Semantic Grading of Written Answers in Low-Resource Language Bangla Using a Fine-Tuned Lightweight Language Model
Pith reviewed 2026-06-27 09:30 UTC · model grok-4.3
The pith
A QLoRA-tuned Qwen3-8B model grades Bangla student answers with strong agreement to human scores by assessing semantic correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
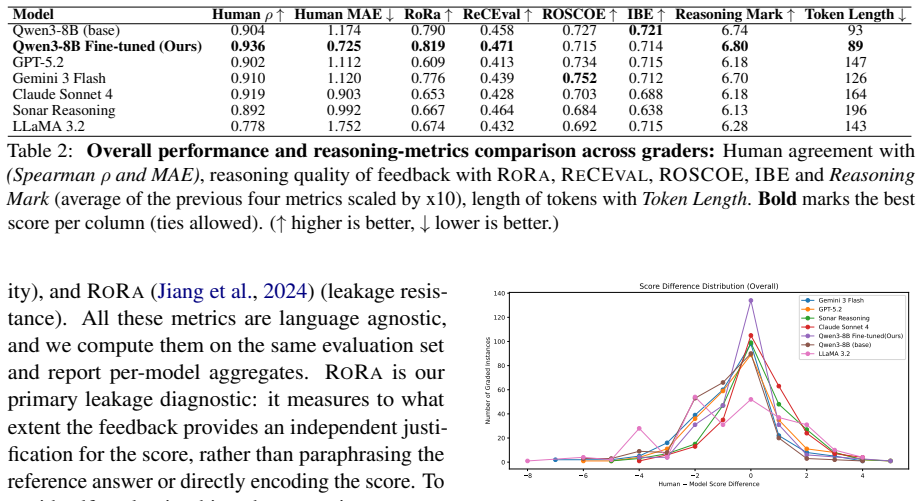
The paper claims that its QLoRA-tuned Qwen3-8B produces the most leakage-resistant feedback with RoRa of 0.819 in synthetic evaluation and the strongest agreement with human scores at rho of 0.936 and MAE of 0.725 in a human study, outperforming other models when grading Bangla answers for semantic correctness rather than surface overlap.
What carries the argument
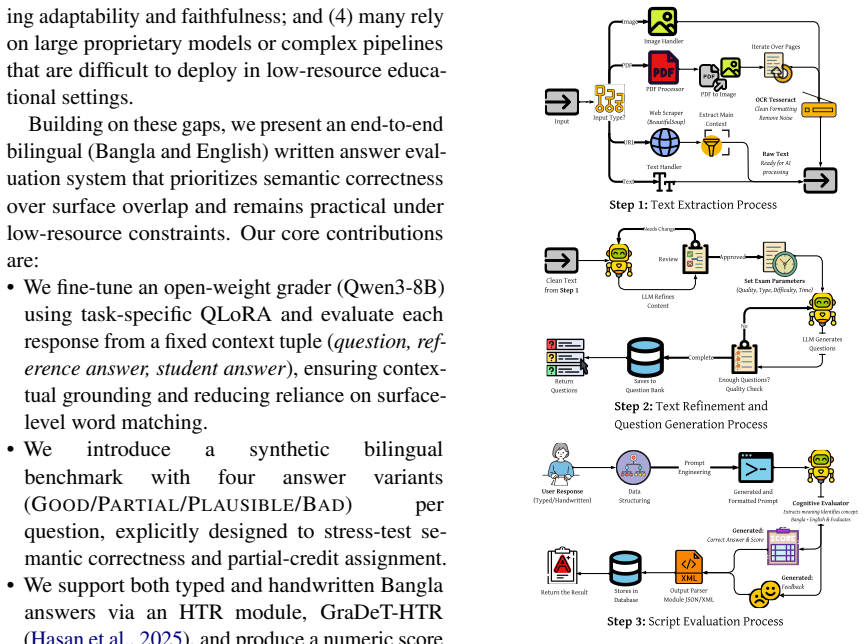
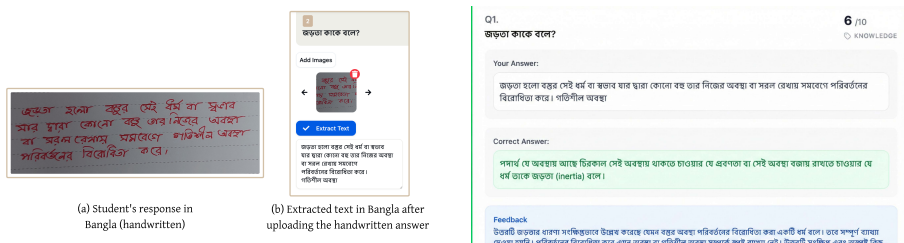
The QLoRA-tuned Qwen3-8B model, which receives the question, reference answer, and student answer as input and outputs a numeric score plus concise feedback.
