PROJECTMEM: A Local-First, Event-Sourced Memory and Judgment Layer for AI Coding Agents
Pith reviewed 2026-06-27 10:04 UTC · model grok-4.3
The pith
Projectmem equips AI coding agents with an append-only event log that projects into summaries and gates actions to avoid repeating past failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Projectmem records development as an append-only, plain-text event log of typed events and deterministically projects that log into compact, AI-readable summaries served through the Model Context Protocol; beyond storage, it adds a deterministic pre-action gate that warns an agent before it repeats a previously failed fix or edits a known-fragile file, framed as Memory-as-Governance.
What carries the argument
The append-only event log projected deterministically into summaries, together with the pre-action judgment gate that acts on the agent's next action.
If this is right
- Agents maintain persistent project context across sessions without re-deriving decisions from raw files each time.
- Every AI-assisted change carries an immutable, auditable provenance trail.
- The system operates entirely offline with no telemetry or external services.
- Agents receive explicit warnings that can prevent repetition of known errors or edits to fragile areas.
- The three-dependency Python package supplies fourteen MCP tools and nineteen CLI commands for immediate use.
Where Pith is reading between the lines
- The same event-log-plus-projection pattern could be applied to non-coding agent domains such as research or operations where repeated failed actions are costly.
- Automatic ingestion of git history or issue-tracker events could reduce the manual logging burden while preserving determinism.
- Because the projections are fully deterministic, they could serve as a stable test oracle for measuring whether new agent architectures respect prior project constraints.
- The provenance trail opens the possibility of post-hoc analysis of which agent decisions led to later failures, independent of any particular model.
Load-bearing premise
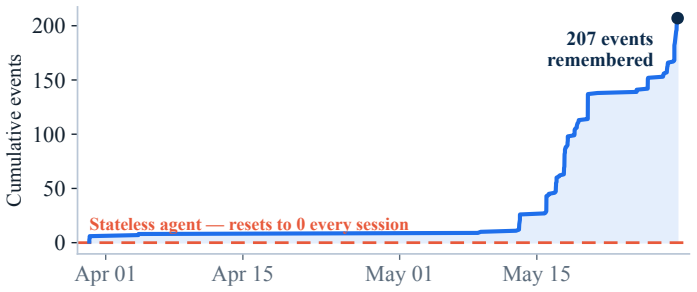
That the deterministic projections and pre-action gate will produce meaningful improvements in agent behavior in practice, an assumption supported only by the authors' internal self-study of 207 events.
What would settle it
A controlled experiment that measures whether agents equipped with projectmem show lower rates of repeated failed fixes, lower token consumption on context reconstruction, or higher task success compared with identical agents lacking the log and gate.
Figures
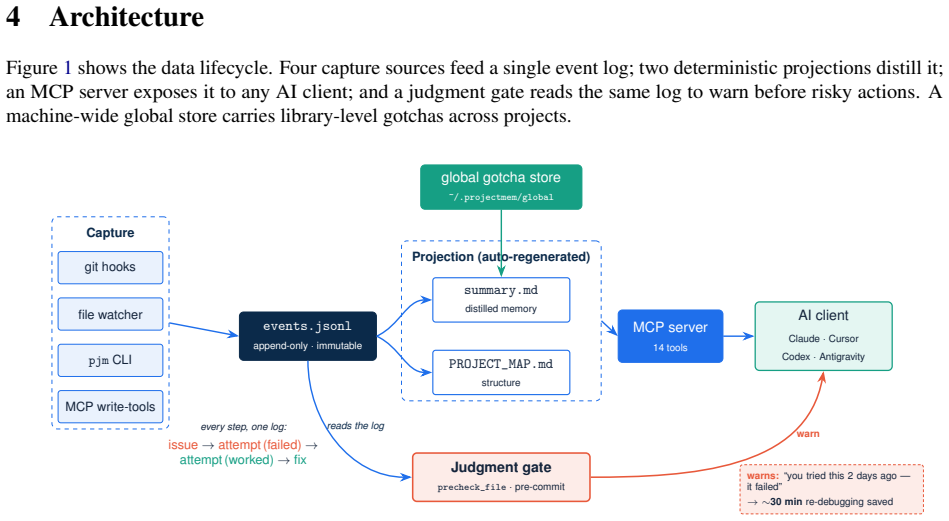
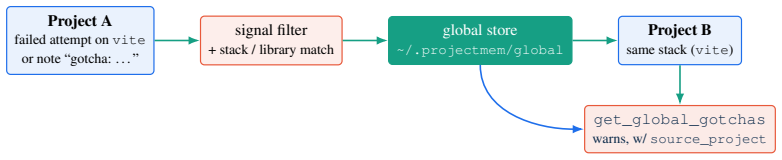
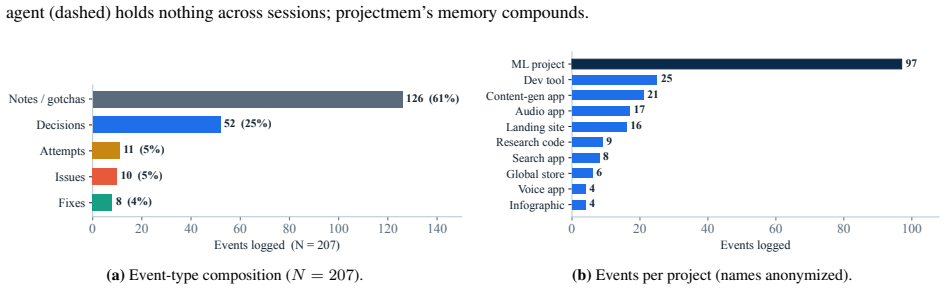
read the original abstract
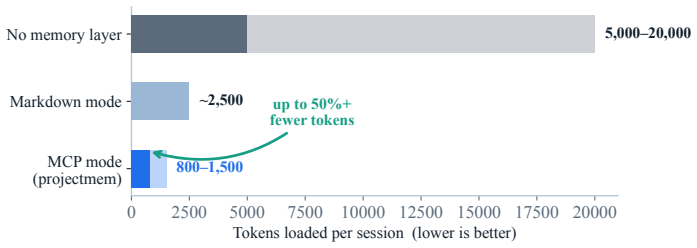
