uva-irlab-conv at SemEval-2026 Task 8: Multi-Turn RAG with Learned Sparse Retrieval and Listwise Reranking
Pith reviewed 2026-06-27 10:11 UTC · model grok-4.3
The pith
A multi-turn RAG pipeline uses learned sparse retrieval and LLM listwise reranking to integrate full conversation history across four domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The multi-step design enables effective integration of conversational context throughout retrieval and generation, improving robustness across domains.
What carries the argument
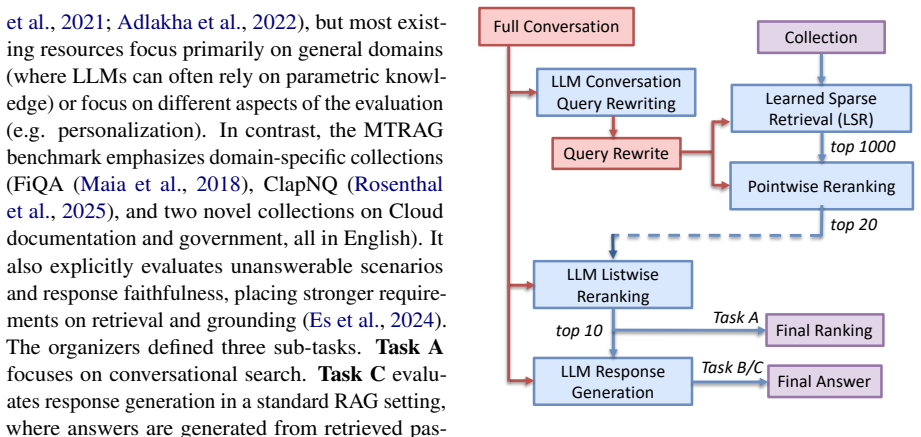
Multi-turn retrieval-augmented generation pipeline that applies learned sparse retrieval first, then LLM-based query rewriting, pointwise and listwise reranking, and final generation, each conditioned on full conversational history.
If this is right
- Sparse retrieval serves as the primary method because it generalizes without per-domain training.
- LLM long-context handling allows rewriting, reranking, and generation to use the entire conversation history at once.
- The pipeline can identify unanswerable queries by checking whether retrieved evidence is sufficient.
- Listwise reranking selects better passages than retrieval scores alone for the generation step.
Where Pith is reading between the lines
- The same staged pipeline could be tested on other conversational retrieval benchmarks that include unanswerable questions.
- Removing any single LLM step (rewriting or listwise reranking) and measuring the drop would isolate which component drives the claimed robustness.
- The approach leaves open whether the same gains appear when the underlying LLM is smaller or when retrieval is restricted to shorter contexts.
Load-bearing premise
Learned sparse retrieval generalizes strongly across the four domains without domain-specific adaptation and LLM listwise reranking measurably improves end-to-end performance.
What would settle it
Measurements on the task test set showing that a domain-adapted dense retriever or a simpler pointwise reranker produces higher final answer quality than the reported pipeline on at least two of the four domains.
Figures
read the original abstract
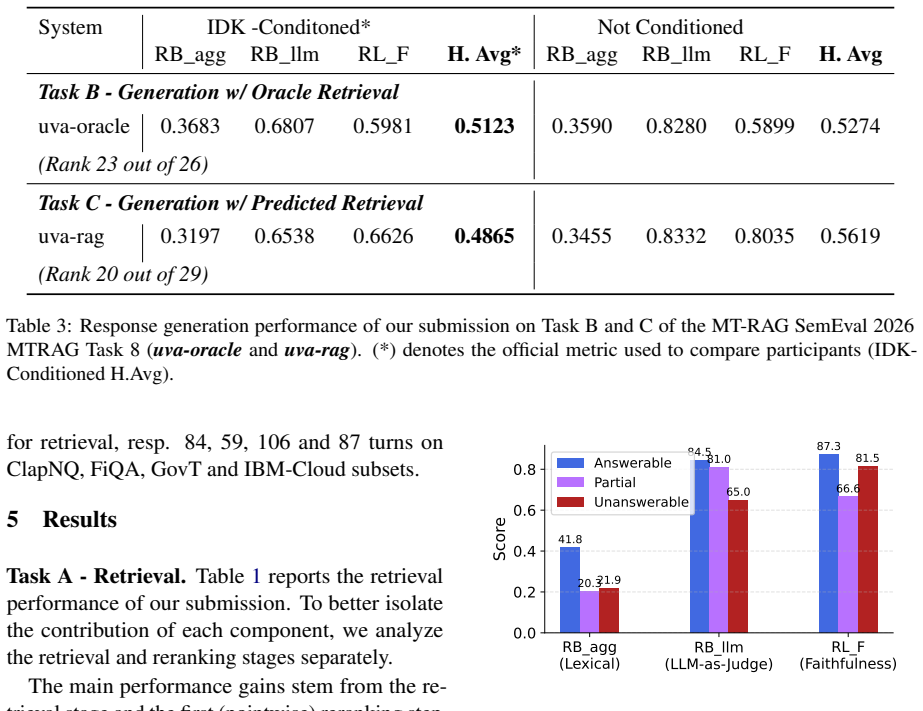
This report describes our participation in SemEval-2026 Task 8 on multi-turn retrieval and question answering. The task evaluates conversational systems across four domains (finance, cloud documentation, government, Wikipedia), and includes unanswerable queries where the available collection does not contain sufficient evidence to produce a complete response. We propose a multi-turn retrieval-augmented generation pipeline that combines learned sparse retrieval with LLM-based reranking and generation. Using sparse retrieval as the primary retrieval method, we leverage its strong generalization across domains. In addition, we make use of the long-context capabilities of LLMs for conversational query rewriting, pointwise and listwise reranking, and generating the final response, each conditioned on the full conversational history. This multi-step design enables effective integration of conversational context throughout retrieval and generation, improving robustness across domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes the uva-irlab-conv participation in SemEval-2026 Task 8 on multi-turn retrieval-augmented generation and QA. It proposes a pipeline that uses learned sparse retrieval as the primary retriever, combined with LLM-based conversational query rewriting, pointwise and listwise reranking, and final answer generation, all conditioned on full conversational history, and claims that this design enables effective context integration and improves robustness across the four evaluation domains (finance, cloud documentation, government, Wikipedia) while handling unanswerable queries.
