Semantically-Aware Diver Activity Recognition Framework for Effective Underwater Multi-Human-Robot Collaboration
Pith reviewed 2026-06-27 09:43 UTC · model grok-4.3
The pith
DAR-Net couples transformer temporal reasoning with pixel-level semantics via multi-loss training to classify six diver activities underwater.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DAR-Net is a transformer-based framework whose multi-loss training explicitly couples global activity recognition with pixel-level scene supervision, enabling accurate classification of six diver activities even in low-visibility underwater conditions when trained on the new UDA dataset.
What carries the argument
The multi-loss training strategy that couples transformer-based temporal reasoning with pixel-level human-robot interaction semantics.
If this is right
- AUVs equipped with DAR-Net could respond to recognized diver actions by offering targeted assistance or safety interventions.
- The UDA dataset supplies a public baseline that future underwater vision methods can be compared against.
- Pixel-level semantic supervision may reduce reliance on large activity-labeled video corpora in data-scarce domains.
- Successful alignment of global and local losses suggests similar multi-task formulations could be applied to other robot perception tasks.
Where Pith is reading between the lines
- If the semantic alignment proves robust, the same loss structure could be tested on surface or aerial human-robot teams facing visual degradation.
- The six-activity taxonomy could be expanded by adding fine-grained sub-actions once more labeled data becomes available.
- Deployment on actual AUV hardware would reveal whether real-time inference speed meets operational requirements.
Load-bearing premise
The multi-loss alignment between global activity labels and local pixel semantics will continue to work when the system moves from controlled test tanks into real low-visibility underwater conditions.
What would settle it
A controlled test that applies the trained DAR-Net to footage from actual murky underwater sites and measures whether accuracy on the six activities falls below the controlled-environment results would directly test the claim.
Figures



read the original abstract
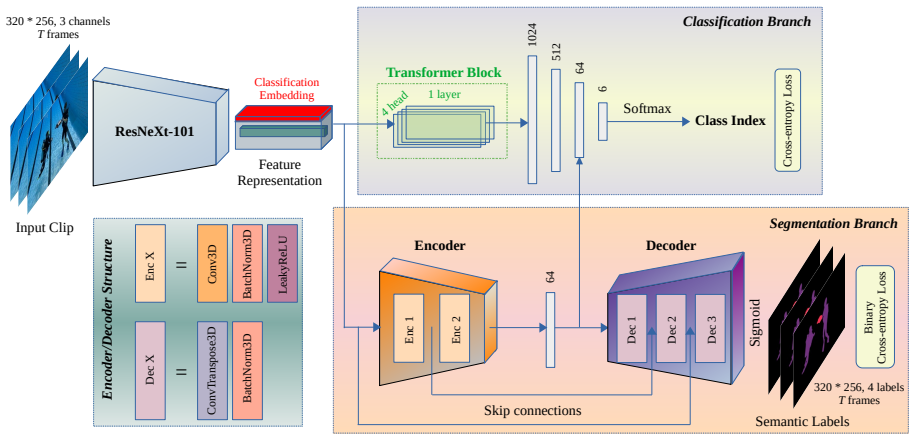
Effective multi-human-robot collaboration is essential for expanding human-led operations in the challenging and high-risk underwater environment. For autonomous underwater vehicles (AUVs) to become true teammates, they must be able to comprehend their surroundings and recognize a diver's activities to offer assistance and ensure safety. Towards this goal, we introduce DAR-Net, a novel transformer-based framework that analyzes complex underwater scenes to classify diver activities. Our contribution lies in a semantically guided learning formulation that couples transformer-based temporal reasoning with pixel-level scene supervision. This multi-loss training strategy explicitly aligns global activity recognition with local human-robot interaction semantics, which is particularly critical in low-visibility underwater conditions. To address the significant challenge of data scarcity in this domain, we present the first-ever Underwater Diver Activity (UDA) dataset, a foundational resource containing over 2,600 annotated images with pixel-level masks. Through rigorous experimental evaluations in a controlled environment, we demonstrate that DAR-Net achieves promising accuracy in recognizing six distinct diver activities, outperforming state-of-the-art models. While this dataset provides a crucial baseline, our work serves as a pioneering step, laying the groundwork for future research and facilitating the development of more intelligent, collaborative underwater robotic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DAR-Net, a transformer-based framework for classifying diver activities in underwater scenes. Its core contribution is a semantically guided multi-loss formulation that couples transformer-based temporal reasoning with pixel-level scene supervision to align global activity recognition and local human-robot interaction semantics. The paper also releases the UDA dataset (>2,600 annotated images with pixel-level masks) and claims that, in controlled-environment experiments, DAR-Net achieves promising accuracy on six activities and outperforms state-of-the-art models.
