Attention by Synchronization in Coupled Oscillator Networks
Pith reviewed 2026-06-27 10:45 UTC · model grok-4.3
The pith
Kuramoto synchronization in oscillator networks implements a unique and globally attractive attention mechanism for transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fixed-query oscillator attention replaces softmax with the equilibration of a gradient flow on the sphere: learned queries act as fixed anchors, oscillators evolve under Kuramoto-Lohe dynamics to positions whose cosine similarities supply the attention weights, and the only global step is affine normalization at readout. The fixed point is provably unique and globally attractive from almost every initial condition across every physical realization.
What carries the argument
Kuramoto-Lohe gradient flow on the sphere, which drives free oscillators to synchronize at positions that encode attention weights via cosine similarity.
If this is right
- Attention requires no exponentiation or global reduction beyond affine normalization.
- The equilibrium is unique and globally attractive independent of the specific physical oscillators.
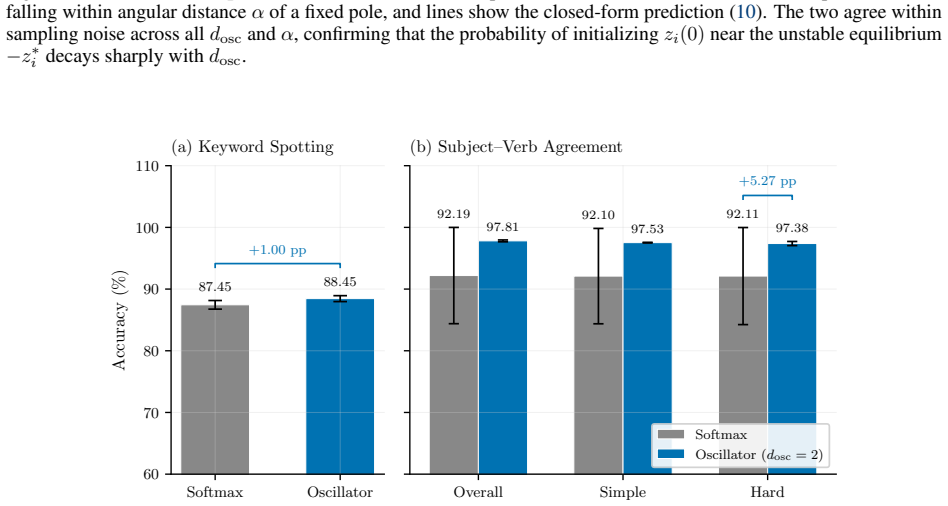
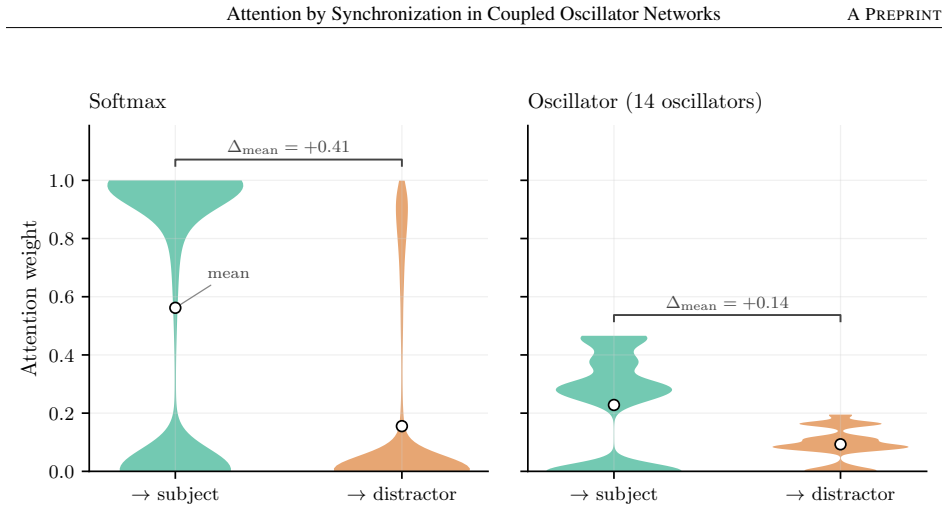
- At oscillator dimension 2 it outperforms softmax on keyword spotting by 1 percentage point and on subject-verb agreement by 5.27 points on hard sentences.
