ViT-FREE: Efficient Face Recognition via Early Exiting and Synthetic Adaptation
Pith reviewed 2026-06-27 09:49 UTC · model grok-4.3
The pith
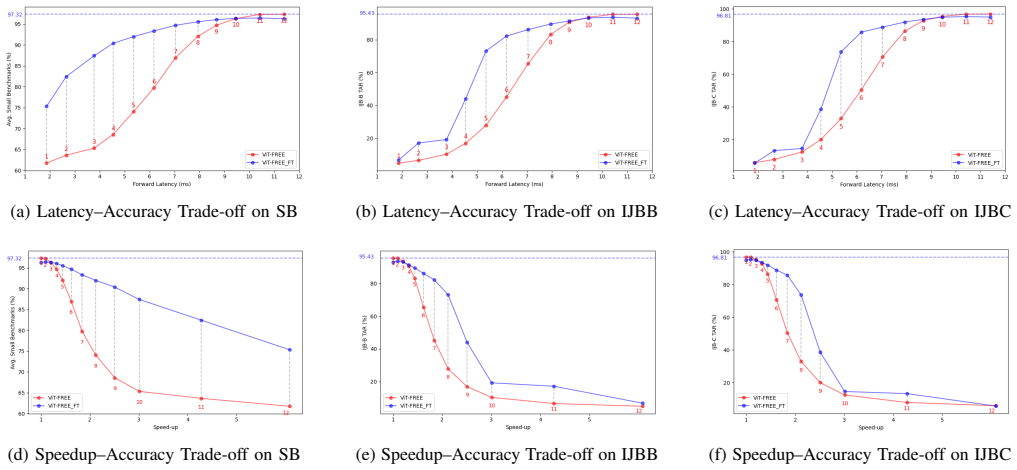
Exiting at layer 10 of a pretrained Vision Transformer speeds up face recognition by 20 percent with a 1.5 point accuracy drop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
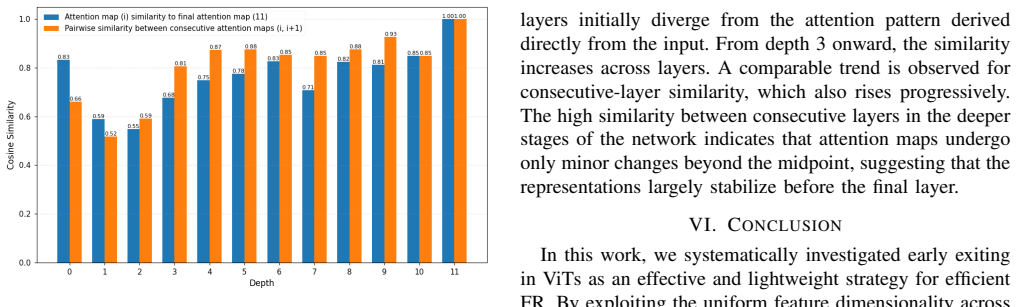
Pretrained ViTs for face recognition exhibit gradual feature refinement where patch embeddings and attention maps become increasingly aligned with the final representation, allowing direct verification from intermediate blocks via a training-free multi-exit framework.
What carries the argument
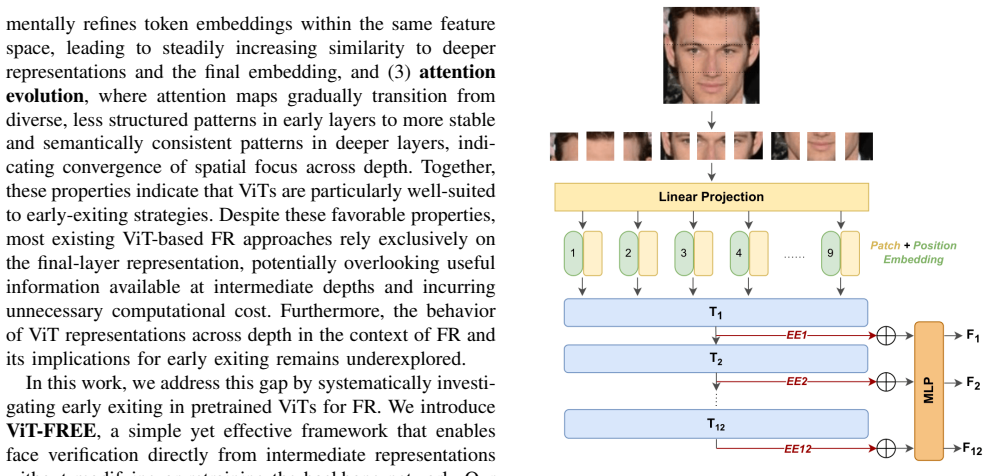
The ViT-FREE multi-exit framework that uses intermediate transformer encoder outputs for face verification without altering the backbone model.
