36–41
2003
-
[13]
Frame-level Instrument Recognition by Timbre and Pitch
Y .-N. Hung and Y .-H. Yang, “Frame-level instrument recognition by timbre and pitch,” inProceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), 2018, pp. 135–142. [Online]. Available: https://arxiv.org/abs/1806.09587
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Generative timbre spaces: regularizing variational auto-encoders with perceptual metrics
P. Esling, A. Chemla-Romeu-Santos, and A. Bitton, “Generative timbre spaces: Regularizing variational auto-encoders with perceptual metrics,” inProceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), 2018, pp. 150–157. [Online]. Available: https://arxiv.org/abs/1805.08501
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Rowe,Interactive Music Systems: Machine Listening and Composing
R. Rowe,Interactive Music Systems: Machine Listening and Composing. Cambridge, MA: MIT Press, 1993
1993
-
[16]
The continuator: Musical interaction with style,
F. Pachet, “The continuator: Musical interaction with style,”Journal of New Music Research, vol. 32, no. 3, pp. 333–341, 2003
2003
-
[17]
A coupled duration-focused architecture for real-time music to score alignment,
A. Cont, “A coupled duration-focused architecture for real-time music to score alignment,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 6, pp. 974–987, 2010
2010
-
[18]
C.-Z. A. Huang, A. Vaswani, J. Uszkoreit, N. Shazeer, I. Simon, C. Hawthorne, A. M. Dai, M. D. Hoffman, M. Dinculescu, and D. Eck, “Music transformer: Generating music with long-term structure,” in International Conference on Learning Representations (ICLR), 2019, arXiv:1809.04281. [Online]. Available: https://arxiv.org/abs/1809.04281
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[19]
Multitrack music transformer,
H.-W. Dong, K. Chen, S. Dubnov, J. McAuley, and T. Berg-Kirkpatrick, “Multitrack music transformer,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
2023
-
[20]
Accomontage: Accompaniment arrangement via phrase selection and style transfer,
J. Zhao and G. Xia, “Accomontage: Accompaniment arrangement via phrase selection and style transfer,” 2021. [Online]. Available: https://archives.ismir.net/ismir2021/paper/000104.pdf
2021
-
[21]
Whole-song hierarchical generation of symbolic music using cascaded diffusion models,
Z. Wang, L. Min, and G. Xia, “Whole-song hierarchical generation of symbolic music using cascaded diffusion models,” inInternational Conference on Learning Representations (ICLR), 2024. [Online]. Available: https://openreview.net/forum?id=sn7CYWyavh
2024
-
[22]
Anticipatory music transformer,
J. Thickstun, D. Hall, C. Donahue, and P. Liang, “Anticipatory music transformer,”arXiv preprint arXiv:2306.08620, 2023
-
[23]
Rl-duet: Online music accompaniment generation using deep reinforcement learning,
N. Jiang, S. Jin, Z. Duan, and C. Zhang, “Rl-duet: Online music accompaniment generation using deep reinforcement learning,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 01, pp. 710–718, Apr. 2020. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/5413
2020
-
[24]
Bachduet: A deep learning system for human-machine counterpoint improvisation,
C. Benetatos, J. VanderStel, and Z. Duan, “Bachduet: A deep learning system for human-machine counterpoint improvisation,” in New Interfaces for Musical Expression, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:221668784
2020
-
[25]
Realjam: Real-time human-ai music jamming with reinforcement learning-tuned transformers,
A. Scarlatos, Y . Wu, I. Simon, A. Roberts, T. Cooijmans, N. Jaques, C. Tarakajian, and A. Huang, “Realjam: Real-time human-ai music jamming with reinforcement learning-tuned transformers,” inProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, ser. CHI EA ’25. New York, NY , USA: Association for Computing Mac...
-
[26]
The jam bot: A real-time system for collaborative free improvisation with music language models,
L. Blanchard, P. Naseck, S. Brade, K. Lecamwasam, J. Rudess, C.-Z. A. Huang, and J. Paradiso, “The jam bot: A real-time system for collaborative free improvisation with music language models,” inProceedings of the 26th International Society for Music Information Retrieval Conference (ISMIR), Daejeon, South Korea, 2025, mIT Media Lab and MIT Music Technolo...
-
[27]
Live music models,
A. Caillon, B. McWilliams, C. Tarakajian, I. Simon, I. Manco, J. Engel, N. Constant, Y . Li, T. I. Denk, A. Lalama, A. Agostinelli, C.-Z. A. Huang, E. Manilow, G. Brower, H. Erdogan, H. Lei, I. Rolnick, I. Grishchenko, M. Orsini, M. Kastelic, M. Zuluaga, M. Verzetti, M. Dooley, O. Skopek, R. Ferrer, Z. Borsos, A. van den Oord, D. Eck, E. Collins, J. M. Ba...
2025
-
[28]
Versatile symbolic music- for-music modeling via function alignment,
J. Jiang, D. Chin, L. Lin, X. Liu, and G. Xia, “Versatile symbolic music- for-music modeling via function alignment,” inProceedings of the 26th International Society for Music Information Retrieval Conference (ISMIR), 2025. [Online]. Available: https://arxiv.org/abs/2506.15548
-
[29]
Transformers: State-of- the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “Transformers: State-of- the-art natural language processing,” inProceedings of the 2020 Conference on Empirical Me...
2020
-
[30]
Efficiently scaling transformer inference,
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference,”Proceedings of machine learning and systems, vol. 5, pp. 606–624, 2023
2023
-
[31]
Pop909: A pop-song dataset for music arrangement generation,
Z. Wang*, K. Chen*, J. Jiang, Y . Zhang, M. Xu, S. Dai, G. Bin, and G. Xia, “Pop909: A pop-song dataset for music arrangement generation,” inProceedings of 21st International Conference on Music Information Retrieval, ISMIR, 2020
2020
-
[32]
Compound Word Transformer: Learning to compose full-song music over dynamic di- rected hypergraphs,
W.-Y . Hsiao, J.-Y . Liu, Y .-C. Yeh, and Y .-H. Yang, “Compound Word Transformer: Learning to compose full-song music over dynamic di- rected hypergraphs,” inThirty-Fifth AAAI Conference on Artificial Intelligence, AAAI, 2021
2021
-
[33]
Frechet music distance: A metric for generative symbolic music evaluation,
J. Retkowski, J. Stepniak, and M. Modrzejewski, “Frechet music distance: A metric for generative symbolic music evaluation,” 2024. [Online]. Available: https://arxiv.org/abs/2412.07948
-
[34]
Adaptive accompaniment with ReaLchords,
Y . Wu, T. Cooijmans, K. Kastner, A. Roberts, I. Simon, A. Scarlatos, C. Donahue, C. Tarakajian, S. Omidshafiei, A. Courville, P. S. Castro, N. Jaques, and C.-Z. A. Huang, “Adaptive accompaniment with ReaLchords,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, R. Salakhutdinov, Z. Kol...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.