Significance. If the claimed robustness gains were demonstrated through evaluation, the work would provide a concrete example of combining sparse retrieval generalization with LLM context handling for conversational QA; however, the complete absence of any metrics, ablations, or comparisons leaves the significance of the design choices unevaluated.
major comments (2)
- [Abstract] Abstract: the assertion that the multi-step design 'improves robustness across domains' is load-bearing for the paper's contribution yet is unsupported by any retrieval metrics (e.g., nDCG, recall), ablation results, baseline comparisons (dense retrieval, single-turn systems), or per-domain breakdowns, rendering the generalization and improvement claims unevaluable.
- [The manuscript as a whole] The manuscript provides no experimental section or results table reporting official task scores, comparison against other participants, or analysis of the contribution of listwise reranking versus pointwise reranking or full-history conditioning.
minor comments (2)
- [Abstract] The description of the four domains and the unanswerable-query handling would be clearer if accompanied by concrete examples of query rewriting or reranking prompts.
- Standard SemEval system papers typically include the team's official ranking and primary metric values; their omission here weakens the report's utility to the shared-task community.
Simulated Author's Rebuttal
We thank the referee for the feedback on our system description paper. We address the major comments point by point below, noting that this is a concise participation report for a shared task.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the multi-step design 'improves robustness across domains' is load-bearing for the paper's contribution yet is unsupported by any retrieval metrics (e.g., nDCG, recall), ablation results, baseline comparisons (dense retrieval, single-turn systems), or per-domain breakdowns, rendering the generalization and improvement claims unevaluable.
Authors: We agree that the abstract makes an unsupported claim about robustness improvements. The statement was intended to reflect the design rationale—leveraging learned sparse retrieval for cross-domain generalization and LLM conditioning on full history—but no quantitative evidence is provided in the manuscript. We will revise the abstract to remove this claim and describe the pipeline components without asserting empirical gains. revision: yes
-
Referee: [The manuscript as a whole] The manuscript provides no experimental section or results table reporting official task scores, comparison against other participants, or analysis of the contribution of listwise reranking versus pointwise reranking or full-history conditioning.
Authors: This manuscript is a system description focused on the pipeline architecture rather than a full experimental study. Official task scores are aggregated in the SemEval task overview rather than individual reports, and we did not run the requested ablations or comparisons during participation. We will add a brief results section reporting any available official scores in revision, but component-level analysis is not available from our work. revision: partial
- The manuscript contains no experimental results, metrics, ablations, or comparisons, which prevents providing the requested evidence or analysis.