If this is right
- Later exits provide better accuracy while still reducing inference cost compared to full model.
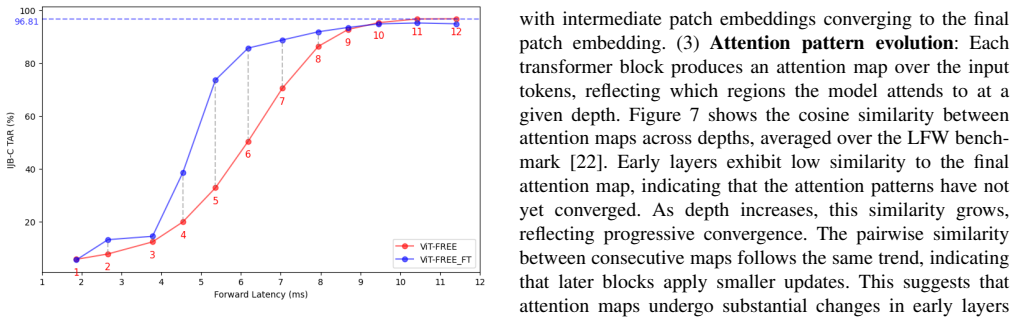
- Exiting at layer 10 achieves up to 20% speedup on IJB-C with 1.5 drop in performance.
- ViT-FREE_FT with synthetic data adaptation improves shallow exits without affecting deeper ones or the backbone.
- Uniform feature dimensionality across blocks enables attachment of verification heads at any depth.
Where Pith is reading between the lines
- Similar early-exit logic could apply to ViT models in other vision tasks like object detection or segmentation.
- Dynamic exiting per image based on confidence at early layers might further improve average speed.
- The progressive convergence suggests that ViT depth is over-provisioned for many face recognition cases.
Load-bearing premise
Intermediate layers produce representations stable and discriminative enough for face verification because embeddings and attention maps align progressively with the final output.
What would settle it
An experiment on IJB-C or similar benchmark where the verification performance at layer 10 drops by more than 3 points compared to the full model would challenge the claimed trade-off.
Figures
read the original abstract
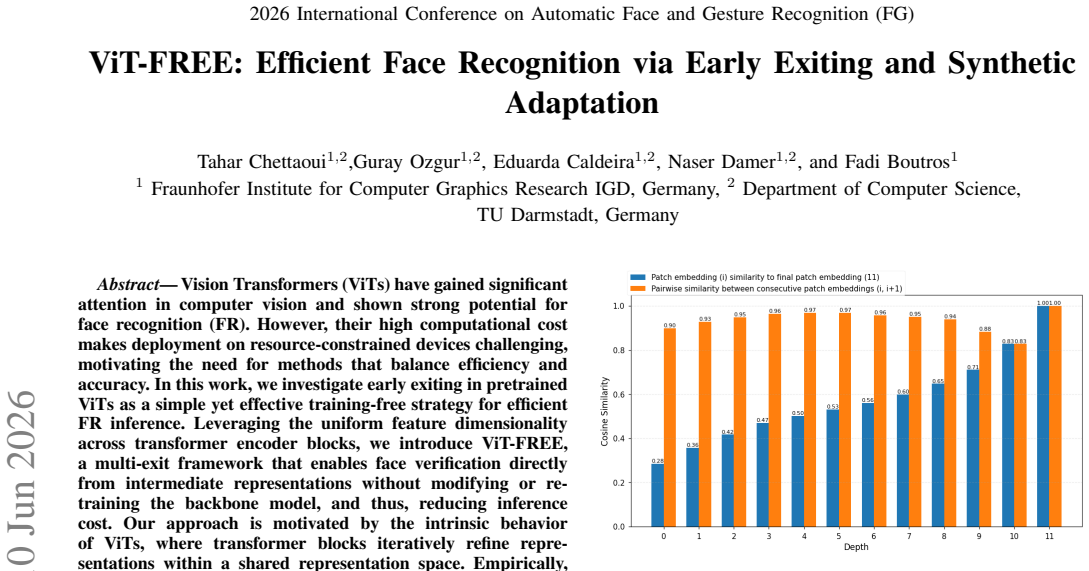
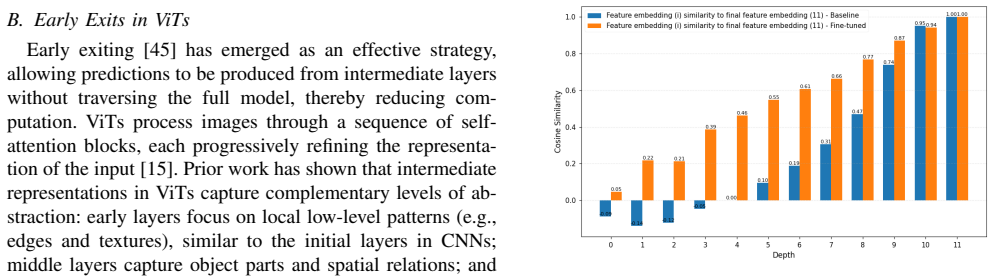
Vision Transformers (ViTs) have gained significant attention in computer vision and shown strong potential for face recognition (FR). However, their high computational cost makes deployment on resource-constrained devices challenging, motivating the need for methods that balance efficiency and accuracy. In this work, we investigate early exiting in pretrained ViTs as a simple yet effective training-free strategy for efficient FR inference. Leveraging the uniform feature dimensionality across transformer encoder blocks, we introduce ViT-FREE, a multi-exit framework that enables face verification directly from intermediate representations without modifying or retraining the backbone model, and thus, reducing inference cost. Empirically, we show that patch embeddings and attention maps evolve progressively across depth, exhibiting high similarity between consecutive ViT blocks and increasing alignment with the final representation. This indicates gradual feature refinement and attention convergence, suggesting that intermediate layers already provide stable and discriminative representations suitable for early exiting. Through extensive experiments on multiple FR benchmarks, we systematically analyze the accuracy-efficiency trade-off across exit depths. Our results demonstrate that later exits achieve a highly favorable balance, with exiting at layer 10 