Significance. If the reported performance holds under proper statistical controls, the work supplies a much-needed public baseline dataset for underwater diver activity recognition and demonstrates a plausible route for incorporating local semantic supervision into activity classifiers. Both the dataset and the multi-loss alignment idea address recognized bottlenecks in underwater HRI and could serve as a reference point for subsequent research.
major comments (2)
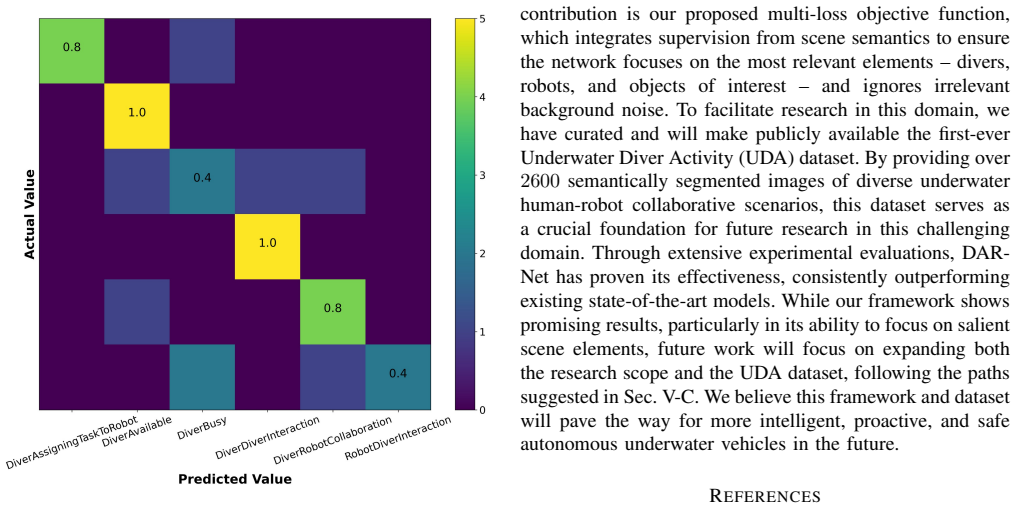
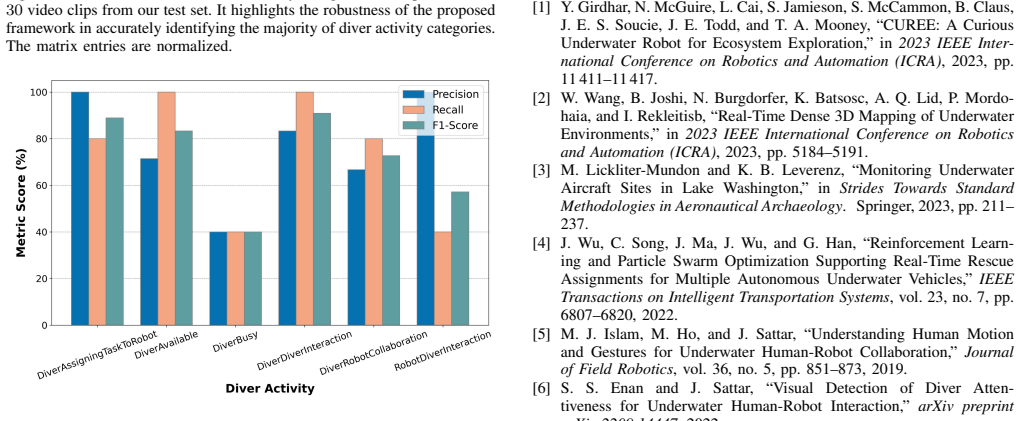
- [Abstract and §4] Abstract and §4 (Experimental Evaluation): the central claim that DAR-Net 'achieves promising accuracy' and 'outperforms state-of-the-art models' is asserted without any numeric accuracy values, confusion matrices, dataset splits, number of runs, or error bars. Because the claim rests entirely on experimental comparison, the absence of these quantities prevents verification that the outperformance is not due to post-hoc choices or limited data.