If this is right
- Grading systems for Bangla can now prioritize meaning over exact wording and still reach high human agreement.
- Lightweight models become viable for deployment in remote regions once tuned on synthetic data.
- The same fine-tuning protocol can be applied across other open-source models to produce comparable feedback.
- Bilingual reference materials improve grading consistency when student answers mix languages.
Where Pith is reading between the lines
- The approach could extend to other low-resource languages by repeating the synthetic data construction step.
- Integration into mobile apps for teachers would allow faster initial scoring before final human review.
- Future work might test whether the same model maintains performance when questions come from different subjects.
Load-bearing premise
The synthetic bilingual dataset captures enough of the variety found in actual student answers for the measured performance to hold in real classrooms.
What would settle it
A follow-up study with several hundred real Bangla classroom answers graded independently by multiple teachers that shows agreement dropping below rho of 0.8.
Figures

read the original abstract
Bangla is among the world's most widely spoken languages, yet it remains underserved in educational NLP research. In many remote and rural regions, access to qualified subject teachers is limited, and written answers are consequently graded largely by hand, restricting timely and consistent feedback. Automatic assessment is challenging because semantically correct responses can vary substantially in surface form. We present a bilingual (Bangla-English) evaluation system designed for low-resource educational settings that prioritizes semantic correctness over lexical overlap. Our approach fine-tunes a lightweight language model to grade each response using the question, reference answer, and student answer, producing a numeric score and concise, context-grounded feedback suitable for classroom deployment. We also construct a synthetic bilingual dataset to enable controlled training and evaluation. Across proprietary and open-source LLMs evaluated under a unified protocol, our QLoRA-tuned Qwen3-8B confirms consistent improvement by producing the most leakage-resistant feedback (RoRa = 0.819) in synthetic evaluation and the strongest agreement with human scores (rho = 0.936, MAE = 0.725) in a dedicated human study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a bilingual (Bangla-English) system for semantic grading of student written answers in low-resource settings. It constructs a synthetic dataset, fine-tunes Qwen3-8B via QLoRA to score responses and generate feedback based on question, reference answer, and student answer, and reports that this model outperforms other LLMs with RoRa=0.819 leakage resistance on synthetic evaluation and strongest human agreement (rho=0.936, MAE=0.725) in a dedicated study, prioritizing semantic correctness.
Significance. If the synthetic dataset proves representative and the human-study results generalize, the work offers a deployable lightweight tool for consistent, timely feedback in Bangla classrooms where qualified teachers are scarce. The emphasis on leakage-resistant feedback and open-source model choice are practical strengths for low-resource NLP in education.
major comments (2)
- [Dataset construction] Dataset construction section: no quantitative validation (overlap statistics, error-type coverage, length/topic distributions) is provided between the synthetic bilingual answers and real student responses from Bangla classrooms. This directly undermines transferability of both the RoRa=0.819 leakage result and the human-agreement metrics to the claimed classroom use case.
- [Human study] Human study section: the study is labeled only as 'dedicated' with no reported scale (number of answers/graders), inter-rater agreement (e.g., Cohen's kappa), sampling frame, or exclusion criteria. These omissions make the rho=0.936 / MAE=0.725 figures impossible to interpret for reliability or statistical significance.
minor comments (2)
- [Abstract] Abstract: the 'unified protocol' for comparing proprietary and open-source LLMs is not summarized; adding one sentence on prompt format, temperature, and scoring rubric would improve clarity.
- [Evaluation metrics] Evaluation: RoRa is introduced without an explicit formula or reference; a short definition or equation in the metrics subsection would prevent reader confusion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments identify clear gaps in reporting that affect interpretability and generalizability. We address each point below and will revise the manuscript to incorporate the requested information where feasible.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: no quantitative validation (overlap statistics, error-type coverage, length/topic distributions) is provided between the synthetic bilingual answers and real student responses from Bangla classrooms. This directly undermines transferability of both the RoRa=0.819 leakage result and the human-agreement metrics to the claimed classroom use case.