yielding up to a 20% speedup while incurring only a 1.5 drop in verification performance on benchmarks such as IJB-C. Also, we propose ViT-FREE_FT, a lightweight exit-specific fine-tuning strategy that adapts only the projection layers using a small synthetic dataset while keeping the transformer backbone frozen. This approach improves the performance of shallow exits while preserving the efficiency benefits and leaving deeper exits largely unaffected.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ViT-FREE, a training-free multi-exit framework that performs face verification directly from intermediate representations of a pretrained ViT backbone by leveraging uniform feature dimensionality across encoder blocks. It reports empirical observations that patch embeddings and attention maps evolve progressively with high inter-block similarity and increasing alignment to the final layer, enabling early exits. Experiments on multiple FR benchmarks show that exiting at layer 10 yields up to 20% speedup with only a 1.5-point drop in verification performance (e.g., on IJB-C); a lightweight exit-specific fine-tuning variant (ViT-FREE_FT) using synthetic data is also introduced to improve shallow exits while keeping the backbone frozen.
Significance. If the reported accuracy-efficiency trade-offs hold under standard protocols, the work provides a practical, zero-retraining method to reduce ViT inference cost for face recognition on resource-constrained devices. The training-free core and the synthetic-adaptation extension are clear strengths; the empirical validation across benchmarks supports the central claim without circularity or invented parameters.
major comments (2)
- [Experiments] Experiments section: the central claim of a 20% speedup with 1.5-point verification drop at layer-10 exit is supported by benchmark measurements, but the manuscript provides no details on exact evaluation protocols, data splits, number of runs, or error bars; this information is required to verify reproducibility of the accuracy-efficiency curves.
- [§3] §3 (empirical observations): the justification for early exiting rests on progressive evolution of patch embeddings and attention maps, yet the text does not report quantitative similarity metrics (e.g., cosine similarity or attention-map correlation) across consecutive blocks or versus the final representation; without these numbers the link between the stated observation and the suitability of intermediate layers remains qualitative.
minor comments (2)
- [Method] Clarify in the method section how the verification head is applied to intermediate representations (e.g., whether the same projection layer is reused or a new one is attached per exit).