- [§4] §4 (Experimental Evaluation): no ablation is presented that isolates the contribution of the multi-loss term (global activity loss + local pixel-level supervision) versus a single-loss baseline. Without this comparison it is impossible to determine whether the semantically-aware component is load-bearing for the reported gains.
minor comments (2)
- [§3] The UDA dataset description would benefit from an explicit statement of train/validation/test split ratios and annotation protocol (inter-annotator agreement, label taxonomy).
- [§4] Figure captions and axis labels in the experimental figures should include the exact metric (e.g., top-1 accuracy, mIoU) and the number of trials averaged.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important gaps in the presentation of our experimental results. We agree that the current manuscript lacks the quantitative details and ablations needed to fully substantiate the claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Evaluation): the central claim that DAR-Net 'achieves promising accuracy' and 'outperforms state-of-the-art models' is asserted without any numeric accuracy values, confusion matrices, dataset splits, number of runs, or error bars. Because the claim rests entirely on experimental comparison, the absence of these quantities prevents verification that the outperformance is not due to post-hoc choices or limited data.
Authors: We acknowledge this limitation in the current version. The abstract and Section 4 present only qualitative statements without the supporting numeric results. In the revised manuscript we will add the specific accuracy values for DAR-Net and the baselines, confusion matrices, explicit train/validation/test splits of the UDA dataset, number of independent runs, and error bars (standard deviation across runs) so that the claimed outperformance can be directly verified. revision: yes
-
Referee: [§4] §4 (Experimental Evaluation): no ablation is presented that isolates the contribution of the multi-loss term (global activity loss + local pixel-level supervision) versus a single-loss baseline. Without this comparison it is impossible to determine whether the semantically-aware component is load-bearing for the reported gains.
Authors: We agree that an ablation isolating the multi-loss formulation is necessary. The current manuscript does not include such an experiment. We will add a new ablation study in the revised Section 4 that compares the full DAR-Net (global activity loss + pixel-level supervision) against a single-loss baseline using only the global activity loss, thereby quantifying the contribution of the semantically guided component. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces DAR-Net, a transformer-based model with a multi-loss training strategy, and the new UDA dataset. Performance claims rest entirely on experimental evaluations in a controlled environment comparing against state-of-the-art models. No equations, derivations, or predictions are present that reduce reported accuracy to quantities defined by fitted parameters or self-citations within the paper. The central result is scoped to empirical accuracy on six activities and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CUREE: A Curious Underwater Robot for Ecosystem Exploration,
Y . Girdhar, N. McGuire, L. Cai, S. Jamieson, S. McCammon, B. Claus, J. E. S. Soucie, J. E. Todd, and T. A. Mooney, “CUREE: A Curious Underwater Robot for Ecosystem Exploration,” in2023 IEEE Inter- national Conference on Robotics and Automation (ICRA), 2023, pp. 11 411–11 417
2023
-
[2]
Real-Time Dense 3D Mapping of Underwater Environments,
W. Wang, B. Joshi, N. Burgdorfer, K. Batsosc, A. Q. Lid, P. Mordo- haia, and I. Rekleitisb, “Real-Time Dense 3D Mapping of Underwater Environments,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 5184–5191
2023
-
[3]
Monitoring Underwater Aircraft Sites in Lake Washington,
M. Lickliter-Mundon and K. B. Leverenz, “Monitoring Underwater Aircraft Sites in Lake Washington,” inStrides Towards Standard Methodologies in Aeronautical Archaeology. Springer, 2023, pp. 211– 237
2023
-
[4]