AI coding assistants now support a growing share of software work, from quick scripts to production applications. Yet these agents remain largely stateless: each new session re-reads project files, re-derives prior decisions, and - most costly - may repeat debugging attempts that already failed. Reconstructing this context can consume an estimated 5,000-20,000 tokens per session; the bottleneck is often not model capability but missing project memory. We present projectmem, an open-source, local-first memory and judgment layer for AI coding agents. projectmem records development as an append-only, plain-text event log of typed events - issues, attempts, fixes, decisions, and notes - and deterministically projects that log into compact, AI-readable summaries served through the Model Context Protocol (MCP). Beyond storage, projectmem adds a deterministic pre-action gate that warns an agent before it repeats a previously failed fix or edits a known-fragile file. We frame this as Memory-as-Governance: memory that does not merely answer the agent but acts on its next action. The system runs fully offline with no telemetry; its immutable log also serves as a provenance trail for reproducible, auditable AI-assisted development. projectmem ships as a three-dependency Python package (14 MCP tools, 19 CLI commands, 37 automated tests) and is evaluated through a two-month self-study across 10 projects comprising 207 logged events. Source code: https://github.com/riponcm/projectmem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ProjectMem, an open-source local-first memory and judgment layer for AI coding agents. It records development as an append-only plain-text event log of typed events (issues, attempts, fixes, decisions, notes) and deterministically projects the log into compact AI-readable summaries served via the Model Context Protocol (MCP). It adds a deterministic pre-action gate that warns agents against repeating failed fixes or editing known-fragile files, framed as Memory-as-Governance. The system is implemented as a three-dependency Python package and evaluated via a two-month self-study across 10 projects comprising 207 logged events.
Significance. If the design claims hold under rigorous testing, ProjectMem could provide a practical, fully offline, auditable memory layer that reduces per-session context reconstruction costs (estimated 5k-20k tokens) and enforces action governance for AI coding agents. The open-source release with MCP integration, CLI commands, and automated tests is a concrete contribution to reproducible AI-assisted development tooling.
major comments (2)
- [Evaluation section (two-month self-study)] Evaluation section (two-month self-study of 207 events): the manuscript reports the self-study as evidence that the summaries and pre-action gate improve agent behavior, but provides no baseline comparisons, no quantitative metrics on repetition rates, token reduction, or error reduction, and no controlled or external validation; this leaves the central claim of meaningful governance benefit as an untested design hypothesis.
- [Abstract and Evaluation] Abstract and Evaluation: the effectiveness of the deterministic projection into MCP summaries and the pre-action gate is asserted without any description of how outcomes were measured (e.g., repetition counts before/after, agent success rates), making it impossible to assess whether the 207 events demonstrate the claimed benefits.
minor comments (2)
- [Implementation] The manuscript would benefit from an explicit table or subsection listing the 14 MCP tools and 19 CLI commands with brief descriptions to improve reproducibility.