- [Figures/Tables] Table or figure captions should explicitly state the baseline model and hardware used for the reported speedup percentages.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments. We address each major point below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of a 20% speedup with 1.5-point verification drop at layer-10 exit is supported by benchmark measurements, but the manuscript provides no details on exact evaluation protocols, data splits, number of runs, or error bars; this information is required to verify reproducibility of the accuracy-efficiency curves.
Authors: We agree that these details are necessary for full reproducibility. In the revised manuscript we will add the precise evaluation protocols (standard IJB-C 1:1 verification protocol and equivalent protocols on other benchmarks), the data splits employed, the number of runs, and error bars or standard deviations on all reported metrics. revision: yes
-
Referee: [§3] §3 (empirical observations): the justification for early exiting rests on progressive evolution of patch embeddings and attention maps, yet the text does not report quantitative similarity metrics (e.g., cosine similarity or attention-map correlation) across consecutive blocks or versus the final representation; without these numbers the link between the stated observation and the suitability of intermediate layers remains qualitative.
Authors: We acknowledge that Section 3 currently presents the observations qualitatively. In the revision we will augment this section with quantitative metrics, specifically average cosine similarity between consecutive-block patch embeddings, cosine similarity of each intermediate representation to the final-layer representation, and correlation coefficients for the attention maps. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical study of early-exiting in pretrained ViTs. All load-bearing claims (layer-10 exit: ~20% speedup, 1.5-point IJB-C drop) are direct measurements on benchmarks rather than derivations. The stated observation of progressive patch/attention evolution is presented as an empirical finding and is not used to derive any quantitative prediction that reduces to the same data by construction. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The method is explicitly training-free for the core early-exit strategy.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. An, X. Zhu, Y . Gao, Y . Xiao, Y . Zhao, Z. Feng, L. Wu, B. Qin, M. Zhang, D. Zhang, and Y . Fu. Partial FC: training 10 million identities on a single machine. InICCVW, pages 1445–1449. IEEE, 2021
2021
-
[2]
Bakhtiarnia, Q
A. Bakhtiarnia, Q. Zhang, and A. Iosifidis. Multi-exit vision trans- former for dynamic inference. InBMVC, page 81. BMV A Press, 2021
2021
-
[3]
Bakhtiarnia, Q
A. Bakhtiarnia, Q. Zhang, and A. Iosifidis. Single-layer vision transformers for more accurate early exits with less overhead.Neural Networks, 153:461–473, 2022
2022
-
[4]
Bolya, C
D. Bolya, C. Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman. Token merging: Your vit but faster. InICLR. OpenReview.net, 2023
2023
-
[5]
Boutros, E
F. Boutros, E. Caldeira, T. Chettaoui, and N. Damer. Idperturb: En- hancing variation in synthetic face generation via angular perturbation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[6]
Boutros, N
F. Boutros, N. Damer, F. Kirchbuchner, and A. Kuijper. Elasticface: Elastic margin loss for deep face recognition. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2022, New Orleans, LA, USA, June 19-20, 2022, pages 1577–1586. IEEE, 2022
2022
-
[7]
Chang, P
S. Chang, P. Wang, M. Lin, F. Wang, D. J. Zhang, R. Jin, and M. Z. Shou. Making vision transformers efficient from A token sparsification view. InCVPR, pages 6195–6205. IEEE, 2023
2023
-
[8]
Cheng, X
Z. Cheng, X. Zhu, and S. Gong. Low-resolution face recognition. InACCV (3), volume 11363 ofLecture Notes in Computer Science, pages 605–621. Springer, 2018
2018
-
[9]
Chettaoui, N
T. Chettaoui, N. Damer, and F. Boutros. Froundation: Are foundation models ready for face recognition?Image Vis. Comput., 156:105453, 2025
2025
-
[10]
E. D. Cubuk, B. Zoph, J. Shlens, and Q. V . Le. Randaugment: Practical automated data augmentation with a reduced search space. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2020, Seattle, WA, USA, June 14-19, 2020, pages 3008–3017. Computer Vision Foundation / IEEE, 2020
2020
-
[11]
J. Dan, Y . Liu, H. Xie, J. Deng, H. Xie, X. Xie, and B. Sun. Transface: Calibrating transformer training for face recognition from a data- centric perspective. InICCV, pages 20585–20596. IEEE, 2023
2023
-
[12]
Darcet, M
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision transform- ers need registers. InICLR. OpenReview.net, 2024
2024
-
[13]
J. Deng, J. Guo, N. Xue, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InCVPR, pages 4690–4699. Computer Vision Foundation / IEEE, 2019
2019
-
[14]
J. Deng, J. Guo, J. Yang, N. Xue, I. Kotsia, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):5962–5979, Oct. 2022
2022
-
[15]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Trans- formers for image recognition at scale. InICLR. OpenReview.net, 2021
2021
-
[16]
Graham, A
B. Graham, A. El-Nouby, H. Touvron, P. Stock, A. Joulin, H. J ´egou, and M. Douze. Levit: a vision transformer in convnet’s clothing for faster inference. InICCV, pages 12239–12249. IEEE, 2021
2021
-
[17]
J. Guo, K. Han, H. Wu, Y . Tang, X. Chen, Y . Wang, and C. Xu. CMT: convolutional neural networks meet vision transformers. InCVPR, pages 12165–12175. IEEE, 2022
2022
-
[18]
Y . Guo, L. Zhang, Y . Hu, X. He, and J. Gao. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In B. Leibe, J. Matas, N. Sebe, and M. Welling, editors,Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III, volume 9907 ofLecture Notes in Computer Science, pages 8...