- The performance gap to softmax on language modeling shrinks as oscillator dimension rises from 2 to 32.
Where Pith is reading between the lines
- If physical arrays track the idealized dynamics, attention could run directly on analog or superconducting hardware with lower energy cost.
- Synchronization equilibria might be usable for other neural operations that currently rely on matrix multiplies.
- Building and measuring small arrays of coupled oscillators would directly test whether the predicted fixed points produce accurate attention.
Load-bearing premise
Real physical oscillator arrays will follow the idealized Kuramoto-Lohe gradient flow on the sphere closely enough for the equilibrium to encode usable attention weights after only an affine normalization at readout.
What would settle it
A physical experiment in which the oscillators fail to converge to one equilibrium or produce attention outputs that deviate substantially from the mathematical prediction after normalization.
Figures
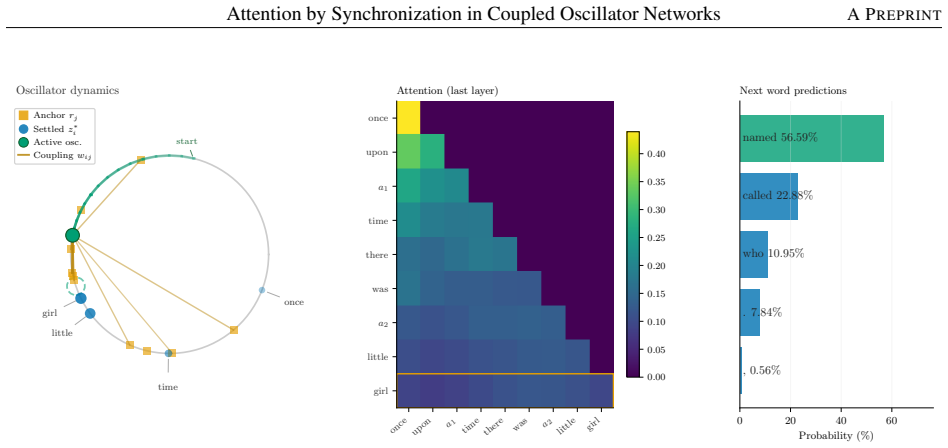
read the original abstract
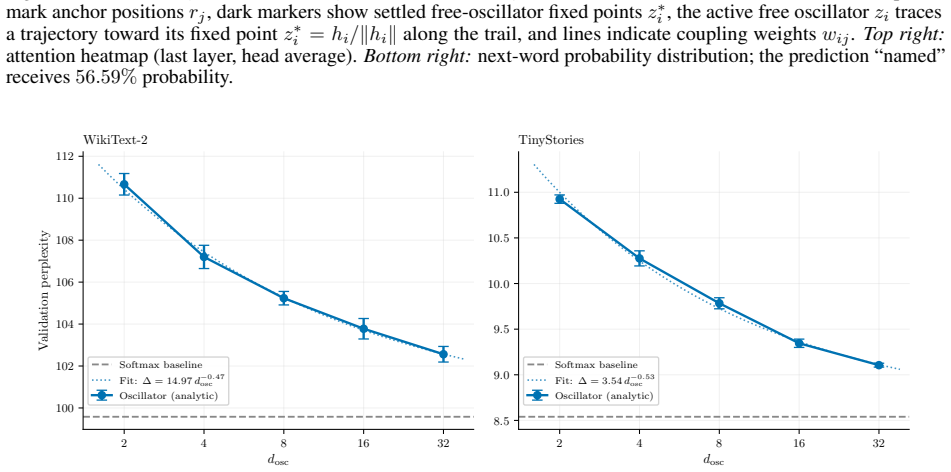
We address transformer attention on energy-constrained physical substrates. Softmax attention requires exponentiation and global reduction, operations with high energy cost on von Neumann hardware and no natural physical analog. We show that Kuramoto synchronization dynamics (which arise in electrical, mechanical, superconducting, and charge-density-wave oscillator arrays, among other physical systems) implement a well-defined attention operation without either. The resulting mechanism, fixed-query oscillator attention, replaces softmax's arithmetic with the equilibration of a gradient flow on the sphere: queries are learned anchors fixed on the sphere, and free oscillators evolve under Kuramoto-Lohe dynamics until they settle at positions encoding attention weights via cosine similarity. Because the computation is equilibration, it requires no exponentiation; the only global operation is an affine normalization at readout. The fixed point is provably unique and globally attractive from almost every initial condition, a guarantee that holds across every physical realization. Empirically, at the minimal hardware configuration (oscillator dimension $d_{\mathrm{osc}}$ = 2), oscillator attention outperforms softmax on keyword spotting (+1.00 pp) and on subject-verb agreement (+5.27 pp on hard sentences, with zero training failures versus one in five for softmax). On causal language modeling, where softmax retains an advantage, oscillator attention closes the gap as $d_{\mathrm{osc}}$ grows: from +11.09 PPL at $d_{\mathrm{osc}}$ = 2 to +2.98 PPL at $d_{\mathrm{osc}}$ = 32 on WikiText-2, and from +2.39 PPL at $d_{\mathrm{osc}}$ = 2 to +0.57 PPL at $d_{\mathrm{osc}}$ = 32 on TinyStories. The main objective of this work is not to replace softmax in software but to provide a mathematically grounded blueprint for accurate