Reinforcement Learn- ing and Particle Swarm Optimization Supporting Real-Time Rescue Assignments for Multiple Autonomous Underwater Vehicles,
J. Wu, C. Song, J. Ma, J. Wu, and G. Han, “Reinforcement Learn- ing and Particle Swarm Optimization Supporting Real-Time Rescue Assignments for Multiple Autonomous Underwater Vehicles,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 7, pp. 6807–6820, 2022
2022
-
[5]
Understanding Human Motion and Gestures for Underwater Human-Robot Collaboration,
M. J. Islam, M. Ho, and J. Sattar, “Understanding Human Motion and Gestures for Underwater Human-Robot Collaboration,”Journal of Field Robotics, vol. 36, no. 5, pp. 851–873, 2019
2019
-
[6]
Visual Detection of Diver Atten- tiveness for Underwater Human-Robot Interaction,
S. S. Enan and J. Sattar, “Visual Detection of Diver Atten- tiveness for Underwater Human-Robot Interaction,”arXiv preprint arXiv:2209.14447, 2022
-
[7]
LSTM-CNN Architecture for Human Activity Recognition,
K. Xia, J. Huang, and H. Wang, “LSTM-CNN Architecture for Human Activity Recognition,”IEEE Access, vol. 8, pp. 56 855–56 866, 2020
2020
-
[8]
Actor- Transformers for Group Activity Recognition,
K. Gavrilyuk, R. Sanford, M. Javan, and C. G. M. Snoek, “Actor- Transformers for Group Activity Recognition,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 836–845
2020
-
[9]
Reliable Data Collection Techniques in Underwater Wireless Sensor Networks: A Survey,
X. Wei, H. Guo, X. Wang, X. Wang, and M. Qiu, “Reliable Data Collection Techniques in Underwater Wireless Sensor Networks: A Survey,”IEEE Communications Surveys & Tutorials, vol. 24, no. 1, pp. 404–431, 2022
2022
-
[10]
SV AM: Saliency-guided Visual Attention Modeling by Autonomous Underwater Robots,
M. J. Islam, R. Wang, and J. Sattar, “SV AM: Saliency-guided Visual Attention Modeling by Autonomous Underwater Robots,” inRobotics: Science and Systems (RSS), NY , USA, 2022
2022
-
[11]
A Survey on Human Activity Recognition using Wearable Sensors,
O. D. Lara and M. A. Labrador, “A Survey on Human Activity Recognition using Wearable Sensors,”IEEE Communications Surveys & Tutorials, vol. 15, no. 3, pp. 1192–1209, 2013
2013
-
[12]
A Review of Human Activity Recognition Methods,
M. Vrigkas, C. Nikou, and I. A. Kakadiaris, “A Review of Human Activity Recognition Methods,”Frontiers in Robotics and AI, vol. 2, pp. 1–28, 2015
2015
-
[13]
A Review on Video-Based Human Activity Recognition,
S.-R. Ke, H. L. U. Thuc, Y .-J. Lee, J.-N. Hwang, J.-H. Yoo, and K.- H. Choi, “A Review on Video-Based Human Activity Recognition,” Computers, vol. 2, no. 2, pp. 88–131, 2013
2013
-
[14]
Wearable Sensor-Based Human Activity Recognition in the Smart Healthcare System,
F. Serpush, M. B. Menhaj, B. Masoumi, B. Karasfiet al., “Wearable Sensor-Based Human Activity Recognition in the Smart Healthcare System,”Computational Intelligence and Neuroscience, vol. 2022, 2022
2022
-
[15]
Recognizing Human Daily Activities From Accelerometer Signal,
J. Wang, R. Chen, X. Sun, M. F. She, and Y . Wu, “Recognizing Human Daily Activities From Accelerometer Signal,”Procedia Engineering, vol. 15, pp. 1780–1786, 2011
2011
-
[16]
Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks,
W. Jiang and Z. Yin, “Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks,” in23rd ACM international conference on Multimedia, 2015, pp. 1307–1310
2015
-
[17]
Understanding Action Recog- nition in Still Images,
D. Girish, V . Singh, and A. Ralescu, “Understanding Action Recog- nition in Still Images,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2020, pp. 1523– 1529
2020
-
[18]
Human Action Recognition Using Histogram of Oriented Gradient of Motion History Image,
C.-P. Huang, C.-H. Hsieh, K.-T. Lai, and W.-Y . Huang, “Human Action Recognition Using Histogram of Oriented Gradient of Motion History Image,” in2011 First International Conference on Instrumentation, Measurement, Computer, Communication and Control, 2011, pp. 353– 356
2011
-
[19]
Human Activity Recognition Based on Silhouette Analysis Using Local Binary Patterns,