2016
-
[19]
Y . Han, G. Huang, S. Song, L. Yang, H. Wang, and Y . Wang. Dynamic neural networks: A survey.IEEE Trans. Pattern Anal. Mach. Intell., 44(11):7436–7456, 2022
2022
- [20]
-
[21]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models. InICLR. OpenReview.net, 2022
2022
-
[22]
G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller. Labeled Faces in the Wild: A Database forStudying Face Recognition in Unconstrained Environments. InWorkshop on Faces in ’Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, Oct. 2008. Erik Learned-Miller and Andras Ferencz and Fr´ed´eric Jurie
2008
-
[23]
Islam, M
K. Islam, M. Z. Zaheer, and A. Mahmood. Face pyramid vision transformer. InBMVC, page 758. BMV A Press, 2022
2022
-
[24]
M. Khan, M. Saeed, A. El-Saddik, and W. Gueaieb. Artrivit: Auto- matic face recognition system using vit-based siamese neural networks with a triplet loss. InISIE, pages 1–6. IEEE, 2023
2023
-
[25]
M. Kim, Y . Su, F. Liu, A. Jain, and X. Liu. Keypoint relative position encoding for face recognition. InCVPR, pages 244–255. IEEE, 2024
2024
-
[26]
Y . Liang, C. Ge, Z. Tong, Y . Song, J. Wang, and P. Xie. Not all patches are what you need: Expediting vision transformers via token reorganizations.CoRR, abs/2202.07800, 2022
-
[27]
X. Liu, H. Peng, N. Zheng, Y . Yang, H. Hu, and Y . Yuan. Efficientvit: Memory efficient vision transformer with cascaded group attention. In CVPR, pages 14420–14430. IEEE, 2023
2023
-
[28]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InICLR (Poster). OpenReview.net, 2019
2019
-
[29]
Matsubara, M
Y . Matsubara, M. Levorato, and F. Restuccia. Split computing and early exiting for deep learning applications: Survey and research challenges.ACM Comput. Surv., 55(5):90:1–90:30, 2023
2023
-
[30]
B. Maze, J. C. Adams, J. A. Duncan, N. D. Kalka, T. Miller, C. Otto, A. K. Jain, W. T. Niggel, J. Anderson, J. Cheney, and P. Grother. IARPA janus benchmark - C: face dataset and protocol. InICB, pages 158–165. IEEE, 2018
2018
-
[31]
Mehta and M
S. Mehta and M. Rastegari. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. InICLR. OpenReview.net, 2022
2022
-
[32]
Mishra and K
P. Mishra and K. Sarawadekar. Polynomial learning rate policy with warm restart for deep neural network. InTENCON, pages 2087–2092. IEEE, 2019
2087
-
[33]
Moschoglou, A
S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou. Agedb: the first manually collected, in-the-wild age database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop, volume 2, page 5, 2017
2017
-
[34]
Nixon, P
S. Nixon, P. Ruiu, M. Cadoni, A. Lagorio, and M. Tistarelli. Exploiting face recognizability with early exit vision transformers. InBIOSIG, LNI, pages 1–7. Gesellschaft f ¨ur Informatik e.V . / IEEE, 2023
2023
-
[35]
Nixon, P
S. Nixon, P. Ruiu, M. Cadoni, A. Lagorio, and M. Tistarelli. Assessing bias and computational efficiency in vision transformers using early exits.EURASIP J. Image Video Process., 2025(1):2, 2025
2025
-
[36]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. As- sran, N. Ballas, W. Galuba, R. Howes, P. Huang, S. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. J ´egou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without supe...