attention on physical substrates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes fixed-query oscillator attention, in which queries act as fixed anchors on the sphere and keys/values evolve under Kuramoto-Lohe gradient flow until the equilibrium positions encode attention weights by cosine similarity. The central mathematical claim is a proof that the resulting fixed point is unique and globally attractive from almost every initial condition, with this guarantee asserted to hold for every physical realization of the dynamics. The only post-processing is an affine normalization at readout. Empirically, at oscillator dimension d_osc=2 the mechanism outperforms softmax on keyword spotting (+1.00 pp) and subject-verb agreement (+5.27 pp on hard sentences), while on causal language modeling the perplexity gap narrows from +11.09 to +2.98 PPL (WikiText-2) and from +2.39 to +0.57 PPL (TinyStories) as d_osc grows to 32.
Significance. If the uniqueness/global-attractivity result is correct and the idealized flow remains a faithful model of physical oscillator arrays, the work supplies a parameter-free, exponentiation-free attention primitive whose only global operation is an affine readout. This would constitute a concrete blueprint for attention on energy-constrained substrates (electrical, mechanical, superconducting, etc.) where softmax has no natural analog. The reported empirical gains at minimal hardware dimension (d_osc=2) and the systematic closure of the language-modeling gap with increasing dimension are concrete, falsifiable predictions that strengthen the contribution.
major comments (2)
- [§3 (Uniqueness and Global Attractivity)] §3 (Uniqueness and Global Attractivity): The proof is derived for the ideal, noise-free, continuous Kuramoto-Lohe gradient flow on the sphere. The manuscript asserts that the same uniqueness and global attractivity hold “across every physical realization,” yet provides no perturbation analysis, Lyapunov bounds, or robustness margins for frequency detuning, additive noise, or higher-order nonlinearities that are unavoidable in physical oscillator arrays. This gap directly affects the load-bearing claim that the equilibrium reliably encodes cosine-similarity attention weights in hardware.
- [§5 (Experimental Results)] Experimental Results (§5): All accuracy and perplexity numbers (keyword spotting +1.00 pp, SVA +5.27 pp, language-modeling gaps) are obtained from exact numerical integration of the ideal ODE. No Monte-Carlo trials with injected noise, detuning, or non-ideal coupling are reported, nor are any hardware-in-the-loop or SPICE-level simulations. Consequently the empirical support for transfer to physical substrates remains limited to the idealized model.
minor comments (2)
- [§2 (Model Definition)] The notation for the sphere dimension versus oscillator dimension d_osc should be introduced once with an explicit mapping to the embedding space used by the transformer layers.