- [System Design] Notation for event types and projection functions could be introduced more formally (even if informal) to clarify how the immutable log maps to the served summaries.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation. The points raised about the self-study are valid, and we will revise the manuscript to align the presentation of results more precisely with the data collected.
read point-by-point responses
-
Referee: Evaluation section (two-month self-study of 207 events): the manuscript reports the self-study as evidence that the summaries and pre-action gate improve agent behavior, but provides no baseline comparisons, no quantitative metrics on repetition rates, token reduction, or error reduction, and no controlled or external validation; this leaves the central claim of meaningful governance benefit as an untested design hypothesis.
Authors: We agree that the self-study does not provide baseline comparisons, quantitative metrics on repetition rates, token reduction, or error reduction, nor controlled validation. The 207 events document usage across projects but were not collected with pre/post measurements or external controls. We will revise the Evaluation section to describe the study explicitly as an observational demonstration of system operation and event patterns, removing any implication of measured governance benefits. This revision will be incorporated. revision: yes
-
Referee: Abstract and Evaluation: the effectiveness of the deterministic projection into MCP summaries and the pre-action gate is asserted without any description of how outcomes were measured (e.g., repetition counts before/after, agent success rates), making it impossible to assess whether the 207 events demonstrate the claimed benefits.
Authors: The observation is accurate: the manuscript does not describe measurement protocols for outcomes such as repetition counts or success rates. The self-study records events but does not include comparative analysis of agent behavior before and after using the projections or gates. We will revise the Abstract and Evaluation sections to remove assertions of effectiveness and instead characterize the study as providing practical usage data from 10 projects. These changes will appear in the revised manuscript. revision: yes
Circularity Check
No circularity: system described via deterministic rules with no equations or self-referential derivations
full rationale
The paper describes an event-sourced memory system whose core operations are deterministic projections from an immutable append-only log into MCP summaries plus a pre-action gate; these are presented as direct implementations of stated rules rather than derived quantities. No equations, fitted parameters, or mathematical derivations appear anywhere. The evaluation consists of an authors' self-study of 207 events, which is an empirical report rather than a derivation that reduces to its own inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The central claim therefore does not reduce by construction to its inputs.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Development activities can be represented as typed events in an append-only log
- domain assumption Deterministic projections of the log produce AI-readable summaries that are useful
- domain assumption Past events can be used to deterministically identify and gate repeated failed actions
Reference graph
Works this paper leans on
-
[2]
URLhttps://arxiv.org/abs/2604.22085
-
[3]
Introducing the model context protocol
Anthropic. Introducing the model context protocol. https://www.anthropic.com/news/ model-context-protocol, 2024
2024
-
[5]
URLhttps://arxiv.org/abs/2505.03574
-
[6]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production- ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025. URL https: //arxiv.org/abs/2504.19413
Pith/arXiv arXiv 2025
-
[7]
ESAA: Event sourcing for autonomous agents in LLM-based software engineering
Elzo Brito dos Santos Filho. ESAA: Event sourcing for autonomous agents in LLM-based software engineering. arXiv preprint arXiv:2602.23193, 2026. URLhttps://arxiv.org/abs/2602.23193
arXiv 2026
-
[8]
Ramtin Ehsani, Sakshi Pathak, Shriya Rawal, Abdullah Al Mujahid, Mia Mohammad Imran, and Preetha Chatterjee. Where do AI coding agents fail? an empirical study of failed agentic pull requests in GitHub.arXiv preprint arXiv:2601.15195, 2026. URLhttps://arxiv.org/abs/2601.15195
arXiv 2026
-
[9]
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. Model context protocol (MCP): Landscape, security threats, and future research directions.arXiv preprint arXiv:2503.23278, 2025. URL https://arxiv.org/ abs/2503.23278