H. Su, J. Zou, and W. Wang, “Human Activity Recognition Based on Silhouette Analysis Using Local Binary Patterns,” in2013 10th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), 2013, pp. 924–929
2013
-
[20]
Human Activity Recognition using Binary Motion Image and Deep Learning,
T. Dobhal, V . Shitole, G. Thomas, and G. Navada, “Human Activity Recognition using Binary Motion Image and Deep Learning,” Procedia Computer Science, vol. 58, pp. 178–185, 2015, second International Symposium on Computer Vision and the Internet (VisionNet’15). [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S1877050915021614
2015
-
[21]
Two-Stream Convolutional Networks for Action Recognition in Videos,
K. Simonyan and A. Zisserman, “Two-Stream Convolutional Networks for Action Recognition in Videos,”Advances in Neural Information Processing Systems, vol. 27, p. 568–576, 2014
2014
-
[22]
SlowFast Networks for Video Recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “SlowFast Networks for Video Recognition,” in2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 6201–6210
2019
-
[23]
A General Method for Human Activity Recognition in Video,
N. Robertson and I. Reid, “A General Method for Human Activity Recognition in Video,”Computer Vision and Image Understanding, vol. 104, no. 2, pp. 232–248, 2006, special Issue on Modeling People: Vision-based understanding of a person’s shape, appearance, movement and behaviour. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S1077...
2006
-
[24]
Event-Based Analysis of Video,
L. Zelnik-Manor and M. Irani, “Event-Based Analysis of Video,” in 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, 2001, pp. 123–130
2001
-
[25]
Learning Spatiotemporal Features with 3D Convolutional Networks,
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning Spatiotemporal Features with 3D Convolutional Networks,” in2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 4489–4497
2015
-
[26]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,
J. Carreira and A. Zisserman, “Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6299– 6308
2017
-
[27]
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition,
K. Hara, H. Kataoka, and Y . Satoh, “Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition,” in 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), 2017, pp. 3154–3160
2017
-
[28]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild,”arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[29]
Large-Scale Video Classification with Convolutional Neu- ral Networks,
A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei, “Large-Scale Video Classification with Convolutional Neu- ral Networks,” in2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 1725–1732
2014
-
[30]
Activi- tyNet: A Large-Scale Video Benchmark for Human Activity Under- standing,
F. C. Heilbron, V . Escorcia, B. Ghanem, and J. C. Niebles, “Activi- tyNet: A Large-Scale Video Benchmark for Human Activity Under- standing,” in2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 961–970
2015
-
[31]
The Kinetics Human Action Video Dataset,
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsev, M. Suleyman, and A. Zisserman, “The Kinetics Human Action Video Dataset,” 2017
2017
-
[32]
Long-Term Feature Banks for Detailed Video Under- standing,
C.-Y . Wu, C. Feichtenhofer, H. Fan, K. He, P. Krähenbühl, and R. Girshick, “Long-Term Feature Banks for Detailed Video Under- standing,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 284–293
2019
-
[33]
Video Action Transformer Network,
R. Girdhar, J. Carreira, C. Doersch, and A. Zisserman, “Video Action Transformer Network,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 244–253
2019
-
[34]
Late Temporal Model- ing in 3D CNN Architectures with BERT for Action Recognition,
M. E. Kalfaoglu, S. Kalkan, and A. A. Alatan, “Late Temporal Model- ing in 3D CNN Architectures with BERT for Action Recognition,” in European Conference on Computer Vision (ECCV). Springer, 2020, pp. 731–747
2020
-
[35]
Underwater Motion and Activity Recogni- tion using Acoustic Wireless Networks,
H. Hu, Z. Sun, and L. Su, “Underwater Motion and Activity Recogni- tion using Acoustic Wireless Networks,” in2020 IEEE International Conference on Communications (ICC), 2020, pp. 1–7