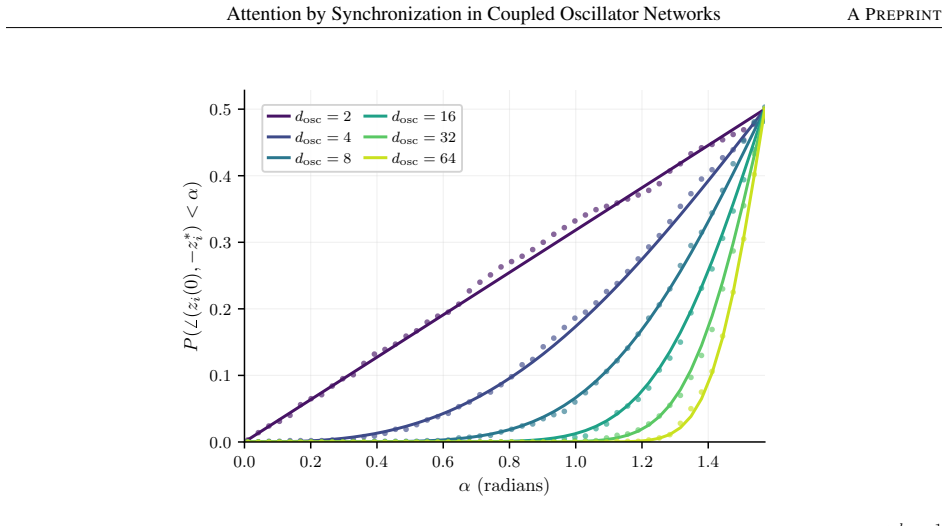
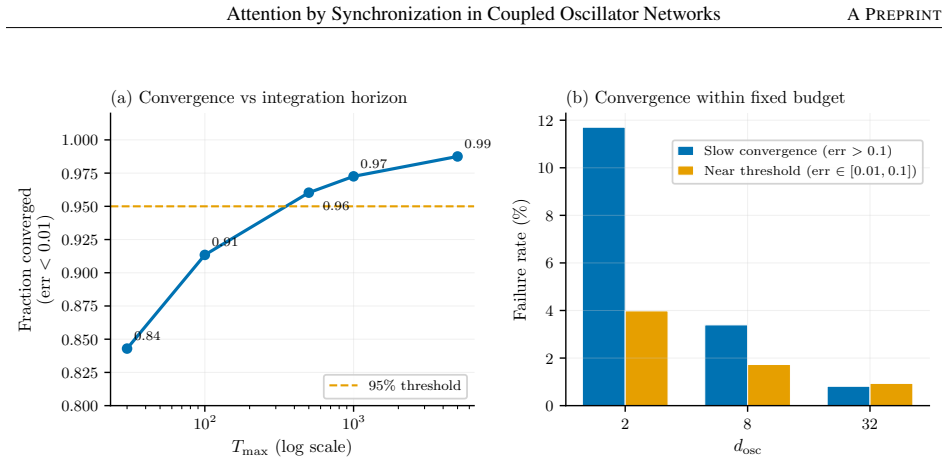
- [Figure captions] Convergence plots (presumably Figure 3 or 4) would benefit from error bands across random initial conditions and a statement of the integration tolerance used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: §3 (Uniqueness and Global Attractivity): The proof is derived for the ideal, noise-free, continuous Kuramoto-Lohe gradient flow on the sphere. The manuscript asserts that the same uniqueness and global attractivity hold “across every physical realization,” yet provides no perturbation analysis, Lyapunov bounds, or robustness margins for frequency detuning, additive noise, or higher-order nonlinearities that are unavoidable in physical oscillator arrays. This gap directly affects the load-bearing claim that the equilibrium reliably encodes cosine-similarity attention weights in hardware.