Pith/arXiv arXiv 2025
-
[10]
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257, 2025. URLhttps://arxiv.org/abs/2507.05257
Pith/arXiv arXiv 2025
-
[11]
Local-first software: You own your data, in spite of the cloud
Martin Kleppmann, Adam Wiggins, Peter van Hardenberg, and Mark McGranaghan. Local-first software: You own your data, in spite of the cloud. InProc. ACM SIGPLAN Onward!, 2019. doi: 10.1145/3359591.3359737
-
[12]
Zihan Li, Xingyu Fan, Feifei Li, and Wenhui Que. MemCog: From memory-as-tool to memory-as-cognition in conversational agents.arXiv preprint arXiv:2605.28046, 2026. URL https://arxiv.org/abs/2605. 28046
Pith/arXiv arXiv 2026
-
[13]
Weidi Luo, Shenghong Dai, Xiaogeng Liu, Suman Banerjee, Huan Sun, Muhao Chen, and Chaowei Xiao. AGrail: A lifelong agent guardrail with effective and adaptive safety detection.arXiv preprint arXiv:2502.11448, 2025. URLhttps://arxiv.org/abs/2502.11448
arXiv 2025
-
[14]
Yutao Mou, Zhangchi Xue, Lijun Li, Peiyang Liu, Shikun Zhang, Wei Ye, and Jing Shao. ToolSafe: Enhancing tool invocation safety of LLM-based agents via proactive step-level guardrail and feedback.arXiv preprint arXiv:2601.10156, 2026. URLhttps://arxiv.org/abs/2601.10156
arXiv 2026
-
[15]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023. URL https:// arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2023
-
[16]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProc. ACM Symposium on User Interface Software and Technology (UIST), 2023. doi: 10.1145/3586183.3606763. arXiv:2304.03442
-
[17]
Beyond the context window: A cost-performance analysis of fact-based memory vs
Natchanon Pollertlam and Witchayut Kornsuwannawit. Beyond the context window: A cost-performance analysis of fact-based memory vs. long-context LLMs for persistent agents.arXiv preprint arXiv:2603.04814, 2026. URL https://arxiv.org/abs/2603.04814. 11
arXiv 2026
-
[18]
Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025. URL https://arxiv.org/ abs/2501.13956
Pith/arXiv arXiv 2025
-
[19]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. arXiv:2303.11366
Pith/arXiv arXiv 2023
-
[20]
Mohammed Latif Siddiq, Arvin Islam-Gomes, Natalie Sekerak, and Joanna C. S. Santos. Large language models for software engineering: A reproducibility crisis.arXiv preprint arXiv:2512.00651, 2025. URL https://arxiv.org/abs/2512.00651
arXiv 2025
-
[21]
Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L
Theodore R. Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L. Griffiths. Cognitive architectures for language agents.arXiv preprint arXiv:2309.02427, 2023. URL https://arxiv.org/abs/2309.02427
Pith/arXiv arXiv 2023
-
[22]
Aristidis Vasilopoulos. Codified context: Infrastructure for AI agents in a complex codebase.arXiv preprint arXiv:2602.20478, 2026. URLhttps://arxiv.org/abs/2602.20478
arXiv 2026
-
[23]
Huanting Wang, Jingzhi Gong, Huawei Zhang, and Zheng Wang. AI agentic programming: A survey of techniques, challenges, and opportunities.arXiv preprint arXiv:2508.11126, 2025. URL https://arxiv.org/abs/ 2508.11126
arXiv 2025
-
[24]
Shu Wang, Edwin Yu, Oscar Love, Tom Zhang, Tom Wong, Steve Scargall, and Charles Fan. MemMachine: A ground-truth-preserving memory system for personalized AI agents.arXiv preprint arXiv:2604.04853, 2026. URLhttps://arxiv.org/abs/2604.04853
Pith/arXiv arXiv 2026
-
[25]
Chunlong Wu and Zhibo Qu. Meta-policy reflexion: Reusable reflective memory and rule admissibility for resource-efficient LLM agents.arXiv preprint arXiv:2509.03990, 2025. URL https://arxiv.org/abs/ 2509.03990
arXiv 2025
-
[26]
A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025
Wujiang Xu, Kai Mei, Hang Gao, Juntao Tan, Zujie Liang, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025. URLhttps://arxiv.org/abs/2502.12110
Pith/arXiv arXiv 2025
-
[27]
MemoryBank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhancing large language models with long-term memory. InProc. AAAI Conference on Artificial Intelligence, 2024. arXiv:2305.10250
Pith/arXiv arXiv 2024
-
[28]
Where LLM agents fail and how they can learn from failures.arXiv preprint arXiv:2509.25370, 2025
Kunlun Zhu, Zijia Liu, Bingxuan Li, Muxin Tian, Yingxuan Yang, Jiaxun Zhang, Pengrui Han, Qipeng Xie, Fuyang Cui, Weijia Zhang, Xiaoteng Ma, Xiaodong Yu, Gowtham Ramesh, Jialian Wu, Zicheng Liu, Pan Lu, James Zou, and Jiaxuan You. Where LLM agents fail and how they can learn from failures.arXiv preprint arXiv:2509.25370, 2025. URLhttps://arxiv.org/abs/250...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.