2020
-
[36]
DARE: Diver Action Recognition Encoder for Underwater Human–Robot Interaction,
J. Yang, J. P. Wilson, and S. Gupta, “DARE: Diver Action Recognition Encoder for Underwater Human–Robot Interaction,”IEEE Access, vol. 11, pp. 76 926–76 940, 2023
2023
-
[37]
Automatic Swimming Activity Recognition and Lap Time Assessment Based on a Single IMU: A Deep Learning Approach,
E. Delhaye, A. Bouvet, G. Nicolas, J. P. Vilas-Boas, B. Bideau, and N. Bideau, “Automatic Swimming Activity Recognition and Lap Time Assessment Based on a Single IMU: A Deep Learning Approach,” Sensors, vol. 22, no. 15, p. 5786, 2022
2022
-
[38]
A Spatio-Temporal Recurrent Network for Salmon Feeding Action Recognition From Underwater Videos in Aquaculture,
H. Måløy, A. Aamodt, and E. Misimi, “A Spatio-Temporal Recurrent Network for Salmon Feeding Action Recognition From Underwater Videos in Aquaculture,”Computers and Electronics in Agriculture, vol. 167, pp. 1–9, 2019
2019
-
[39]
Robotic Detection of a Human- Comprehensible Gestural Language for Underwater Multi-Human- Robot Collaboration,
S. S. Enan, M. Fulton, and J. Sattar, “Robotic Detection of a Human- Comprehensible Gestural Language for Underwater Multi-Human- Robot Collaboration,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 3085–3092
2022
-
[40]
DiverNet - a Network of Inertial Sensors for Real Time Diver Visualization,
G. M. Goodfellow, J. A. Neasham, I. Renduli ´c, Ð. Na ¯d, and N. Miškovi´c, “DiverNet - a Network of Inertial Sensors for Real Time Diver Visualization,” in2015 IEEE Sensors Applications Symposium (SAS), 2015, pp. 1–6
2015
-
[41]
Towards Advancing Diver-Robot Interaction Capabilities,
Ð. Na ¯d, C. Walker, I. Kvasi ´c, D. O. Antillon, N. Miškovi ´c, I. An- derson, and I. Lon ˇcar, “Towards Advancing Diver-Robot Interaction Capabilities,”IFAC-PapersOnLine, vol. 52, no. 21, pp. 199–204, 2019
2019
-
[42]
CADDY Underwater Stereo-Vision Dataset for Human–Robot Interaction (HRI) in the Context of Diver Activities,
A. Gomez Chavez, A. Ranieri, D. Chiarella, E. Zereik, A. Babi ´c, and A. Birk, “CADDY Underwater Stereo-Vision Dataset for Human–Robot Interaction (HRI) in the Context of Diver Activities,” Journal of Marine Science and Engineering, vol. 7, no. 1, 2019. [Online]. Available: https://www.mdpi.com/2077-1312/7/1/16
2019
-
[43]
GoPro Hero 8,
“GoPro Hero 8,” 2019, https://gopro.com
2019
-
[44]
Segment Anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Dollar, and R. Girshick, “Segment Anything,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 4015– 4026
2023
-
[45]
Aggregated Residual Transformations for Deep Neural Networks,
S. Xie, R. B. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated Residual Transformations for Deep Neural Networks,”2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5987–5995, 2016. [Online]. Available: https://api.semanticscholar. org/CorpusID:8485068
2017
-
[46]
PyTorch: An Imperative Style, High-Performance Deep Learning Library,
A. Paszke, S. Gross, F. Massa, A. Lereret al., “PyTorch: An Imperative Style, High-Performance Deep Learning Library,” inAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2019, pp. 8024–8035
2019
-
[47]
Towards Good Practices for Very Deep Two-Stream ConvNets
L. Wang, Y . Xiong, Z. Wang, and Y . Qiao, “Towards Good Practices for Very Deep Two-Stream ConvNets,”arXiv preprint arXiv:1507.02159, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[48]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regulariza- tion,”arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
A Closer Look at Spatiotemporal Convolutions for Action Recognition,
D. Tran, H. Wang, L. Torresani, J. Ray, Y . LeCun, and M. Paluri, “A Closer Look at Spatiotemporal Convolutions for Action Recognition,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6450–6459
2018
-
[50]
Attention is All You Need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is All You Need,” in31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY , USA: Curran Associates Inc., 2017, p. 6000–6010
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.