Authors: The uniqueness and global attractivity result is proven for the Kuramoto-Lohe model, which is the standard mathematical description of the dynamics in the physical oscillator arrays referenced in the manuscript. The statement that the guarantee holds across physical realizations assumes faithful adherence to this model. We agree that explicit robustness analysis for deviations such as detuning or noise is absent and would strengthen hardware claims. We will revise §3 and add a dedicated discussion paragraph citing known robustness results for Kuramoto flows under small perturbations. revision: partial
-
Referee: Experimental Results (§5): All accuracy and perplexity numbers (keyword spotting +1.00 pp, SVA +5.27 pp, language-modeling gaps) are obtained from exact numerical integration of the ideal ODE. No Monte-Carlo trials with injected noise, detuning, or non-ideal coupling are reported, nor are any hardware-in-the-loop or SPICE-level simulations. Consequently the empirical support for transfer to physical substrates remains limited to the idealized model.
Authors: The experiments evaluate the attention mechanism under the exact idealized dynamics that define the theoretical contribution. This is appropriate given the paper's primary focus on the mathematical model rather than hardware validation. We acknowledge that Monte-Carlo noise trials or SPICE simulations would better support physical transfer claims; such experiments lie outside the current scope and are reserved for follow-up work. We will insert a short limitations paragraph in §5 noting the idealized simulation setting. revision: partial
Circularity Check
No significant circularity; mathematical guarantee rests on independent ODE analysis.
full rationale
The paper derives the uniqueness and global attractivity of the fixed point directly from analysis of the Kuramoto-Lohe gradient flow on the sphere, with queries as fixed anchors and equilibration yielding cosine-similarity weights. This is a standard dynamical-systems argument on the idealized continuous ODE and does not reduce to any fitted parameter, self-definition, or self-citation chain. The affine readout normalization is an explicit post-processing step, not smuggled into the dynamics. Empirical results are obtained from exact simulation of the ideal model and are reported separately from the proof. No load-bearing self-citations, ansatzes, or renamings of known results appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Oscillator arrays obey Kuramoto-Lohe gradient flow on the sphere
Reference graph
Works this paper leans on
-
[1]
doi: 10.1145/3530811. Y . Kuramoto. Self-entrainment of a population of coupled non-linear oscillators. In H. Araki, editor,Int. Symposium on Mathematical Problems in Theoretical Physics, volume 39 ofLecture Notes in Physics, pages 420–422. Springer,
-
[2]
doi: 10.1103/zmlj-6nn7. M. A. Lohe. Non-Abelian Kuramoto models and synchronization.Journal of Physics A: Mathematical and Theoretical, 42(39):395101,
-
[3]
doi: 10.1088/1751-8113/42/39/395101. M. Breakspear, S. Heitmann, and A. Daffertshofer. Generative models of cortical oscillations: Neurobiological implications of the Kuramoto model.Frontiers in Human Neuroscience, 4:190,
-
[4]
doi: 10.3389/fnhum.2010. 00190. Wolf Singer and Charles M. Gray. Visual feature integration and the temporal correlation hypothesis.Annual Review of Neuroscience, 18:555–586,
-
[5]
Todri-Sanial, S
A. Todri-Sanial, S. Carapezzi, C. Delacour, M. Abernot, T. Gil, E. Corti, S. F. Karg, J. N ´u˜nez, M. Jim ´enez, M. J. Avedillo, and B. Linares-Barranco. How frequency injection locking can train oscillatory neural networks to compute in phase.IEEE Transactions on Neural Networks and Learning Systems, 33(5):1996–2009,