2024
-
[37]
Phuong and C
M. Phuong and C. Lampert. Distillation-based training for multi- exit architectures. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 1355–1364. IEEE, 2019
2019
-
[38]
L. Qin, M. Wang, C. Deng, K. Wang, X. Chen, J. Hu, and W. Deng. Swinface: A multi-task transformer for face recognition, expression recognition, age estimation and attribute estimation.IEEE Trans. Circuits Syst. Video Technol., 34(4):2223–2234, 2024
2024
-
[39]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, volume 139 ofProceedings of Machine Learning Research, pages 8748–8763. PMLR, 2021
2021
-
[40]
Raghu, T
M. Raghu, T. Unterthiner, S. Kornblith, C. Zhang, and A. Dosovitskiy. Do vision transformers see like convolutional neural networks? In M. Ranzato, A. Beygelzimer, Y . N. Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Decembe...
2021
-
[41]
Rasley, S
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InKDD, pages 3505–3506. ACM, 2020
2020
-
[42]
Sengupta, J
S. Sengupta, J. Chen, C. Castillo, V . Patel, R. Chellappa, and D. Ja- cobs. Frontal to profile face verification in the wild. In2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016, 2016 IEEE Winter Conference on Applications of Computer Vision, W ACV 2016. Institute of Electrical and Electronics Engineers Inc., May 2016. Publisher C...
2016
-
[43]
Sun and G
Z. Sun and G. Tzimiropoulos. Part-based face recognition with vision transformers. InBMVC, page 611. BMV A Press, 2022
2022
-
[44]
Y . Tang, K. Han, Y . Wang, C. Xu, J. Guo, C. Xu, and D. Tao. Patch slimming for efficient vision transformers. InCVPR, pages 12155– 12164. IEEE, 2022
2022
-
[45]
Teerapittayanon, B
S. Teerapittayanon, B. McDanel, and H. T. Kung. Branchynet: Fast inference via early exiting from deep neural networks. InICPR, pages 2464–2469. IEEE, 2016
2016
-
[46]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need.CoRR, abs/1706.03762, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
H. Wang, Y . Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu. Cosface: Large margin cosine loss for deep face recognition. InCVPR, pages 5265–5274. Computer Vision Foundation / IEEE Computer Society, 2018
2018
-
[48]
Whitelam, E
C. Whitelam, E. Taborsky, A. Blanton, B. Maze, J. C. Adams, T. Miller, N. D. Kalka, A. K. Jain, J. A. Duncan, K. Allen, J. Cheney, and P. Grother. IARPA janus benchmark-b face dataset. InCVPR Workshops, pages 592–600. IEEE Computer Society, 2017
2017
-
[49]
Wolczyk, B
M. Wolczyk, B. W ´ojcik, K. Balazy, I. T. Podolak, J. Tabor, M. Smieja, and T. Trzcinski. Zero time waste: Recycling predictions in early exit neural networks. InNeurIPS, pages 2516–2528, 2021
2021
-
[50]
J. Xin, R. Tang, Y . Yu, and J. Lin. Berxit: Early exiting for BERT with better fine-tuning and extension to regression. In P. Merlo, J. Tiedemann, and R. Tsarfaty, editors,Proceedings of the 16th Con- ference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021, pages 91–104. Associ...
2021
-
[51]
G. Xu, J. Hao, L. Shen, H. Hu, Y . Luo, H. Lin, and J. Shen. Lgvit: Dynamic early exiting for accelerating vision transformer. InACM Multimedia, pages 9103–9114. ACM, 2023
2023
- [52]
-
[53]
Zheng and W
T. Zheng and W. Deng. Cross-pose lfw: A database for studying cross-pose face recognition in unconstrained environments. Technical Report 18-01, Beijing University of Posts and Telecommunications, February 2018
2018
-
[54]
Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments
T. Zheng, W. Deng, and J. Hu. Cross-age LFW: A database for studying cross-age face recognition in unconstrained environments. CoRR, abs/1708.08197, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
Y . Zhong and W. Deng. Face transformer for recognition.CoRR, abs/2103.14803, 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.