Circularity Check
No circularity; purely descriptive system report with no derivations or fitted predictions
full rationale
The paper is a participation report for a SemEval shared task. It describes a retrieval-augmented generation pipeline using learned sparse retrieval, LLM query rewriting, pointwise/listwise reranking, and response generation, all conditioned on conversational history. No equations, parameters, derivations, or quantitative predictions appear in the provided text. Claims about generalization and robustness are presented as design motivations rather than results derived from prior steps within the paper. No self-citations, ansatzes, or renamings reduce any claim to its own inputs by construction. The work is self-contained as an engineering description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 34th Text REtrieval Conference (TREC 2025)(NIST SP xxxx)
UvAIRLab at iKAT25: Exploring Learned Sparse Retrieval and Query Rewriting for Personalized Conversational QA , author=. Proceedings of the 34th Text REtrieval Conference (TREC 2025)(NIST SP xxxx). Gaithersburg, Maryland , year=
2025
-
[2]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[3]
The Twelfth International Conference on Learning Representations , year=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. The Twelfth International Conference on Learning Representations , year=
-
[4]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[5]
Bruce Croft, Erik Learned-Miller, and Jaap Kamps
Zamani, Hamed and Dehghani, Mostafa and Croft, W. Bruce and Learned-Miller, Erik and Kamps, Jaap , title =. Proceedings of the 27th ACM International Conference on Information and Knowledge Management , pages =. 2018 , isbn =. doi:10.1145/3269206.3271800 , abstract =
-
[6]
Companion proceedings of the the web conference 2018 , pages=
Www'18 open challenge: financial opinion mining and question answering , author=. Companion proceedings of the the web conference 2018 , pages=
2018
-
[7]
Transactions of the Association for Computational Linguistics , volume=
CLAPnq: C ohesive L ong-form A nswers from P assages in Natural Questions for RAG systems , author=. Transactions of the Association for Computational Linguistics , volume=. 2025 , publisher=
2025
-
[8]
Proceedings of the 14th ACM international conference on web search and data mining , pages=
Question rewriting for conversational question answering , author=. Proceedings of the 14th ACM international conference on web search and data mining , pages=
-
[9]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Is ChatGPT good at search? investigating large language models as re-ranking agents , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[10]
Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval , pages=
Conversational information seeking: Theory and application , author=. Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[11]
Transactions of the Association for Computational Linguistics , volume=
Evaluating correctness and faithfulness of instruction-following models for question answering , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[12]
RAD-Bench: Evaluating large language models’ capabilities in retrieval augmented dialogues , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track) , pages=
2025
-
[13]
IR Evaluation Methods for Retrieving Highly Relevant Documents , booktitle =
J\". IR Evaluation Methods for Retrieving Highly Relevant Documents , booktitle =. 2000 , isbn =. doi:10.1145/345508.345545 , acmid =
-
[14]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Efficient inverted indexes for approximate retrieval over learned sparse representations , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[15]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=
-
[16]
2025 , institution=
How people use ChatGPT , author=. 2025 , institution=
2025
-
[17]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[18]
arXiv preprint arXiv:2601.13115 , year=
Agentic Conversational Search with Contextualized Reasoning via Reinforcement Learning , author=. arXiv preprint arXiv:2601.13115 , year=
-
[19]
U ni C onv: Unifying Retrieval and Response Generation for Large Language Models in Conversations
Mo, Fengran and Gao, Yifan and Meng, Chuan and Liu, Xin and Wu, Zhuofeng and Mao, Kelong and Wang, Zhengyang and Chen, Pei and Li, Zheng and Li, Xian and Yin, Bing and Jiang, Meng. U ni C onv: Unifying Retrieval and Response Generation for Large Language Models in Conversations. Proceedings of the 63rd Annual Meeting of the Association for Computational L...