1996
-
[6]
doi: 10.1109/TNNLS.2021.3107771. H. K. Khalil.Nonlinear Systems. Prentice Hall,
-
[7]
P. Warden. Speech commands: A dataset for limited-vocabulary speech recognition.arXiv:1804.03209,
-
[8]
doi: 10.1162/tacl a 00115. R. Eldan and Y . Li. TinyStories: How small can language models be and still speak coherent English?arXiv:2305.07759,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/tacl
-
[9]
S. Wang, B. Z. Li, M. Khabsa, H. Fang, and H. Ma. Linformer: Self-attention with linear complexity.arXiv:2006.04768,
Pith/arXiv arXiv 2006
-
[10]
R. Child, S. Gray, A. Radford, and I. Sutskever. Generating long sequences with sparse transformers.arXiv:1904.10509,
Pith/arXiv arXiv 1904
-
[11]
I. Beltagy, M. E. Peters, and A. Cohan. Longformer: The long-document transformer.arXiv:2004.05150,
Pith/arXiv arXiv 2004
-
[12]
doi: 10.1016/j.neucom.2023.127063. O. Press, N. A. Smith, and M. Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. InInternational Conference on Learning Representations,
-
[13]
R.-J. Zhu, Q. Zhao, and J. K. Eshraghian. SpikeGPT: Generative pre-trained language model with spiking neural networks.arXiv:2302.13939,
-
[14]
C. Lv, T. Li, J. Xu, C. Gu, Z. Ling, C. Zhang, X. Zheng, and X. Huang. SpikeBERT: A language Spikformer trained with two-stage knowledge distillation from BERT.arXiv:2308.15122,
-
[15]
doi: 10.1103/PhysRevX.9.011002. R. Olfati-Saber. Swarms on sphere: A programmable swarm with synchronous behaviors like oscillator networks. In IEEE Conf. on Decision and Control, pages 5060–5066,
-
[16]
doi: 10.1109/72.846744. T. Menara, G. Baggio, D. S. Bassett, and F. Pasqualetti. Functional control of oscillator networks.Nature Communica- tions, 13:4721,
-
[17]
doi: 10.1038/s41467-022-31733-2. Y . Qin, A. M. Nobili, D. S. Bassett, and F. Pasqualetti. Vibrational stabilization of cluster synchronization in oscillator networks.IEEE Open Journal of Control Systems, 2:439–453,
-
[18]
doi: 10.1109/OJCSYS.2023.3331195. A. Ogranovich, T. Guo, A. R. Venkatakrishnan, M. R. Shapiro, F. Bullo, and F. Pasqualetti. Oscillator-based associative memory with exponential capacity: Theory, algorithms, and hardware implementation.IEEE Transactions on Control of Network Systems,
-
[19]
Emergence transformer: Dynamical temporal attention matters.arXiv preprint arXiv:2604.19816,
Zihan Zhou, Bo-Wei Qin, Kai Du, and Wei Lin. Emergence transformer: Dynamical temporal attention matters.arXiv preprint arXiv:2604.19816,
-
[20]
doi: 10.1016/j.tics.2005.08.011. J. J. Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558,
-
[21]
doi: 10.1073/pnas.79.8.2554. H. Ramsauer, B. Sch ¨afl, J. Lehner, P. Seidl, M. Widrich, T. Adler, L. Gruber, M. Holzleitner, D. Kreil, M. Kopp, G. Klambauer, J. Brandstetter, and S. Hochreiter. Hopfield networks is all you need. InInternational Conference on Learning Representations,
-
[22]
The first term satisfies Ωixi =ω iτi
Apply this to the right-hand side of (1) with Ωi =ω iJ where J= 0−1 1 0 is the 90◦ rotation. The first term satisfies Ωixi =ω iτi. The second term projects the coupling onto the tangent: (I−x ix⊤ i ) X j wijxj = X j wij (τ ⊤ i xj)τ i. Usingτ ⊤ i xj =−sinθ i cosθ j + cosθ i sinθ j = sin(θj −θ i), the full Lohe equation (1) becomes ˙θi τi =ω i τi + X j wij ...
1975
-
[23]
The keys on the table are/is
Input is log-mel spectrograms with 40 bins, 25 ms windows with 10 ms hop, T= 49 frames per utterance. No positional encoding; the spectrogram’s temporal structure is encoded implicitly through the coupling weights. Training: AdamW optimizer with weight decay 10−4, lr= 10 −3, batch 64, 30 epochs, cosine learning-rate schedule, gradient clipping at 1.0. The...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.