Authors: We acknowledge that the current manuscript provides no quantitative comparison between the synthetic dataset and real Bangla classroom responses. The synthetic data was generated to control for specific semantic variations and error patterns, enabling the leakage-resistance evaluation (RoRa). However, the referee is correct that this limits claims about transfer to real classrooms. In the revised manuscript we will add a dedicated subsection under Dataset Construction that reports overlap statistics, error-type coverage, length and topic distributions, using any available real student answer samples. If real data access is limited, we will explicitly note the scope of the comparison. revision: yes
-
Referee: [Human study] Human study section: the study is labeled only as 'dedicated' with no reported scale (number of answers/graders), inter-rater agreement (e.g., Cohen's kappa), sampling frame, or exclusion criteria. These omissions make the rho=0.936 / MAE=0.725 figures impossible to interpret for reliability or statistical significance.
Authors: We agree that the human-study description is insufficient. The manuscript reports only the aggregate metrics without the underlying study parameters. In the revision we will expand the Human Study section to include the number of answers and graders, inter-rater agreement (Cohen's kappa or equivalent), sampling frame, exclusion criteria, and any power or significance considerations for the reported rho and MAE. These details were collected during the study and will be added for transparency. revision: yes
Circularity Check
No circularity; purely empirical evaluation
full rationale
The paper reports fine-tuning results (QLoRA on Qwen3-8B) and empirical metrics (RoRa on synthetic data, Spearman rho and MAE on human scores) with no equations, derivations, or parameter-fitting steps that reduce to inputs by construction. Dataset construction and evaluation are described as standard supervised training plus held-out testing; no self-citation load-bearing, uniqueness theorems, or ansatz smuggling appear. The central claims rest on direct comparison to external human judgments and leakage metrics rather than any definitional or fitted-input reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mahmudul and Choudhury, Ahmed Nesar Tahsin and Hasan, Mahmudul and Khan, Md Mosaddek
Hasan, Md. Mahmudul and Choudhury, Ahmed Nesar Tahsin and Hasan, Mahmudul and Khan, Md Mosaddek. G ra D e T - HTR : A Resource-Efficient B engali Handwritten Text Recognition System utilizing Grapheme-based Tokenizer and Decoder-only Transformer. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations....
-
[2]
Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , pages =
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[3]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[4]
Towards a Unified Multi-Dimensional Evaluator for Text Generation
Zhong, Ming and Liu, Yang and Yin, Da and Mao, Yuning and Jiao, Yizhu and Liu, Pengfei and Zhu, Chenguang and Ji, Heng and Han, Jiawei. Towards a Unified Multi-Dimensional Evaluator for Text Generation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.131
-
[5]
Yang Liu and Dan Iter and Yichong Xu and Shuohang Wang and Ruochen Xu and Chenguang Zhu , booktitle=. G-Eval:. 2023 , url=
2023
-
[6]
ChatEval: Towards Better
Chi-Min Chan and Weize Chen and Yusheng Su and Jianxuan Yu and Wei Xue and Shanghang Zhang and Jie Fu and Zhiyuan Liu , booktitle=. ChatEval: Towards Better. 2024 , url=
2024
-
[7]
Filighera, Anna and Parihar, Siddharth and Steuer, Tim and Meuser, Tobias and Ochs, Sebastian. Your Answer is Incorrect... Would you like to know why? Introducing a Bilingual Short Answer Feedback Dataset. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.587
-
[8]
Handbook of Automated Essay Evaluation: Current Applications and New Directions , editor =
Automated Essay Scoring and Writing Assessment , author =. Handbook of Automated Essay Evaluation: Current Applications and New Directions , editor =
-
[9]
Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013) , year =
SemEval-2013 Task 7: The Joint Student Response Analysis and 8th Recognizing Textual Entailment Challenge , author =. Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013) , year =
2013
-
[10]
International Journal of Artificial Intelligence in Education , volume =
The Eras and Trends of Automatic Short Answer Grading , author =. International Journal of Artificial Intelligence in Education , volume =. 2015 , publisher =
2015
-
[11]
Proceedings of NAACL , year=
Leveraging Context Information for Natural Question Generation , author=. Proceedings of NAACL , year=
-
[12]
Proceedings of ACL , year=
Harvesting Paragraph-Level Question-Answer Pairs from Wikipedia , author=. Proceedings of ACL , year=
-
[13]
Proceedings of EMNLP , year=
Asking Questions Like Educational Experts , author=. Proceedings of EMNLP , year=
-
[14]
2023 , url =
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =. 2023 , url =
2023
-
[15]
arXiv preprint arXiv:2106.09685 , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. arXiv preprint arXiv:2106.09685 , year=
-
[16]
RORA : Robust Free-Text Rationale Evaluation
Jiang, Zhengping and Lu, Yining and Chen, Hanjie and Khashabi, Daniel and Van Durme, Benjamin and Liu, Anqi. RORA : Robust Free-Text Rationale Evaluation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.60
-
[17]
Gong, Jiefu and Hu, Xiao and Song, Wei and Fu, Ruiji and Sheng, Zhichao and Zhu, Bo and Wang, Shijin and Liu, Ting. IF ly EA : A C hinese Essay Assessment System with Automated Rating, Review Generation, and Recommendation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference o...