-
[20]
arXiv preprint arXiv:2510.13312 , year=
Chatr1: Reinforcement learning for conversational reasoning and retrieval augmented question answering , author=. arXiv preprint arXiv:2510.13312 , year=
-
[21]
Investigating LLM Variability in Personalized Conversational Information Retrieval , year =
Lupart, Simon and van Dijk, Dani\". Investigating LLM Variability in Personalized Conversational Information Retrieval , year =. Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages =. doi:10.1145/3767695.3769502 , abstract =
-
[22]
Nguyen, Thong and MacAvaney, Sean and Yates, Andrew , title =. Advances in Information Retrieval: 45th European Conference on Information Retrieval, ECIR 2023, Dublin, Ireland, April 2–6, 2023, Proceedings, Part III , pages =. 2023 , isbn =. doi:10.1007/978-3-031-28241-6_7 , abstract =
-
[23]
Zeng, Hansi and Killingback, Julian and Zamani, Hamed , title =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2025 , isbn =. doi:10.1145/3726302.3730225 , abstract =
-
[24]
Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St\'. From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective , year =. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. doi:10.1145/3477495.3531857 , abstract =
-
[25]
arXiv preprint arXiv:2312.10997 , volume=
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
-
[26]
Can You Unpack That? Learning to Rewrite Questions-in-Context
Elgohary, Ahmed and Peskov, Denis and Boyd-Graber, Jordan. Can You Unpack That? Learning to Rewrite Questions-in-Context. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1605
-
[27]
Yu, Shi and Liu, Zhenghao and Xiong, Chenyan and Feng, Tao and Liu, Zhiyuan , title =. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2021 , isbn =. doi:10.1145/3404835.3462856 , abstract =
-
[28]
Embracing Plasticity: Balancing Stability and Plasticity in Continual Recommender Systems
Lupart, Simon and Aliannejadi, Mohammad and Kanoulas, Evangelos , title =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2025 , isbn =. doi:10.1145/3726302.3729966 , abstract =
-
[29]
arXiv preprint arXiv:2411.14739 , year=
IRLab@ iKAT24: Learned Sparse Retrieval with Multi-aspect LLM Query Generation for Conversational Search , author=. arXiv preprint arXiv:2411.14739 , year=
-
[30]
arXiv preprint arXiv:2403.19302 , year=
Generating Multi-Aspect Queries for Conversational Search , author=. arXiv preprint arXiv:2403.19302 , year=
-
[31]
arXiv preprint arXiv:2406.05013 , year=
CHIQ: Contextual History Enhancement for Improving Query Rewriting in Conversational Search , author=. arXiv preprint arXiv:2406.05013 , year=
-
[32]
Mao, Kelong and Dou, Zhicheng and Mo, Fengran and Hou, Jiewen and Chen, Haonan and Qian, Hongjin. Large Language Models Know Your Contextual Search Intent: A Prompting Framework for Conversational Search. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.86
-
[33]
RAGA s: Automated Evaluation of Retrieval Augmented Generation
Es, Shahul and James, Jithin and Espinosa Anke, Luis and Schockaert, Steven. RAGA s: Automated Evaluation of Retrieval Augmented Generation. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. 2024. doi:10.18653/v1/2024.eacl-demo.16
-
[34]
Open-Domain Question Answering Goes Conversational via Question Rewriting
Anantha, Raviteja and Vakulenko, Svitlana and Tu, Zhucheng and Longpre, Shayne and Pulman, Stephen and Chappidi, Srinivas. Open-Domain Question Answering Goes Conversational via Question Rewriting. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18...
-
[35]
T opi OCQA : Open-domain Conversational Question Answering with Topic Switching
Adlakha, Vaibhav and Dhuliawala, Shehzaad and Suleman, Kaheer and de Vries, Harm and Reddy, Siva. T opi OCQA : Open-domain Conversational Question Answering with Topic Switching. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00471
-
[36]
Formal, Thibault and Piwowarski, Benjamin and Clinchant, St\'. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2021 , isbn =. doi:10.1145/3404835.3463098 , abstract =
-
[37]
Text Retrieval Conference , year=
CAsT 2020: The Conversational Assistance Track Overview , author=. Text Retrieval Conference , year=
2020
-
[38]
Aliannejadi, Mohammad and Abbasiantaeb, Zahra and Chatterjee, Shubham and Dalton, Jeffrey and Azzopardi, Leif , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , isbn =. doi:10.1145/3626772.3657860 , abstract =
-
[39]
Abbasiantaeb, Zahra and Lupart, Simon and Azzopardi, Leif and Dalton, Jeffrey and Aliannejadi, Mohammad , title =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2025 , isbn =. doi:10.1145/3726302.3730316 , abstract =
-
[40]
SIGIR Forum , volume=
User simulation in practice: Lessons learned from three shared tasks , author=. SIGIR Forum , volume=
-
[41]
2026 , url=
Philippe Laban and Hiroaki Hayashi and Yingbo Zhou and Jennifer Neville , booktitle=. 2026 , url=
2026
-
[42]
Radlinski, Filip and Craswell, Nick , title =. Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval , pages =. 2017 , isbn =. doi:10.1145/3020165.3020183 , abstract =
-
[43]
2026 , eprint=
MTRAG-UN: A Benchmark for Open Challenges in Multi-Turn RAG Conversations , author=. 2026 , eprint=
2026
-
[44]
Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026) , address=
SemEval-2026 Task 8: MTRAGEval: Evaluating Multi-Turn RAG Conversations , author=. Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026) , address=. 2026 , organization=
2026
-
[45]
Mekonnen, Kidist Amde and Tang, Yubao and de Rijke, Maarten , title =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2025 , isbn =. doi:10.1145/3726302.3730023 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.