-
[18]
Automatic Comment Generation for C hinese Student Narrative Essays
Zhang, Zhexin and Guan, Jian and Xu, Guowei and Tian, Yixiang and Huang, Minlie. Automatic Comment Generation for C hinese Student Narrative Essays. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2022. doi:10.18653/v1/2022.emnlp-demos.21
-
[19]
PEEP -Talk: A Situational Dialogue-based Chatbot for E nglish Education
Lee, Seungjun and Jang, Yoonna and Park, Chanjun and Lee, Jungseob and Seo, Jaehyung and Moon, Hyeonseok and Eo, Sugyeong and Lee, Seounghoon and Yahya, Bernardo and Lim, Heuiseok. PEEP -Talk: A Situational Dialogue-based Chatbot for E nglish Education. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: Syst...
-
[20]
Bengali language , author =
-
[21]
Bangladesh: Selected Indicators , author =
-
[22]
km of land area) --- Bangladesh , author =
Population density (people per sq. km of land area) --- Bangladesh , author =
-
[23]
World Development Indicators: Bangladesh (DataBank view) , author =
-
[24]
Understanding networked family language policy: a study among Bengali immigrants in Australia , volume =
Bose, Priyanka and Gao, Xuesong and Starfield, Sue and Perera, Nirukshi , year =. Understanding networked family language policy: a study among Bengali immigrants in Australia , volume =. Current Issues in Language Planning , doi =
-
[25]
2025 , howpublished =
What are the 10 largest / most spoken languages in the world? , author =. 2025 , howpublished =
2025
-
[26]
The American Journal of Psychology , volume =
The Proof and Measurement of Association between Two Things , author =. The American Journal of Psychology , volume =. 1904 , url =
1904
-
[27]
R e CE val: Evaluating Reasoning Chains via Correctness and Informativeness
Prasad, Archiki and Saha, Swarnadeep and Zhou, Xiang and Bansal, Mohit. R e CE val: Evaluating Reasoning Chains via Correctness and Informativeness. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.622
-
[28]
2023 , url=
Olga Golovneva and Moya Peng Chen and Spencer Poff and Martin Corredor and Luke Zettlemoyer and Maryam Fazel-Zarandi and Asli Celikyilmaz , booktitle=. 2023 , url=
2023
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Inference to the Best Explanation in Large Language Models , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[30]
Climate Research , volume =
Advantages of the Mean Absolute Error (MAE) over the Root Mean Square Error (RMSE) in Assessing Average Model Performance , author =. Climate Research , volume =. 2005 , doi =
2005
-
[31]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , month = jun, year =. doi:10.18653/v1/N18-1101 , url =
work page internal anchor Pith review doi:10.18653/v1/n18-1101 2018
-
[32]
Lewis, Mike and Liu, Yinhan and Goyal, Naman and Ghazvininejad, Marjan and Mohamed, Abdelrahman and Levy, Omer and Stoyanov, Ves and Zettlemoyer, Luke , booktitle =. 2020 , address =. doi:10.18653/v1/2020.acl-main.703 , url =
-
[33]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna , booktitle =. Sentence-. 2019 , address =. doi:10.18653/v1/D19-1410 , url =
-
[34]
2020 , url =
Song, Kaitao and Tan, Xu and Qin, Tao and Lu, Jianfeng and Liu, Tie-Yan , booktitle =. 2020 , url =
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.